
Cuando diagnosticamos problemas en un clúster de Kubernetes, a menudo notamos que a veces uno de los nodos del clúster llovizna * y, por supuesto, esto es raro y extraño. Entonces llegamos a la necesidad de una herramienta que hiciera
ping de cada nodo a cada nodo y presentara los resultados de su trabajo en forma
de métricas de Prometheus . Solo tendríamos que dibujar gráficos en Grafana y localizar rápidamente el nodo fallido (y, si es necesario, eliminar todos los pods y luego hacer el trabajo correspondiente **) ...
* Por "llovizna" entiendo que el nodo puede entrar en estado NotReady y de repente volver a trabajar. O, por ejemplo, parte del tráfico en los pods puede no llegar a los pods en los nodos vecinos.** ¿Por qué surgen tales situaciones? Una de las causas comunes puede ser problemas de red en el conmutador en el centro de datos. Por ejemplo, una vez en Hetzner configuramos un conmutador virtual, pero en un momento maravilloso uno de los nodos dejó de ser accesible en este puerto: debido a esto, resultó que el nodo era completamente inaccesible en la red local.Además, nos gustaría
lanzar un servicio de este tipo directamente en Kubernetes , de modo que toda la implementación se
realice mediante la instalación de Helm-chart. (Anticipando preguntas: si usamos el mismo Ansible, tendríamos que escribir roles para varios entornos: AWS, GCE, bare metal ...) Al buscar un poco en Internet herramientas listas para la tarea, no encontramos nada adecuado. Por lo tanto, hicieron lo suyo.
Script y configuraciones
Por lo tanto, el componente principal de nuestra solución es un
script que monitorea los cambios en cualquier nodo en el campo
.status.addresses y, si un campo ha cambiado para algún nodo (es decir, se ha agregado un nuevo nodo), envía los valores de Helm al gráfico usando esta lista de nodos en forma de ConfigMap:
--- apiVersion: v1 kind: ConfigMap metadata: name: node-ping-config namespace: kube-prometheus data: nodes.json: > {{ .Values.nodePing.nodes | toJson }}
Script Python en sí mismo: Se
ejecuta en cada nodo y envía paquetes ICMP a todas las demás instancias de clúster de Kubernetes 2 veces por segundo, y los resultados se escriben en los archivos de texto.
El script está incluido en la
imagen de Docker :
FROM python:3.6-alpine3.8 COPY rootfs / WORKDIR /app RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping ENTRYPOINT ["python3", "/app/node-ping.py"]
Además, se creó una cuenta de servicio y un rol para ella, que permite recibir solo una lista de nodos (para conocer sus direcciones):
--- apiVersion: v1 kind: ServiceAccount metadata: name: node-ping namespace: kube-prometheus --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:node-ping rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:kube-node-ping subjects: - kind: ServiceAccount name: node-ping namespace: kube-prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-prometheus:node-ping
Finalmente, necesita
DaemonSet , que se ejecuta en todas las instancias del clúster:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: node-ping namespace: kube-prometheus labels: tier: monitoring app: node-ping version: v1 spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: node-ping spec: terminationGracePeriodSeconds: 0 tolerations: - operator: "Exists" serviceAccountName: node-ping priorityClassName: cluster-low containers: - resources: requests: cpu: 0.10 image: private-registry.flant.com/node-ping/node-ping-exporter:v1 imagePullPolicy: Always name: node-ping env: - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: PROMETHEUS_TEXTFILE_DIR value: /node-exporter-textfile/ - name: PROMETHEUS_TEXTFILE_PREFIX value: node-ping_ volumeMounts: - name: textfile mountPath: /node-exporter-textfile - name: config mountPath: /config volumes: - name: textfile hostPath: path: /var/run/node-exporter-textfile - name: config configMap: name: node-ping-config imagePullSecrets: - name: antiopa-registry
Resumen de trazos en palabras:
- Resultados del script Python, es decir los archivos de texto ubicados en la máquina host en el directorio
/var/run/node-exporter-textfile textfile entran en DaemonSet node-exporter. Los argumentos para ejecutarlo indican --collector.textfile.directory /host/textfile , donde /host/textfile es el hostPath en /var/run/node-exporter-textfile . (Puede leer sobre el recopilador de archivos de texto en el exportador de nodos aquí ). - Como resultado, el exportador de nodos lee estos archivos y Prometheus recopila todos los datos del exportador de nodos.
