Hola Habr! Les traigo a su atención una traducción del artículo de Rudy Gilman y Katherine Wang RL intuitiva: Introducción a Advantage-Actor-Critic (A2C) .

Los especialistas en aprendizaje reforzado (RL) han producido muchos tutoriales excelentes. Sin embargo, la mayoría describe RL en términos de ecuaciones matemáticas y diagramas abstractos. Nos gusta pensar sobre el tema desde una perspectiva diferente. El RL en sí mismo está inspirado en cómo aprenden los animales, entonces, ¿por qué no traducir el mecanismo de RL subyacente nuevamente en fenómenos naturales que se pretende simular? La gente aprende mejor a través de las historias.
Esta es la historia del modelo Actor Advantage Critic (A2C). El modelo de sujeto crítico es una forma popular del modelo Policy Gradient, que en sí mismo es un algoritmo RL tradicional. Si entiendes A2C, entiendes RL profundo.
Después de obtener una comprensión intuitiva de A2C, verifique:
Ilustraciones @embermarke
En RL, el agente, el zorro Klyukovka, se mueve a través de estados rodeados de acciones, tratando de maximizar las recompensas en el camino.
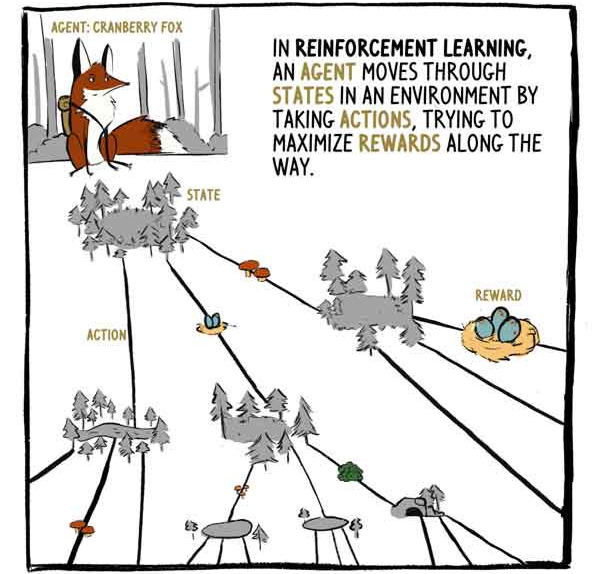
A2C recibe entradas de estado - entradas de sensor en el caso de Klukovka - y genera dos salidas:
1) Una evaluación de cuánta remuneración se recibirá, a partir del momento del estado actual, con la excepción de la remuneración actual (existente).
2) Una recomendación sobre qué medidas tomar (política).
Crítico: wow, qué maravilloso valle! ¡Será un día fructífero para buscar comida! Apuesto a que hoy recogeré 20 puntos antes del atardecer.
"Sujeto": estas flores se ven hermosas, siento un antojo por "A".

Los modelos Deep RL son máquinas de mapeo de entrada-salida, como cualquier otro modelo de clasificación o regresión. En lugar de categorizar imágenes o texto, los modelos RL profundos traen estados a acciones y / o estados a valores de estado. A2C hace las dos cosas.


Este conjunto de recompensa de acción estatal es una observación. Ella escribirá esta línea de datos en su diario, pero todavía no va a pensar en ello. Ella lo llenará cuando se detenga a pensar.
Algunos autores asocian la recompensa 1 con el tiempo paso 1, otros la asocian con el paso 2, pero todos tienen en cuenta el mismo concepto: la recompensa está asociada con el estado y la acción la precede inmediatamente.

Enganchar repite el proceso nuevamente. Primero, percibe su entorno y desarrolla una función V (S) y una recomendación para la acción.
Crítico: Este valle parece bastante estándar. V (S) = 19.
Asunto: Las opciones de acción son muy similares. Creo que simplemente iré por la pista "C".
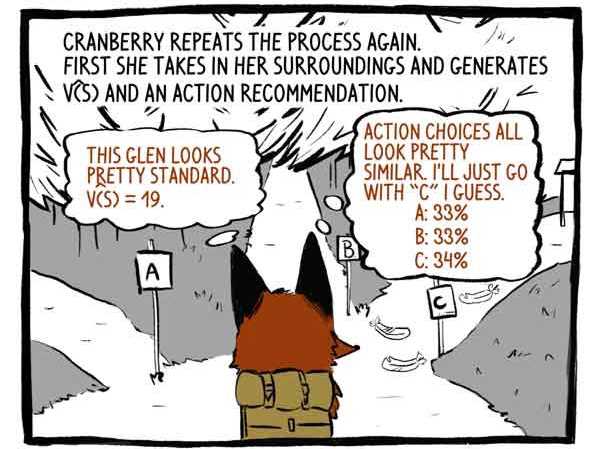
Entonces actúa.

