El primer artículo describió el
motor de indexación PostgreSQL , el segundo se ocupó de
la interfaz de los métodos de acceso , y ahora estamos listos para discutir tipos específicos de índices. Comencemos con el índice hash.
Hachís
Estructura
Teoría general
Muchos lenguajes de programación modernos incluyen tablas hash como tipo de datos base. En el exterior, una tabla hash se parece a una matriz regular que se indexa con cualquier tipo de datos (por ejemplo, cadena) en lugar de con un número entero. El índice hash en PostgreSQL está estructurado de manera similar. ¿Cómo funciona esto?
Como regla, los tipos de datos tienen rangos muy grandes de valores permitidos: ¿cuántas cadenas diferentes podemos imaginar en una columna de tipo "texto"? Al mismo tiempo, ¿cuántos valores diferentes se almacenan realmente en una columna de texto de alguna tabla? Por lo general, no muchos de ellos.
La idea del hash es asociar un número pequeño (de 0 a
N −1,
N valores en total) con un valor de cualquier tipo de datos. Una asociación como esta se llama
función hash . El número obtenido se puede usar como un índice de una matriz regular donde se almacenarán las referencias a las filas de la tabla (TID). Los elementos de esta matriz se denominan
cubos de tabla hash : un cubo puede almacenar varios TID si el mismo valor indexado aparece en diferentes filas.
Cuanto más uniformemente una función hash distribuya los valores de origen por cubos, mejor será. Pero incluso una buena función hash a veces producirá resultados iguales para diferentes valores de origen; esto se denomina
colisión . Por lo tanto, un depósito puede almacenar los TID correspondientes a diferentes claves y, por lo tanto, los TID obtenidos del índice deben volver a comprobarse.
Solo por ejemplo: ¿en qué función hash para cadenas podemos pensar? Deje que el número de depósitos sea 256. Luego, por ejemplo, de un número de depósito, podemos tomar el código del primer carácter (suponiendo una codificación de caracteres de un solo byte). ¿Es esta una buena función hash? Evidentemente, no: si todas las cadenas comienzan con el mismo carácter, todas entrarán en un cubo, por lo que la uniformidad está fuera de discusión, todos los valores deberán volver a comprobarse, y el hash no tendrá ningún sentido. ¿Qué pasa si resumimos los códigos de todos los caracteres del módulo 256? Esto será mucho mejor, pero lejos de ser ideal. Si está interesado en los aspectos internos de dicha función hash en PostgreSQL, consulte la definición de hash_any () en
hashfunc.c .
Estructura del índice
Volvamos al índice hash. Para un valor de algún tipo de datos (una clave de índice), nuestra tarea es encontrar rápidamente el TID correspondiente.
Al insertar en el índice, calculemos la función hash para la clave. Las funciones hash en PostgreSQL siempre devuelven el tipo "entero", que está en el rango de 2
32 ≈ 4 mil millones de valores. El número de depósitos inicialmente es igual a dos y aumenta dinámicamente para ajustarse al tamaño de los datos. El número de depósito se puede calcular a partir del código hash utilizando la aritmética de bits. Y este es el cubo donde pondremos nuestro TID.
Pero esto es insuficiente ya que los TID que coinciden con diferentes claves se pueden poner en el mismo depósito. Que haremos Es posible almacenar el valor de origen de la clave en un depósito, además del TID, pero esto aumentaría significativamente el tamaño del índice. Para ahorrar espacio, en lugar de una clave, el depósito almacena el código hash de la clave.
Al buscar a través del índice, calculamos la función hash para la clave y obtenemos el número de depósito. Ahora queda revisar el contenido del depósito y devolver solo los TID coincidentes con los códigos hash apropiados. Esto se realiza de manera eficiente ya que se ordenan los pares almacenados de "código hash - TID".
Sin embargo, pueden suceder dos claves diferentes no solo para entrar en un cubo, sino también para tener los mismos códigos hash de cuatro bytes: nadie ha eliminado la colisión. Por lo tanto, el método de acceso solicita al motor de indexación general que verifique cada TID volviendo a verificar la condición en la fila de la tabla (el motor puede hacer esto junto con la verificación de visibilidad).
Asignación de estructuras de datos a páginas
Si observamos un índice tal como lo ve el administrador de la memoria caché del búfer en lugar de desde la perspectiva de la planificación y ejecución de consultas, resulta que toda la información y todas las filas del índice deben empaquetarse en páginas. Dichas páginas de índice se almacenan en la memoria caché del búfer y se expulsan de allí exactamente de la misma manera que las páginas de la tabla.
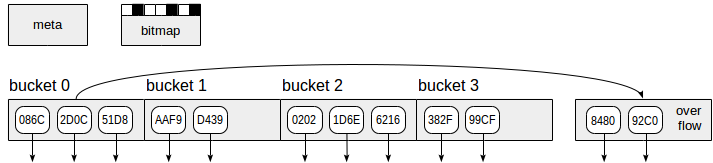
El índice hash, como se muestra en la figura, utiliza cuatro tipos de páginas (rectángulos grises):
- Meta página: número de página cero, que contiene información sobre lo que está dentro del índice.
- Páginas de depósito: páginas principales del índice, que almacenan datos como pares "código hash - TID".
- Páginas de desbordamiento: estructuradas de la misma manera que las páginas de depósito y utilizadas cuando una página es insuficiente para un depósito.
- Páginas de mapa de bits: que realizan un seguimiento de las páginas de desbordamiento que actualmente son claras y pueden reutilizarse para otros depósitos.
Las flechas hacia abajo que comienzan en los elementos de la página de índice representan TID, es decir, referencias a las filas de la tabla.
Cada vez que aumenta el índice, PostgreSQL crea instantáneamente el doble de depósitos (y, por lo tanto, páginas) que la última vez que se crearon. Para evitar la asignación de este número potencialmente grande de páginas a la vez, la versión 10 hizo que el tamaño aumentara más suavemente. En cuanto a las páginas de desbordamiento, se asignan justo cuando surge la necesidad y se rastrean en páginas de mapa de bits, que también se asignan cuando surge la necesidad.
Tenga en cuenta que el índice hash no puede disminuir de tamaño. Si eliminamos algunas de las filas indexadas, las páginas una vez asignadas no se devolverán al sistema operativo, sino que solo se reutilizarán para nuevos datos después de VACUUMING. La única opción para disminuir el tamaño del índice es reconstruirlo desde cero utilizando el comando REINDEX o VACUUM FULL.
Ejemplo
Veamos cómo se crea el índice hash. Para evitar diseñar nuestras propias tablas, a partir de ahora utilizaremos
la base de
datos de
demostración de transporte aéreo, y esta vez consideraremos la tabla de vuelos.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
Lo inconveniente de la implementación actual del índice hash es que las operaciones con el índice no se registran en el registro de escritura anticipada (de lo cual PostgreSQL advierte cuando se crea el índice). En consecuencia, los índices hash no se pueden recuperar después del error y no participan en las réplicas. Además, el índice de hash está muy por debajo del "árbol B" en versatilidad, y su eficiencia también es cuestionable. Por lo tanto, ahora no es práctico usar tales índices.
Sin embargo, esto cambiará tan pronto como este otoño (2017) una vez que se lance la versión 10 de PostgreSQL. En esta versión, el índice hash finalmente obtuvo soporte para el registro de escritura anticipada; Además, la asignación de memoria se optimizó y el trabajo concurrente se hizo más eficiente.
Eso es verdad Desde PostgreSQL 10 los índices hash tienen soporte completo y se pueden usar sin restricciones. La advertencia ya no se muestra.
Semántica de hash
Pero, ¿por qué el índice hash sobrevivió casi desde el nacimiento de PostgreSQL hasta que 9.6 no se pudo utilizar? La cuestión es que DBMS hace un uso extensivo del algoritmo de hash (específicamente, para combinaciones de hash y agrupaciones), y el sistema debe saber qué función de hash se aplica a qué tipos de datos. Pero esta correspondencia no es estática, y no se puede establecer de una vez por todas, ya que PostgreSQL permite agregar nuevos tipos de datos sobre la marcha. Y este es un método de acceso por hash, donde se almacena esta correspondencia, representada como una asociación de funciones auxiliares con familias de operadores.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
Aunque estas funciones no están documentadas, se pueden usar para calcular el código hash para un valor del tipo de datos apropiado. Por ejemplo, la función "hashtext" si se usa para la familia de operadores "text_ops":
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
Propiedades
Veamos las propiedades del índice hash, donde este método de acceso proporciona al sistema información sobre sí mismo. Proporcionamos consultas la
última vez . Ahora no iremos más allá de los resultados:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Una función hash no retiene la relación de orden: si el valor de una función hash para una clave es menor que para la otra clave, es imposible sacar conclusiones sobre cómo se ordenan las claves. Por lo tanto, en general, el índice hash puede admitir la única operación "igual":
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
En consecuencia, el índice hash no puede devolver datos ordenados ("can_order", "orderable"). El índice hash no manipula NULL por la misma razón: la operación "igual" no tiene sentido para NULL ("search_nulls").
Dado que el índice hash no almacena claves (sino solo sus códigos hash), no se puede usar para acceso de solo índice ("retornable").
Este método de acceso tampoco admite índices de varias columnas ("can_multi_col").
Internos
A partir de la versión 10, será posible buscar en el índice interno hash a través de la extensión "
pageinspect ". Así se verá:
demo=# create extension pageinspect;
La página meta (obtenemos el número de filas en el índice y el número máximo de cubos usados):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
Una página de depósito (obtenemos el número de tuplas vivas y tuplas muertas, es decir, las que se pueden aspirar):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
Y así sucesivamente. Pero apenas es posible descifrar el significado de todos los campos disponibles sin examinar el código fuente. Si desea hacerlo, debe comenzar con
README .
Sigue leyendo .