Que paso
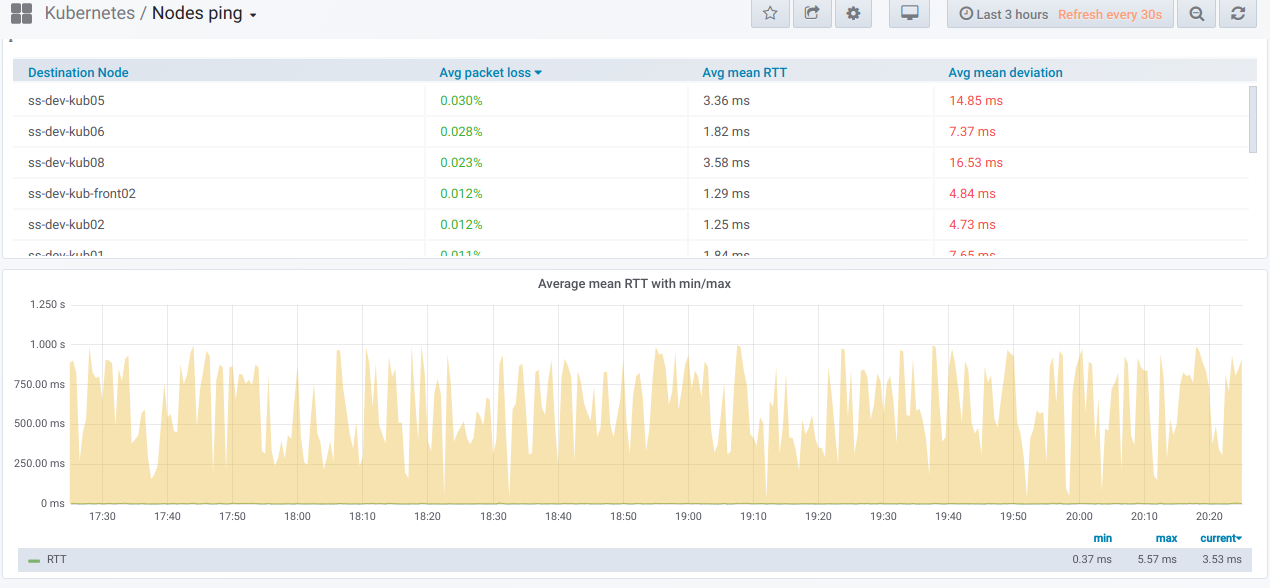
Ahora, al resultado tan esperado. Cuando se crearon tales métricas, podemos mirarlas y, por supuesto, dibujar gráficos visuales. Así es como se ve.
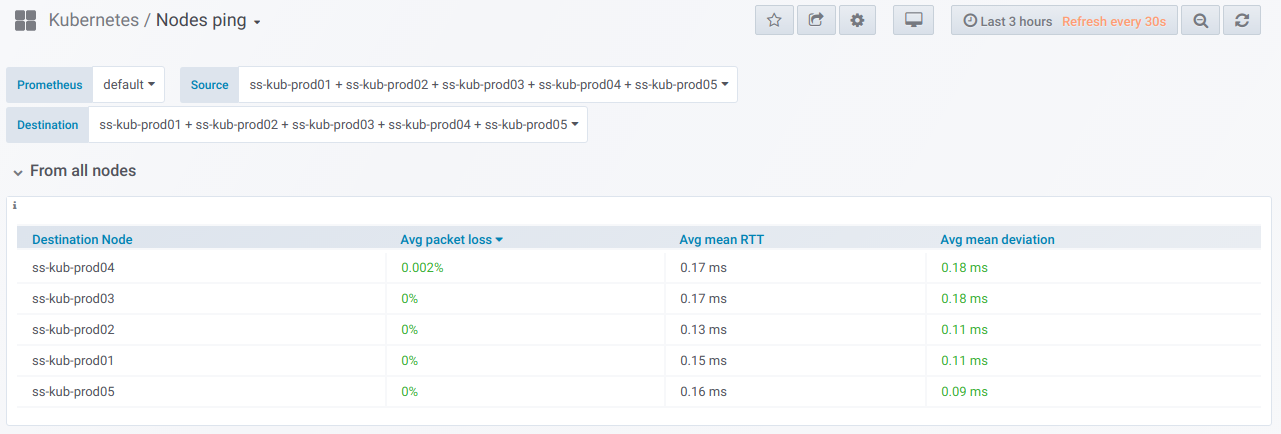
En primer lugar, hay un bloque general con la capacidad (usando el selector) de seleccionar una lista de nodos
desde los cuales se realiza el ping y
en el cual. Esta es la
