Cuando los participantes de
HighLoad ++ llegaron al informe de
Alexander Krasheninnikov , esperaban escuchar sobre el procesamiento de 1,600,000 eventos por segundo. Las expectativas no se hicieron realidad ... Debido a que durante la preparación para el rendimiento, esta cifra aumentó a
1.800.000 , por lo que, en HighLoad ++, la realidad supera las expectativas.
Hace 3 años, Alexander contó cómo construyeron un sistema de procesamiento de eventos escalable casi en tiempo real en Badoo. Desde entonces, ha evolucionado, los volúmenes han crecido en el proceso, fue necesario resolver los problemas de escala y tolerancia a fallas, y en algún momento se requirieron medidas radicales: un
cambio en la pila tecnológica .

A partir del descifrado, aprenderá cómo en Badoo reemplazó el paquete Spark + Hadoop con ClickHouse,
guardó el hardware 3 veces y aumentó la carga 6 veces , por qué y por qué medios recopilar estadísticas en el proyecto, y luego qué hacer con estos datos.
Sobre el orador: Alexander Krasheninnikov (
alexkrash ) - Jefe de Ingeniería de Datos en Badoo. Está involucrado en la infraestructura de BI, escalando las cargas de trabajo y administra los equipos que construyen la infraestructura de procesamiento de datos. Le encanta todo lo distribuido: Hadoop, Spark, ClickHouse. Estoy seguro de que se pueden preparar sistemas distribuidos geniales desde OpenSource.
Colección de estadísticas
Si no tenemos datos, estamos ciegos y no podemos administrar nuestro proyecto. Es por eso que necesitamos estadísticas, para
monitorear la viabilidad del proyecto. Nosotros, como ingenieros, deberíamos esforzarnos por mejorar nuestros productos y, si
lo desea, medirlo. Este es mi lema en el trabajo. En primer lugar, nuestro objetivo son los beneficios comerciales. Las estadísticas
proporcionan respuestas a preguntas comerciales . Las métricas técnicas son métricas técnicas, pero la empresa también está interesada en los indicadores, y también deben tenerse en cuenta.
Estadísticas del ciclo de vida
Defino el ciclo de vida de las estadísticas por 4 puntos, cada uno de los cuales discutiremos por separado.
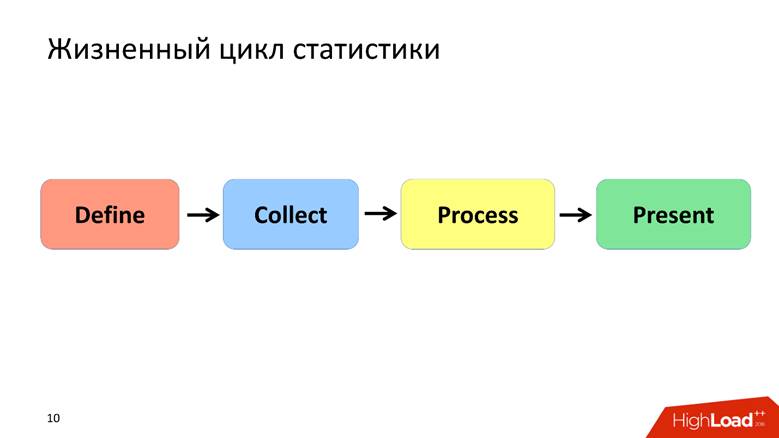
Definir Fase - Formalización
En la aplicación, recopilamos varias métricas. En primer lugar, estas son
métricas comerciales . Si tiene un servicio de fotografía, por ejemplo, se pregunta cuántas fotos se cargan por día, por hora, por segundo. Las siguientes métricas son
"semi-técnicas" : capacidad de respuesta de una aplicación móvil o sitio, trabajo de API, qué tan rápido interactúa un usuario con un sitio, instalación de la aplicación, UX.
El seguimiento del comportamiento del usuario es la tercera métrica importante. Estos son sistemas como Google Analytics y Yandex.Metrics. Tenemos nuestro propio sistema de seguimiento, en el que invertimos mucho.
En el proceso de trabajar con estadísticas, muchos usuarios están involucrados, estos son desarrolladores y análisis de negocios. Es importante que todos hablen el mismo idioma, por lo que debe estar de acuerdo.
Es posible negociar verbalmente, pero es mucho mejor cuando esto ocurre formalmente, en una estructura clara de eventos.
La formalización de la estructura de los eventos comerciales es cuando el desarrollador dice cuántos registros tenemos, el analista entiende que se le proporcionó información no solo sobre el número total de registros, sino también por país, género y otros parámetros. Y toda esta información está formalizada y es
de dominio público para todos los usuarios de la empresa . El evento tiene una estructura mecanografiada y una descripción formal. Por ejemplo, almacenamos esta información en formato
Protocol Buffers .
Descripción del evento "Registro":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
El evento de registro contiene información sobre el
usuario, el campo, la hora del evento y el
país de registro del usuario. Esta información está disponible para los analistas y, en el futuro, la empresa comprende lo que recopilamos.
¿Por qué necesito una descripción formal?
Una descripción formal es la
uniformidad para los desarrolladores, analistas y el departamento de productos. Entonces esta información impregna la descripción de la lógica empresarial de la aplicación. Por ejemplo, tenemos un sistema interno para describir los procesos comerciales y en él hay una pantalla con una nueva función.
En el
documento de requisitos del
producto hay una sección con las instrucciones de que cuando el usuario interactúa con la aplicación de esta manera, debemos enviar un evento con exactamente los mismos parámetros. Posteriormente, podremos validar qué tan bien funcionan nuestras características y que las medimos correctamente. Una descripción formal nos permite comprender mejor cómo guardar estos datos en una base de datos: NoSQL, SQL u otros. Tenemos
un esquema de datos , y eso es genial.
En algunos sistemas analíticos que se proporcionan como un servicio, solo hay 10-15 eventos en el almacenamiento secreto. En nuestro país, este número ha crecido más de 1000 y no va a detenerse;
es imposible vivir sin un solo registro .
Definir resumen de fase
Decidimos que las
estadísticas, esto es importante y
describimos un área temática determinada , es bueno, puedes seguir viviendo.
Fase de recopilación: recopilación de datos
Decidimos construir el sistema para que cuando ocurra un evento comercial (registro, envío de un mensaje, como) al mismo tiempo que guardamos esta información, enviemos por separado un determinado evento estadístico.
En el código, las estadísticas se envían simultáneamente con el evento comercial.
Se procesa de manera completamente independiente de los almacenes de datos en los que se ejecuta la aplicación, porque el
flujo de datos pasa a través de una tubería de procesamiento separada.Descripción a través de EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
Tenemos una descripción del evento de registro. Se genera automáticamente una API, accesible para los desarrolladores desde el código, que en 4 líneas le permite enviar estadísticas.
API basada en EDL:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
Entrega de eventos
Este es nuestro sistema externo. Hacemos esto porque tenemos servicios increíbles que proporcionan una API para trabajar con datos de fotos, sobre otra cosa. Todos almacenan datos en bases de datos novedosas, como Aerospike y CockroachDB.
Cuando necesita crear algún tipo de informe, no tiene que ir y luchar: "Chicos, ¿cuánto de esto tienen y cuánto?" - Todos los datos se envían en un flujo separado. Transportador de procesamiento - sistema externo. Desde el contexto de la aplicación, desatamos todos los datos del repositorio de lógica de negocios y los enviamos a una tubería separada.
La fase de recopilación supone la disponibilidad de servidores de aplicaciones. Tenemos este PHP.
Transporte
Este es un subsistema que nos permite enviar a otra tubería lo que hicimos desde el contexto de la aplicación. El transporte se selecciona únicamente según sus requisitos, según la situación del proyecto.
El transporte tiene características, y el primero son
las garantías de entrega. Características del transporte: al menos una vez, exactamente una vez, elige estadísticas para tus tareas, en función de la importancia de estos datos. Por ejemplo, para los sistemas de facturación es inaceptable que las estadísticas muestren más transacciones de las que hay; esto es dinero, no es posible.
El segundo parámetro son los
enlaces para lenguajes de programación. De alguna manera debemos interactuar con el transporte, por lo que se selecciona de acuerdo con el idioma en el que se escribe el proyecto.
El tercer parámetro es la
escalabilidad. Como estamos hablando de millones de eventos por segundo, sería bueno tener en cuenta la escalabilidad futura.
Hay muchas opciones de transporte: aplicaciones RDBMS, Flume, Kafka o LSD. Usamos
LSD , esta es nuestra forma especial.
Transmisión en vivo del demonio
El LSD no tiene nada que ver con sustancias prohibidas. Este es un
demonio de transmisión animado y muy rápido que no proporciona ningún agente para escribirle. Podemos ajustarlo, tenemos
integración con otros sistemas : HDFS, Kafka, podemos reorganizar los datos enviados. El LSD no tiene una llamada de red en INSERT, y puede controlar la topología de la red.
Lo más importante, este es
OpenSource de Badoo, no hay razón para no confiar en este software.
Si fuera un demonio perfecto, entonces, en lugar de Kafka, hablaríamos de LSD en cada conferencia, pero cada LSD tiene una mosca en la pomada. Tenemos nuestras propias limitaciones con las que nos sentimos cómodos:
no tenemos soporte de replicación en LSD y tiene
al menos una garantía de entrega. Además, para las transacciones de dinero, este no es el transporte más adecuado, pero generalmente necesita comunicarse con dinero exclusivamente a través de bases de datos "ácidas", que admiten
ACID .
Recopilar resumen de fase
Con base en los resultados de la serie anterior, recibimos una
descripción formal de los datos, generamos una
API excelente y conveniente
para los despachadores de eventos de ellos, y descubrimos cómo
transferir estos datos
desde el contexto de la aplicación a una tubería separada . Ya no está mal, y nos estamos acercando a la siguiente fase.
Proceso de fase: procesamiento de datos
Recopilamos datos de registros, subimos fotos, encuestas. ¿Qué hacer con todo esto? De estos datos queremos obtener
gráficos con una larga historia y
datos sin procesar . Los gráficos entienden todo: no es necesario ser un desarrollador para comprender desde la curva que los ingresos de la compañía están creciendo. Utilizamos datos en bruto para informes en línea y ad-hoc. Para casos más complejos, nuestros analistas desean realizar consultas analíticas sobre estos datos. Tanto eso como esa funcionalidad son necesarios para nosotros.
Gráficos
Los gráficos vienen en muchas formas.
O, por ejemplo, un gráfico con un historial que muestra datos de 10 años.
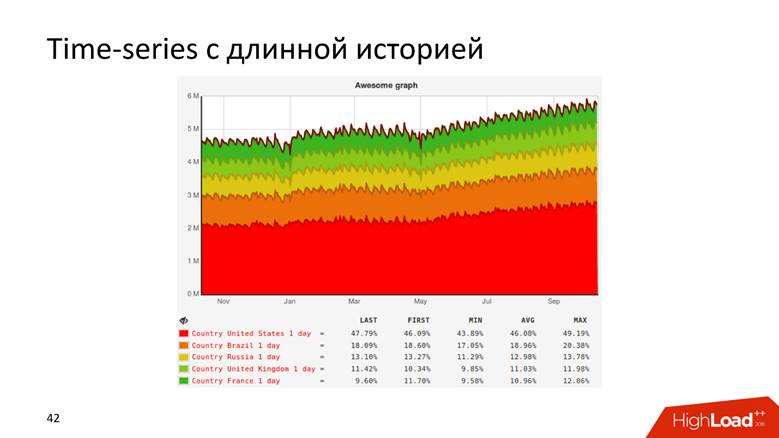
Los gráficos son incluso así.
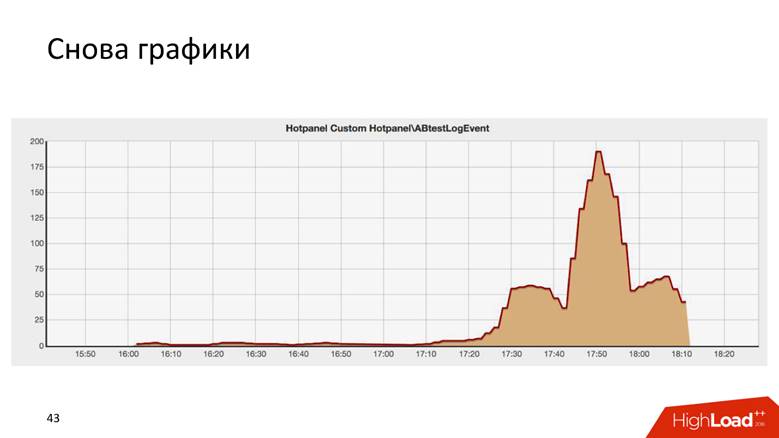
Este es el resultado de una prueba AB, y es sorprendentemente similar al edificio Chrysler en Nueva York.
Hay dos formas de dibujar un gráfico: una
consulta de datos en bruto y una
serie de tiempo . Ambos enfoques tienen desventajas y ventajas, que no analizaremos en detalle. Utilizamos un
enfoque híbrido : mantenemos una breve cola de datos sin procesar para informes operativos y series de tiempo para almacenamiento a largo plazo. El segundo se calcula a partir del primero.
Cómo hemos crecido a 1.8 millones de eventos por segundo
Es una larga historia: millones de RPS no suceden en un día. Badoo es una empresa con una década de historia, y podemos decir que el sistema de procesamiento de datos creció con la empresa.
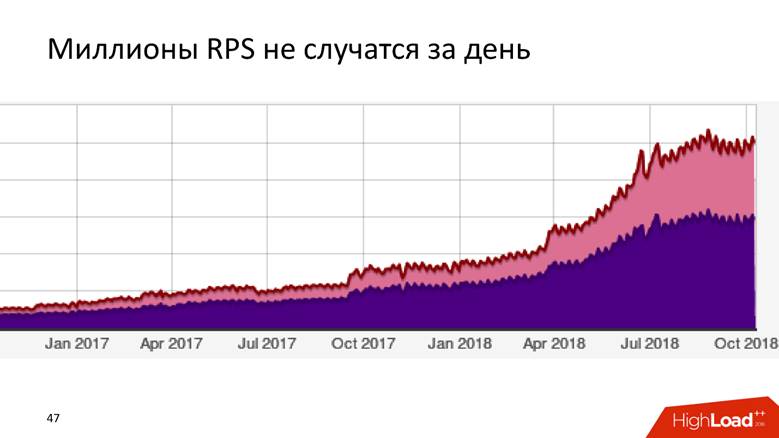
Al principio no teníamos nada. Comenzamos a recopilar datos: resultaron
5.000 eventos por segundo. ¡Un host MySQL y nada más! Cualquier DBMS relacional hará frente a esta tarea, y se sentirá cómodo con ella: tendrá transaccionalidad, ingresará los datos, recibirá solicitudes, todo funciona bien y bien. Entonces vivimos por un tiempo.
En algún momento, ocurrió el fragmentación funcional: datos de registro, aquí, y sobre fotos, allí. Así que vivimos hasta
200,000 eventos por segundo y comenzamos a usar varios enfoques combinados: para almacenar datos no brutos, sino
agregados , pero hasta ahora dentro de la base de datos relacional. Almacenamos contadores, pero la esencia de la mayoría de las bases de datos relacionales es tal que será imposible ejecutar una
consulta DISTINCT sobre estos datos: el modelo algebraico de contadores no permite calcular DISTINCT.
En Badoo tenemos el lema
"Fuerza imparable" . No íbamos a parar y crecimos más. En el momento en que cruzamos el umbral de
200,000 eventos por segundo , decidimos crear una descripción formal, de la que hablé anteriormente. Antes de eso, hubo un poco de caos, y ahora tenemos un registro estructurado de eventos: comenzamos a escalar el sistema,
conectamos Hadoop , todos los datos fueron a las
tablas de Hive.Hadoop es un gran paquete de software, sistema de archivos. Para la informática distribuida, Hadoop dice: "Ponga los datos aquí, le dejaré realizar consultas analíticas sobre ellos". Así lo hicimos, escribimos un
cálculo regular de todos los gráficos , resultó bien. Pero los gráficos son valiosos cuando se actualizan rápidamente: una vez al día, ver una actualización del gráfico no es tan divertido. Si lanzamos algo que conduce a un error fatal en la producción, nos gustaría ver que el gráfico caiga de inmediato, y no cada dos días. Por lo tanto, todo el sistema comenzó a degradarse después de un tiempo. Sin embargo, nos dimos cuenta de que en esta etapa, puede apegarse a la pila de tecnología seleccionada.