¡Recibe una recompensa de +20! Y registra la observación.

Ella repite el proceso nuevamente.

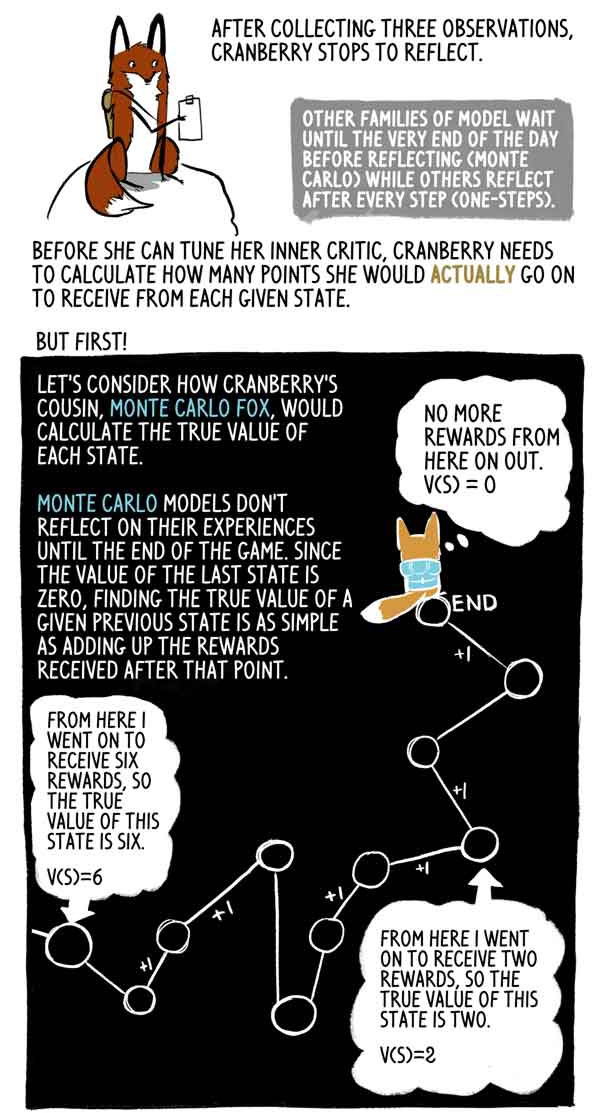
Después de recoger tres observaciones, Klyukovka se detiene a pensar.
Otras familias modelo esperan hasta el final del día (Monte Carlo), mientras que otras piensan después de cada paso (un paso).
Antes de que pueda configurar su crítico interno, Klukovka necesita calcular cuántos puntos recibirá realmente en cada estado.
Pero primero!
Veamos cómo la prima de Klukovka, Lis Monte Carlo, calcula el verdadero significado de cada estado.
Los modelos de Monte Carlo no reflejan su experiencia hasta el final del juego, y dado que el valor del último estado es cero, es muy simple encontrar el verdadero valor de este estado anterior como la suma de las recompensas recibidas después de este momento.
De hecho, esta es solo una muestra de alta dispersión V (S). El agente podría seguir fácilmente una trayectoria diferente desde el mismo estado, recibiendo así una recompensa agregada diferente.
Pero Klyukovka se va, se detiene y reflexiona muchas veces hasta que el día llega a su fin. Ella quiere saber cuántos puntos obtendrá realmente de cada estado hasta el final del juego, porque quedan varias horas hasta el final del juego.
Ahí es donde hace algo realmente inteligente: la zorra Klyukovka estima cuántos puntos recibirá por el último estado en este set. Afortunadamente, tiene una evaluación correcta de su condición: su crítica.
Con esta evaluación, Klyukovka puede calcular los valores "correctos" de los estados anteriores exactamente como lo hace el zorro de Monte Carlo.
Lis Monte Carlo evalúa las marcas de destino, realiza el despliegue de la trayectoria y agrega recompensas hacia adelante desde cada estado. A2C corta esta trayectoria y la reemplaza con una evaluación de su crítico. Esta carga inicial reduce la varianza de la puntuación y permite que el A2C se ejecute continuamente, aunque introduciendo un pequeño sesgo.

Las recompensas a menudo se reducen para reflejar el hecho de que la remuneración ahora es mejor que en el futuro. Por simplicidad, Klukovka no reduce sus recompensas.

Klukovka ahora puede pasar por cada fila de datos y comparar sus estimaciones de valores de estado con sus valores reales. Ella usa la diferencia entre estos números para perfeccionar sus habilidades de predicción. Cada tres pasos durante el día, Klyukovka recopila una valiosa experiencia que vale la pena considerar.
“Califiqué mal los estados 1 y 2. ¿Qué hice mal? Si! La próxima vez que vea plumas como estas, aumentaré V (S).
Puede parecer una locura que Klukovka pueda usar su calificación V (S) como base para compararlo con otros pronósticos. ¡Pero los animales (incluidos nosotros) hacen esto todo el tiempo! Si siente que las cosas van bien, no necesita volver a capacitar las acciones que lo llevaron a este estado.

Al recortar nuestros resultados calculados y reemplazarlos con una estimación de carga inicial, reemplazamos la gran variación de Monte Carlo con un pequeño sesgo. Los modelos RL suelen sufrir una alta dispersión (que representa todos los caminos posibles), y tal reemplazo generalmente vale la pena.
Klukovka repite este proceso todo el día, recogiendo tres observaciones de estado-acción-recompensa y reflexionando sobre ellas.
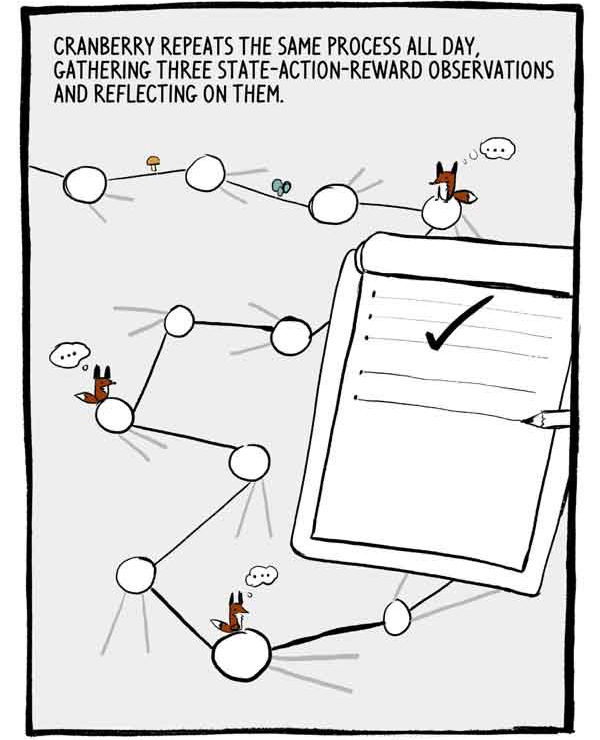
Cada conjunto de tres observaciones es una pequeña serie autocorrelacionada de datos de entrenamiento etiquetados. Para reducir esta autocorrelación, muchas A2C capacitan a muchos agentes en paralelo, sumando su experiencia antes de enviarla a una red neuronal común.

El día finalmente está llegando a su fin. Solo quedan dos pasos.
Como dijimos anteriormente, las recomendaciones de las acciones de Klukovka se expresan en porcentaje de confianza sobre sus capacidades. En lugar de simplemente elegir la opción más confiable, Klukovka elige de esta distribución de acciones. Esto asegura que ella no siempre acepta acciones seguras, pero potencialmente mediocres.
Podría arrepentirme, pero ... A veces, explorando cosas desconocidas, puedes llegar a nuevos descubrimientos emocionantes ...

Para alentar aún más la investigación, un valor llamado entropía se resta de la función de pérdida. Entropía significa el "alcance" de la distribución de acciones.
- ¡Parece que el juego ha valido la pena!

O no?
A veces, el agente se encuentra en un estado donde todas las acciones conducen a resultados negativos. A2C, sin embargo, hace frente a situaciones malas.


Cuando se puso el sol, Klyukovka reflexionó sobre el último conjunto de soluciones.

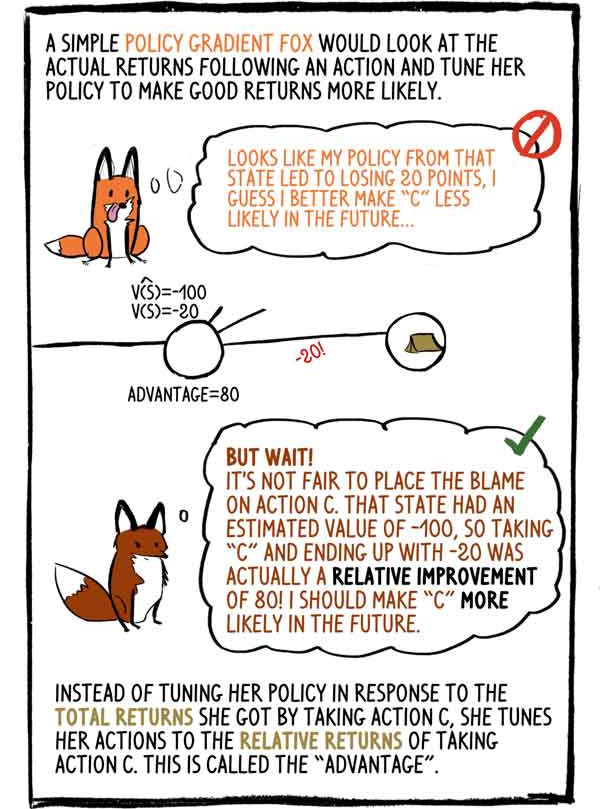
Hablamos sobre cómo Klyukovka configura su crítico interno. Pero, ¿cómo afina su "sujeto" interior? ¿Cómo aprende a tomar decisiones tan exquisitas?
La política de gradiente de zorro de mente simple miraría los ingresos reales después de la acción y ajustaría su política para hacer que los buenos ingresos sean más probables: - Parece que mi política en este estado condujo a una pérdida de 20 puntos, creo que en el futuro es mejor hacer "C" menos probable
- Pero espera! Es injusto culpar a la acción "C". Este estado tenía un valor estimado de -100, por lo que elegir "C" y terminar con -20 fue en realidad una mejora relativa de 80. Tengo que hacer que "C" sea más probable en el futuro.
En lugar de ajustar su política en respuesta a los ingresos totales que recibió al seleccionar la acción C, sintoniza su acción con los ingresos relativos de la acción C. Esto se denomina "ventaja".
Lo que llamamos una ventaja es simplemente un error. Como ventaja, Klukovka lo usa para hacer actividades que fueron sorprendentemente buenas, más probables. Como error, ella usa la misma cantidad para presionar a su crítico interno a mejorar su evaluación del valor del estado.
El sujeto aprovecha:
- "Wow, eso funcionó mejor de lo que pensaba, la acción C debe ser una buena idea".
El crítico usa el error:
“¿Pero por qué me sorprendió? Probablemente no debería haber evaluado esta condición tan negativamente ".
Ahora podemos mostrar cómo se calculan las pérdidas totales: minimizamos esta función para mejorar nuestro modelo.
"Pérdida total = pérdida de acción + pérdida de valor - entropía"
Tenga en cuenta que para calcular los gradientes de tres tipos cualitativamente diferentes, tomamos los valores "a través de uno". Esto es efectivo, pero puede dificultar la convergencia.

Como todos los animales, a medida que Klyukovka crezca, perfeccionará su capacidad de predecir los valores de los estados, ganará más confianza en sus acciones y, con menos frecuencia, se sorprenderá de los premios.
Los agentes de RL, como Klukovka, no solo generan todos los datos necesarios, simplemente interactúan con el entorno, sino que también evalúan las etiquetas de destino. Así es, los modelos RL actualizan las calificaciones anteriores para que coincidan mejor con las calificaciones nuevas y mejoradas.
Como dice el Dr. David Silver, jefe del grupo RL en Google Deepmind: AI = DL + RL. Cuando un agente como Klyukovka puede establecer su propia inteligencia, las posibilidades son infinitas ...