tabla de resumen para hacer ping entre los nodos seleccionados durante el período especificado en el panel de Grafana:
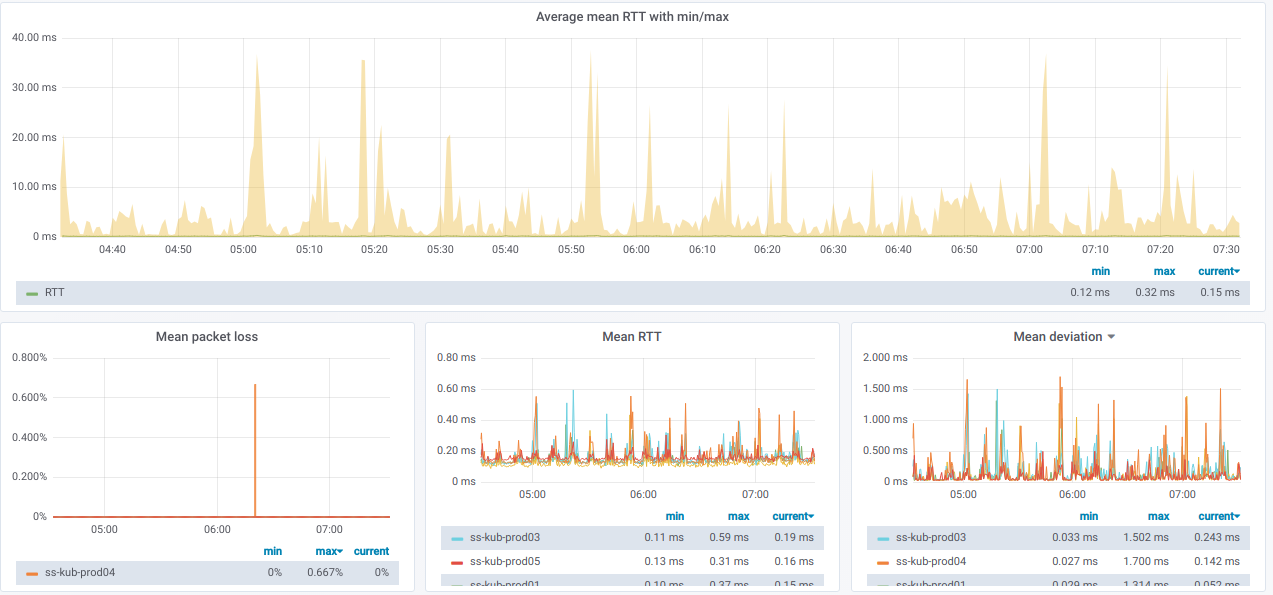
Y aquí están los gráficos con información general
sobre los nodos seleccionados :
También tenemos una lista de líneas, cada una de las cuales es un gráfico
para un nodo separado del selector de
nodo de origen :

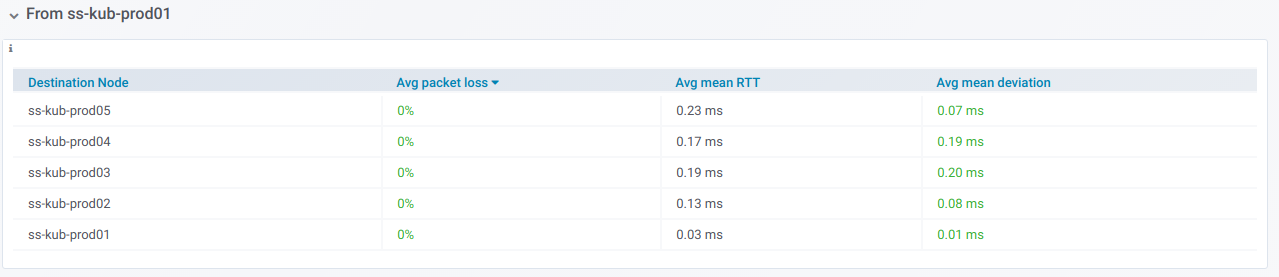
Si expande dicha línea, puede ver información sobre pings
