Introduccion
Netcracker es una compañía internacional que desarrolla soluciones complejas de TI, que incluyen servicios de alojamiento y soporte para equipos de clientes, así como el sistema de TI creado para operadores de telecomunicaciones.
Estas son principalmente decisiones relacionadas con la organización de las actividades operativas y comerciales de los operadores de telecomunicaciones. Más detalles se pueden encontrar
aquí .
La disponibilidad continua de la solución que se está desarrollando es muy importante. Si el operador de telecomunicaciones deja de trabajar durante al menos una hora, esto generará grandes pérdidas financieras y de reputación tanto para el operador como para el proveedor de software. Por lo tanto, uno de los requisitos clave para la solución es el parámetro de
disponibilidad , cuyo valor varía de 99.995% a 99.95%, dependiendo del tipo de solución.
La solución en sí misma es un conjunto complejo de sistemas informáticos monolíticos centrales, que incluyen equipos de telecomunicaciones complejos y software de servicio ubicado en una nube pública, así como muchos microservicios integrados con un núcleo central.
Por lo tanto, es muy importante para el equipo de soporte monitorear todos los sistemas de hardware y software integrados en una única solución. En la mayoría de los casos, la compañía usa monitoreo tradicional. Este proceso está bien establecido: podemos construir un sistema de monitoreo similar desde cero y sabemos cómo organizar adecuadamente los procesos de respuesta a incidentes. Sin embargo, hay varias dificultades en este enfoque que enfrentamos de un proyecto a otro.
- Que monitorear
¿Qué métrica es actualmente importante y cuál será importante en el futuro? No hay una respuesta definitiva aquí, así que tratamos de monitorear todo . Dificultad número uno: la cantidad de métricas. Hay problemas de rendimiento, los paneles operativos se parecen cada vez más a un panel de control de una nave espacial.
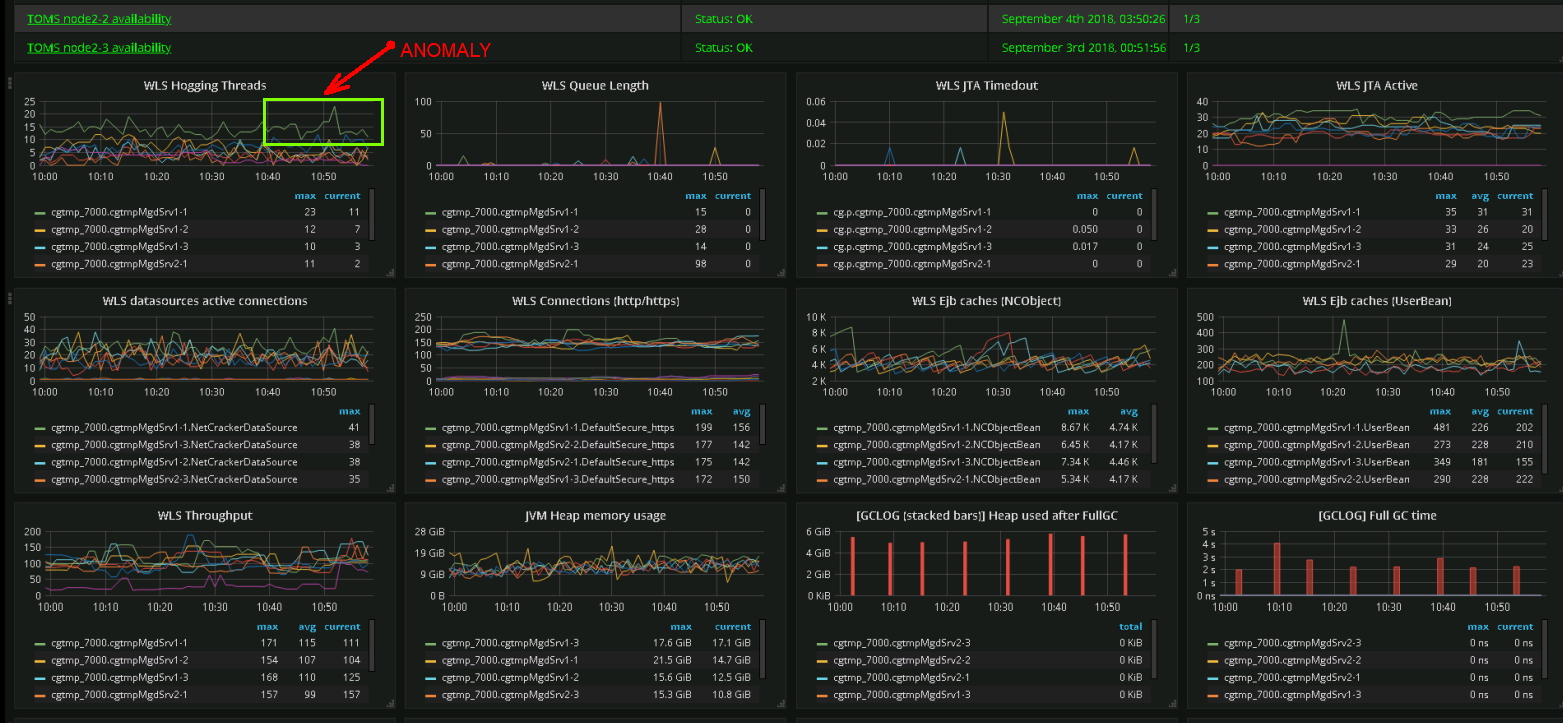
Captura de pantalla de un tablero real. Los ingenieros del equipo de soporte pueden identificar anomalías en el comportamiento del sistema en función de su representación gráfica
- Alerta / umbral
A pesar del hecho de que tenemos experiencia en la operación de muchos sistemas grandes, monitorearlos sigue siendo una tarea difícil debido a los detalles del equipo utilizado y las versiones de software de varios proveedores. La experiencia y las reglas preparadas a menudo no se pueden transferir completamente de una solución a otra. Existe un conjunto básico, cuya mejora ocurre de manera iterativa, como el análisis de incidentes derivados de la operación de la solución.
La dificultad número dos es la falta de reglas claras para la personalización. - Interpretación del resultado.
Cuando ocurre un incidente, es muy importante localizarlo rápidamente. Esto depende en gran medida de la experiencia del equipo de soporte, ya que bajo el eje de los mensajes secundarios sobre fallas, no puede notar la causa raíz de los problemas y perder tiempo en una respuesta rápida. Y esta es la complejidad tres.
Con la ayuda de procesos adecuadamente organizados, el equipo puede hacer frente a las dificultades anteriores, sin embargo, la solicitud moderna de un cambio de decisión reactivo, cuando el tiempo para pasar de una idea a la implementación se mide en días, complica significativamente la tarea. Se requiere capacitación continua en equipo. Los cambios constantes conducen al hecho de que ciertas reglas y relaciones de causa y efecto pierden su significado y, como resultado, el incidente, que no se elimina a tiempo, puede convertirse en un accidente.
Cómo nos ayuda el aprendizaje automático
La predicción del mal funcionamiento de los sistemas de hardware y software se convierte en una función muy popular de una respuesta preventiva o reactiva a los incidentes.
NEC Corporation, nuestra empresa matriz, invierte mucho en el desarrollo de la idea de monitoreo. Un resultado de esta inversión es la
Tecnología de Análisis Invariante del Sistema (SIAT) patentada.
SIAT es una tecnología de aprendizaje automático que, entre el conjunto de datos de sensores o métricas presentados como series de tiempo, encuentra mediante el uso de algoritmos ML relaciones funcionales constantes y construye un modelo general: un gráfico de estas relaciones. Los detalles se pueden encontrar
aquí .
Figura que ilustra la relación encontrada entre sensores de objetos físicos.
La idea, desarrollada originalmente para sistemas de TI, en este momento se ha extendido solo para monitorear complejos físicos, como fábricas, fábricas, plantas de energía nuclear.
Lockheed Martin , por ejemplo,
implementa estas tecnologías en su división espacial. En 2018,
Netcracker, junto con
NEC, repensaron esta idea y crearon un producto adecuado para monitorear los sistemas de TI como una herramienta para análisis adicionales.
Importante : esto es solo una adición al sistema de monitoreo, pero no su reemplazo.
Aplicaciones SIAT para sistemas de TI
¿Cuál es la diferencia entre un complejo físico y un software? En los sistemas de software, se utilizan métricas, en las físicas: sensores. La métrica se usa mucho más, ya que un sensor físico siempre vale la pena y se coloca solo donde tiene sentido. Las métricas de software, cuando se organizan adecuadamente, no cuestan nada. Además, las métricas de datos de los sistemas de información son mucho más difíciles de interpolar correctamente al estado del sistema. Es más fácil para una persona comprender los sensores relacionados con el mundo físico, mientras que los valores específicos de las métricas de software solo tienen sentido en relación con un hardware, configuración y carga específicos.
La interconexión
funcional en el modelo también sugiere que si reemplazamos la versión de hardware o software (por ejemplo, parches del sistema operativo) y todas las operaciones se vuelven igualmente rápidas o lentas, esto no generará mensajes falsos sobre accidentes debido al hecho de que no cambiamos
umbrales Si las métricas dejaron de correlacionarse entre sí, esto significa una desviación de la norma en el comportamiento del sistema. Además, la tecnología
SIAT permite detectar incluso pequeñas desviaciones en el comportamiento en tiempo real, incluidas las llamadas
fallas silenciosas, fallas que no van acompañadas de ningún mensaje de error. Y si esta desviación es solo un presagio de una falla mayor, tenemos tiempo para reaccionar correctamente.
Verificamos esta declaración simulando un pequeño servidor web Apache bajo carga, emulando errores internos utilizando el mecanismo de
inyección de fallas en Linux .
El resultado se presenta en forma de una
puntuación numérica de
anomalía métrica, cuyo valor está asociado con este modelo. Cuanto mayor sea el valor, más grave será la falla: más métricas se comportan de manera anormal. El valor límite es el 100% de las métricas son anormales, el sistema no funciona. Además, el resultado indica aquellas métricas cuyo comportamiento en este momento puede considerarse anormal. Esto acelera enormemente el análisis de la causa y la identificación del subsistema que actualmente falla en el modelo de comportamiento actual.
En general,
SIAT le permite responder incluso a cambios menores en el comportamiento que casi no son detectables mediante el monitoreo tradicional o de referencia.
Figura que ilustra una perturbación en la relación entre sensores
Una ventaja adicional de
SIAT es el algoritmo para construir un modelo de comportamiento que no requiere la indicación de ningún sentido comercial de las métricas. El algoritmo selecciona automáticamente todas las métricas cuyo comportamiento está interconectado entre sí, y esta relación es constante. Las métricas aisladas restantes son subsistemas puntuales que no afectan la solución de TI o métricas que no son importantes para el estado de la solución en este momento. Si tiene sentido, el monitoreo de tales métricas se implementa en el marco del enfoque tradicional basado en
alertas de umbral .
Es muy importante que la creación de un modelo requiera datos relacionados con el funcionamiento normal del sistema, que es
mucho más simple que cuando se aborda con entrenamiento de accidentes.
El modelo se refina y reconstruye aún más si el comportamiento ha cambiado o si le hemos agregado nuevas métricas.
Dado que el comportamiento normal del sistema es una característica variable, dependiendo de la hora del día y otras condiciones comerciales, para una respuesta más precisa, tiene sentido crear varios modelos que describan el comportamiento del sistema en ciertas condiciones.
¿Cómo se ve el proceso?
El proceso de organización de monitoreo es el siguiente.
- Comenzamos el monitoreo tradicional. La elección correcta del nombre de la métrica es muy importante. El hecho es que el resultado incluye los nombres de las métricas cuyo comportamiento es anormal, lo que significa que cuanto más exactamente la métrica describa el lugar y el significado, más rápido se obtendrá el resultado. Por ejemplo, una métrica llamada ncp. erp_netcracker _com.apps.erp. clust4.wls .jdbc. LMSDataSource . ActiveConnectionsCurrentCount indica que en el sistema Netcracker ERP , una métrica llamada ActiveConnectionsCurrentCount falla en el cuarto clúster de Weblogic para LMSDataSource . Para el experto, dicha información es más que suficiente para localizar con precisión la anomalía.
- A continuación, nos integramos con el sistema de almacenamiento de datos de métricas, en nuestro caso, ClickHouse , y obtenemos los datos de todas las métricas durante un cierto período del comportamiento normal de la solución: los mejores modelos se crean sobre la base de resultados de monitoreo de 30 días. Para obtener modelos más precisos, utilizamos datos métricos por minuto sin ninguna agregación.
- Construimos un modelo utilizando SIAT basado en datos de un sistema de monitoreo. Dentro del marco del modelo construido, filtramos las relaciones funcionales según el grado de similitud. En resumen, este es el grado de desviación del comportamiento de un determinado, expresado como un porcentaje.
- Verificamos el modelo con los datos de días anteriores, donde se detectaron fallas utilizando el equipo tradicional de monitoreo y soporte.
- Comenzamos el monitoreo en línea: cada 10 minutos, los datos de todas las métricas se transfieren al modelo o modelos. Obtenemos el resultado: puntaje de anomalía, y si el resultado no es cero, además obtenemos una lista de métricas cuyo comportamiento es actualmente anormal.
- El resultado se envía al sistema de monitoreo general, donde se convierte en parte de los paneles comunes y otras herramientas de monitoreo tradicionales.
Prueba
Ni una sola implementación ocurre sin verificación. Como sistemas probados, elegimos nuestro propio
ERP (monolito,
Weblogic ,
Oracle , 4500 métricas) y el sistema de enrutamiento de todo nuestro sistema de monitoreo, 7 millones de métricas por minuto, -
relé de carbono-c (1200 métricas).
Se utilizaron los volcados de todas las métricas como entrada, y también se indicaron los días en que se registraron las fallas. Para evaluar el resultado, presentamos los siguientes conceptos:
- El número de errores del segundo tipo es cuando un sistema de monitoreo tradicional o un equipo de soporte encontraron una falla, pero SIAT no.
- El número de detecciones correctas, cuando tanto el monitoreo tradicional como SIAT detectan un problema.
- El número de errores del primer tipo: cuando el SIAT detectó una desviación de comportamiento, pero el equipo de soporte no lo encontró.
No encontramos ningún error del segundo tipo para ambos sistemas probados. El número de detecciones correctas - 85% del número total de fallas encontradas por
SIAT , y en el caso de fallas del equipo - una matriz RAID en la base de datos
falló -
SIAT detectó una degradación del comportamiento con una indicación exacta de las métricas asociadas con la base de datos, siete horas antes de llegar establecer el valor umbral en el sistema de monitoreo.
El 15% restante de las fallas
SIAT indicadas son errores del primer tipo: comportamiento anormal que el equipo de soporte no puede explicar. Esto probablemente se deba al hecho de que al construir el modelo, se incluyeron automáticamente esas métricas que tienen un significado funcional, pero que no tienen un efecto notable en el comportamiento general del sistema. Después de varios falsos positivos, un experto en TI puede marcar estas métricas como sin importancia y eliminarlas del modelo, habiendo acordado previamente esto con la
PYME .
Los resultados mostraron que este producto automatiza completamente el proceso de detección de fallas (incluidas las ocultas), localiza oportunamente el incidente y evalúa su escala.
Que sigue
Ahora estamos acumulando experiencia en la operación del producto para varios tipos de sistemas de hardware y software con el fin de analizar la aplicabilidad de este enfoque a varios sistemas: dispositivos de red, dispositivos
IoT , microservicios en la nube, etc.
Por el momento, la tarea de reconstruir el modelo es el cuello de botella. Esto requiere una potencia informática considerable, pero, afortunadamente, el recuento puede llevarse a cabo en una máquina aislada, exportando el resultado como un modelo terminado. El monitoreo en tiempo real en sí mismo no requiere recursos significativos y se realiza en paralelo con el monitoreo tradicional en el mismo equipo.
Conclusión
En resumen, quiero señalar que el uso de una combinación de técnicas de monitoreo tradicionales y algoritmos de aprendizaje automático le permite construir un modelo simple que lo ayuda a responder a tiempo, averiguar dónde se originó el problema y también mantener el sistema en funcionamiento.
Además de la prometedora tecnología
SIAT , estamos analizando las posibilidades de utilizar otra tecnología
NEC :
Next Generation Log Analytics . La tecnología permite el uso de algoritmos de aprendizaje automático y el uso de registros del sistema para determinar anomalías relacionadas con el estado interno del producto que no afectan la degradación general del sistema en términos de rendimiento.
¿Qué análisis utiliza para monitorear los sistemas de TI?