
Muchos clientes que alquilan recursos en la nube de nosotros usan Check Points virtuales. Con su ayuda, los clientes resuelven varios problemas: alguien controla el acceso del segmento del servidor a Internet o publica sus servicios para nuestro equipo. Alguien necesita ejecutar todo el tráfico a través del blade IPS, mientras que alguien necesita Check Point como una puerta de enlace VPN para acceder a los recursos internos en el centro de datos desde las sucursales. Hay quienes necesitan proteger su infraestructura en la nube para aprobar la certificación de acuerdo con FZ-152, pero les contaré esto por separado.
De servicio, participo en el apoyo y la administración de Check Points. Hoy les diré qué considerar al implementar un clúster de puntos de control en un entorno virtual. Me referiré a momentos del nivel de virtualización, red, configuración de Check Point y monitoreo.
No prometo descubrir América: hay mucho en las recomendaciones y mejores prácticas del vendedor. Pero nadie los lee), así que condujeron.
Modo de clúster
Tenemos Check Points en vivo en grupos. La instalación más común es un grupo de dos nodos en modo de espera activa. Si algo le sucede al nodo activo, se vuelve inactivo y el nodo en espera se enciende. El cambio a un nodo "de repuesto" generalmente ocurre debido a problemas de sincronización entre los miembros del clúster, el estado de las interfaces, la política de seguridad establecida, simplemente debido a la gran carga en el equipo.
En un clúster de dos nodos, no utilizamos el modo activo-activo.
Si uno de los nodos cae, es posible que el nodo superviviente simplemente no pueda soportar la doble carga, y luego lo perderemos todo. Si realmente quiere activo-activo, entonces el clúster debe tener al menos 3 nodos.
Configuración de red y virtualización
El tráfico de multidifusión entre las interfaces SYNC de los miembros del clúster está permitido en los equipos de red. Si el tráfico de multidifusión no es posible, se utiliza el protocolo de sincronización (CCP). Los nodos en el clúster de Check Point se sincronizan entre sí. Los mensajes sobre cambios se transmiten de nodo a nodo a través de multidifusión. Check Point utiliza una implementación de multidifusión no estándar (se utiliza una dirección IP sin multidifusión). Debido a esto, algunos equipos, como el switch Cisco Nexus, no entienden estos mensajes y, por lo tanto, los bloquean. En este caso, cambie a transmisión.
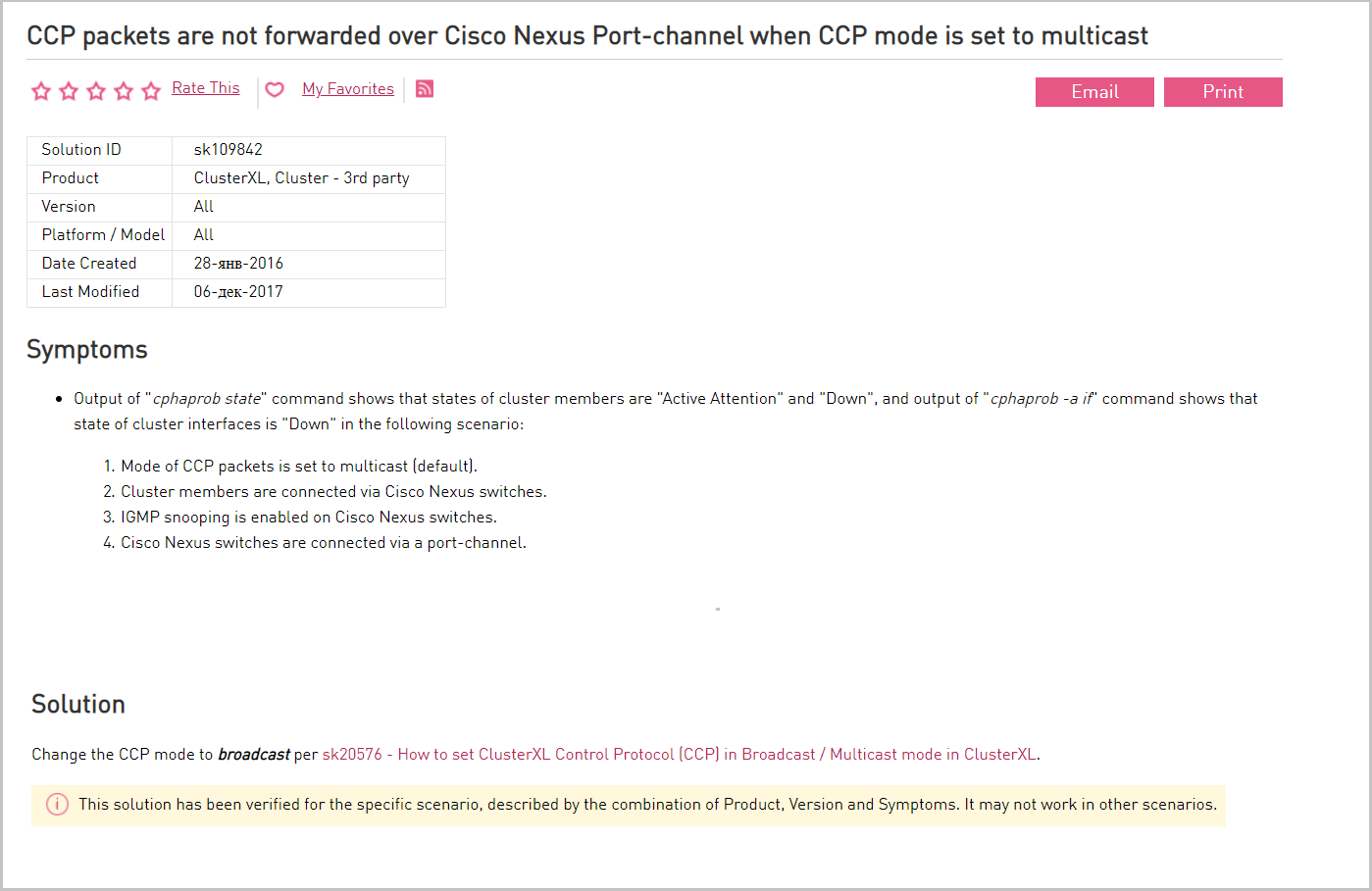 Descripción del problema con Cisco Nexus y sus soluciones en el portal del proveedor.
Descripción del problema con Cisco Nexus y sus soluciones en el portal del proveedor.En el nivel de virtualización, también permitimos el paso del tráfico de multidifusión. Si la multidifusión está prohibida para la sincronización de clúster (CCP), utilice la transmisión.
En la consola de Check Point, con el comando cphaprob -a if, puede ver la configuración de CPP y su modo de funcionamiento (multidifusión o difusión). Para cambiar el modo operativo, use el comando de transmisión cphaconf set_ccp.
 Los nodos del clúster deben estar en diferentes hosts ESXi.
Los nodos del clúster deben estar en diferentes hosts ESXi. Aquí todo está claro: cuando el host físico cae, el segundo nodo continúa funcionando. Esto se puede lograr utilizando las reglas anti-afinidad de DRS.
Dimensiones de la máquina virtual en la que se ejecutará Check Point. Las recomendaciones del proveedor son 2 vCPU y 6 GB, pero esto es para una configuración mínima, por ejemplo, si tiene un firewall con un ancho de banda mínimo. En nuestra experiencia de implementación, cuando se usan múltiples blades de software, es aconsejable usar al menos 4 vCPU, 8 GB de RAM.
En un nodo, asignamos un promedio de 150 GB de disco. Al implementar un punto de control virtual, el disco se divide y podemos ajustar la cantidad de espacio asignado para el intercambio del sistema, la raíz del sistema, los registros, la copia de seguridad y la actualización.
Cuando aumenta la raíz del sistema, también es necesario aumentar la partición de copia de seguridad y actualización para mantener la proporción entre ellas. Si no se respeta la proporción, es posible que la siguiente copia de seguridad no se ajuste al disco.
Aprovisionamiento de disco: aprovisionamiento grueso Lazy Zeroed. Check Point genera muchos eventos y registros, cada segundo aparecen 1000 entradas. Debajo de ellos, es mejor reservar un lugar de inmediato. Para hacer esto, al crear una máquina virtual, le asignamos un disco utilizando la tecnología Thick Provisioning, es decir. Reservamos espacio en el almacenamiento físico en el momento de la creación del disco.
Reserva de recursos configurada al 100% para Check Point durante la migración entre hosts ESXi. Recomendamos que reserve el 100% de los recursos para que la máquina virtual en la que se implementa Check Point no compita por los recursos con otras máquinas virtuales en el host.
Misceláneos Usamos la versión Check Point de R77.30. Para ello, se recomienda utilizar RedHat Enterprise Linux versión 5 (64 bits) como sistema operativo invitado en una máquina virtual. Desde controladores de red: VMXNET3 o Intel E1000.
Configuración de punto de verificación
Las últimas actualizaciones de Check Point se instalan en las puertas de enlace y el servidor de administración. Busque actualizaciones a través de CPUSE.
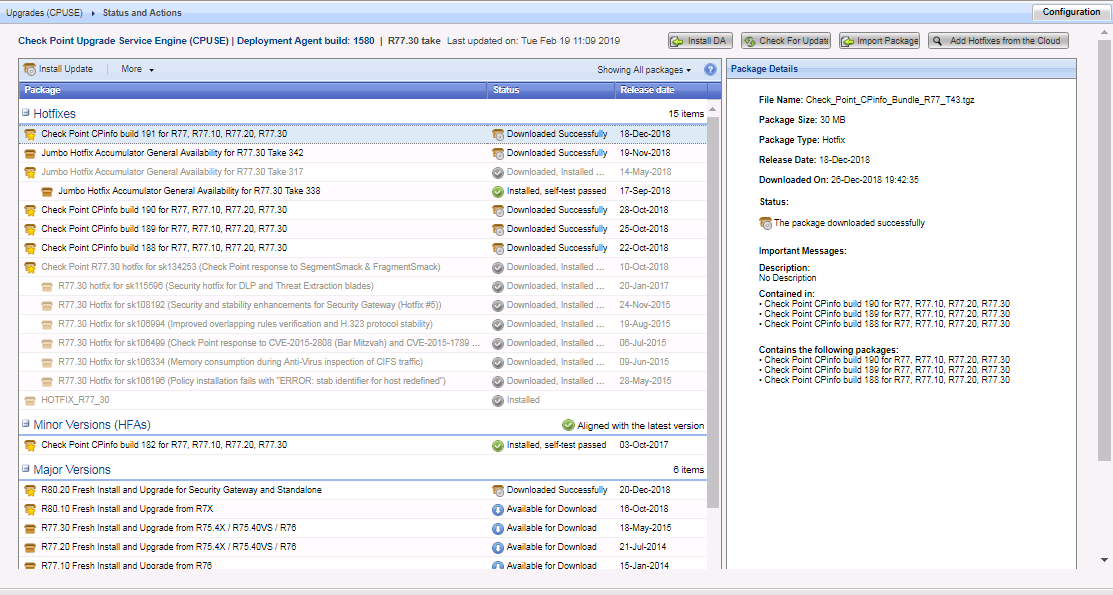
Con Verifier, verificamos que el paquete de servicio que estamos a punto de instalar no entre en conflicto con el sistema.

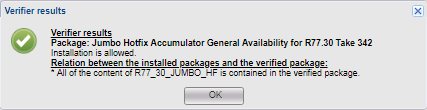
Verificador, por supuesto, es algo bueno, pero hay matices. Algunas actualizaciones no son compatibles con el complemento, pero Verifier no mostrará estos conflictos y permitirá la actualización. Al final de la actualización, obtendrá un error, y solo de él descubrirá qué impide la actualización. Por ejemplo, esta situación se produjo con el paquete de servicio MABDA_001 (Mobile Access Blade Deployment Agent), que resuelve el problema de iniciar Java Plugin en navegadores que no sean IE.
Configuramos actualizaciones automáticas diarias de firmas para IPS y otros blades de software. Check Point lanza firmas que pueden usarse para detectar o bloquear nuevas vulnerabilidades. A las vulnerabilidades se les asigna automáticamente un nivel de criticidad. De acuerdo con este nivel y el filtro establecido, el sistema decide si detectar o bloquear la firma. Aquí es importante no exagerar con los filtros, verificar periódicamente y hacer ajustes para que el tráfico legítimo no se bloquee.
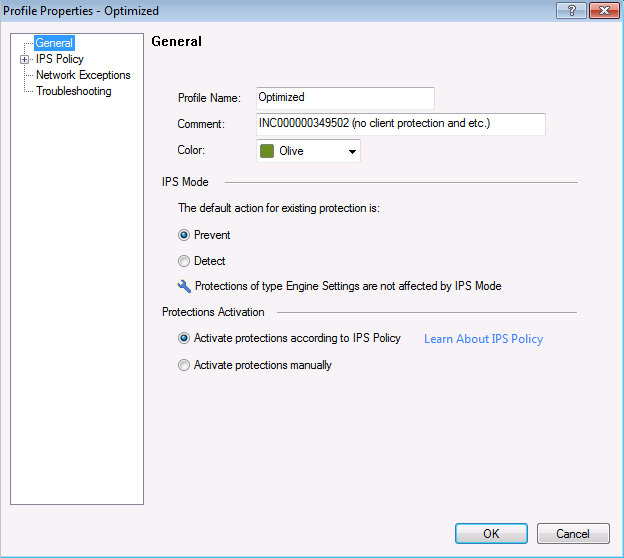 Perfil IPS, donde seleccionamos la acción con respecto a la firma de acuerdo con sus parámetros.
Perfil IPS, donde seleccionamos la acción con respecto a la firma de acuerdo con sus parámetros.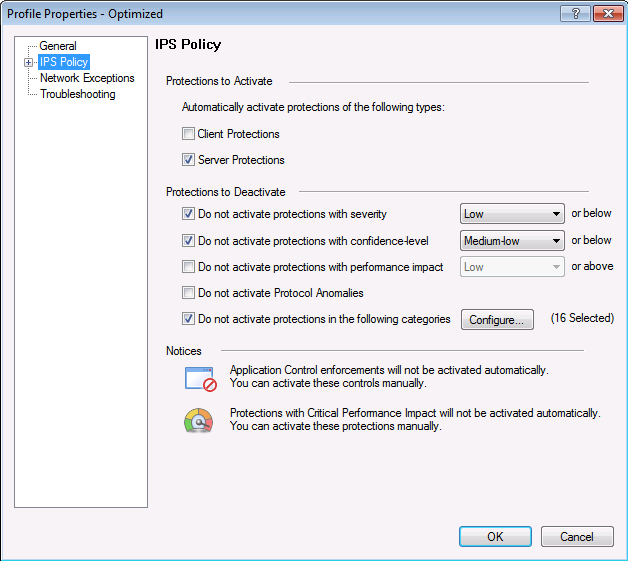 Configuración de políticas para este perfil IPS de acuerdo con la configuración de la firma: nivel de gravedad, impacto en el rendimiento, etc.El hardware Check Point está configurado con el protocolo de sincronización horaria NTP.
Configuración de políticas para este perfil IPS de acuerdo con la configuración de la firma: nivel de gravedad, impacto en el rendimiento, etc.El hardware Check Point está configurado con el protocolo de sincronización horaria NTP. Según las
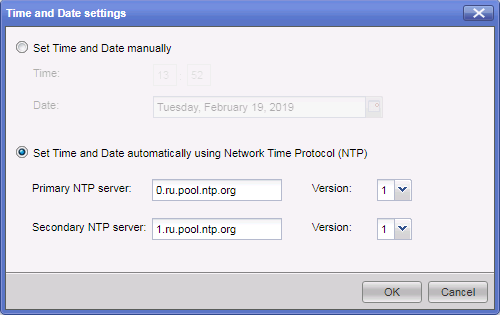
recomendaciones , Check Point debe usar un servidor NTP externo para sincronizar la hora en el equipo. Esto se puede hacer a través del portal web gaia.
El tiempo configurado incorrectamente puede hacer que el clúster no esté sincronizado. Si no es el momento adecuado, es extremadamente inconveniente buscar la entrada de registro que nos interesa. Cada entrada en los registros de eventos está marcada con una llamada marca de tiempo.
 Evento inteligente configurado para alertas sobre IPS, Control de aplicaciones, Anti-Bot, etc.
Evento inteligente configurado para alertas sobre IPS, Control de aplicaciones, Anti-Bot, etc. Este es un módulo separado con su propia licencia. Si tiene uno, su uso es conveniente para visualizar información sobre el funcionamiento de todos los blades y dispositivos de software. Por ejemplo, los ataques, la cantidad de operaciones de IPS, el nivel de criticidad de las amenazas, qué aplicaciones prohibidas son utilizadas por los usuarios, etc.
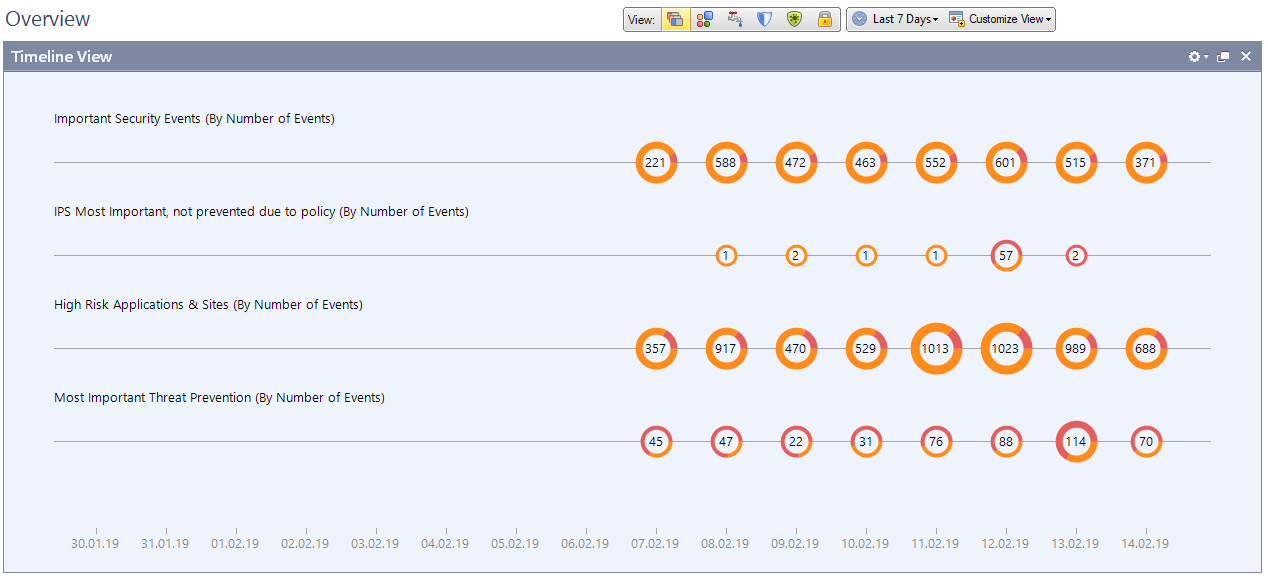
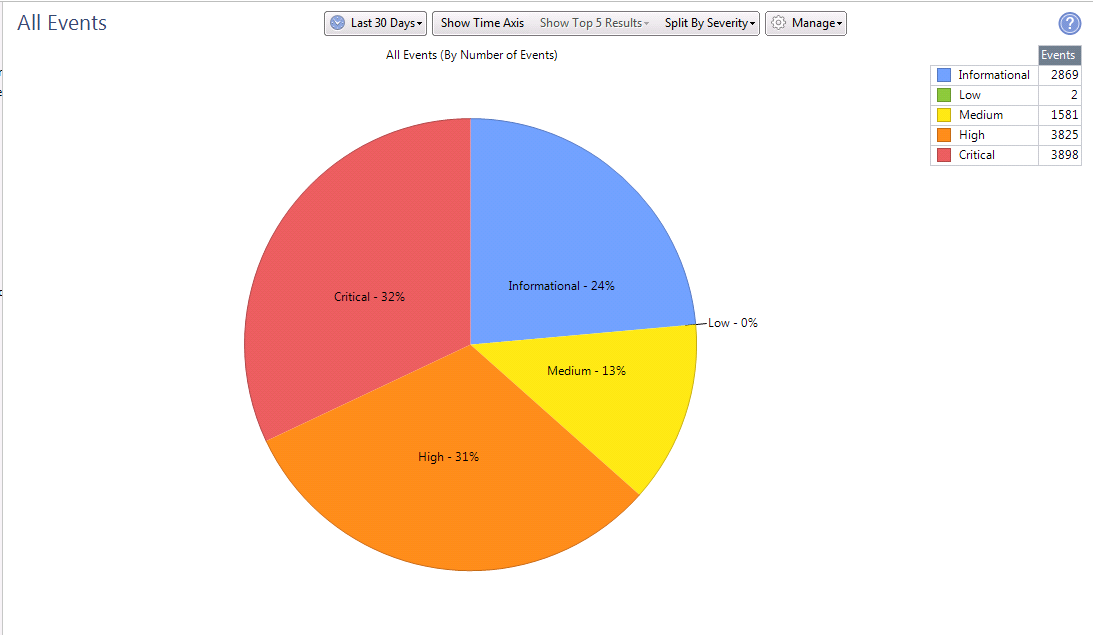 Estas son estadísticas de 30 días según el número de firmas y el grado de su criticidad.
Estas son estadísticas de 30 días según el número de firmas y el grado de su criticidad.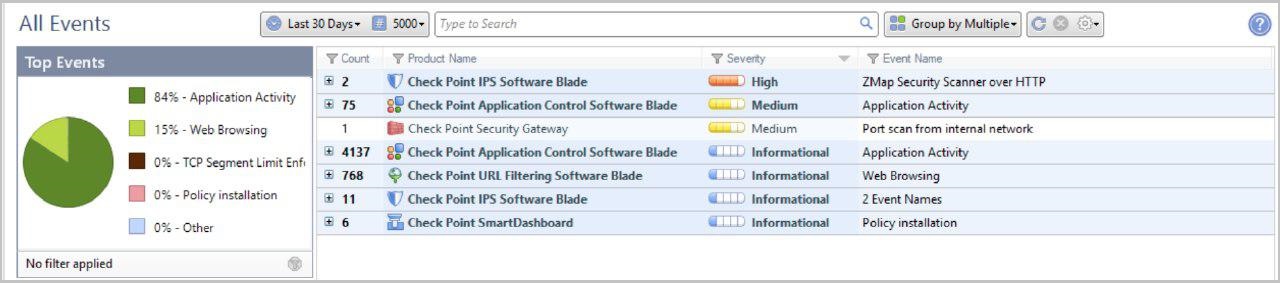 Información más detallada sobre las firmas detectadas en cada blade de software.
Información más detallada sobre las firmas detectadas en cada blade de software.Monitoreo
Es importante monitorear al menos los siguientes parámetros:
- estado de clúster;
- disponibilidad de componentes de Check Point;
- Carga de la CPU
- espacio restante en disco;
- memoria libre
Check Point tiene una hoja de software separada: Smart Monitoring (licencia separada). En él, también puede monitorear la disponibilidad de componentes de Check Point, cargas en blades individuales y estados de licencia.
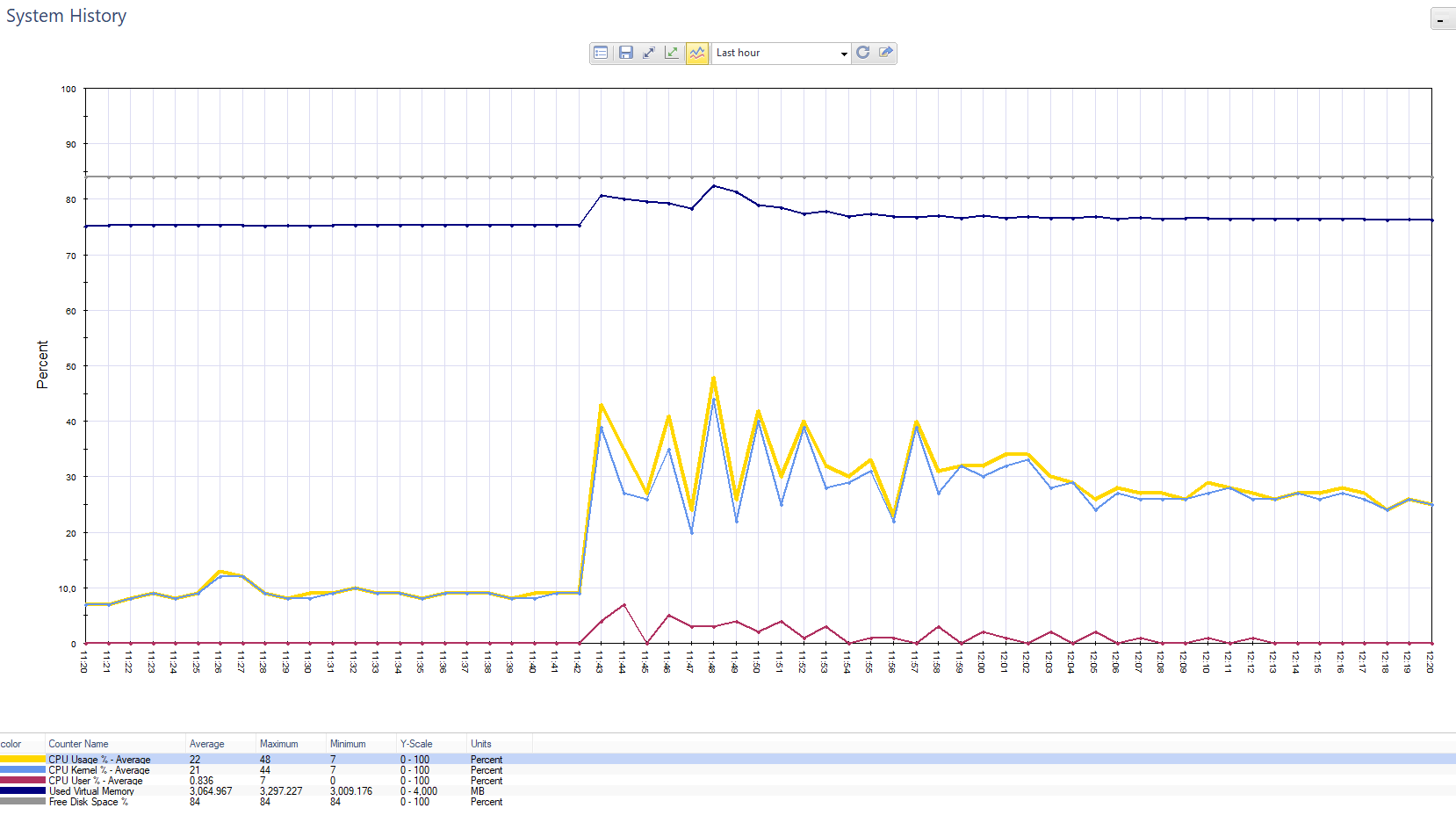 Gráfico de carga Chek Point. Splash: este es el cliente que envió notificaciones push a 800 mil clientes.
Gráfico de carga Chek Point. Splash: este es el cliente que envió notificaciones push a 800 mil clientes. El gráfico de la carga en el blade de Firewall en la misma situación.
El gráfico de la carga en el blade de Firewall en la misma situación.El monitoreo también se puede configurar a través de servicios de terceros. Por ejemplo, también usamos Nagios, donde monitoreamos:
- disponibilidad de red de equipos;
- Disponibilidad de dirección de clúster
- Carga de CPU por núcleos. Al descargar más del 70%, llega una alerta por correo electrónico. Una carga tan alta puede indicar tráfico específico (vpn, por ejemplo). Si esto se repite con frecuencia, entonces quizás no haya suficientes recursos y valga la pena expandir el grupo.
- RAM libre. Si queda menos del 80%, lo descubriremos.
- carga de disco en ciertas particiones, por ejemplo var / log. Si pronto se obstruye, entonces es necesario expandirse.
- Split Brain (a nivel de clúster). Monitoreamos el estado cuando ambos nodos se activan y la sincronización entre ellos desaparece.
- Modo de alta disponibilidad: supervisamos que el clúster esté en modo de espera activo. Observamos los estados de los nodos: activo, en espera, inactivo.
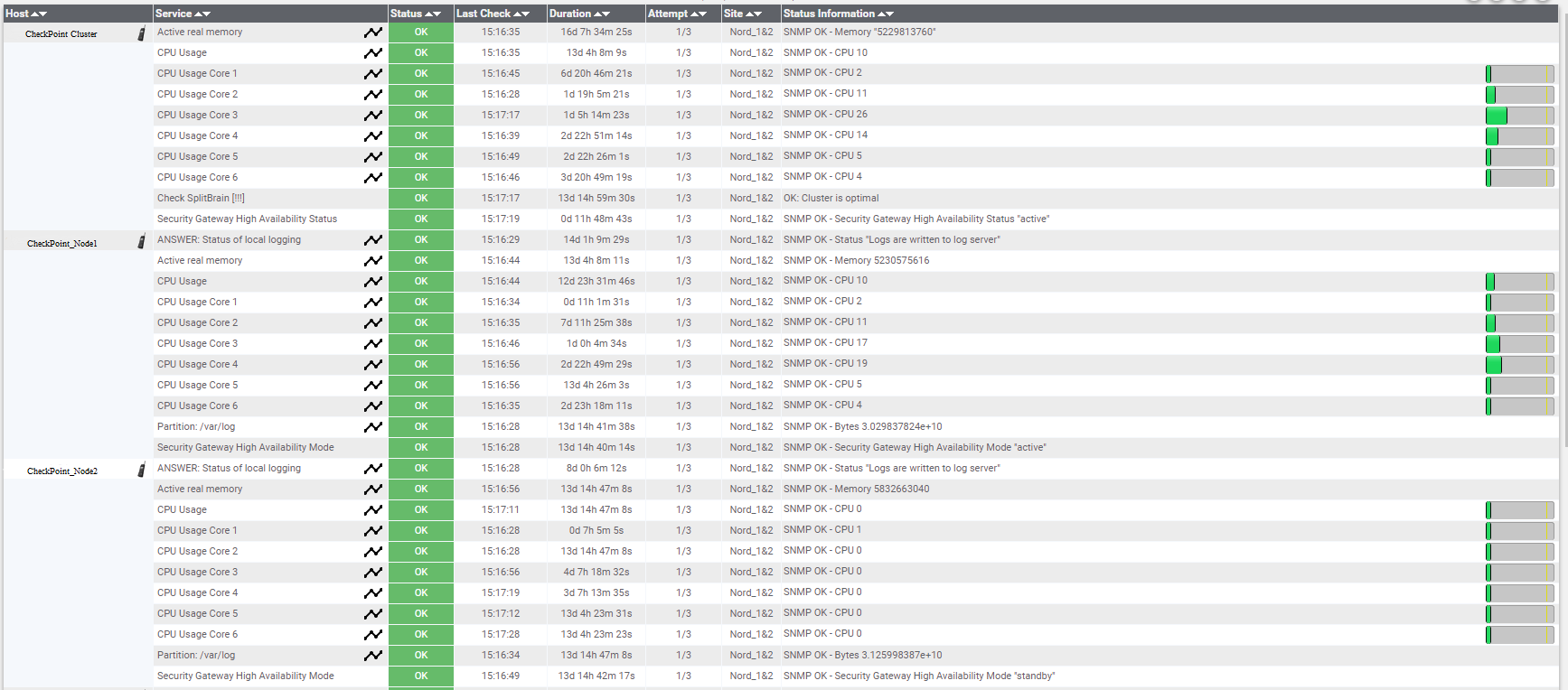 Opciones de monitoreo en Nagios.
Opciones de monitoreo en Nagios.También vale la pena monitorear el estado de los servidores físicos en los que se implementan los hosts ESXi.
Copia de seguridad
El propio vendedor recomienda tomar una instantánea inmediatamente después de instalar la actualización (Hotfixies).
Dependiendo de la frecuencia de los cambios, se configura una copia de seguridad completa una vez a la semana o al mes. En nuestra práctica, hacemos copias incrementales diarias de los archivos de Check Point y una copia de seguridad completa una vez por semana.
Eso es todo. Estos fueron los puntos más básicos a tener en cuenta al implementar puntos de control virtuales. Pero incluso cumplir con este mínimo ayudará a evitar problemas con su trabajo.