Hola, me llamo Vladislav y soy miembro del equipo de desarrollo de
Tarantool . Tarantool es un DBMS y un servidor de aplicaciones todo en uno. Hoy voy a contar la historia de cómo implementamos el escalado horizontal en Tarantool mediante el módulo
VShard .
Algunos conocimientos básicos primero.
Hay dos tipos de escalado: horizontal y vertical. Y hay dos tipos de escalado horizontal: replicación y fragmentación. La replicación asegura el escalado computacional mientras que el fragmentación se usa para el escalado de datos.
Sharding también se subdivide en dos tipos: sharding basado en rango y sharding basado en hash.
El particionamiento basado en rango implica que se calcula alguna clave de fragmento para cada registro de clúster. Las teclas de fragmentos se proyectan en una línea recta que se separa en rangos y se asigna a diferentes nodos físicos.
La fragmentación basada en hash es menos complicada: se calcula una función hash para cada registro en un clúster; los registros con la misma función hash se asignan al mismo nodo físico.
Me centraré en el escalado horizontal utilizando el fragmentación basada en hash.
Implementación anterior
Tarantool Shard fue nuestro módulo original para escalado horizontal. Utilizó fragmentos simples basados en hash y claves de fragmentos calculados por clave principal para todos los registros en un clúster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Pero eventualmente Tarantool Shard se volvió incapaz de abordar nuevas tareas.
Primero, uno de nuestros eventuales requisitos se convirtió en la
localidad garantizada
de datos relacionados lógicamente . En otras palabras, cuando tenemos datos relacionados lógicamente, siempre queremos almacenarlos en un solo nodo físico, independientemente de la topología del clúster y los cambios de equilibrio. Fragmento de Tarantool no puede garantizar eso. Calculaba hashes solo con claves primarias, por lo que el reequilibrio podría causar la separación temporal de registros con el mismo hash porque los cambios no se realizan atómicamente.
Esta falta de localidad de datos fue el principal problema para nosotros. Aquí hay un ejemplo. Digamos que hay un banco donde un cliente ha abierto una cuenta. La información sobre la cuenta y el cliente debe almacenarse físicamente juntos para que pueda recuperarse en una sola solicitud o modificarse en una sola transacción, por ejemplo, durante una transferencia de dinero. Si utilizamos el fragmentación tradicional de Tarantool Shard, habrá diferentes valores de función hash para cuentas y clientes. Los datos podrían terminar en nodos físicos separados. Esto realmente complica tanto la lectura como la transacción con los datos de un cliente.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
En el ejemplo anterior, los campos de identificación de las cuentas y el cliente pueden ser inconsistentes. Están conectados por el campo customer_id de la cuenta y el campo id del cliente. El mismo campo de identificación violaría la restricción de unicidad de la clave primaria de la cuenta. Y Shard no puede realizar fragmentación de ninguna otra manera.
Otro problema fue el
lento reacomodamiento , que es el problema fundamental de todos los fragmentos hash. La conclusión es que al cambiar los componentes del clúster, la función de fragmento cambia porque generalmente depende del número de nodos. Entonces, cuando la función cambia, es necesario revisar todos los registros del clúster y volver a calcular la función. También puede ser necesario transferir algunos registros. Y durante la transferencia de datos, ¿ni siquiera sabemos si el registro requerido? En la solicitud, los datos ya se han transferido o se están transfiriendo en este momento. Por lo tanto, durante la reorganización, es necesario realizar solicitudes de lectura con funciones de fragmento antiguas y nuevas. Las solicitudes se manejan dos veces más lento, y esto es inaceptable.
Otro problema con Tarantool Shard fue la baja disponibilidad de lecturas en el caso de falla de nodo en un conjunto de réplicas.