Para nosotros, Java era nuevo, nos gustó y entendimos lo que se podía hacer de manera diferente.
En la etapa de 400,000 a
800,000 eventos por segundo , reemplazamos a Hadoop en su forma más pura y Hive, como ejecutor de consultas analíticas, con
Spark Streaming , escribió un
mapa genérico / reducción y cálculo incremental de métricas. Hace 3 años
dije cómo lo hicimos. Entonces nos pareció que Spark viviría para siempre, pero la vida decretó lo contrario: nos encontramos con las limitaciones de Hadoop. Quizás si tuviéramos otras condiciones, seguiríamos viviendo con Hadoop.
Otro problema, además de calcular gráficos en Hadoop, fueron las increíbles consultas SQL de cuatro pisos que fueron conducidas por analistas, y los gráficos no se actualizaron rápidamente. El hecho es que hay un trabajo bastante complicado con el procesamiento de datos operativos, por lo que es en tiempo real, rápido y genial.
Badoo es atendido por dos centros de datos ubicados en dos lados del Océano Atlántico, en Europa y América del Norte. Para crear un informe unificado, debe enviar datos de América a Europa. Es en el centro de datos europeo donde guardamos todas las estadísticas estadísticas, porque hay más poder de cómputo.
Un recorrido de ida y vuelta entre centros de datos de aproximadamente
200 ms (la red es bastante delicada) no es lo mismo hacer una solicitud a otro DC que ir al siguiente rack.
Cuando comenzamos a formalizar eventos y desarrolladores, y los gerentes de producto se involucraron, a todos les gustó todo, solo hubo un
crecimiento explosivo de eventos . En este momento, era hora de comprar hierro en el clúster, pero realmente no queríamos hacer esto.
Cuando superamos el pico de
800,000 eventos por segundo , descubrimos lo que Yandex había subido a OpenSource
ClickHouse , y decidimos probarlo.
Llenaron un tren de conos mientras intentaban hacer algo, y como resultado, cuando todo funcionó, hicieron una pequeña recepción en el buffet sobre el primer millón de eventos. Probablemente, ClickHouse podría haber terminado el informe.
Solo toma ClickHouse y vive con él.
Pero esto no es interesante, por lo que continuaremos hablando sobre el procesamiento de datos.
Clickhouse
ClickHouse es una exageración de los últimos dos años y no necesita ser presentado: solo en HighLoad ++ en 2018 recuerdo
unos cinco informes al respecto, así como seminarios y reuniones.
Esta herramienta está diseñada para resolver exactamente las tareas que establecemos para nosotros mismos. Hay
actualizaciones y chips en
tiempo real que recibimos de Hadoop: replicación, fragmentación. No había razón para no probar ClickHouse, porque entendieron que con la implementación en Hadoop ya habíamos roto el fondo. La herramienta es genial, y la documentación generalmente es buena: escribí allí yo mismo, realmente me gusta todo, y todo es genial. Pero tuvimos que resolver una serie de problemas.
¿Cómo cambiar todo el flujo de eventos en ClickHouse? ¿Cómo combinar datos de dos centros de datos? Por el hecho de que acudimos a los administradores y les dijimos: "Chicos, vamos a instalar ClickHouse", no harán que la red sea dos veces más gruesa, y el retraso es la mitad. No, la red sigue siendo tan delgada y pequeña como el primer salario.
¿Cómo almacenar los resultados ? En Hadoop, entendimos cómo dibujar gráficos, pero ¿cómo hacerlo en el mágico ClickHouse? La varita mágica no está incluida.
¿Cómo entregar resultados al almacenamiento de series temporales?
Como dijo mi profesor en el instituto, considere 3 esquemas de datos: estratégico, lógico y físico.