desde un nodo específico a todos los demás que se seleccionaron en el selector de
nodos de destino :
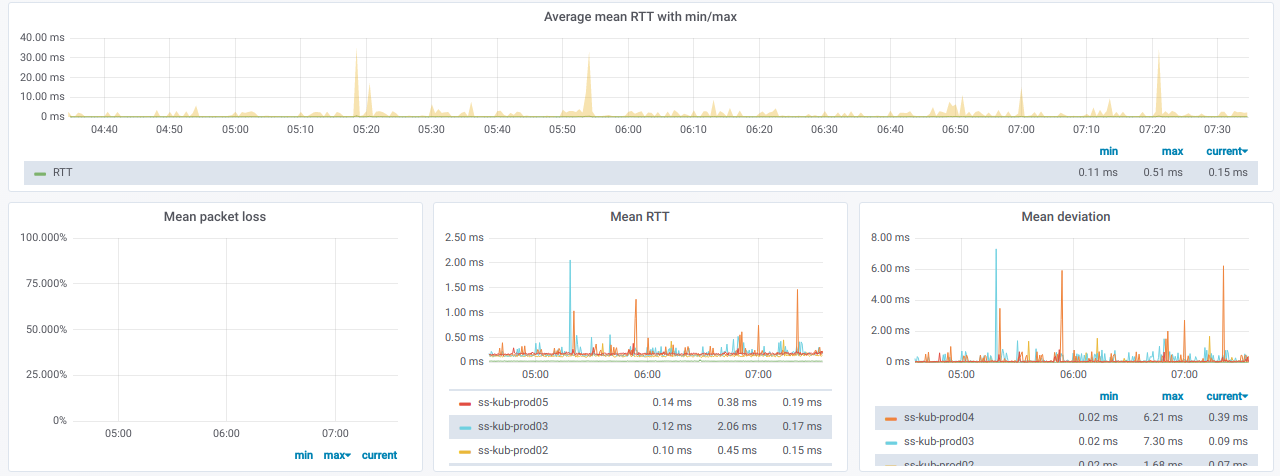
Esta información está en gráficos:
Finalmente, ¿cómo serán los gráficos apreciados con un ping pobre entre nodos?
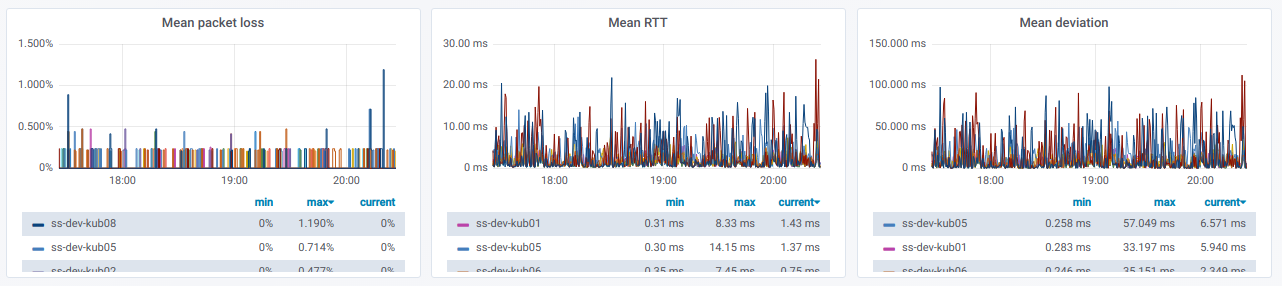
Si observa esto en un entorno real, es hora de descubrir las razones.
PS
Lea también en nuestro blog: