
Cualquier proceso relacionado con la base de datos, tarde o temprano, encuentra problemas con el rendimiento de las consultas a esta base de datos.
El almacén de datos de Rostelecom se basa en Greenplum, la mayoría de los cálculos (transformación) se realizan mediante consultas sql, que inician (o generan e inician) el mecanismo ETL. DBMS tiene sus propios matices que afectan significativamente el rendimiento. Este artículo es un intento de resaltar los aspectos más críticos de trabajar con Greenplum en términos de rendimiento y compartir experiencias.
En pocas palabras sobre GreenplumGreenplum: servidor de base de datos
MPP , cuyo núcleo se basa en PostgreSql.
Representa varias instancias diferentes del proceso PostgreSql (instancias). Uno de ellos es el punto de entrada para el cliente y se llama instancia maestra (maestra), todas las demás se llaman instancias de segmento (segmento, instancias independientes, cada una de las cuales tiene su propia pieza de datos). Cada servidor (host de segmento) puede ejecutarse de uno a varios servicios (segmento). Esto se hace para utilizar mejor los recursos del servidor y principalmente los procesadores. El asistente almacena metadatos, es responsable de comunicar a los clientes con datos y también distribuye el trabajo entre segmentos.
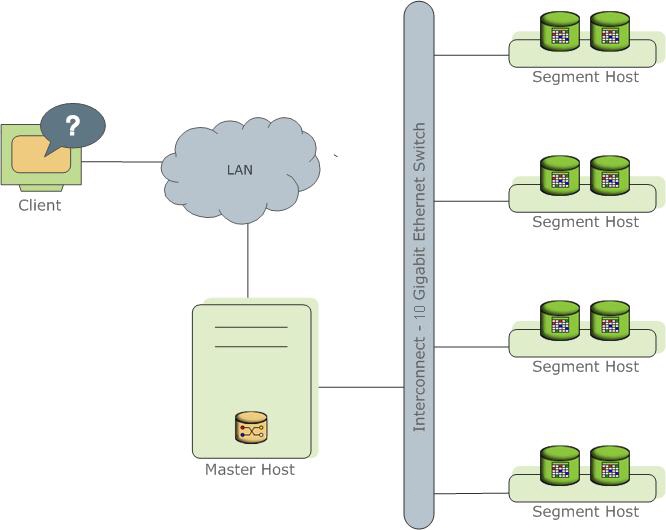
Lea más en la
documentación oficial .
Además en el artículo habrá muchas referencias al plan de solicitud. La información para Greenplum está disponible
aquí .
Cómo escribir buenas consultas en Greenplum (bueno, o al menos no del todo triste)
Como estamos tratando con una base de datos distribuida, es importante no solo cómo se escribe la consulta SQL, sino también cómo se almacenan los datos.
1. Distribución
Los datos se almacenan físicamente en diferentes segmentos. Puede separar los datos por segmentos al azar o por el valor de la función hash de un campo o un conjunto de campos.
Sintaxis (al crear una tabla):
DISTRIBUTED BY (some_field)
Más o menos:
DISTRIBUTED RANDOMLY
El campo de distribución debe tener una buena selectividad y no tener valores nulos (o tener un mínimo de dichos valores), ya que los registros con dichos campos se distribuirán en un segmento, lo que puede conducir a distorsiones de datos.
El tipo de campo es preferiblemente entero. El campo se usa para unir tablas. Hash join es una de las mejores formas de unir tablas (en términos de ejecución de consultas), funciona mejor con este tipo de datos.
Para la distribución, es aconsejable elegir no más de dos campos y, por supuesto, uno es mejor que dos. Los campos adicionales en las claves de distribución, en primer lugar, requieren tiempo adicional para el hash, y en segundo lugar (en la mayoría de los casos) requerirán la transferencia de datos entre segmentos al ejecutar uniones.
Puede utilizar la distribución aleatoria si no puede seleccionar uno o dos campos adecuados, así como para etiquetas pequeñas. Pero debemos tener en cuenta que dicha distribución funciona mejor para la inserción de datos en masa, y no para un registro. GreenPlum distribuye datos de acuerdo con el algoritmo
cíclico , y comienza un nuevo ciclo para cada operación de inserción, comenzando desde el primer segmento, que, con pequeñas inserciones frecuentes, conduce a sesgos (sesgo de datos).
Con un campo de distribución bien elegido, todos los cálculos se realizarán en el segmento, sin enviar datos a otros segmentos. Además, para una unión óptima de tablas (join), los mismos valores deben ubicarse en el mismo segmento.
Distribución en imágenes.Buena clave de distribución: Mala clave de distribución:
Mala clave de distribución: Distribución aleatoria:
Distribución aleatoria:
El tipo de campos utilizados en join debe ser el mismo en todas las tablas.
Importante: no use como campos de distribución aquellos que se usan para filtrar consultas en donde, ya que en este caso la carga durante la consulta tampoco se distribuirá de manera uniforme.
2. Particionamiento
La partición le permite dividir tablas grandes, como
hechos , en piezas separadas lógicamente. Greenplum divide físicamente su tabla en tablas separadas, cada una de las cuales se divide en segmentos según la configuración de la p. 1.
Las tablas deben dividirse lógicamente en secciones, para este propósito, seleccione el campo que se usa con frecuencia en el bloque where. De hecho tablas este será el período. Por lo tanto, con el acceso adecuado a la tabla en consultas, solo trabajará con parte de la tabla grande completa.
En general, la partición es un tema bastante conocido, y quería enfatizar que no debe elegir el mismo campo para la partición y distribución. Esto conducirá al hecho de que la solicitud se ejecutará completamente en un segmento.
Es hora de ir, de hecho, a las solicitudes. La solicitud se ejecutará en segmentos de acuerdo con un
plan específico:
3. El optimizador
Greenplum tiene dos optimizadores, el optimizador heredado incorporado y el optimizador Orca de terceros: GPORCA - Orca - Pivotal Query Optimizer.
Habilitar GPORCA a petición:
set optimizer = on;
Como regla general , el optimizador GPORCA es mejor que el incorporado. Funciona más adecuadamente con subconsultas y
CTE (más detalles
aquí ).
Realizó una llamada a una tabla grande en CTE con el máximo filtrado de datos (no se olvide de la poda de particiones) y una lista explícitamente especificada de campos: funciona muy bien.
Modifica ligeramente el plan de consulta, por ejemplo, de lo contrario muestra las particiones escaneadas:
Optimizador estándar: Orca
Orca
GPORCA también permite actualizar los campos de partición / distribución. Aunque hay situaciones en las que el optimizador incorporado funciona mejor. Un optimizador de terceros es muy exigente con las estadísticas, es importante no olvidar
analizar .
No importa cuán bueno sea el optimizador, una consulta mal escrita ni siquiera estirará a Orca:
4. Manipulaciones con campos en las condiciones donde bloquear o unir
Es importante recordar que la función aplicada al campo de filtro o las condiciones de la unión se aplica a
cada registro.
En el caso del campo de particionamiento (por ejemplo, date_trunc al campo de particionamiento - fecha), incluso GPORCA no puede funcionar correctamente en este caso, el
recorte de particiones no funcionará.
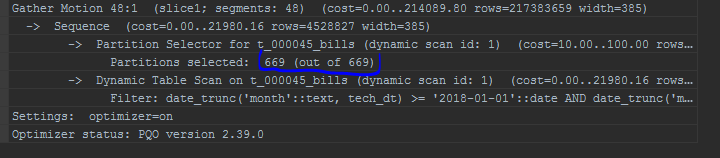
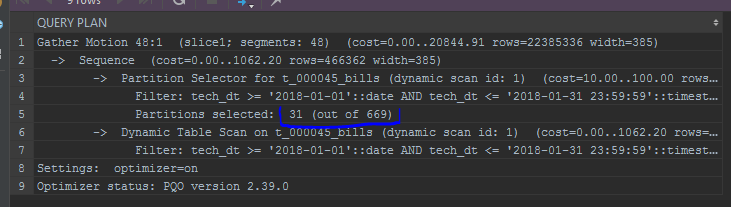 También llamo la atención sobre la visualización de particiones. El optimizador incorporado mostrará particiones en una lista:
También llamo la atención sobre la visualización de particiones. El optimizador incorporado mostrará particiones en una lista:
Aplique cuidadosamente las funciones a las constantes en los mismos filtros de partición. Un ejemplo es el mismo date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCA hará frente por completo a esa finta y funcionará correctamente, el optimizador estándar ya no lo hará. Sin embargo, al hacer una conversión de tipo explícita, puede hacer que funcione:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

¿Y si todo se hace mal?
5. Mociones
Otro tipo de operación que se puede observar en
el plan de consulta son los movimientos. Movimientos de datos tan marcados entre segmentos:
- Recopilar movimiento : se mostrará en casi todos los planes, lo que significa combinar los resultados de la ejecución de consultas de todos los segmentos en una secuencia (generalmente al maestro).
Dos tablas, distribuidas por una clave, que se utilizan para la unión, realizan todas las operaciones en segmentos, sin mover datos. De lo contrario, se produce movimiento de difusión o movimiento de redistribución: - Movimiento de transmisión : cada segmento envía su copia de los datos a otros segmentos. En una situación ideal, la transmisión se produce solo para tablas pequeñas.
- Movimiento de redistribución : para unir tablas grandes distribuidas en diferentes claves, la redistribución se realiza para hacer conexiones localmente. Para mesas grandes, esta puede ser una operación bastante costosa.
La difusión y la redistribución son operaciones bastante desventajosas. Se ejecutan cada vez que se ejecuta la solicitud. Se recomienda evitarlos. Habiendo visto estos puntos en el plan de consulta, vale la pena prestar atención a las claves de distribución. Las operaciones distintivas y sindicales también causan mociones.
Esta lista no es exhaustiva y se basa principalmente en la experiencia del autor. No funcionó encontrar todo de inmediato en Internet al mismo tiempo. Aquí traté de identificar los factores más críticos que afectan el rendimiento de la solicitud y entender por qué y por qué sucede esto.
Este artículo fue preparado por el equipo de gestión de datos de Rostelecom