
Vivimos en un tiempo asombroso. A nuestro alrededor hay una abundancia de tecnología: teléfonos, computadoras, relojes inteligentes y otros dispositivos. Todos los días, los fabricantes lanzan cada vez más dispositivos al mercado. La mayoría de ellos están destinados a una vida corta y brillante (o no tan): una poderosa compañía de marketing en el momento del lanzamiento, 1-2 años de soporte completo por parte del fabricante y luego olvido lento. Los dispositivos simples pueden funcionar durante años después del final del período de soporte oficial. Con los dispositivos inteligentes, cada vez es más difícil. Es bueno si el gadget al menos continúa funcionando después de desconectar los servidores / servicios del fabricante. Y es una suerte que la próxima actualización del sistema operativo, los controladores u otro software no supere la compatibilidad.
Desafortunadamente, los eventos se desarrollan cada vez más de acuerdo con un escenario pesimista. Y entre 5 y 10 años después de la compra, tenemos dispositivos técnicamente sólidos en nuestras manos, que, sin embargo, no pueden utilizarse debido a la falta de soporte de software. Por supuesto, un dispositivo roto es desagradable. Pero mucho más desagradable si hay datos de usuario en un formato incompatible con cualquier cosa. Estos datos pueden considerarse perdidos si el dispositivo deja de funcionar. En mi caso, lo peor aún no ha sucedido, pero las alarmas ya están sonando.
Entonces, está la famosa empresa Korg, que produce equipos musicales de muy alta calidad. En 2010, compré un sintetizador de esta compañía para practicar música como hobby. La microestacion de Korg es un modelo bastante avanzado. Entre otras cosas, tiene un secuenciador integrado para grabar sus pistas y puede escribir datos en una tarjeta de memoria en el formato SNG patentado. Es posible exportar a un formato midi común, pero casi todos los metadatos se pierden: información sobre efectos y filtros superpuestos, diversas configuraciones de instrumentos virtuales, etc. El principal problema para mí personalmente es la velocidad de transición para grabar ideas musicales. La musa es una creación caprichosa, y la mayoría de las veces me encuentro con una idea interesante simplemente improvisando o tocando algo sin complicaciones. Cuanto más rápido presione el botón de grabación sin deambular por el menú, es más probable que pueda repetir y grabar un fragmento interesante, que en el futuro puede convertirse en parte de un trabajo completo. Por supuesto, este enfoque es imperfecto, pero estamos hablando de un pasatiempo. De una forma u otra, durante casi diez años, he acumulado alrededor de mil bocetos musicales y bocetos en formato SNG.
La campana sonó en forma de una serie de problemas técnicos del sintetizador, que requieren un parpadeo del dispositivo. Y pensé en convertir todos mis datos acumulados al formato Midi, más aún, ya que hará que sea mucho más fácil almacenarlos, organizarlos y editarlos. La búsqueda del convertidor en Google no dio nada. Hay muchas solicitudes en todo tipo de foros, la historia ha estado sucediendo durante 20 años, si no más. Todo lo que encontré fue la antigua utilidad de Windows de otra persona, naturalmente incompatible con mis archivos.
¿Y luego decidí tratar de ver de qué se trata este formato SNG? ¿Quizás en algún lugar dentro hay datos MIDI normales que puede extraer y guardar fácilmente?
Un intento de resolver el problema "frente"
Entonces, a partir de las instrucciones para el sintetizador, puede descubrir que el formato SNG es un contenedor en el que se almacenan las llamadas "canciones". Cada canción contiene 16 pistas de secuenciador con datos de música, así como configuraciones para sonidos y efectos. Al exportar a formato Midi a través del menú del sintetizador, cada "canción" se exporta a un archivo .MID separado, y se pierden todos los ajustes de sonidos y efectos. Porque Reproduzco mis ideas de la forma más simple y sin efectos, el problema es precisamente una gran cantidad de archivos SNG y las molestias del proceso de conversión manual. Veamos si este proceso puede ser acelerado o automatizado.
Primero, recordemos qué son los datos MIDI. En pocas palabras, esta es una secuencia de eventos musicales: presionar y soltar una tecla, presionar y soltar un pedal de sostenido, cambiar el tempo, el parche (instrumento virtual) y otros parámetros. Cada evento contiene un delta de tiempo desde el momento del evento anterior y datos, por ejemplo, intensidad de nota y tono. El formato de archivo midi es muy simple: además de los encabezados y los datos en sí, prácticamente no hay nada allí.
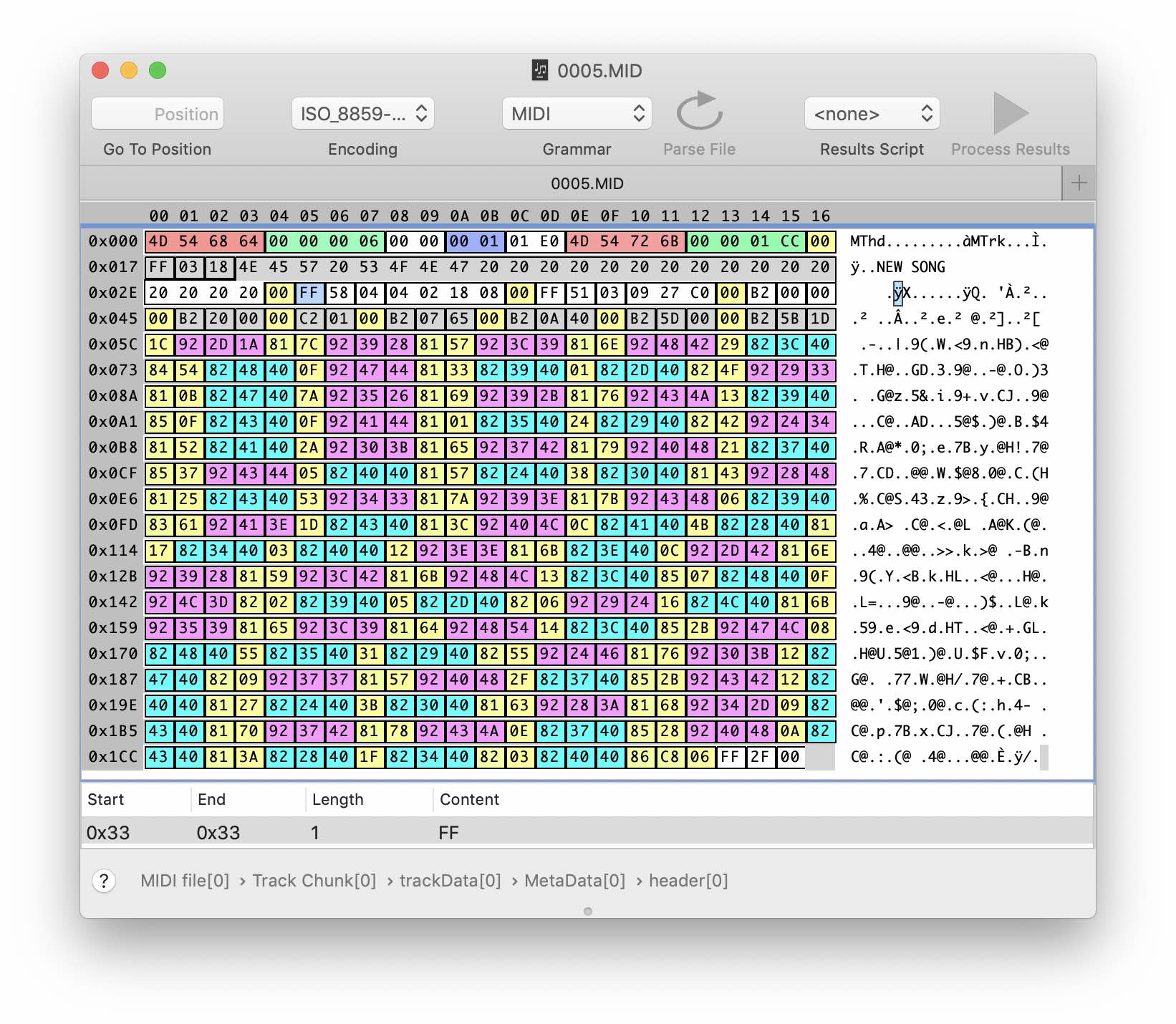 El rosa es una nota sobre el evento. El amarillo pálido es un delta del tiempo. Azul: evento Note Off.
El rosa es una nota sobre el evento. El amarillo pálido es un delta del tiempo. Azul: evento Note Off.Intentemos buscar nuestros datos midi en el archivo SNG. Para hacer esto, escriba una secuencia de varias notas en el sintetizador y expórtela a ambos formatos. Porque Como no sabemos dónde están exactamente los datos musicales en los archivos binarios, intentaremos repetir el proceso con diferentes secuencias de notas.
En lo sucesivo, uso el editor hexadecimal Synalyze It! Sus capacidades en el futuro nos serán muy útiles. Mientras tanto, solo use la función de comparación binaria.
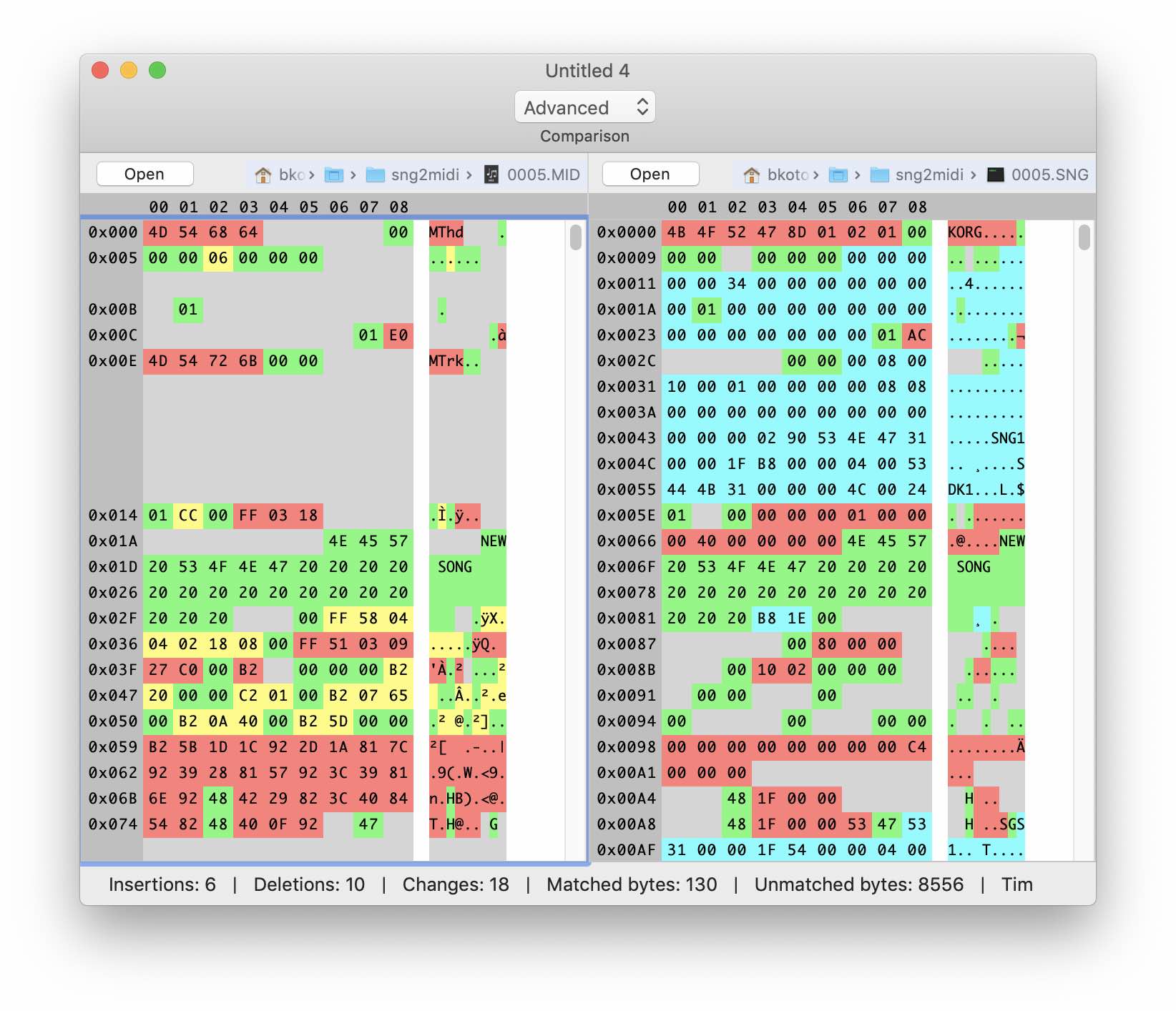
De hecho, solo el nombre de la "canción" coincidió. Comparando dos archivos SNG con diferentes secuencias de notas, podemos adivinar aproximadamente dónde se almacenan exactamente los datos musicales, pero por ahora esto no nos ayudará de ninguna manera: el formato de datos es diferente. El archivo en sí es diez veces más grande que el archivo Midi y parece contener mucha información adicional. Puede ver la firma KORG en los primeros cuatro bytes y algunas otras líneas, incluido el nombre de la "canción" y los nombres de los parches (tonos) asignados a las pistas.
Analizando la estructura de bloques de datos
Esto podría completarse si, afortunadamente, no hubiera herramientas que hicieran relativamente fácil analizar y comprender la estructura de los datos binarios. El mismo programa Synalaze It! Nos ayudará con esto, que le permite crear y aplicar una "gramática" para analizar archivos binarios.
La gramática es una estructura descriptiva jerárquica que le permite representar datos binarios en una forma legible para humanos. El programa te permite descargar gramática para algunos formatos. Por ejemplo, para el mismo midi:
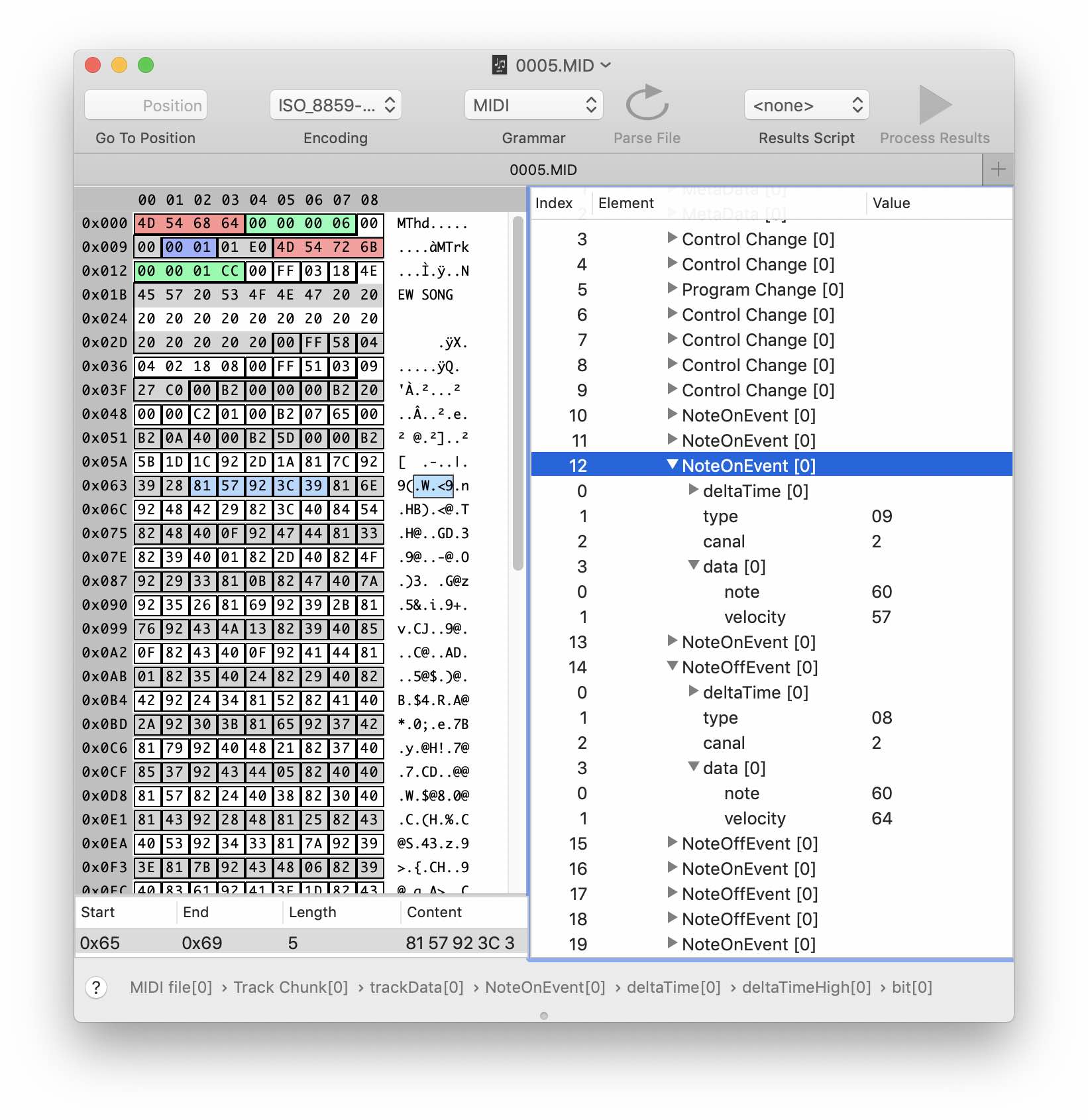
Para el formato SNG, no se esperaba una gramática preparada. Bueno, veamos qué podemos extraer del archivo por nuestra cuenta.
Comencemos con el titular. Por lo general, esta parte contiene la firma del archivo, la información de la versión, los tamaños y las compensaciones de los bloques de datos. Después de comparar varios archivos SNG diferentes, encontramos las partes invariables y prestamos más atención a las que cambian
Crea una estructura de título en el editor de gramática. Los primeros 4 bytes son obviamente la firma del archivo. Suponga que los siguientes 4 bytes están versionados. Las siguientes decenas de bytes no cambian y no contienen nada interesante: crearemos para ellos datos binarios del tamaño apropiado. Pero entonces comienza la diversión. Puede observar algunos patrones en el comportamiento de los bytes en las compensaciones 0x13 y 0x1b. El segundo parece corresponder al número de "canciones" en nuestro archivo. Y el primero también crece con la cantidad de datos en el encabezado: este parece ser el tamaño, solo la cuenta regresiva no proviene del comienzo del archivo, sino del siguiente byte 0x14. En esta etapa, solo podemos adivinar sobre el tipo de datos numéricos. Supongamos que el tamaño es del tipo UInt32, es decir Toma 4 bytes. Agréguelos a nuestra estructura. Ahora podemos establecer el tamaño de la estructura del encabezado (tamaño + 20).
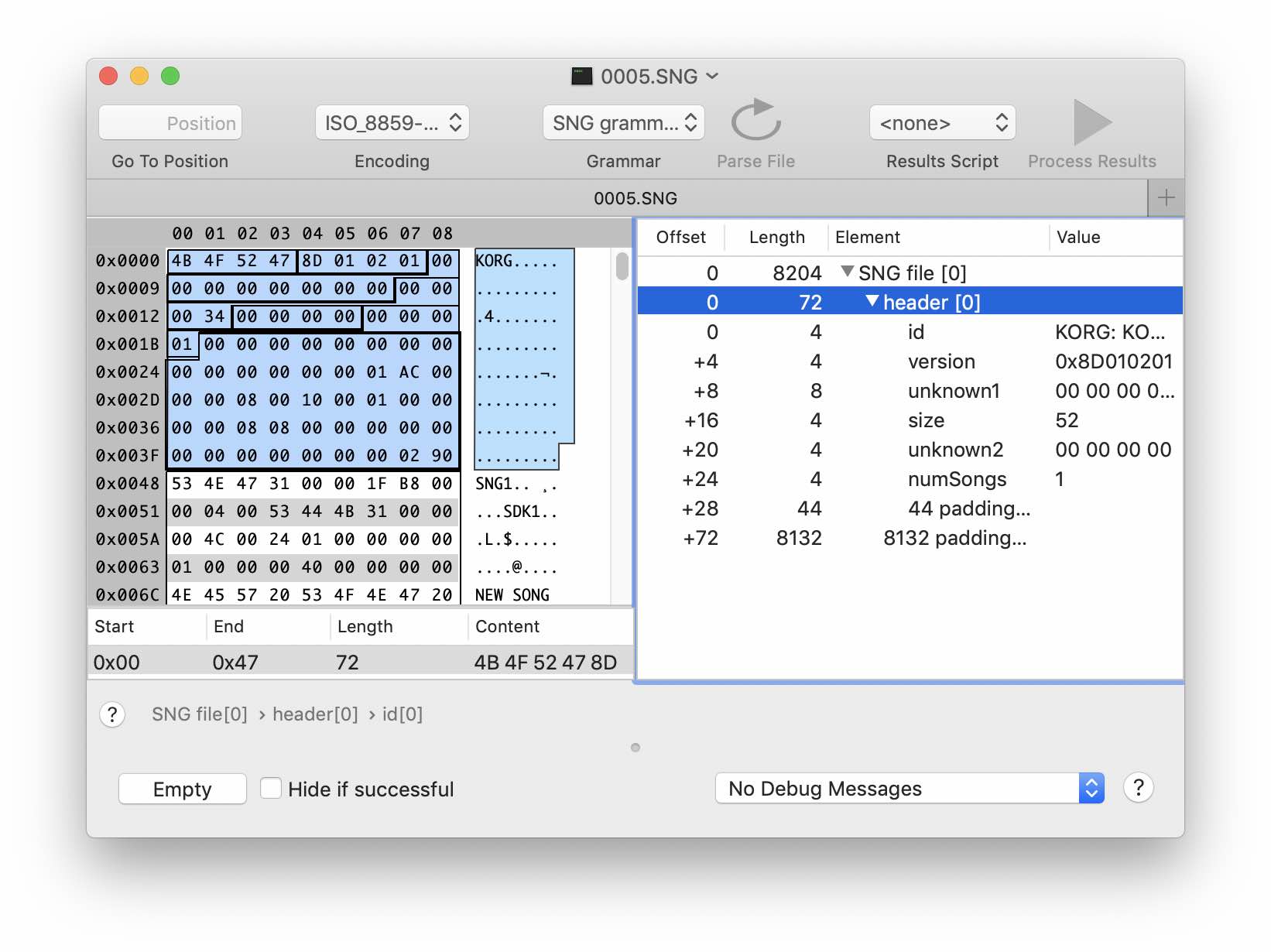
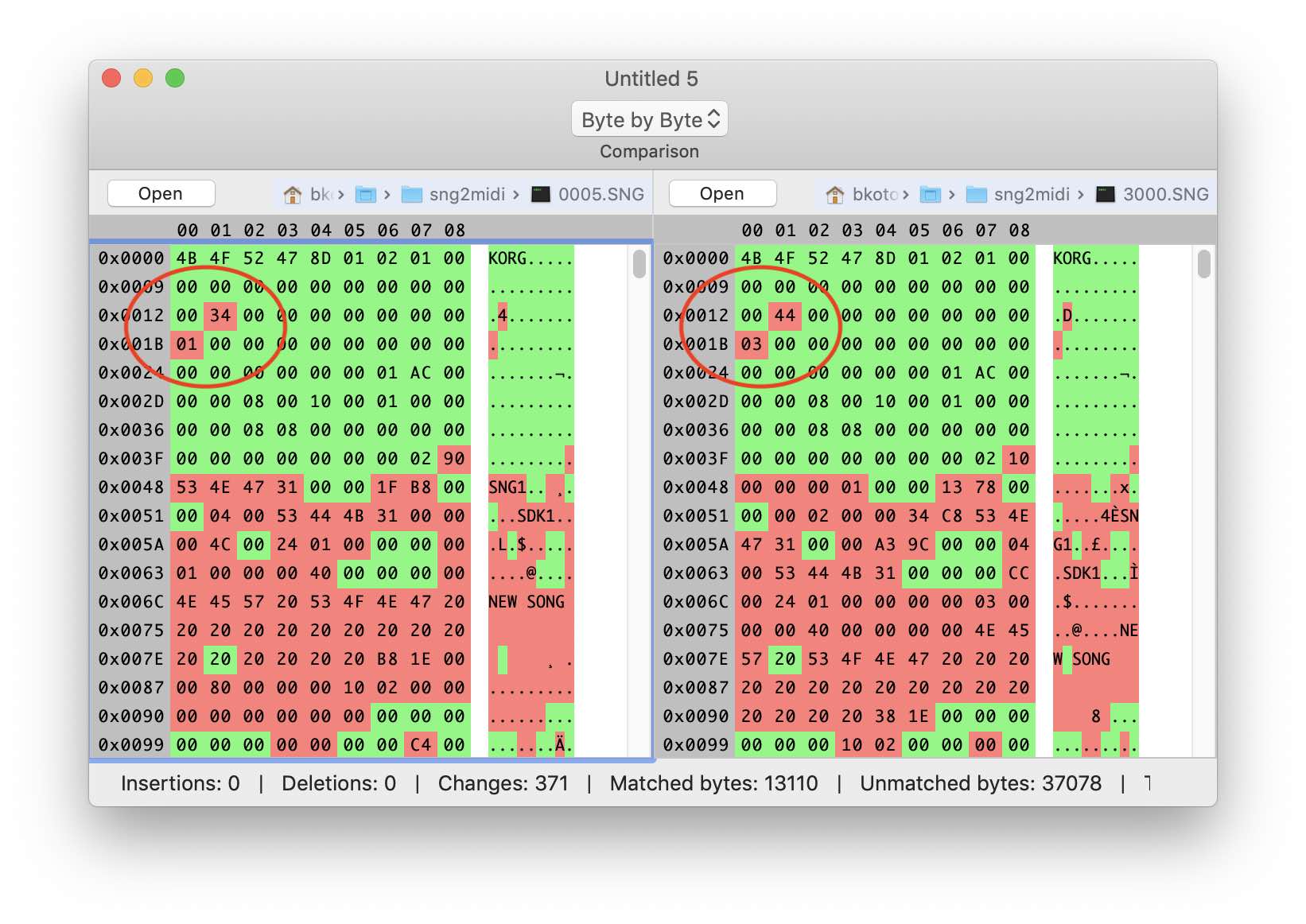
Gramática con estructura de encabezado de archivo agregada Veamos que viene después. Si observa detenidamente, notará que las abreviaturas de tres letras están dispersas por todo el archivo: SNG1, SDK1, SGS1, etc. Estos caracteres se encuentran en todos los archivos SNG, por lo que podemos suponer que son firmas de ciertos bloques. Además, nuestro título terminó con mucho éxito justo antes de una de estas firmas. Compare el comportamiento de los siguientes 4 bytes en archivos de diferentes tamaños. Se puede ver que los valores aumentan con la cantidad creciente de datos.
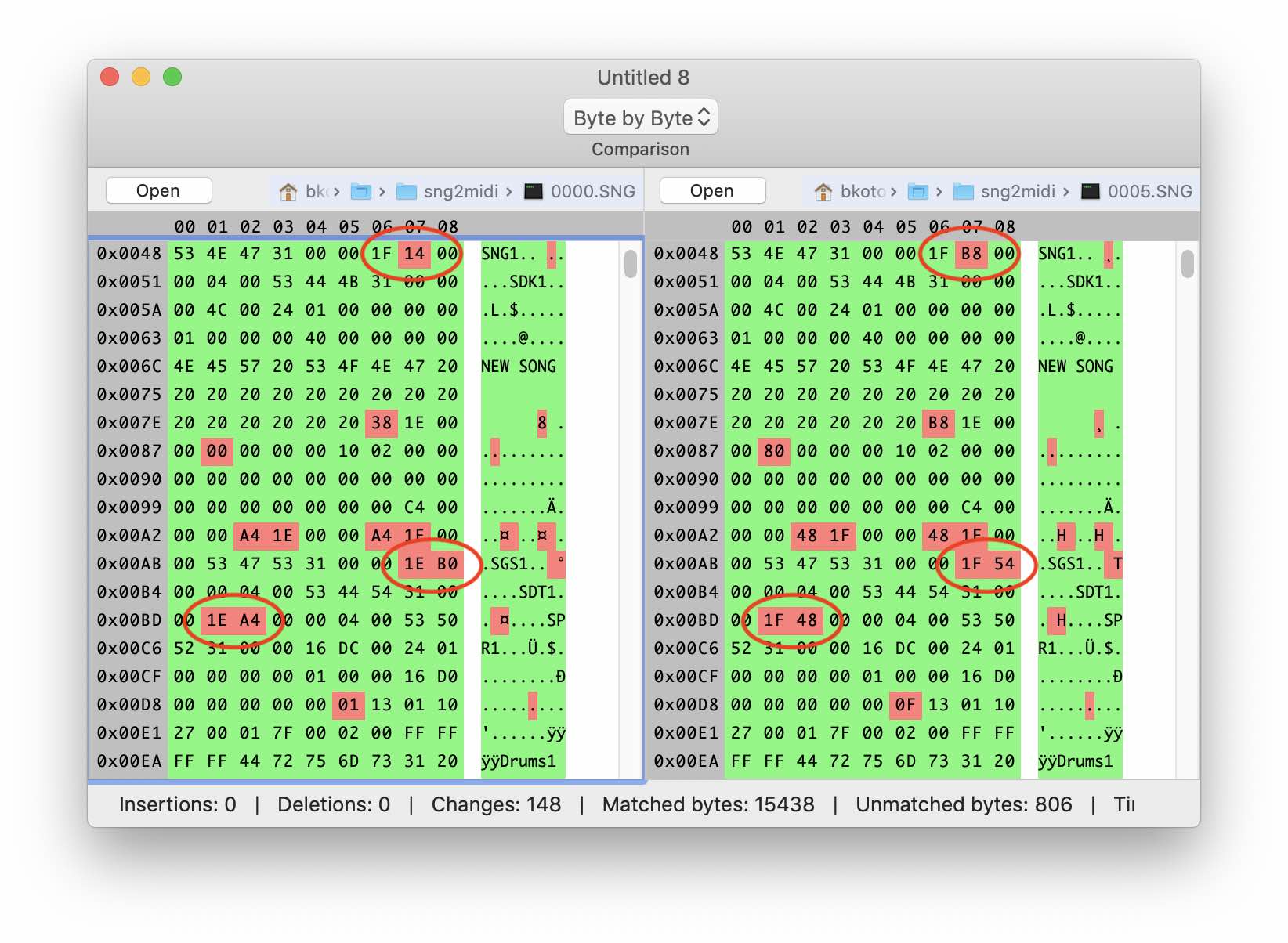
Algunos experimentos, análisis y cálculos más, y la siguiente imagen comienza a surgir:
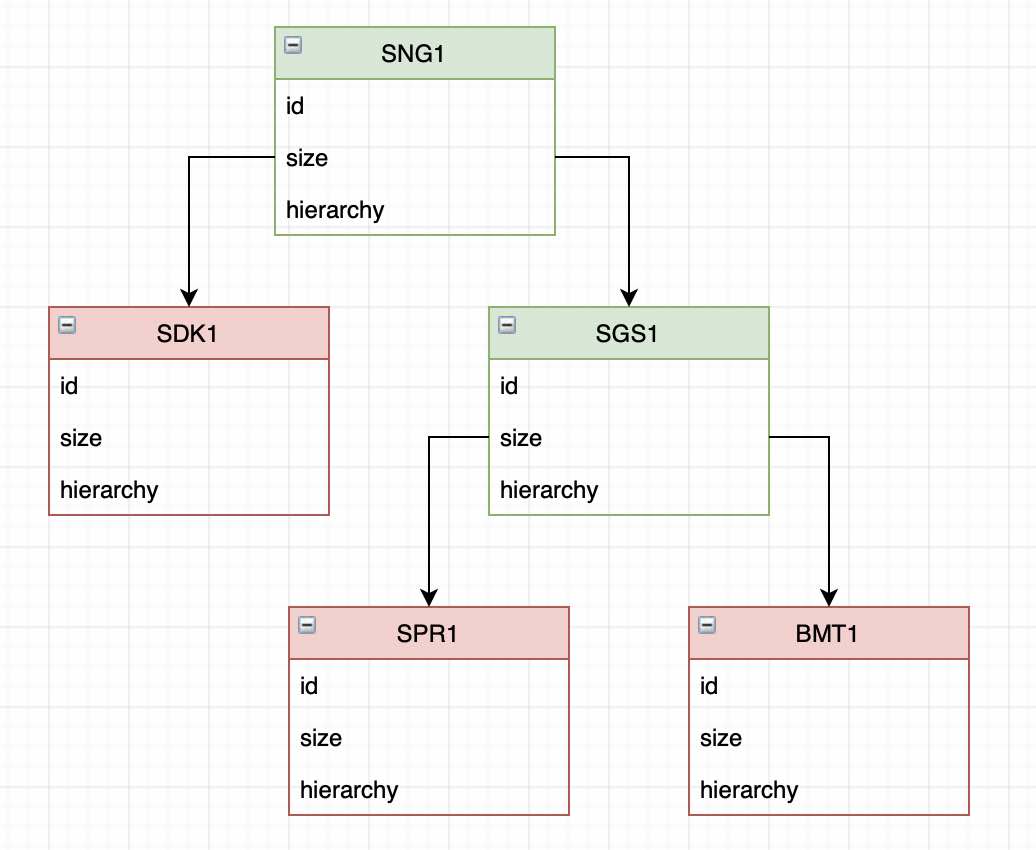
Vista alternativa del gráfico Por lo tanto, nuestro archivo consiste en una jerarquía de bloques bastante simple. Hay bloques principales que pueden contener múltiples bloques secundarios. Hay bloques de hojas (en la terminología de los árboles binarios) que no contienen otros bloques.
Entonces comienza la magia.
Con solo unas pocas estructuras gramaticales, podemos analizar completamente la estructura del archivo de bloquePor lo tanto, cree una estructura de plantilla DataChunk con los siguientes campos (el tamaño se indica entre corchetes):
id: cadena [4]
tamaño: Int [4]
jerarquía: Int [4]
datos: estructura
Ahora cree una estructura parentChunk que herede DataChunk. En la propiedad de la jerarquía, especifique el Valor fijo 0x400; este es un signo del bloque principal. Asegúrese de marcar la casilla Debe coincidir.
Del mismo modo, crea childChunk. La jerarquía en este caso tendrá dos valores: 0x240100 y 0x100
Agregue referencias a las estructuras parentChunk y childChunk a la estructura de datos parentChunk, de esta manera creamos recursividad.
Finalmente, agregue una referencia a la estructura parentChunk en el nodo principal.
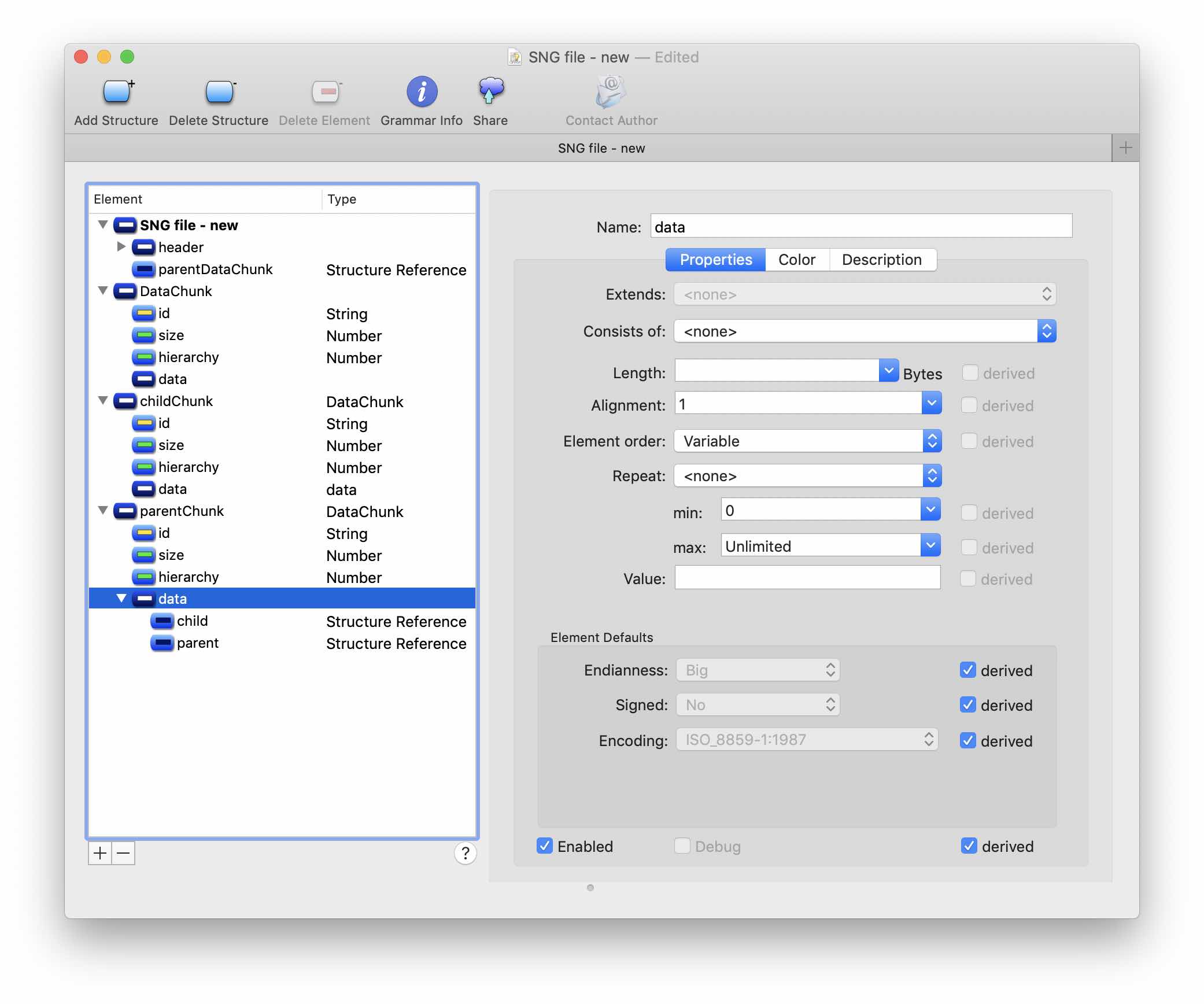
El orden de los elementos en la estructura de datos de parentChunk debe ser Variable, también es necesario establecer el número mínimo y máximo de elementos secundarios de esta estructura: 0 e Ilimitado, respectivamente.
Apliquemos los cambios y listo, nuestro archivo está muy bien analizado en los bloques principales.
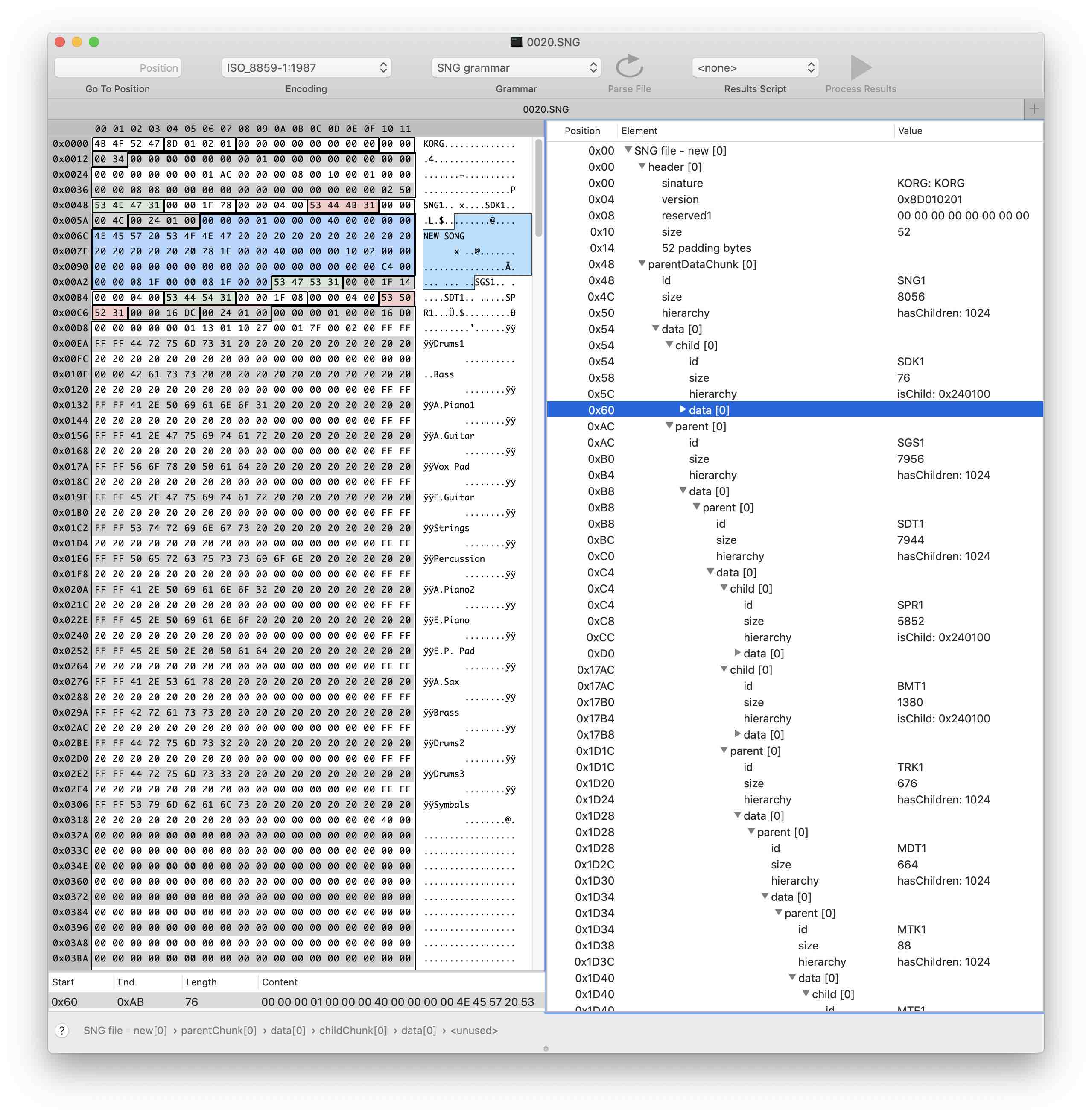
Todavía no sabemos nada sobre los datos en sí, pero ahora podemos navegar mucho más fácilmente en el archivo y centrarnos en encontrar la información que necesitamos.
Analizar un bloque que contiene una tabla de contenido de un archivo
Para el entrenamiento, intentemos analizar un bloque simple, por ejemplo, SDK1. Aparentemente, contiene algo así como una tabla de contenido: una lista de canciones y probablemente algunos desplazamientos / tamaños.
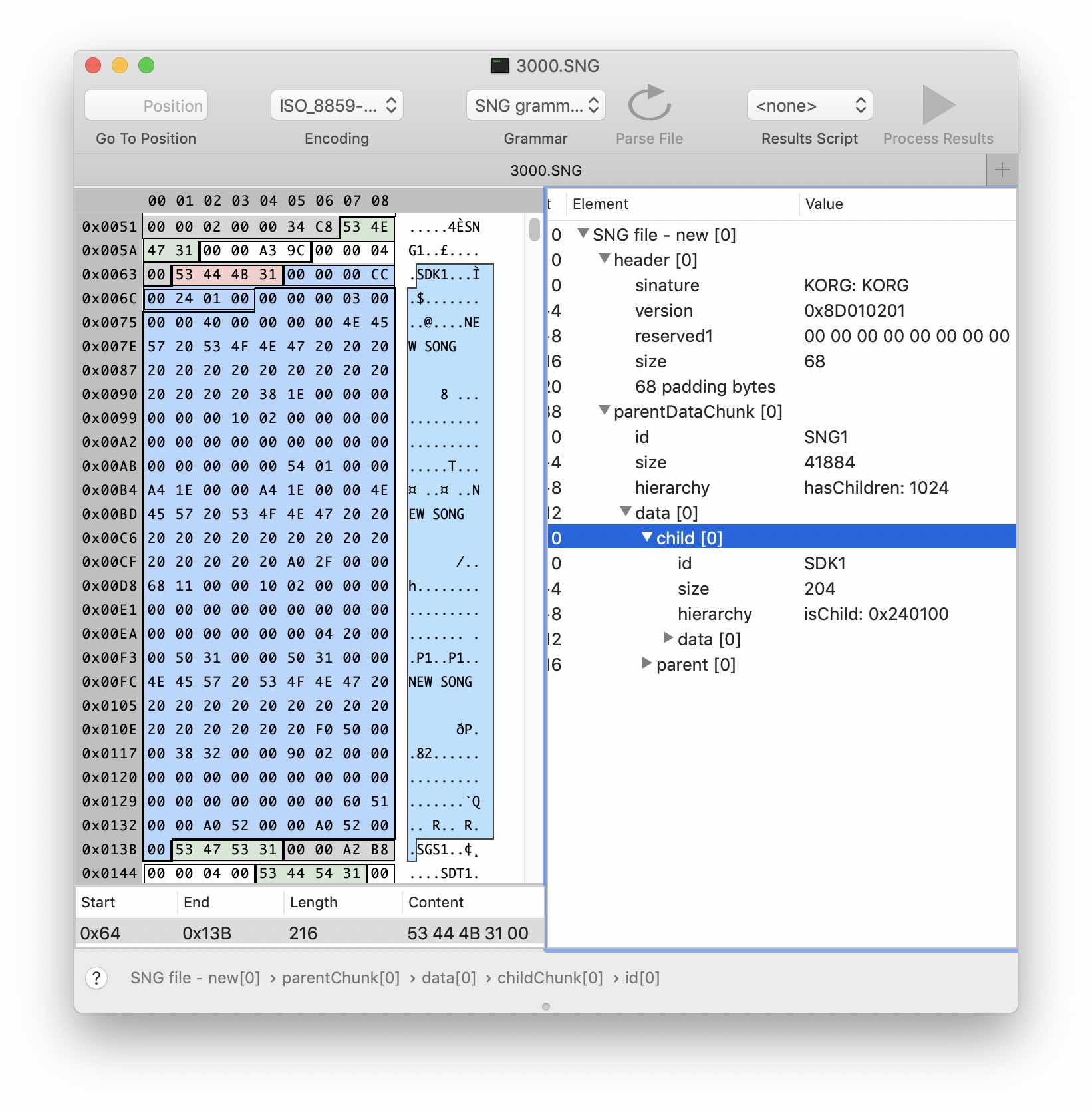
Cree una estructura sdk1Chunk que herede childChunk. Editaremos el campo ID, indicando la firma de nuestro bloque en el campo Valores fijos. No se olvide de la casilla de verificación Debe coincidir. En los datos del bloque, se puede observar un patrón repetitivo bastante obvio: el nombre de la "canción" y hasta ahora datos desconocidos. Tenga en cuenta que el tamaño de los fragmentos repetidos es de 64 bytes. Además, al comparar las versiones de archivo con un número diferente de "canciones", puede determinar que el número se almacena en los primeros cuatro bytes. Usando cálculos simples y haciendo varias suposiciones, obtenemos la siguiente versión de la estructura en la gramática:
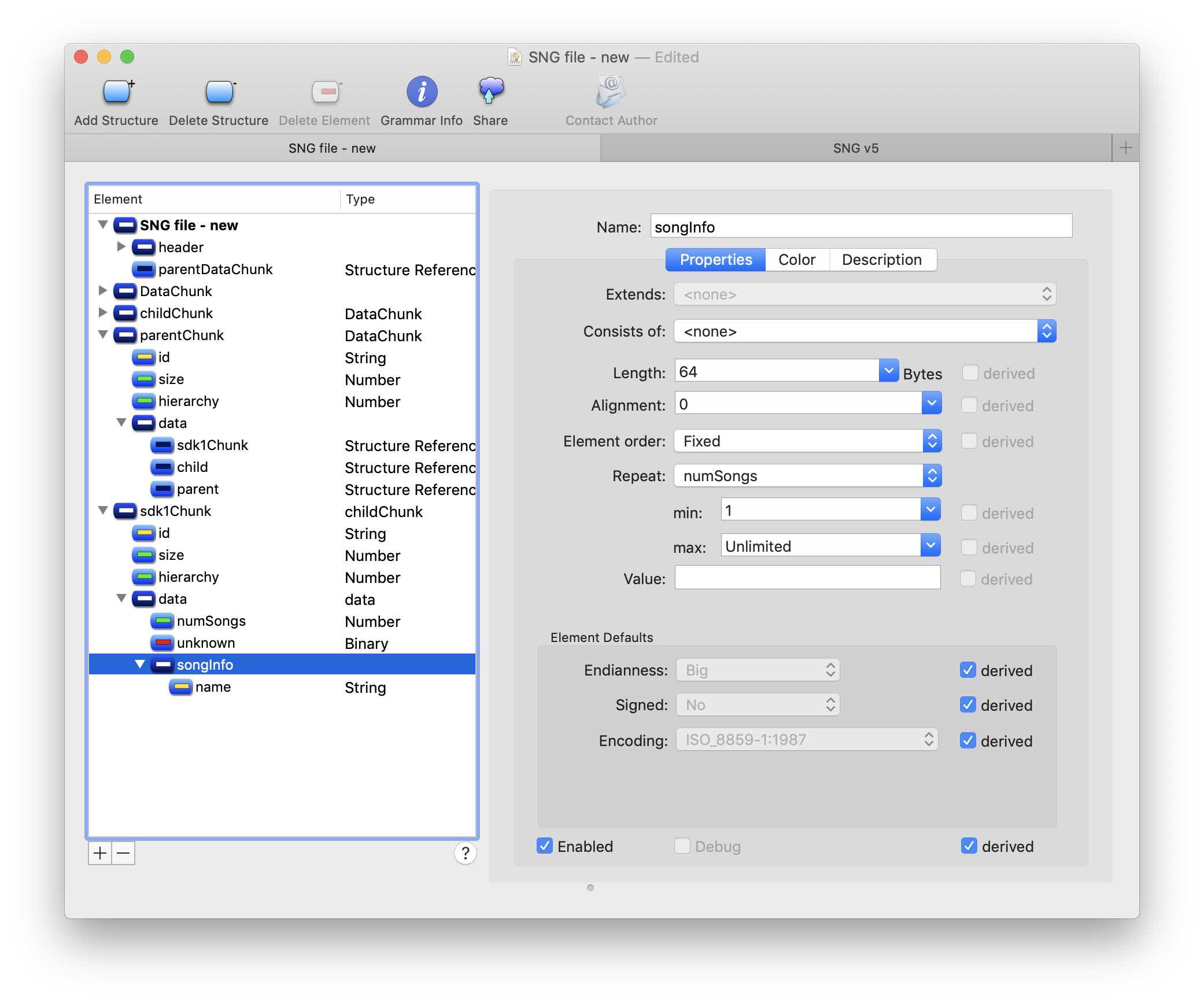
Aquí creé una estructura secundaria SongInfo de 64 bytes e indiqué la capacidad de repetir numSongs veces. Aquí está el resultado de aplicar la gramática:
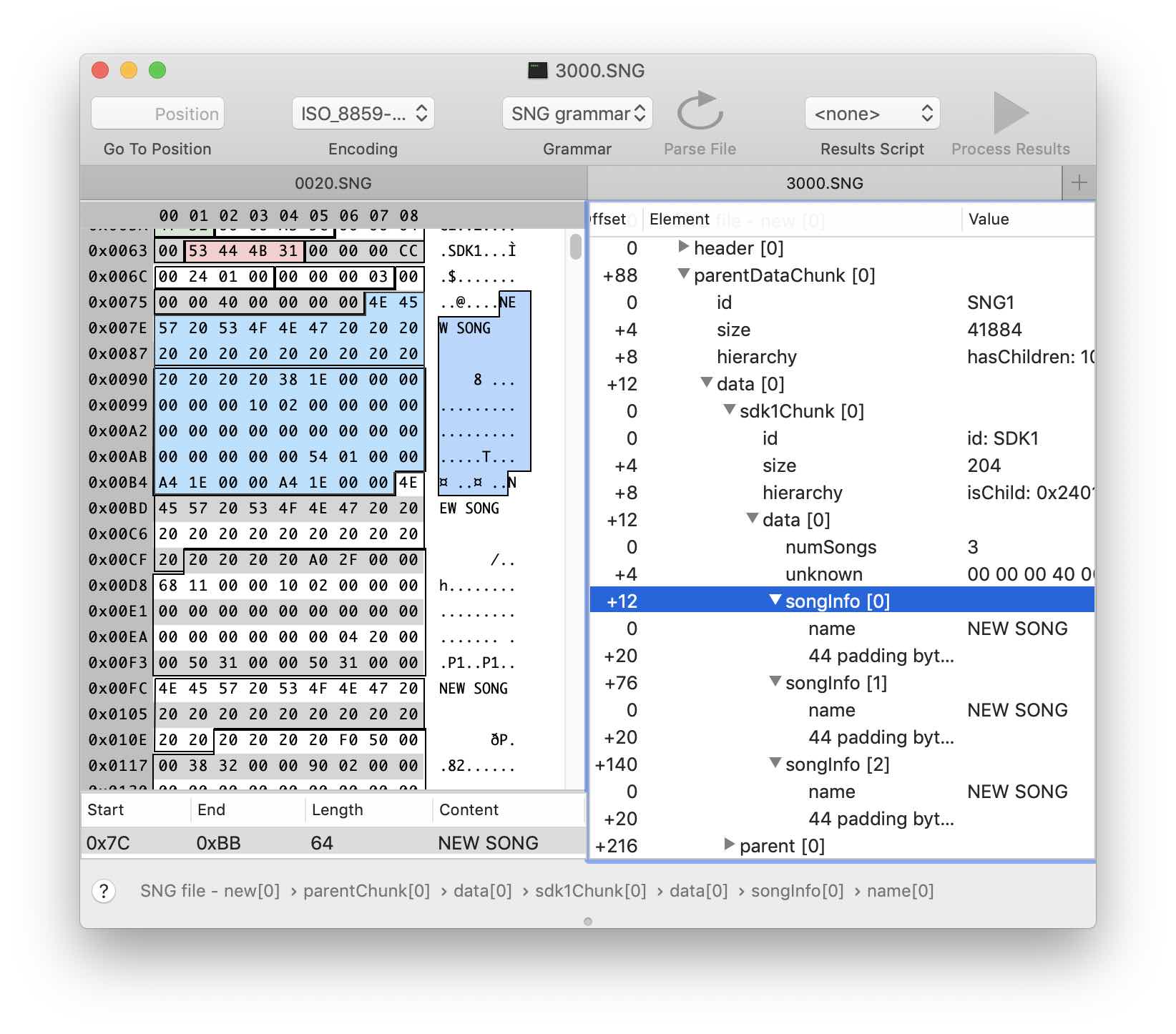
El análisis posterior de los archivos sigue siendo una cuestión técnica. Cambié la configuración general de la "canción" y los parámetros de pistas individuales en el sintetizador. Al comparar versiones de archivos con varios cambios, puede mejorar y refinar la gramática. Después de un número suficientemente grande de tales iteraciones, casi no hay datos no reconocidos en el archivo. Me dejé llevar por el proceso y resolví casi todas las secciones del archivo, aunque esto no era necesario para la tarea original.
Una pequeña porción de la gramática de un archivo SNG después de 8 horas de análisis Extrañaré los detalles de este proceso; en el futuro nos centraremos en el análisis de los datos musicales directamente.
Pero más sobre eso en la siguiente parte. Allí nos encontraremos con una tarea interesante de conversión de datos (es bastante adecuada para entrevistas), trataremos de resolverla con un pequeño script y escucharemos un resultado de conversión de prueba bastante inusual.
Resultados preliminares
La necesidad de ingeniería inversa de archivos binarios puede ocurrir inesperadamente. Por ejemplo, para analizar el firmware del dispositivo, convertir desde formatos de datos raros, analizar amenazas digitales o incluso modificar trivialmente los juegos guardados. Las herramientas modernas le permiten resolver estos problemas de forma rápida y eficiente. Hace unos 10 años, estaba investigando el firmware de la computadora portátil y este proceso podría llevar varias semanas. Luego se requería escribir scripts manualmente para analizar bloques de datos y diseñar estructuras. Con un nuevo enfoque parcialmente automatizado, creé una gramática de archivo casi completa en solo un par de días.
Puede comenzar el análisis del archivo binario buscando cadenas: pueden dar las primeras pistas y acelerar el proceso de análisis. A menudo, los archivos binarios consisten en bloques de datos que están organizados en una estructura jerárquica o lineal. Si trata con esta estructura, un análisis más detallado será mucho más fácil. El encabezado del archivo puede dar pistas sobre los desplazamientos / tamaños de los bloques de datos. En las primeras etapas, tiene sentido centrarse en la descripción de estructuras y bloques obvios. La tarea de análisis se simplifica enormemente por la capacidad de crear nuevas versiones de archivos con diferentes configuraciones, parámetros, datos. Hay una serie de dificultades asociadas con los tipos de datos desconocidos y el orden de los bytes en su representación binaria (Endianness). Nos referiremos a estas preguntas en la siguiente parte.
Lectura recomendada
Andreas Pehnack. Cómo abordar el análisis de formato de archivo binario