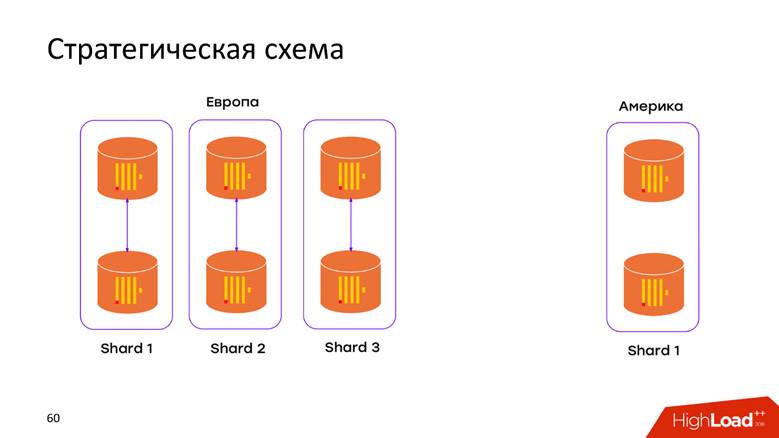
Esquema de almacenamiento estratégico
Tenemos
2 centros de datos . Aprendimos que ClickHouse no sabe nada sobre los DC, y acabamos de abrir el clúster en cada DC. Ahora los
datos no se mueven a través del cable cruzado del Atlántico : todos los datos que ocurrieron en el DC se almacenan localmente en su clúster. Cuando deseamos realizar una solicitud sobre los datos combinados, por ejemplo, para averiguar cuántos registros hay en ambos DC, ClickHouse nos brinda esta oportunidad. Baja latencia y disponibilidad para la solicitud, ¡solo una obra maestra!
Esquema de almacenamiento físico
Nuevamente, preguntas: ¿cómo caerán nuestros datos en el modelo relacional ClickHouse, qué se debe hacer para no perder replicación y fragmentación? Todo se describe ampliamente en la
documentación de ClickHouse , y si tiene más de un servidor, se encontrará con este artículo. Por lo tanto, no profundizaremos en lo que está en el manual: replicaciones, fragmentos y consultas a todos los datos en fragmentos.
Lógica de almacenamiento
El diagrama lógico es el más interesante. En una tubería procesamos eventos heterogéneos. Esto significa que tenemos una
secuencia de eventos heterogéneos : registro, voz, carga de fotos, métricas técnicas, seguimiento del comportamiento del usuario: todos estos eventos tienen
atributos completamente
diferentes . Por ejemplo, miré la pantalla en un teléfono móvil: necesito una identificación de pantalla, voté por alguien, debes entender si el voto fue a favor o en contra. Todos estos eventos tienen diferentes atributos, se dibujan diferentes gráficos en ellos, pero todo esto debe procesarse en una sola tubería. ¿Cómo ponerlo en el modelo ClickHouse?
Enfoque n. ° 1: por tabla de eventos. Este primer enfoque, extrapolamos de la experiencia adquirida con MySQL: creamos una
tableta para cada evento en ClickHouse. Suena bastante lógico, pero nos encontramos con una serie de dificultades.
No tenemos restricciones de que el evento cambie su estructura cuando se publique la compilación de hoy. Este parche puede ser realizado por cualquier desarrollador. El esquema generalmente es mutable en todas las direcciones. El único
campo requerido es el
evento de marca de tiempo y cuál fue el evento. Todo lo demás cambia sobre la marcha y, en consecuencia, estas placas deben modificarse. ClickHouse tiene la capacidad de realizar
ALTER en un clúster , pero este es un procedimiento delicado y delicado que es difícil de automatizar para que funcione sin problemas. Por lo tanto, esto es un menos.
Tenemos más de mil eventos diferentes, lo que nos da una
alta tasa de INSERTAR por máquina : registramos constantemente todos los datos en mil tablas. Para ClickHouse, este es un antipatrón. Si Pepsi tiene el eslogan: "Vive en grandes sorbos", entonces ClickHouse:
"Vive en grandes lotes" . Si esto no se hace, entonces la replicación se ahoga, ClickHouse se niega a aceptar nuevas inserciones, un esquema desagradable.
Enfoque n. ° 2: una mesa amplia . Los hombres siberianos intentaron deslizar la motosierra en el riel y aplicar un modelo de datos diferente. Hacemos una tabla con
mil columnas , donde cada evento tiene columnas reservadas para sus datos. Obtenemos una gran
tabla dispersa ; afortunadamente, esto no fue más allá del entorno de desarrollo, porque desde los primeros insertos quedó claro que el esquema es absolutamente malo, y no lo haremos.
Pero aún así quiero usar un producto de software tan genial, un poco más para terminar, y será lo que necesita.
Enfoque n. ° 3: tabla genérica. Tenemos una gran tabla en la que almacenamos datos en matrices, porque ClickHouse admite
tipos de datos no escalares . Es decir, comenzamos una columna en la que se almacenan los nombres de los atributos, y una columna separada con una matriz en la que se almacenan los valores de los atributos.
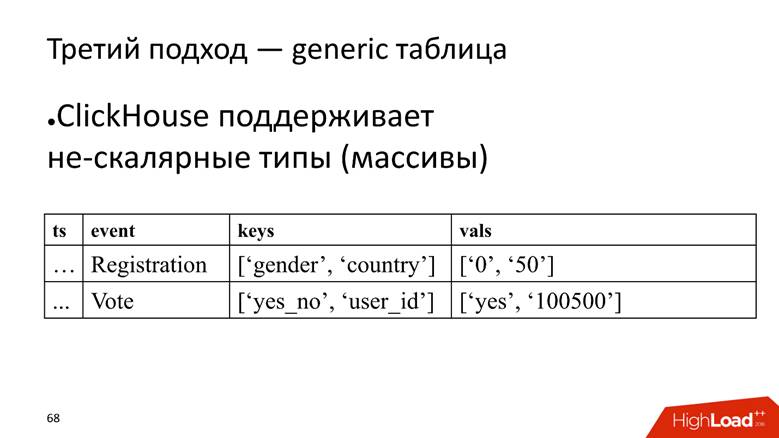
ClickHouse aquí realiza su tarea muy bien. Si solo tuviéramos que insertar datos, probablemente exprimiríamos 10 veces más en la instalación actual.
Sin embargo, la mosca en la pomada es que también es un antipatrón para ClickHouse,
para almacenar matrices de cadenas . Esto es malo porque las matrices de filas
ocupan más espacio en disco : se reducen peor que las columnas simples y son
más difíciles de procesar . Pero para nuestra tarea, cerramos los ojos a esto, ya que las ventajas son mayores.
¿Cómo hacer SELECCIONAR de tal tabla? Nuestra tarea es contar los registros agrupados por género. Primero necesita encontrar en una matriz qué posición corresponde a la columna de género, luego subir a otra columna con este índice y obtener los datos.
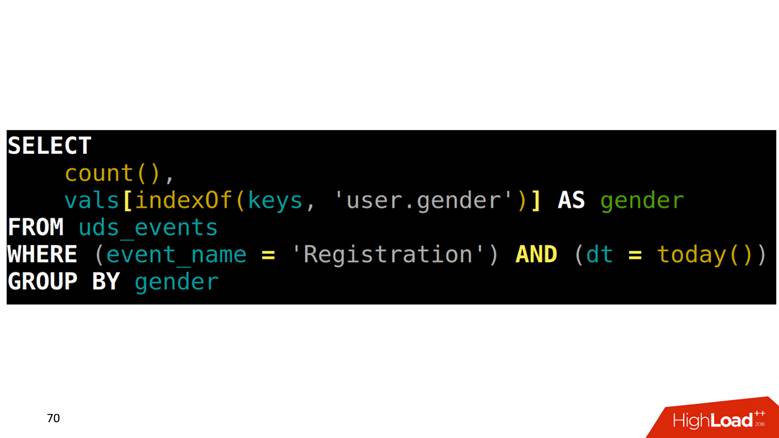
Cómo dibujar gráficos en estos datos
Como se describen todos los eventos, tienen una estructura estricta, formamos una consulta SQL de cuatro pisos para cada tipo de evento, la ejecutamos y guardamos los resultados en otra tabla.
El problema es que para dibujar dos puntos adyacentes en el gráfico, debe
escanear toda la tabla . Ejemplo: nos fijamos en el registro por día. Este evento es desde la línea superior hasta la penúltima. Escaneado una vez, excelente. Después de 5 minutos, queremos dibujar un nuevo punto en el gráfico; nuevamente, escaneamos el rango de datos que se cruza con el escaneo anterior, y así sucesivamente para cada evento. Suena lógico, pero no se ve muy bien.
Además, cuando tomamos algunas líneas, también necesitamos
leer los resultados bajo agregación . Por ejemplo, hay un hecho de que el siervo de Dios estaba registrado en Escandinavia y era un hombre, y necesitamos calcular las estadísticas resumidas: cuántos registros, cuántos hombres, cuántos de ellos son personas y cuántos son de Noruega. Esto se llama en términos de las bases de datos analíticas
ROLLUP, CUBE y
GROUPING SETS : convierte una línea en varias.
Como tratar
Afortunadamente, ClickHouse tiene una herramienta para resolver este problema, a saber, el
estado serializado de las funciones agregadas . Esto significa que puede escanear un dato una vez y guardar estos resultados. Esta es una
característica asesina . Hace 3 años hicimos exactamente esto en Spark y Hadoop, y es genial que en paralelo con nosotros, las mejores mentes de Yandex implementaron un análogo en ClickHouse.
Solicitud lenta
Tenemos una solicitud lenta: contar usuarios únicos para hoy y ayer.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
En el plano físico, podemos hacer SELECCIONAR para el estado de ayer, obtener su representación binaria, guardarla en algún lugar.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
Por hoy, solo cambiamos la condición de que será hoy:
'yyy' AS ts y
WHERE dt = today() y marca de tiempo llamaremos “xxx” y “aaa”. , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
8 ClickHouse , 6 - , 2 : 2 — , .
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
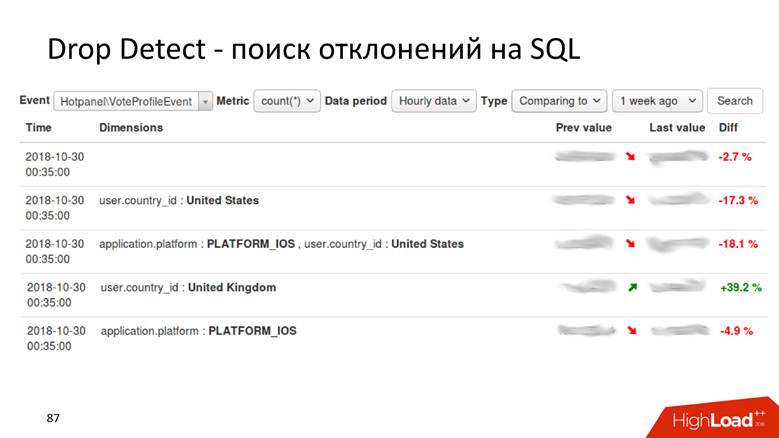
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
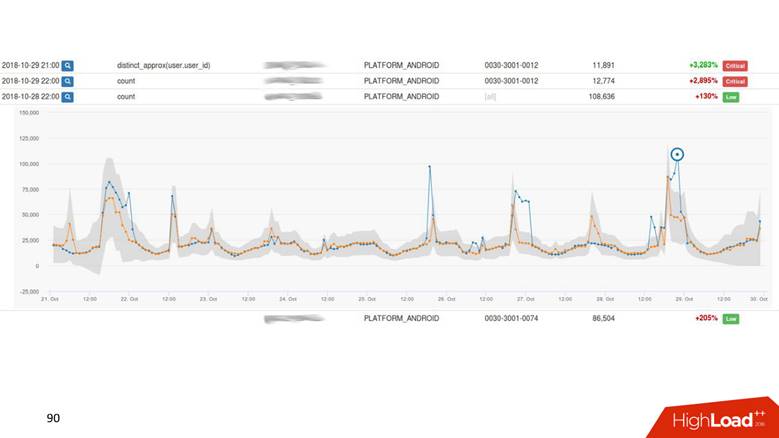
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .