Interfaz
En
el primer artículo , hemos mencionado que un método de acceso debe proporcionar información sobre sí mismo. Veamos la estructura de la interfaz del método de acceso.
Propiedades
Todas las propiedades de los métodos de acceso se almacenan en la tabla "pg_am" ("am" significa método de acceso). También podemos obtener una lista de métodos disponibles de esta misma tabla:
postgres=# select amname from pg_am;
amname -------- btree hash gist gin spgist brin (6 rows)
Aunque la exploración secuencial se puede referir legítimamente a métodos de acceso, no está en esta lista por razones históricas.
En PostgreSQL versiones 9.5 y anteriores, cada propiedad se representaba con un campo separado de la tabla "pg_am". A partir de la versión 9.6, las propiedades se consultan con funciones especiales y se separan en varias capas:
- Propiedades del método de acceso: "pg_indexam_has_property"
- Propiedades de un índice específico: "pg_index_has_property"
- Propiedades de columnas individuales del índice: "pg_index_column_has_property"
La capa del método de acceso y la capa de índice se separan con la vista puesta en el futuro: a partir de ahora, todos los índices basados en un método de acceso siempre tendrán las mismas propiedades.
Las siguientes cuatro propiedades son las del método de acceso (por un ejemplo de "btree"):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) from pg_am a, unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name) where a.amname = 'btree' order by a.amname;
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t (4 rows)
- can_order.
El método de acceso nos permite especificar el orden de clasificación de los valores cuando se crea un índice (hasta ahora solo se aplica a "btree"). - can_unique
Soporte de la restricción única y la clave primaria (solo aplicable a "btree"). - can_multi_col.
Se puede construir un índice en varias columnas. - puede_excluir
Soporte de la restricción de exclusión EXCLUDE.
Las siguientes propiedades pertenecen a un índice (consideremos uno existente por ejemplo):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name) from unnest(array[ 'clusterable','index_scan','bitmap_scan','backward_scan' ]) p(name);
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t (4 rows)
- agrupable
Una posibilidad de reordenar filas de acuerdo con el índice (agrupamiento con el comando CLUSTER del mismo nombre). - index_scan.
Soporte de escaneo de índice. Aunque esta propiedad puede parecer extraña, no todos los índices pueden devolver TID uno por uno; algunos devuelven todos los resultados de una vez y solo admiten la exploración de mapa de bits. - bitmap_scan.
Soporte de escaneo de mapa de bits. - backward_scan.
El resultado se puede devolver en el orden inverso al especificado al generar el índice.
Finalmente, las siguientes son propiedades de columna: postgres=# select p.name, pg_index_column_has_property('t_a_idx'::regclass,1,p.name) from unnest(array[ 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable', 'returnable','search_array','search_nulls' ]) p(name);
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t (9 rows)
- asc, desc, nulls_first, nulls_last, ordenable.
Estas propiedades están relacionadas con el orden de los valores (los discutiremos cuando lleguemos a una descripción de los índices "btree"). - distancia_orderable.
El resultado se puede devolver en el orden de clasificación determinado por la operación (hasta ahora solo se aplica a los índices GiST y RUM). - retornable
Una posibilidad de usar el índice sin acceder a la tabla, es decir, soporte de escaneos de solo índice. - search_array.
Soporte de búsqueda de varios valores con la expresión " indexed-field IN ( list_of_constants )", que es lo mismo que " indexed-field = ANY ( array_of_constants )". - search_nulls.
Posibilidad de buscar por condiciones IS NULL y IS NOT NULL.
Ya hemos discutido algunas de las propiedades en detalle. Algunas propiedades son específicas de ciertos métodos de acceso. Discutiremos tales propiedades cuando consideremos estos métodos específicos.
Clases de operador y familias
Además de las propiedades de un método de acceso expuesto por la interfaz descrita, se necesita información para saber qué tipos de datos y qué operadores acepta el método de acceso. Con este fin, PostgreSQL presenta los conceptos de
clase de operador y
familia de operadores .
Una clase de operador contiene un conjunto mínimo de operadores (y tal vez, funciones auxiliares) para que un índice manipule un determinado tipo de datos.
Se incluye una clase de operador en alguna familia de operadores. Además, una familia de operadores común puede contener varias clases de operadores si tienen la misma semántica. Por ejemplo, la familia "integer_ops" incluye las clases "int8_ops", "int4_ops" e "int2_ops" para los tipos "bigint", "integer" y "smallint", que tienen diferentes tamaños pero el mismo significado:
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'integer_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype -------------+----------+----------- integer_ops | int2_ops | smallint integer_ops | int4_ops | integer integer_ops | int8_ops | bigint (3 rows)
Otro ejemplo: la familia "datetime_ops" incluye clases de operador para manipular fechas (con y sin hora):
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'datetime_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype --------------+-----------------+----------------------------- datetime_ops | date_ops | date datetime_ops | timestamptz_ops | timestamp with time zone datetime_ops | timestamp_ops | timestamp without time zone (3 rows)
Una familia de operadores también puede incluir operadores adicionales para comparar valores de diferentes tipos. Agrupar en familias permite al planificador usar un índice para predicados con valores de diferentes tipos. Una familia también puede contener otras funciones auxiliares.
En la mayoría de los casos, no necesitamos saber nada sobre las familias y clases de operadores. Por lo general, solo creamos un índice, utilizando una determinada clase de operador de forma predeterminada.
Sin embargo, podemos especificar explícitamente la clase de operador. Este es un ejemplo simple de cuándo es necesaria la especificación explícita: en una base de datos con la clasificación diferente de C, un índice regular no admite la operación LIKE:
postgres=# show lc_collate;
lc_collate ------------- en_US.UTF-8 (1 row)
postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ----------------------------- Seq Scan on t Filter: (b ~~ 'A%'::text) (2 rows)
Podemos superar esta limitación creando un índice con la clase de operador "text_pattern_ops" (observe cómo ha cambiado la condición en el plan):
postgres=# create index on t(b text_pattern_ops); postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ---------------------------------------------------------------- Bitmap Heap Scan on t Filter: (b ~~ 'A%'::text) -> Bitmap Index Scan on t_b_idx1 Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text)) (4 rows)
Catálogo del sistema
En conclusión de este artículo, proporcionamos un diagrama simplificado de tablas en el catálogo del sistema que están directamente relacionadas con las clases y familias de operadores.
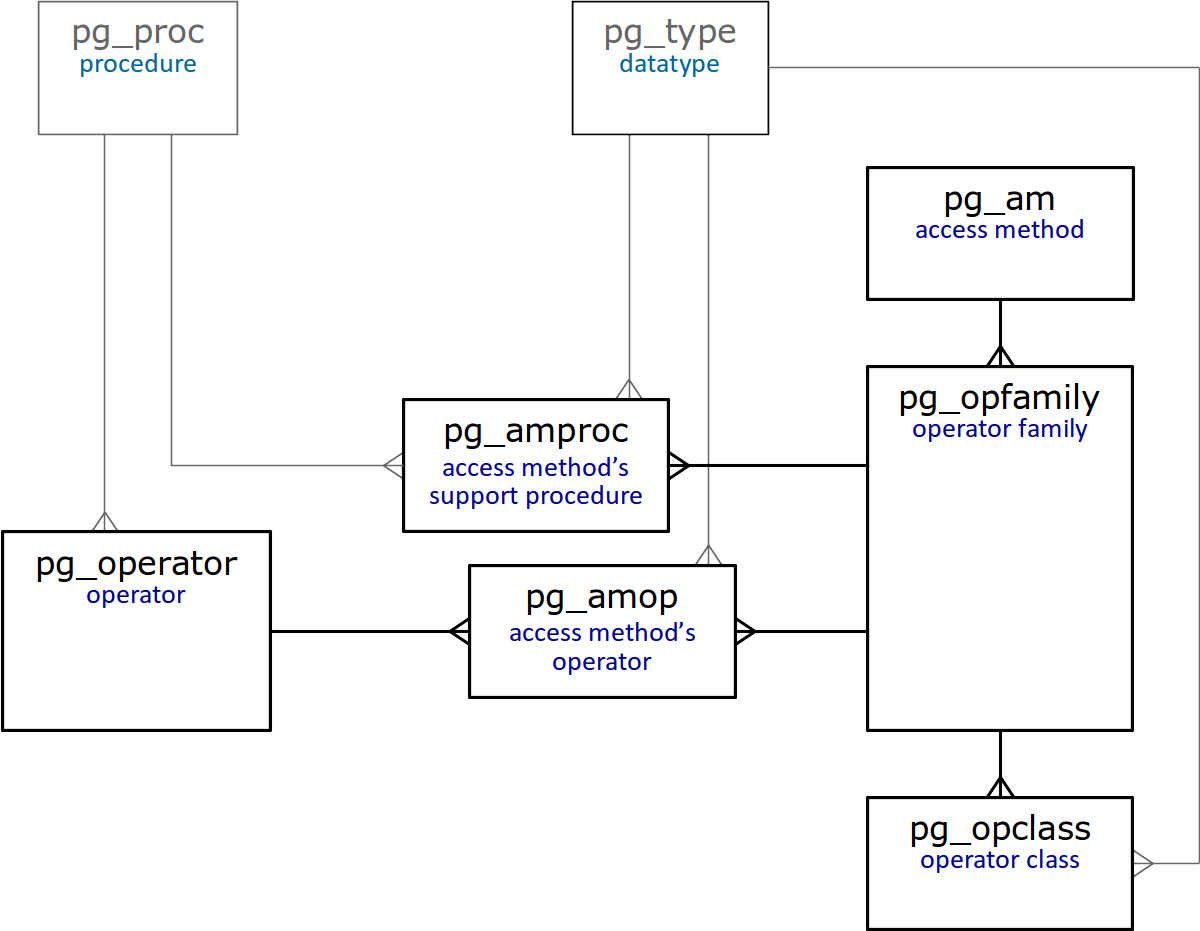
No hace falta decir que todas estas tablas
se describen en detalle .
El catálogo del sistema nos permite encontrar respuestas a una serie de preguntas sin consultar la documentación. Por ejemplo, ¿qué tipos de datos puede manipular un determinado método de acceso?
postgres=# select opcname, opcintype::regtype from pg_opclass where opcmethod = (select oid from pg_am where amname = 'btree') order by opcintype::regtype::text;
opcname | opcintype ---------------------+----------------------------- abstime_ops | abstime array_ops | anyarray enum_ops | anyenum ...
¿Qué operadores contiene una clase de operador (y, por lo tanto, el acceso al índice se puede usar para una condición que incluye dicho operador)?
postgres=# select amop.amopopr::regoperator from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'btree' and amop.amoplefttype = opc.opcintype;
amopopr ----------------------- <(anyarray,anyarray) <=(anyarray,anyarray) =(anyarray,anyarray) >=(anyarray,anyarray) >(anyarray,anyarray) (5 rows)
Sigue leyendo .