Nueva solución
Creamos
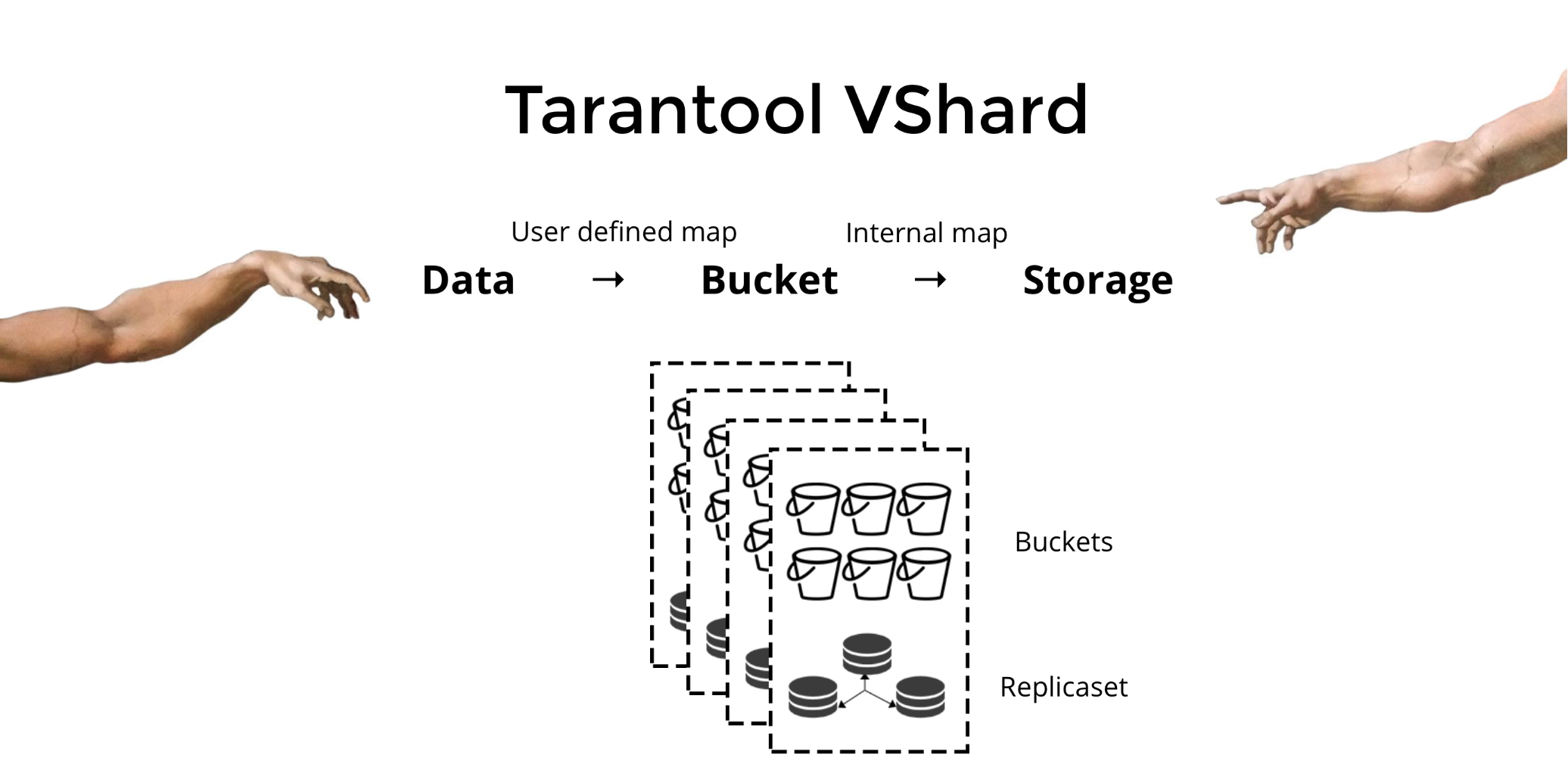
Tarantool VShard para resolver los tres problemas mencionados anteriormente. Su diferencia clave es que su nivel de almacenamiento de datos está virtualizado, es decir, los almacenamientos físicos alojan almacenamientos virtuales, y los registros de datos se asignan sobre los virtuales. Estos almacenamientos se llaman
cubos . El usuario no tiene que preocuparse por lo que se encuentra en un nodo físico dado. Un cubo es una unidad de datos indivisible atómica, como una tupla en el fragmentación tradicional. VShard siempre almacena un depósito completo en un nodo físico, y durante la reorganización migra atómicamente todos los datos de un depósito. Este método asegura la localidad de los datos. Simplemente colocamos los datos en un depósito y siempre podemos estar seguros de que no se separarán durante los cambios del clúster.

¿Cómo ponemos los datos en un cubo? Agreguemos un nuevo campo de identificación de depósito a la tabla para nuestro cliente bancario. Si este valor de campo es el mismo para datos relacionados, todos los registros estarán en un depósito. La ventaja es que podemos almacenar registros con la misma identificación del depósito en diferentes espacios, e incluso en diferentes motores. La localidad de los datos basada en la identificación del depósito está garantizada independientemente del método de almacenamiento.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
¿Por qué es esto tan importante? Cuando se usa el fragmentación tradicional, los datos se extenderían a varios almacenamientos físicos existentes. Para nuestro ejemplo bancario, tendríamos que contactar a cada nodo cuando solicitemos todas las cuentas para un cliente determinado. Entonces obtenemos una complejidad de lectura O (N), donde N es el número de almacenamientos físicos. Es exasperantemente lento.
El uso de cubos y la localidad por ID de cubo hace posible leer los datos necesarios de un nodo utilizando una solicitud, independientemente del tamaño del clúster.

En VShard, calcula su id. De cubo y lo asigna. Para algunas personas, esto es una ventaja, mientras que otras lo consideran una desventaja. Creo que la posibilidad de elegir su propia función para el cálculo del id del depósito es una ventaja.
¿Cuál es la diferencia clave entre los fragmentos tradicionales y los fragmentos virtuales con cubos?
En el primer caso, cuando cambiamos los componentes del clúster, tenemos dos estados: el actual (antiguo) y el nuevo que se implementará. En el proceso de transición, es necesario no solo migrar datos, sino también recalcular la función hash para cada registro. Esto no es muy conveniente porque en un momento dado no sabemos si los datos requeridos ya se han migrado o no. Además, este método no es confiable y los cambios no son atómicos, ya que la migración atómica del conjunto de registros con el mismo valor de función hash requeriría un almacenamiento persistente del estado de migración en caso de que sea necesaria la recuperación. Como resultado, hay conflictos y errores, y la operación debe reiniciarse varias veces.
El fragmentación virtual es mucho más simple. No tenemos dos estados de clúster diferentes; solo tenemos el estado del cubo. El clúster es más flexible, se mueve suavemente de un estado a otro. ¿Hay más de dos estados ahora? (claro) Con la transición suave, es posible cambiar el equilibrio sobre la marcha o eliminar almacenamientos recién agregados. Es decir, el control de equilibrio ha aumentado considerablemente y se ha vuelto más granular.
Uso
Digamos que hemos seleccionado una función para nuestra identificación de depósito y hemos cargado tantos datos en el clúster que no queda espacio. Ahora nos gustaría agregar algunos nodos y mover datos automáticamente a ellos. Así es como lo hacemos en VShard: primero, iniciamos nuevos nodos y ejecutamos Tarantool allí, luego actualizamos nuestra configuración de VShard. Contiene información sobre cada componente del clúster, cada réplica, conjuntos de réplicas, maestros, URI asignados y mucho más. Ahora agregamos nuestros nuevos nodos al archivo de configuración y lo aplicamos a todos los nodos del clúster usando VShard.storage.cfg.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Como recordará, al cambiar el número de nodos en el fragmentación tradicional, la función de fragmentación también cambia. Esto no sucede en VShard. Aquí tenemos un número fijo de almacenamientos virtuales, o cubos. Esta es una constante que elige al iniciar el clúster. Puede parecer que la escalabilidad es, por lo tanto, limitada, pero realmente no lo es. Puede especificar una gran cantidad de cubos, decenas y cientos de miles. Lo importante es saber que debe haber al menos dos órdenes de magnitud más depósitos que el número máximo de conjuntos de réplicas que tendrá en el clúster.
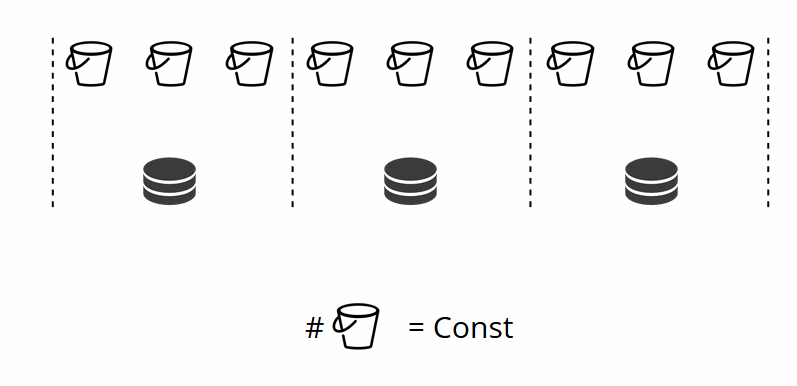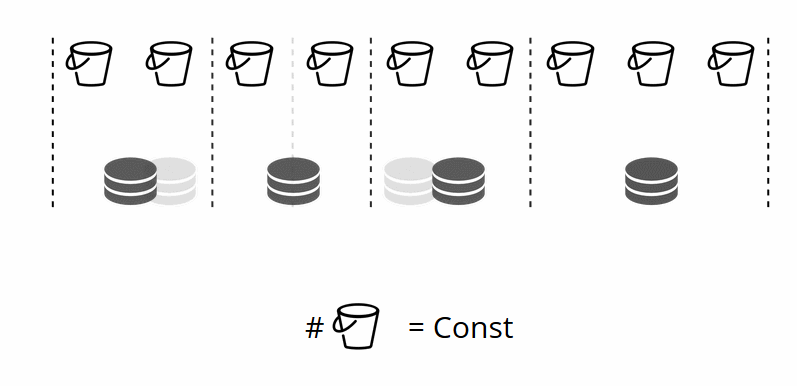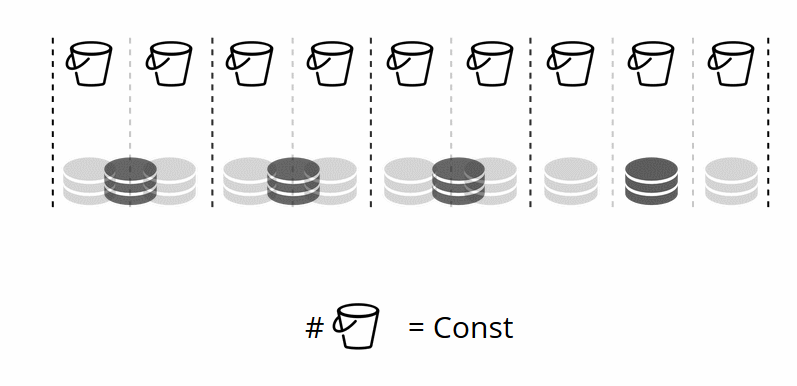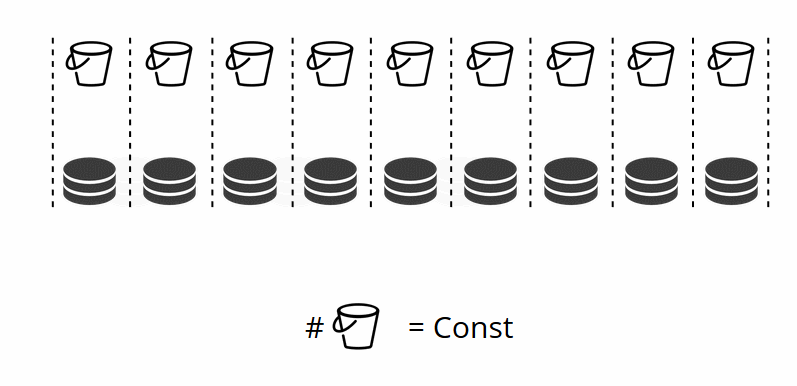
Dado que el número de almacenamientos virtuales no cambia, y la función de fragmento depende solo de este valor, podemos agregar tantos almacenamientos físicos como quisiéramos sin volver a calcular la función de fragmento.
Entonces, ¿cómo se asignan los cubos a los almacenamientos físicos? Si se llama VShard.storage.cfg, un proceso de reequilibrio se activa en uno de los nodos. Este es un proceso analítico que calcula el equilibrio perfecto para el clúster. El proceso va a cada nodo físico y recupera su número de cubos, y luego construye rutas de sus movimientos para equilibrar la asignación. Luego, el reequilibrador envía las rutas a los almacenes sobrecargados, que a su vez comienzan a enviar cubos. Un poco más tarde, el grupo está equilibrado.
En proyectos del mundo real, un equilibrio perfecto puede no alcanzarse tan fácilmente. Por ejemplo, un conjunto de réplicas podría contener menos datos que el otro porque tiene menos capacidad de almacenamiento. En este caso, VShard puede pensar que todo está equilibrado pero, de hecho, el primer almacenamiento está a punto de sobrecargarse. Para contrarrestar esto, hemos proporcionado un mecanismo para corregir las reglas de equilibrio mediante pesas. Se puede asignar un peso a cualquier conjunto de réplica o almacenamiento. Cuando el reequilibrador decide cuántos cubos se deben enviar y dónde, considera las
relaciones de todos los pares de pesos.
Por ejemplo, si un almacenamiento pesa 100 y el otro 200, el segundo almacenará el doble de cubos que el primero. Tenga en cuenta que estoy hablando específicamente de las
relaciones de peso. Los valores absolutos no tienen influencia alguna. Usted elige pesos basados en una distribución del 100% en un clúster: por lo tanto, el 30% para un almacenamiento produciría el 70% para el otro. Puede tomar la capacidad de almacenamiento en gigabytes como base, o puede medir el peso en la cantidad de cubos. Lo más importante es mantener la proporción necesaria.

Este método tiene un efecto secundario interesante: si se asigna un peso cero a un almacenamiento, el reequilibrador hará que este almacenamiento redistribuya todos sus depósitos. A partir de entonces, puede eliminar todo el conjunto de réplicas de la configuración.
Migración de cubo atómico
Tenemos un balde; acepta algunas lecturas y escrituras, y en un momento dado, el reequilibrador solicita su migración a otro almacenamiento. El depósito deja de aceptar solicitudes de escritura; de lo contrario, se actualizaría durante la migración, luego se actualizaría nuevamente durante la migración de actualización, luego la actualización se actualizaría, y así sucesivamente. Por lo tanto, las solicitudes de escritura están bloqueadas, pero aún es posible leer desde el depósito. Los datos ahora se están migrando a la nueva ubicación. Cuando se completa la migración, el depósito comienza a aceptar solicitudes nuevamente. Todavía existe en la ubicación anterior, pero está marcado como basura, y más tarde el recolector de basura lo elimina pieza por pieza.
Hay algunos metadatos almacenados físicamente en el disco que están asociados con cada depósito. Todos los pasos descritos anteriormente se almacenan en el disco, y no importa lo que pase con el almacenamiento, el estado del depósito se restaurará automáticamente.
Puede tener algunas preguntas siguientes:
- ¿Qué sucede con las solicitudes que funcionan con el depósito cuando comienza la migración?
Hay dos tipos de referencias en los metadatos de cada segmento: RO y RW. Cuando un usuario realiza una solicitud a un depósito, indica si el trabajo debe estar en modo de solo lectura o en modo de lectura y escritura. Para cada solicitud, se incrementa el contador de referencia correspondiente.
¿Por qué necesitamos contadores de referencia para solicitudes de escritura? Digamos que se está migrando un cubo y, de repente, el recolector de basura quiere eliminarlo. El recolector de basura reconoce que el contador de referencia está por encima de cero y, por lo tanto, el depósito no se eliminará. Cuando se completan todas las solicitudes, el recolector de basura puede hacer su trabajo.
El contador de referencia para escrituras también asegura que la migración del depósito no se iniciará si hay al menos una solicitud de escritura en proceso. Pero, de nuevo, las solicitudes de escritura podrían venir una tras otra, y el depósito nunca se migraría. Entonces, si el reequilibrador desea mover el depósito, el sistema bloquea las nuevas solicitudes de escritura mientras espera que se completen las solicitudes actuales durante un cierto período de tiempo de espera. Si las solicitudes no se completan dentro del tiempo de espera especificado, el sistema comenzará a aceptar nuevas solicitudes de escritura nuevamente mientras pospone la migración del depósito. De esta manera, el reequilibrador intentará migrar el depósito hasta que la migración se realice correctamente.
VShard tiene una API bucket_ref de bajo nivel en caso de que necesite algo más que capacidades de alto nivel. Si realmente desea hacer algo usted mismo, consulte esta API. - ¿Es posible dejar los registros desbloqueados?
No Si el depósito contiene datos críticos y requiere acceso de escritura permanente, entonces tendrá que bloquear su migración por completo. Tenemos una función bucket_pin para hacer precisamente eso. Conecta el depósito al conjunto de réplica actual para que el reequilibrador no pueda migrar el depósito. En este caso, los cubos adyacentes podrán moverse sin restricciones.

Un bloqueo de conjunto de réplica es una herramienta aún más fuerte que bucket_pin. Esto ya no se hace en el código sino en la configuración. Un bloqueo de conjunto de réplicas deshabilita la migración de cualquier depósito dentro / fuera del conjunto de réplica. Por lo tanto, todos los datos estarán disponibles permanentemente para escrituras.

VShard.router
VShard consta de dos submódulos: VShard.storage y VShard.router. Podemos crear y escalar estos de forma independiente en una sola instancia. Al solicitar un clúster, no sabemos dónde se encuentra un depósito determinado, y VShard.router lo buscará por ID de depósito para nosotros.
Volvamos a nuestro ejemplo, el grupo bancario con cuentas de clientes. Me gustaría poder obtener todas las cuentas de un determinado cliente del clúster. Esto requiere una función estándar para la búsqueda local:

Busca todas las cuentas del cliente por su id. Ahora tengo que decidir dónde debo ejecutar la función. Para este propósito, calculo la identificación del depósito por el identificador del cliente en mi solicitud y le pido a VShard.router que llame a la función en el almacenamiento donde se encuentra el depósito con la identificación del depósito objetivo. El submódulo tiene una tabla de enrutamiento que describe las ubicaciones de los depósitos en los conjuntos de réplica. VShard.router redirige mi solicitud.
Ciertamente, puede suceder que el fragmentación comience en este momento exacto y que los cubos comiencen a moverse. El enrutador en segundo plano actualiza gradualmente la tabla en fragmentos grandes al solicitar tablas de depósito actuales de los almacenes.
Incluso podemos solicitar un depósito recientemente migrado, por el cual el enrutador aún no ha actualizado su tabla de enrutamiento. En este caso, solicitará el almacenamiento anterior, que redirigirá el enrutador a otro almacenamiento o simplemente responderá que no tiene los datos necesarios. Luego, el enrutador pasará por cada almacenamiento en busca del cubo requerido. Y ni siquiera notaremos un error en la tabla de enrutamiento.
Leer conmutación por error
Recordemos nuestros problemas iniciales:
- Sin localidad de datos. Resuelto mediante cubos.
- Proceso de reacomodamiento empantanado y reteniendo todo. Implementamos la transferencia de datos atómicos mediante cubos y eliminamos el recálculo de la función de fragmento.
- Lea la conmutación por error.
VShard.router resuelve el último problema, compatible con el subsistema de conmutación por error de lectura automática.
De vez en cuando, el enrutador hace ping a los almacenamientos especificados en la configuración. Digamos, por ejemplo, que el enrutador no puede hacer ping a uno de ellos. El enrutador tiene una conexión de respaldo en caliente para cada réplica, por lo que si la réplica actual no responde, simplemente cambia a otra. Las solicitudes de lectura se procesarán normalmente porque podemos leer en las réplicas (pero no escribir). Y podemos especificar la prioridad para las réplicas como un factor para que el enrutador elija la conmutación por error para las lecturas. Esto se hace por medio de la zonificación.

Asignamos un número de zona a cada réplica y cada enrutador y especificamos una tabla donde indicamos la distancia entre cada par de zonas. Cuando el enrutador decide a dónde debe enviar una solicitud de lectura, selecciona una réplica en la zona más cercana.
Así es como se ve en la configuración:

En general, puede solicitar cualquier réplica, pero si el clúster es grande, complejo y altamente distribuido, la zonificación puede ser muy útil. Se pueden seleccionar diferentes racks de servidores como zonas para que el tráfico no sobrecargue la red. Alternativamente, se pueden seleccionar puntos geográficamente aislados.
La zonificación también ayuda cuando las réplicas demuestran diferentes comportamientos. Por ejemplo, cada conjunto de réplicas tiene una réplica de respaldo que no debe aceptar solicitudes, sino que solo debe almacenar una copia de los datos. En este caso, lo colocamos en una zona lejos de todos los enrutadores de la tabla para que el enrutador no aborde esta réplica a menos que sea absolutamente necesario.
Escribir failover
Ya hemos hablado sobre la conmutación por error de lectura. ¿Qué pasa con la escritura de conmutación por error al cambiar el maestro? En VShard, la imagen no es tan optimista como antes: la selección maestra no está implementada, por lo que tendremos que hacerlo nosotros mismos. Cuando de alguna manera hemos designado un maestro, la instancia designada ahora debería asumir el control como maestro. Luego, actualizamos la configuración especificando master = false para el maestro anterior y master = true para el nuevo, aplicamos la configuración mediante VShard.storage.cfg y la compartimos con cada almacenamiento. Todo lo demás se hace automáticamente. El viejo maestro deja de aceptar solicitudes de escritura e inicia la sincronización con el nuevo, porque puede haber datos que ya se han aplicado en el viejo maestro pero no en el nuevo. Después de eso, el nuevo maestro está a cargo y comienza a aceptar solicitudes, y el viejo maestro es una réplica. Así es como funciona la conmutación por error de escritura en VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
¿Cómo rastreamos estos diversos eventos?
VShard.storage.info y VShard.router.info son suficientes.
VShard.storage.info muestra información en varias secciones.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
La primera sección es para replicación. Aquí puede ver el estado del conjunto de réplicas donde se llama la función: su retraso de replicación, sus conexiones disponibles y no disponibles, su configuración maestra, etc.
En la sección de depósito, puede ver en tiempo real el número de depósitos que se migran hacia / desde el conjunto de réplica actual, el número de depósitos que funcionan en modo normal, el número de depósitos marcados como basura y el número de depósitos anclados.
La sección Alertas muestra los problemas que VShard pudo determinar por sí mismo: "el maestro no está configurado", "hay un nivel de redundancia insuficiente", "el maestro está allí, pero todas las réplicas fallaron", etc.
Y la última sección (q: ¿es este "estado"?) Es una luz que se vuelve roja cuando todo sale mal. Es un número de cero a tres, por lo que un número mayor es peor.
VShard.router.info tiene las mismas secciones, pero su significado es algo diferente.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
La primera sección es para la replicación, aunque no contiene información sobre los retrasos de replicación, sino más bien información sobre disponibilidad: conexiones de enrutador a un conjunto de réplica; conexión en caliente y conexión de respaldo en caso de que falle el maestro; el maestro seleccionado; y el número de depósitos RW disponibles y depósitos RO en cada conjunto de réplicas.
La sección del depósito muestra el número total de depósitos de lectura-escritura y solo lectura disponibles actualmente para este enrutador; el número de cubos con una ubicación desconocida; y el número de depósitos con una ubicación conocida pero sin conexión con el conjunto de réplicas necesario.
La sección de alertas describe principalmente conexiones, eventos de conmutación por error y depósitos no identificados.
Finalmente, también está el estado simple? Indicador de cero a tres.
¿Qué necesitas para usar VShard?
Primero debe seleccionar un número constante de cubos. ¿Por qué no simplemente configurarlo en int32_max? Debido a que los metadatos se almacenan junto con cada depósito, 30 bytes en almacenamiento y 16 bytes en el enrutador. Cuantos más cubos tenga, más espacio ocuparán los metadatos. Pero al mismo tiempo, el tamaño del depósito será más pequeño, lo que significa una mayor granularidad del clúster y una mayor velocidad de migración por depósito. Por lo tanto, debe elegir qué es más importante para usted y el nivel de escalabilidad que es necesario.
En segundo lugar, debe seleccionar una función de fragmento para calcular la identificación del depósito. Las reglas son las mismas que cuando se selecciona una función de fragmento en el fragmento tradicional, ya que un depósito aquí es el mismo que el número fijo de almacenamientos en el fragmento tradicional. La función debe distribuir uniformemente los valores de salida, de lo contrario, el crecimiento del tamaño de la cubeta no se equilibrará y VShard solo opera con la cantidad de cubetas. Si no equilibra su función de fragmento, deberá migrar los datos de un depósito a otro y cambiar la función de fragmento. Por lo tanto, debe elegir con cuidado.
Resumen
VShard asegura:
- localidad de datos
- reabastecimiento atómico
- mayor flexibilidad de clúster
- failover de lectura automática
- Controladores de cubos múltiples.
VShard está en desarrollo activo. Algunas tareas planificadas ya se están implementando. La primera tarea es
el equilibrio de carga del enrutador . Si hay muchas solicitudes de lectura, no siempre se recomienda dirigirlas al maestro. El enrutador debe equilibrar las solicitudes de diferentes réplicas de lectura por sí mismo.
La segunda tarea es la
migración del depósito sin bloqueo . Ya se ha implementado un algoritmo que ayuda a mantener los cubos desbloqueados incluso durante la migración. El depósito se bloqueará solo al final para documentar la migración en sí.
La tercera tarea es
la aplicación atómica de la configuración . No es conveniente ni atómico aplicar la configuración por separado porque es posible que parte del almacenamiento no esté disponible, y si la configuración no se aplica, ¿qué hacemos a continuación? Es por eso que estamos trabajando en un mecanismo para la transferencia automática de configuración.