
Las herramientas tradicionales en el campo de la ciencia de datos son lenguajes como R y Python : la sintaxis relajada y una gran cantidad de bibliotecas para el aprendizaje automático y el procesamiento de datos le permiten obtener rápidamente algunas soluciones de trabajo. Sin embargo, hay situaciones en las que las limitaciones de estas herramientas se convierten en un obstáculo importante, en primer lugar, si necesita lograr un alto rendimiento en términos de velocidad de procesamiento y / o trabajar con conjuntos de datos realmente grandes. En este caso, el especialista tiene que recurrir a regañadientes a la ayuda del "lado oscuro" y conectar las herramientas en los lenguajes de programación "industrial": Scala , Java y C ++ .
¿Pero es este lado tan oscuro? A lo largo de los años de desarrollo, las herramientas de la ciencia de datos "industrial" han recorrido un largo camino y hoy son muy diferentes de sus propias versiones hace 2-3 años. Intentemos usar el ejemplo de la tarea SNA Hackathon 2019 para calcular cuánto puede corresponder el ecosistema Scala + Spark con Python Data Science.
En el marco de SNA Hackathon 2019, los participantes resuelven el problema de clasificar la fuente de noticias de un usuario de una red social en una de tres "disciplinas": usar datos de textos, imágenes o registros de funciones. En esta publicación, veremos cómo en Spark es posible resolver un problema sobre la base de un registro de signos utilizando herramientas clásicas de aprendizaje automático.
Al resolver el problema, seguiremos el camino estándar que cualquier especialista en análisis de datos sigue al desarrollar un modelo:
- Realizaremos análisis de datos de investigación, construiremos gráficos.
- Analizamos las propiedades estadísticas de los signos en los datos, observamos sus diferencias entre los conjuntos de entrenamiento y prueba.
- Realizaremos una selección inicial de características basadas en propiedades estadísticas.
- Calculamos las correlaciones entre los signos y la variable objetivo, así como la correlación cruzada entre los signos.
- Formaremos el conjunto final de características, entrenaremos al modelo y verificaremos su calidad.
- Analicemos la estructura interna del modelo para identificar puntos de crecimiento.
Durante nuestro "viaje" nos familiarizaremos con herramientas como el cuaderno interactivo Zeppelin , la biblioteca de aprendizaje automático Spark ML y su extensión PravdaML , el paquete de gráficos GraphX , la biblioteca de visualización de Vegas y, por supuesto, Apache Spark en todo su esplendor: ) Todos los resultados del código y del experimento están disponibles en la plataforma de cuaderno colaborativo Zepl .
Carga de datos
La peculiaridad de los datos presentados en SNA Hackathon 2019 es que es posible procesarlos directamente usando Python, pero es difícil: los datos originales se empaquetan de manera bastante eficiente gracias a las capacidades del formato de columna Apache Parquet y cuando se lee en la memoria "por la frente" se descomprime en varias decenas de gigabytes. Cuando se trabaja con Apache Spark, no hay necesidad de cargar completamente los datos en la memoria, la arquitectura Spark está diseñada para procesar datos en partes, cargando desde el disco según sea necesario.
Por lo tanto, el primer paso, verificar la distribución de datos por día, se realiza fácilmente mediante herramientas en caja:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
Lo que mostrará el gráfico correspondiente en Zeppelin:
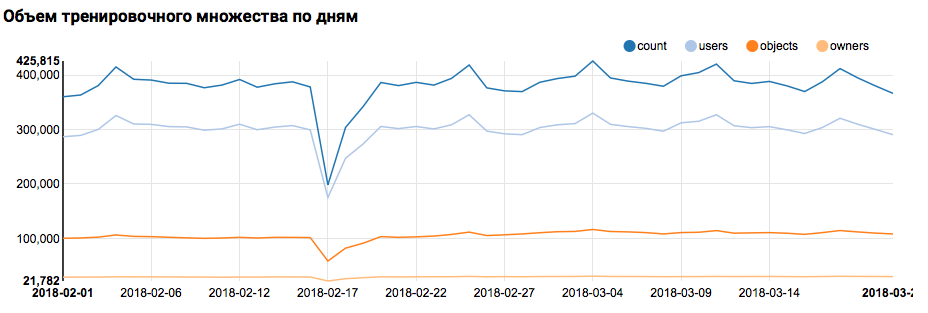
Debo decir que la sintaxis de Scala es bastante flexible, y el mismo código puede verse, por ejemplo, así:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
Aquí debe hacerse una advertencia importante: cuando se trabaja en un equipo grande, donde todos se acercan a escribir el código Scala exclusivamente desde el punto de vista de su propio gusto, la comunicación es mucho más difícil. Por lo tanto, es mejor desarrollar un concepto unificado de estilo de código.
Pero volvamos a nuestra tarea. Un análisis simple por día mostró la presencia de puntos anormales el 17 y 18 de febrero; Probablemente en estos días se han recopilado datos incompletos y la distribución de los rasgos puede estar sesgada. Esto debe tenerse en cuenta en un análisis posterior. Además, es sorprendente que el número de usuarios únicos sea muy cercano al número de objetos, por lo que tiene sentido estudiar la distribución de usuarios con diferentes números de objetos:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
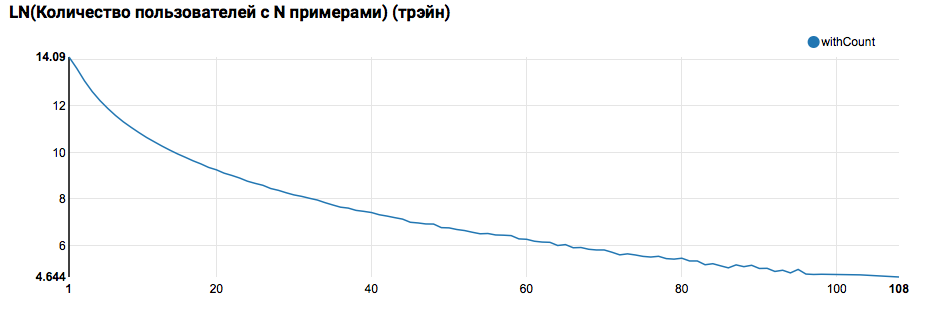
Se espera ver una distribución cercana a exponencial, con una cola muy larga. En tales tareas, por regla general, es posible lograr una mejora en la calidad del trabajo segmentando modelos para usuarios con diferentes niveles de actividad. Para verificar si vale la pena hacer esto, compare la distribución del número de objetos por usuario en el conjunto de prueba:
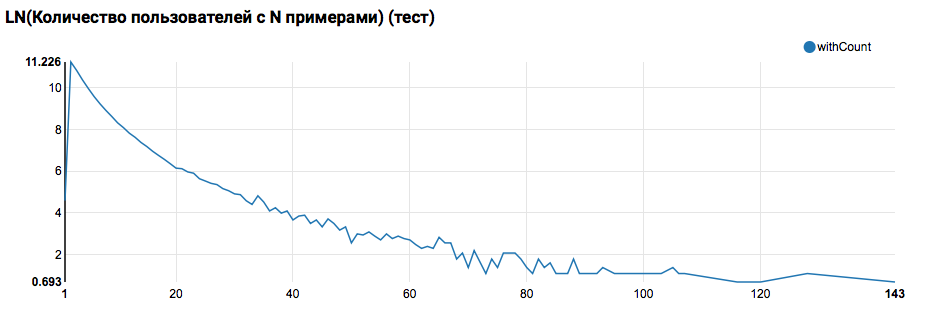
La comparación con la prueba muestra que los usuarios de la prueba tienen al menos dos objetos en los registros (dado que el problema de clasificación se resuelve en el hackathon, esta es una condición necesaria para evaluar la calidad). En el futuro, recomiendo mirar más de cerca a los usuarios en el conjunto de entrenamiento, para lo cual declaramos la Función definida por el usuario con un filtro:
También debería hacerse una observación importante: es desde el punto de vista de la definición de UDF que el uso de Spark desde debajo de Scala / Java y desde debajo de Python es notablemente diferente. Si bien el código PySpark utiliza la funcionalidad básica, todo funciona casi tan rápido, pero cuando aparecen funciones anuladas, el rendimiento de PySpark se degrada en un orden de magnitud.
La primera tubería de ML
En el siguiente paso, intentaremos calcular las estadísticas básicas sobre acciones y atributos. Pero para esto necesitamos las capacidades de SparkML, así que primero veremos su arquitectura general:

SparkML se basa en los siguientes conceptos:
- Transformador: toma un conjunto de datos como entrada y devuelve un conjunto modificado (transformación). Como regla general, se utiliza para implementar algoritmos de preprocesamiento y posprocesamiento, extracción de características y también puede representar los modelos ML resultantes.
- Estimador: toma un conjunto de datos como entrada y devuelve Transformador (ajuste). Naturalmente, Estimator puede representar el algoritmo ML.
- Pipeline es un caso especial de Estimator, que consiste en una cadena de transformadores y estimadores. Cuando se llama al método, el ajuste pasa a través de la cadena, y si ve un transformador, lo aplica a los datos, y si ve un estimador, entrena el transformador con él, lo aplica a los datos y va más allá.
- PipelineModel: el resultado de Pipeline también contiene una cadena en su interior, pero que consiste exclusivamente en transformadores. En consecuencia, PipelineModel es también un transformador.
Tal enfoque para la formación de algoritmos ML ayuda a lograr una estructura modular clara y una buena reproducibilidad: tanto los modelos como las tuberías se pueden guardar.
Para comenzar, construiremos una tubería simple con la que calcularemos las estadísticas de la distribución de acciones (campo de comentarios) de los usuarios en el conjunto de capacitación:
val feedbackAggregator = new Pipeline().setStages(Array(
En esta tubería, la funcionalidad de PravdaML se usa activamente: bibliotecas con bloques útiles extendidos para SparkML, a saber:
- MultinominalExtractor se utiliza para codificar un carácter de tipo "matriz de cadenas" en un vector de acuerdo con el principio de hot-one. Este es el único estimador en la tubería (para construir una codificación, debe recopilar líneas únicas del conjunto de datos).
- VectorStatCollector se utiliza para calcular estadísticas vectoriales.
- VectorExplode se utiliza para convertir el resultado a un formato conveniente para la visualización.
El resultado del trabajo será un gráfico que muestra que las clases en el conjunto de datos no están equilibradas, sin embargo, el desequilibrio para la clase de Me gusta de destino no es extremo:

El análisis de una distribución similar entre usuarios similares a los de prueba (que tienen tanto "positivo" como "negativo" en los registros) muestra que está sesgado hacia la clase positiva:
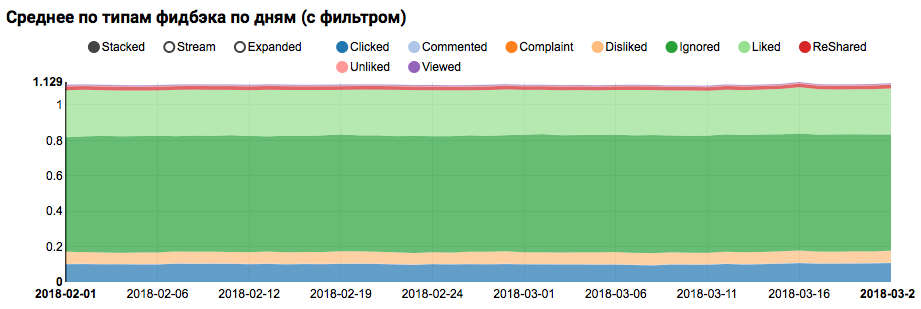
Análisis estadístico de signos.
En la siguiente etapa, realizaremos un análisis detallado de las propiedades estadísticas de los atributos. Esta vez necesitamos un transportador más grande:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
Como ahora necesitamos trabajar no con un campo separado, sino con todos los atributos a la vez, utilizaremos dos utilidades PravdaML más útiles:
- NullToDefaultReplacer le permite reemplazar elementos faltantes en los datos con sus valores predeterminados (0 para números, falso para variables lógicas, etc.). Si no realiza esta conversión, aparecerán valores de NaN en los vectores resultantes, lo cual es fatal para muchos algoritmos (aunque, por ejemplo, XGBoost puede sobrevivir a esto). Una alternativa para reemplazar con ceros puede ser reemplazar con promedios, esto se implementa en NaNToMeanReplacerEstimator.
- AutoAssembler es una utilidad muy poderosa que analiza el diseño de la tabla y para cada columna selecciona un esquema de vectorización que coincide con el tipo de columna.
Usando la tubería resultante, calculamos las estadísticas para tres conjuntos (entrenamiento, entrenamiento con filtro de usuario y prueba) y los guardamos en archivos separados:
Habiendo recibido tres conjuntos de datos con estadísticas de atributos, analizamos las siguientes cosas:
- ¿Tenemos señales de que hay grandes emisiones?
- Tales signos deben ser limitados, o los registros atípicos deben ser filtrados. - ¿Tenemos signos con un gran sesgo de la media en relación con la mediana.
- Tal cambio a menudo ocurre en presencia de una distribución de potencia, tiene sentido logaritmar estos signos. - ¿Hay un cambio en las distribuciones promedio entre los conjuntos de entrenamiento y prueba?
- Cuán apretada nuestra matriz de características.
Para aclarar estos aspectos, dicha solicitud nos ayudará a:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
En esta etapa, surge la pregunta de visualización: es difícil mostrar de inmediato todos los aspectos utilizando herramientas regulares de Zeppelin, y los cuadernos con una gran cantidad de gráficos comienzan a disminuir notablemente debido al DOM hinchado. Las Vegas : la biblioteca DSL en Scala para construir especificaciones vega-lite puede resolver este problema. Vegas no solo proporciona capacidades de visualización más ricas (comparables a matplotlib), sino que también las dibuja en Canvas sin inflar el DOM :).
La especificación de la tabla que nos interesa se verá así:
vegas.Vegas(width = 1024, height = 648)
El cuadro a continuación debería leer así:
- El eje X muestra el desplazamiento de los centros de distribución entre los conjuntos de prueba y entrenamiento (cuanto más cerca de 0, más estable es el signo).
- El porcentaje de elementos distintos de cero se traza a lo largo del eje Y (cuanto más alto, más datos hay para el mayor número de puntos por atributo).
- El tamaño muestra el desplazamiento del promedio en relación con la mediana (cuanto mayor es el punto, más probable es la distribución de la ley de potencia para él).
- El color indica emisiones (cuanto más rojo, más emisiones).
- Bueno, la forma se distingue por un modo de comparación: con un filtro de usuario en el conjunto de entrenamiento o sin filtro.
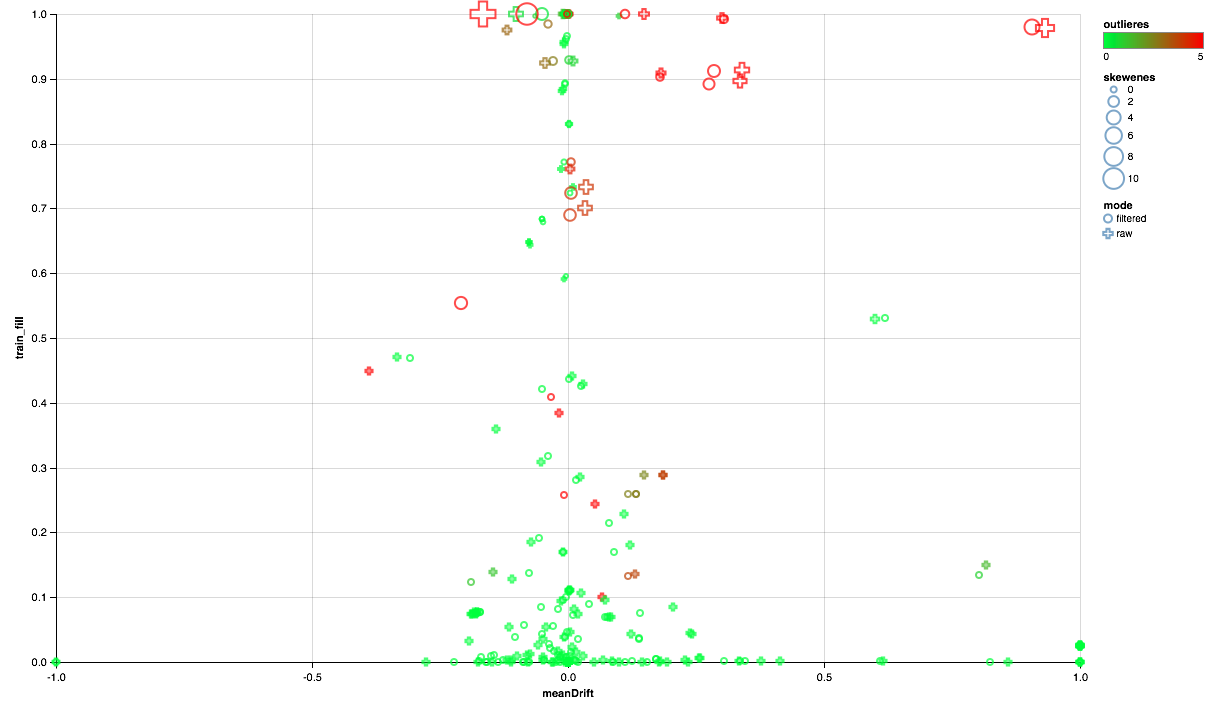
Entonces, podemos sacar las siguientes conclusiones:
- Algunas señales necesitan un filtro de emisión: limitaremos los valores máximos para el percentil 90.
- Algunos signos muestran una distribución cercana a la exponencial: tomaremos el logaritmo.
- Algunas características no se presentan en la prueba; las excluiremos de la capacitación.
Análisis de correlación
Después de tener una idea general de cómo se distribuyen los atributos y cómo se relacionan entre los conjuntos de entrenamiento y prueba, intentemos analizar las correlaciones. Para hacer esto, configure el extractor de características basado en observaciones anteriores:
De la nueva maquinaria en esta tubería, la utilidad SQLTransformer llama la atención, lo que permite transformaciones arbitrarias de SQL de la tabla de entrada.
Cuando se analizan las correlaciones, es importante filtrar el ruido creado por la correlación natural de las características únicas. Para hacer esto, me gustaría entender qué elementos del vector corresponden a qué columnas de origen. Esta tarea en Spark se realiza utilizando metadatos de columna (almacenados con datos) y grupos de atributos. El siguiente bloque de código se usa para filtrar pares de nombres de atributos que provienen de la misma columna de tipo String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
Tener a mano un conjunto de datos con una columna vectorial, calcular las correlaciones cruzadas usando Spark es bastante simple, pero el resultado es una matriz, para la implementación de la cual tendrás que jugar un poco en un conjunto de pares:
val pearsonCorrelation =
Y, por supuesto, visualización: necesitaremos nuevamente la ayuda de Vegas para dibujar un mapa de calor:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
El resultado es mejor mirar en Zepl-e . Para una comprensión general:
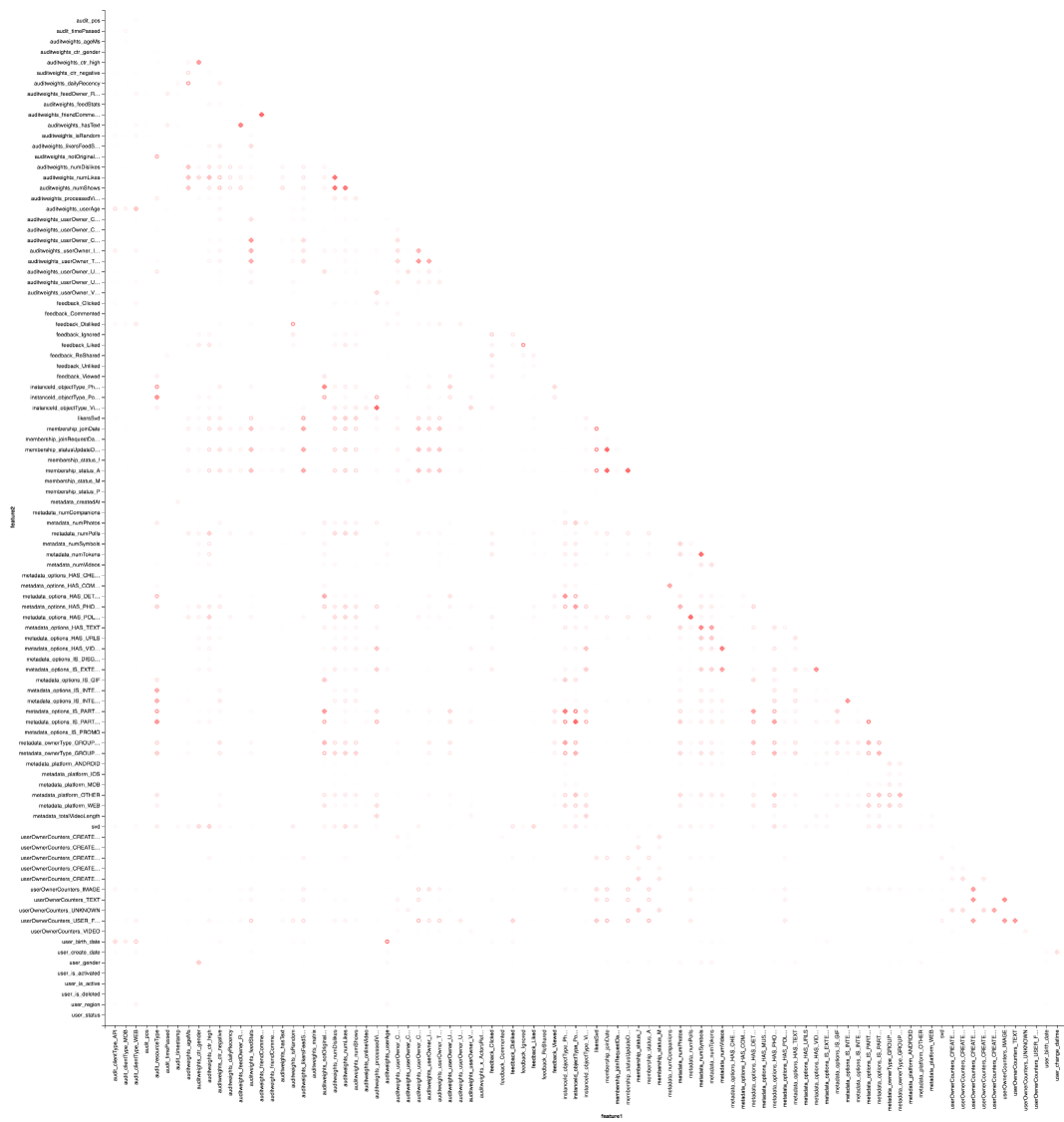
El mapa de calor muestra que algunas correlaciones están claramente allí. Intentemos seleccionar los bloques de las características más fuertemente correlacionadas, para esto usamos la biblioteca GraphX : convertimos la matriz de correlación en un gráfico, filtramos los bordes por peso, después de lo cual encontramos los componentes conectados y dejamos solo los no degenerados (de más de un elemento). Tal procedimiento es esencialmente similar a la aplicación del algoritmo DBSCAN y es el siguiente:
El resultado se presenta en forma de tabla:
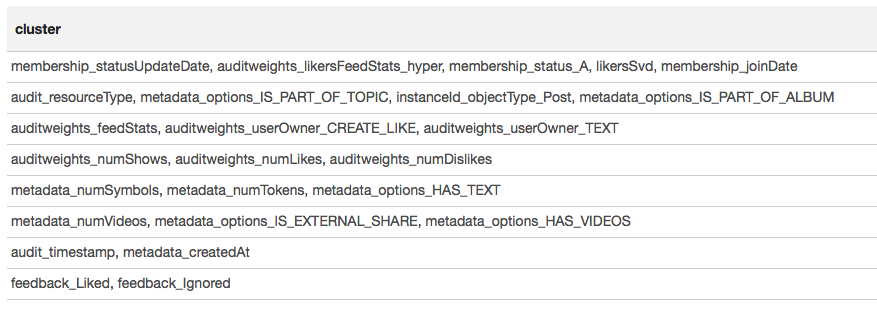
Con base en los resultados de la agrupación, podemos concluir que los grupos más correlacionados se formaron alrededor de los signos asociados con la membresía del usuario en el grupo (member_status_A), así como alrededor del tipo de objeto (instanceId_objectType). Para el mejor modelado de la interacción de los signos, tiene sentido aplicar la segmentación del modelo, para entrenar diferentes modelos para diferentes tipos de objetos, por separado para grupos en los que el usuario es y no es.
Aprendizaje automático
Nos acercamos a lo más interesante: el aprendizaje automático. La tubería para entrenar el modelo más simple (regresión logística) usando extensiones SparkML y PravdaML es la siguiente:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
Aquí vemos no solo muchos elementos familiares, sino también varios elementos nuevos:
- LogisticRegressionLBFSG es un estimador con entrenamiento distribuido de regresión logística.
- Para lograr el máximo rendimiento de algoritmos ML distribuidos. los datos deben distribuirse de manera óptima entre las particiones. La utilidad UnwrappedStage.repartition ayudará en esto, agregando una operación de reparto a la tubería de tal manera que se use solo en la etapa de entrenamiento (después de todo, cuando se construyen pronósticos, ya no es necesario).
- Para que el modelo lineal pueda dar un buen resultado. los datos deben ser escalados, de los cuales la utilidad Scaler.scale es responsable. Sin embargo, la presencia de dos transformaciones lineales consecutivas (escala y multiplicación por los pesos de regresión) conduce a gastos innecesarios, y es deseable colapsar estas operaciones. Al usar PravdaML, la salida será un modelo limpio con una transformación :).
- Bueno, por supuesto, para tales modelos necesita un miembro gratuito, que agregamos usando la operación Interceptor.intercept.
La canalización resultante, aplicada a todos los datos, proporciona AUC por usuario 0.6889 (el código de validación está disponible en Zepl ). Ahora queda por aplicar toda nuestra investigación: filtrar datos, transformar características y segmentar modelos. La tubería final se verá así:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
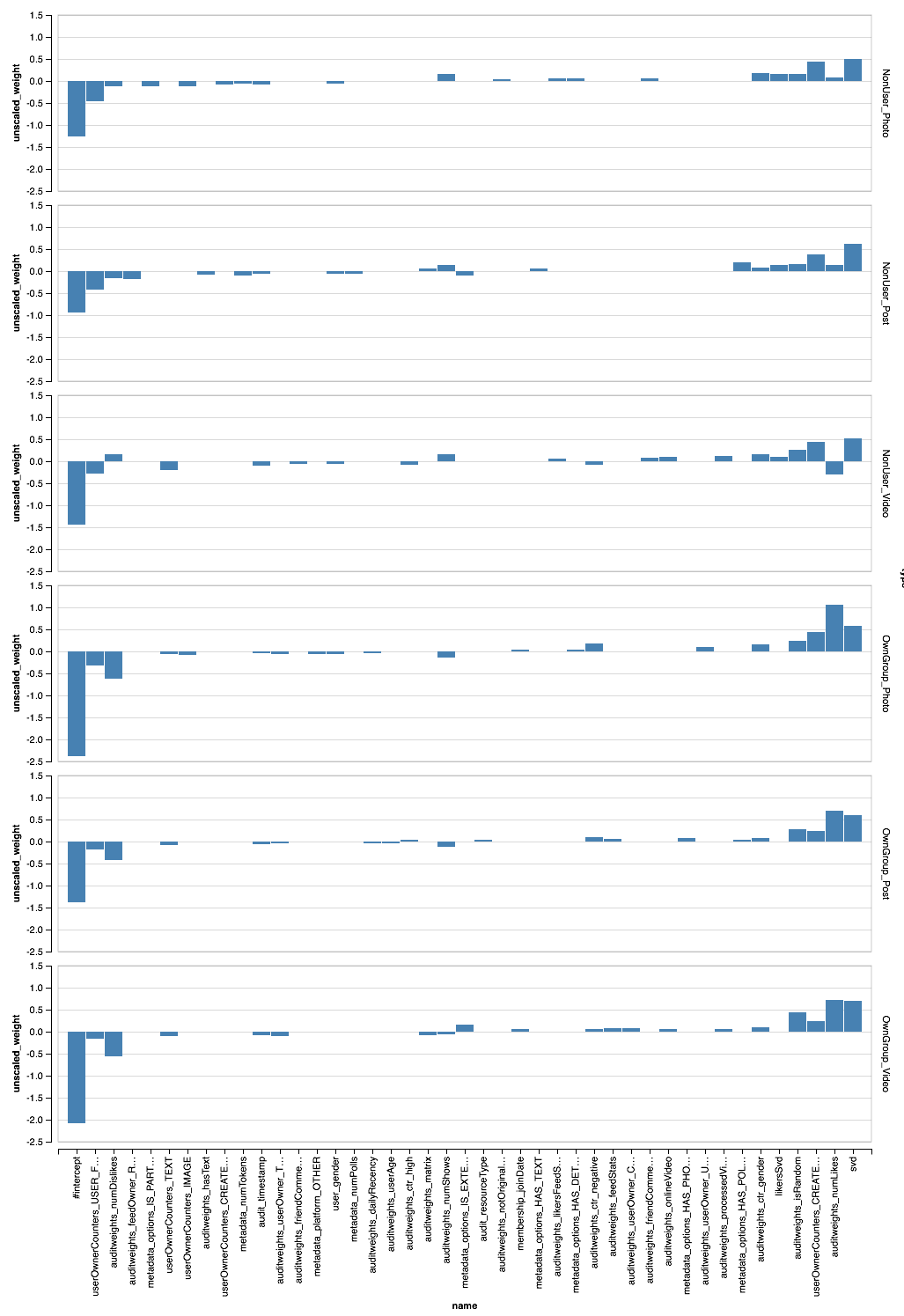
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
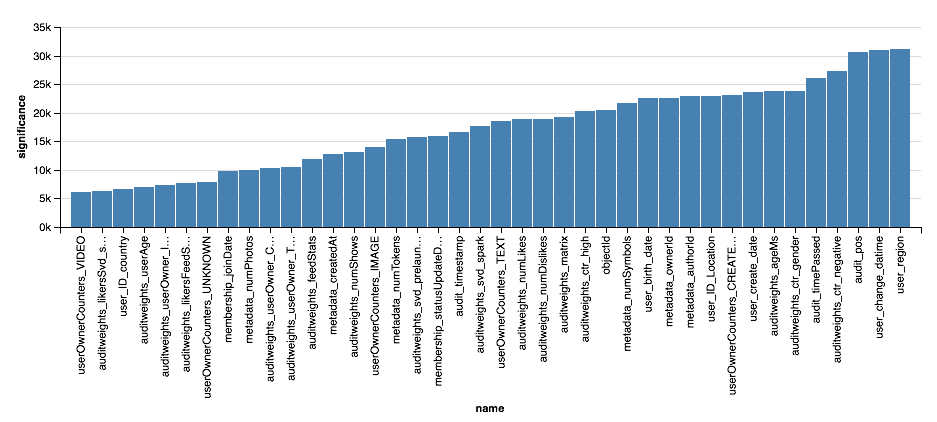
, , XGBoost, , . . , XGBoost , , .
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .