Amigos, a finales de marzo estamos lanzando una nueva transmisión en el curso
"Data Scientist" . Y en este momento, estamos comenzando a compartir material útil sobre el curso con usted.
IntroduccionRecordando la experiencia temprana de mi pasión por el aprendizaje automático (ML), puedo decir que se hizo un gran esfuerzo para construir un modelo realmente bueno. Consulté con expertos en este campo para comprender cómo mejorar mi modelo, pensé en las funciones necesarias, traté de asegurarme de que se tuvieran en cuenta todos los consejos que propusieron. Pero aún así me encontré con un problema.
¿Cómo implementar el modelo en un proyecto real? No tenía ideas sobre este puntaje. Toda la literatura que estudié hasta este punto se centró solo en mejorar los modelos. No vi el siguiente paso en su desarrollo.

Es por eso que estoy escribiendo esta guía ahora. Quiero que enfrentes el problema que encontré en mi tiempo, pero pude resolverlo rápidamente. Hacia el final de este artículo, le mostraré cómo implementar un modelo de aprendizaje automático utilizando el marco Flask en Python.
Contenido- Opciones de implementación para modelos de aprendizaje automático.
- ¿Qué es una API?
- Instalación del entorno Python e información básica sobre Flask.
- Crear un modelo de aprendizaje automático.
- Guardar modelos de aprendizaje automático: serialización y deserialización.
- Crear una API usando Flask.
Opciones de implementación para modelos de aprendizaje automático.
En la mayoría de los casos, el uso real de modelos de aprendizaje automático es una parte central del desarrollo, incluso si es solo un pequeño componente de un sistema automatizado de distribución de correo electrónico o chatbot. A veces hay momentos en que las barreras para la implementación parecen insuperables.
Por ejemplo, la mayoría de los especialistas en ML utilizan R o Python para su investigación científica. Sin embargo, los ingenieros de software que usan una pila de tecnología completamente diferente serán consumidores de estos modelos. Hay dos opciones que pueden resolver este problema:
Opción 1: vuelva a escribir todo el código en el idioma con el que trabajan los ingenieros de desarrollo. Suena lógico, pero lleva mucho tiempo y esfuerzo replicar los modelos desarrollados. Al final, resulta solo una pérdida de tiempo. La mayoría de los lenguajes, como JavaScript, no tienen bibliotecas convenientes para trabajar con ML. Por lo tanto, será una solución racional no utilizar esta opción.
Opción 2: usar la API. Las API de red resolvieron el problema de trabajar con aplicaciones en diferentes idiomas. Si el desarrollador front-end necesita usar su modelo de aprendizaje automático para crear una aplicación web sobre la base, solo necesita obtener la URL del servidor de destino que discute la API.
¿Qué es una API?En palabras simples, la API (Application Programming Interface) es un tipo de contrato entre dos programas, que dice que si un programa de usuario proporciona datos de entrada en un formato específico, el programa desarrollador (API) los pasa a través de sí mismo y proporciona al usuario datos de salida.
Podrá leer un par de artículos por su cuenta, que describen bien por qué la API es una opción bastante popular entre los desarrolladores.
La mayoría de los grandes proveedores de servicios en la nube y las empresas más pequeñas y centradas en el aprendizaje automático proporcionan API listas para usar. Satisfacen las necesidades de los desarrolladores que no entienden el aprendizaje automático, pero desean integrar esta tecnología en sus soluciones.
Por ejemplo, uno de estos proveedores de API es Google con su
API de Google Vision .
Todo lo que el desarrollador debe hacer es simplemente llamar a la API REST (Representational State Transfer) utilizando el SDK proporcionado por Google. Vea lo que puede hacer con la
API de Google Vision .
Suena genial, ¿verdad? En este artículo, descubriremos cómo crear su propia API utilizando Flask, un marco de Python.
Nota : Flask no es el único marco de red para este propósito. También hay Django, Falcon, Hug y muchos otros que no se mencionan en este artículo. Por ejemplo, para R hay un paquete llamado
fontaneroInstalación del entorno Python e información básica sobre Flask.1) Crear un entorno virtual usando Anaconda. Si necesita crear su propio entorno virtual para Python y mantener el estado de dependencias necesario, Anaconda ofrece buenas soluciones para esto. A continuación funcionará con la línea de comando.
- Aquí encontrarás el instalador de miniconda para Python;
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda3-latest-Linux-x86_64.sh- Sigue la secuencia de preguntas.
source .bashrc- Si escribe:
conda , puede ver una lista de comandos disponibles y ayuda. - Para crear un nuevo entorno, escriba:
conda create --name <environment-name> python=3.6 - Siga los pasos que se le pedirá que haga y al final ingrese:
source activate <environment-name> - Instale los paquetes Python requeridos. Los más importantes son frasco y gunicorn.
2) Intentaremos crear nuestra sencilla aplicación Flask "Hello world" usando gunicorn .- Abra su editor de texto favorito y cree el archivo
hello-world.py en la carpeta - Escribe el siguiente código:
"""Filename: hello-world.py """ from flask import Flask app = Flask(__name__) @app.route('/users/<string:username>') def hello_world(username=None): return("Hello {}!".format(username))
- Guarde el archivo y regrese a la terminal.
- Para iniciar la API, ejecute en la terminal:
gunicorn --bind 0.0.0.0:8000 hello-world:app - Si obtiene lo siguiente, entonces está en el camino correcto:

- En el navegador, ingrese lo siguiente:
https://localhost:8000/users/any-name

¡Hurra! ¡Escribiste tu primer programa Flask! Como ya tiene cierta experiencia con estos sencillos pasos, podemos crear puntos finales de red a los que se pueda acceder localmente.
Usando Flask podemos envolver nuestros modelos y usarlos como una API web. Si queremos crear aplicaciones de red más complejas (por ejemplo, en JavaScript), debemos agregar algunos cambios.
Crear un modelo de aprendizaje automático.- Para comenzar, echemos un vistazo a la competencia de aprendizaje automático de la Competencia de predicción de préstamos . El objetivo principal es establecer una tubería de preprocesamiento y crear modelos ML para facilitar la tarea de predicción durante la implementación.
import os import json import numpy as np import pandas as pd from sklearn.externals import joblib from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.base import BaseEstimator, TransformerMixin from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline import warnings warnings.filterwarnings("ignore")
- Guarde el conjunto de datos en la carpeta:
!ls /home/pratos/Side-Project/av_articles/flask_api/data/
test.csv training.csv
data = pd.read_csv('../data/training.csv')
list(data.columns)
['Loan_ID', 'Gender', 'Married', 'Dependents', 'Education', 'Self_Employed', 'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term', 'Credit_History', 'Property_Area', 'Loan_Status']
data.shape
(614, 13)
ul>
Encuentre los valores nulo / Nan en las columnas:
for _ in data.columns: print("The number of null values in:{} == {}".format(_, data[_].isnull().sum()))
The number of null values in:Loan_ID == 0 The number of null values in:Gender == 13 The number of null values in:Married == 3 The number of null values in:Dependents == 15 The number of null values in:Education == 0 The number of null values in:Self_Employed == 32 The number of null values in:ApplicantIncome == 0 The number of null values in:CoapplicantIncome == 0 The number of null values in:LoanAmount == 22 The number of null values in:Loan_Amount_Term == 14 The number of null values in:Credit_History == 50 The number of null values in:Property_Area == 0 The number of null values in:Loan_Status == 0
- El siguiente paso es crear conjuntos de datos para capacitación y pruebas:
red_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome','CoapplicantIncome',\ 'LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] X_train, X_test, y_train, y_test = train_test_split(data[pred_var], data['Loan_Status'], \ test_size=0.25, random_state=42)
- Para asegurarnos de que todos los pasos de preprocesamiento se completen correctamente, incluso después de que hayamos experimentado, y no nos hayamos perdido nada durante la predicción, crearemos nuestro propio evaluador de Scikit-learn para preprocesamiento (estimador de pre-procesamiento de Scikit-learn) .
Para entender cómo lo creamos, lea lo
siguiente .
from sklearn.base import BaseEstimator, TransformerMixin class PreProcessing(BaseEstimator, TransformerMixin): """Custom Pre-Processing estimator for our use-case """ def __init__(self): pass def transform(self, df): """Regular transform() that is a help for training, validation & testing datasets (NOTE: The operations performed here are the ones that we did prior to this cell) """ pred_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome',\ 'CoapplicantIncome','LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] df = df[pred_var] df['Dependents'] = df['Dependents'].fillna(0) df['Self_Employed'] = df['Self_Employed'].fillna('No') df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(self.term_mean_) df['Credit_History'] = df['Credit_History'].fillna(1) df['Married'] = df['Married'].fillna('No') df['Gender'] = df['Gender'].fillna('Male') df['LoanAmount'] = df['LoanAmount'].fillna(self.amt_mean_) gender_values = {'Female' : 0, 'Male' : 1} married_values = {'No' : 0, 'Yes' : 1} education_values = {'Graduate' : 0, 'Not Graduate' : 1} employed_values = {'No' : 0, 'Yes' : 1} property_values = {'Rural' : 0, 'Urban' : 1, 'Semiurban' : 2} dependent_values = {'3+': 3, '0': 0, '2': 2, '1': 1} df.replace({'Gender': gender_values, 'Married': married_values, 'Education': education_values, \ 'Self_Employed': employed_values, 'Property_Area': property_values, \ 'Dependents': dependent_values}, inplace=True) return df.as_matrix() def fit(self, df, y=None, **fit_params): """Fitting the Training dataset & calculating the required values from train eg: We will need the mean of X_train['Loan_Amount_Term'] that will be used in transformation of X_test """ self.term_mean_ = df['Loan_Amount_Term'].mean() self.amt_mean_ = df['LoanAmount'].mean() return self
- Convierta
y_train y y_test en np.array :
y_train = y_train.replace({'Y':1, 'N':0}).as_matrix() y_test = y_test.replace({'Y':1, 'N':0}).as_matrix()
Creemos una tubería para asegurarnos de que todos los pasos de preprocesamiento que hacemos son el trabajo del evaluador de scikit-learn.
pipe = make_pipeline(PreProcessing(), RandomForestClassifier())
pipe
Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))])
Para buscar hiperparámetros adecuados (grado para objetos polinomiales y alfa para un borde), haremos una búsqueda de cuadrícula (Búsqueda de cuadrícula):
param_grid = {"randomforestclassifier__n_estimators" : [10, 20, 30], "randomforestclassifier__max_depth" : [None, 6, 8, 10], "randomforestclassifier__max_leaf_nodes": [None, 5, 10, 20], "randomforestclassifier__min_impurity_split": [0.1, 0.2, 0.3]}
- Inicia la búsqueda de cuadrícula:
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3)
- Ajustamos los datos de entrenamiento para el estimador de tubería:
grid.fit(X_train, y_train)
GridSearchCV(cv=3, error_score='raise', estimator=Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impu..._jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))]), fit_params=None, iid=True, n_jobs=1, param_grid={'randomforestclassifier__n_estimators': [10, 20, 30], 'randomforestclassifier__max_leaf_nodes': [None, 5, 10, 20], 'randomforestclassifier__min_impurity_split': [0.1, 0.2, 0.3], 'randomforestclassifier__max_depth': [None, 6, 8, 10]}, pre_dispatch='2*n_jobs', refit=True, return_train_score=True, scoring=None, verbose=0)
- Veamos qué parámetro eligió la búsqueda en la cuadrícula:
print("Best parameters: {}".format(grid.best_params_))
Best parameters: {'randomforestclassifier__n_estimators': 30, 'randomforestclassifier__max_leaf_nodes': 20, 'randomforestclassifier__min_impurity_split': 0.2, 'randomforestclassifier__max_depth': 8}
print("Validation set score: {:.2f}".format(grid.score(X_test, y_test)))
Validation set score: 0.79
- Descargue la suite de prueba:
test_df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") test_df = test_df.head()
grid.predict(test_df)
array([1, 1, 1, 1, 1])
Nuestra cartera se ve lo suficientemente buena como para pasar al siguiente paso importante: serializar el modelo de aprendizaje automático.
Guardar un modelo de aprendizaje automático: serialización y deserialización."En informática, en el contexto del almacenamiento de datos, la serialización es el proceso de traducir estructuras de datos o estados de objetos a un formato almacenado (por ejemplo, un archivo o memoria intermedia) y luego reconstruirlo en el mismo entorno informático u otro".
En Python, el decapado es la forma estándar de almacenar objetos y recuperarlos más tarde en su estado original. Para hacerlo más claro, daré un ejemplo simple:
list_to_pickle = [1, 'here', 123, 'walker']
list_pickle
b'\x80\x03]q\x00(K\x01X\x04\x00\x00\x00hereq\x01K{X\x06\x00\x00\x00walkerq\x02e.'
Luego volvemos a descargar el objeto enlatado:
loaded_pickle = pickle.loads(list_pickle)
loaded_pickle
[1, 'here', 123, 'walker']
Podemos guardar objetos enlatados en un archivo y usarlos. Este método es similar a la creación de archivos
.rda , como en la programación R, por ejemplo.
Nota: puede que a algunos no les guste este método de preservación para la serialización. Una alternativa podría ser
h5py .
Tenemos una clase personalizada (Clase) que debemos importar mientras se realiza el entrenamiento, por lo que utilizaremos el módulo de
dill para empacar el evaluador de clase con el objeto de cuadrícula.
Es aconsejable crear un archivo
training.py separado que contenga todo el código para entrenar el modelo. (Un ejemplo se puede ver
aquí ).
!pip install dill
Requirement already satisfied: dill in /home/pratos/miniconda3/envs/ordermanagement/lib/python3.5/site-packages
import dill as pickle filename = 'model_v1.pk'
with open('../flask_api/models/'+filename, 'wb') as file: pickle.dump(grid, file)
El modelo se guardará en el directorio seleccionado anteriormente. Una vez que el modelo se despedaza, se puede envolver en una envoltura de matraz. Sin embargo, antes de esto, debe asegurarse de que el archivo enlatado funcione. Volvamos a cargarlo y hagamos una predicción:
with open('../flask_api/models/'+filename ,'rb') as f: loaded_model = pickle.load(f)
loaded_model.predict(test_df)
array([1, 1, 1, 1, 1])
Dado que seguimos los pasos de preprocesamiento para que los datos recién llegados sean parte de la tubería, solo necesitamos ejecutar predic (). Con la biblioteca scikit-learn, es bastante sencillo trabajar con tuberías. Los tasadores y las tuberías se encargan de su tiempo y nervios, incluso si la implementación inicial parece salvaje.
Crear una API usando FlaskMantengamos la estructura de carpetas lo más simple posible:
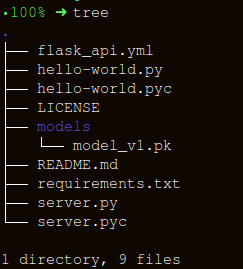
Hay tres partes importantes para crear un contenedor para la función
apicall() :
- Recibir datos de
request (para lo cual se realizará un pronóstico); - Cargando un tasador enlatado;
- Traducción de nuestras previsiones en formato JSON y recepción de un
status code: 200 respuesta status code: 200 ;
Los mensajes HTTP se crean a partir del encabezado y el cuerpo. En general, el contenido del cuerpo principal se transmite en formato JSON. Enviaremos (
POST url-endpoint/ ) datos entrantes como un paquete para recibir pronósticos.
Nota: Puede enviar texto plano, XML, cvs o una imagen directamente para intercambiar el formato, sin embargo, es preferible utilizar JSON en nuestro caso.
"""Filename: server.py """ import os import pandas as pd from sklearn.externals import joblib from flask import Flask, jsonify, request app = Flask(__name__) @app.route('/predict', methods=['POST']) def apicall(): """API Call Pandas dataframe (sent as a payload) from API Call """ try: test_json = request.get_json() test = pd.read_json(test_json, orient='records')
Después de la ejecución, ingrese:
gunicorn --bind 0.0.0.0:8000 server:appGeneremos datos para el pronóstico y una cola para ejecutar la API localmente en
https:0.0.0.0:8000/predict import json import requests
"""Setting the headers to send and accept json responses """ header = {'Content-Type': 'application/json', \ 'Accept': 'application/json'} """Reading test batch """ df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") df = df.head() """Converting Pandas Dataframe to json """ data = df.to_json(orient='records')
data
'[{"Loan_ID":"LP001015","Gender":"Male","Married":"Yes","Dependents":"0","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5720,"CoapplicantIncome":0,"LoanAmount":110.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001022","Gender":"Male","Married":"Yes","Dependents":"1","Education":"Graduate","Self_Employed":"No","ApplicantIncome":3076,"CoapplicantIncome":1500,"LoanAmount":126.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001031","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5000,"CoapplicantIncome":1800,"LoanAmount":208.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001035","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":2340,"CoapplicantIncome":2546,"LoanAmount":100.0,"Loan_Amount_Term":360.0,"Credit_History":null,"Property_Area":"Urban"},{"Loan_ID":"LP001051","Gender":"Male","Married":"No","Dependents":"0","Education":"Not Graduate","Self_Employed":"No","ApplicantIncome":3276,"CoapplicantIncome":0,"LoanAmount":78.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"}]'
"""POST <url>/predict """ resp = requests.post("http://0.0.0.0:8000/predict", \ data = json.dumps(data),\ headers= header)
resp.status_code
200
"""The final response we get is as follows: """ resp.json()
{'predictions': '[{"0":"LP001015","1":1},{...
ConclusiónEn este artículo, hemos recorrido solo la mitad del camino, creando una API funcional que ofrece pronósticos, y nos hemos acercado un paso más a la integración de soluciones de ML directamente en aplicaciones desarrolladas. Hemos creado una API bastante simple que ayudará a crear prototipos del producto y lo hará realmente funcional, pero para enviarlo a producción, debe realizar algunos ajustes que ya no están en el campo del aprendizaje automático.
Hay algunas cosas a tener en cuenta al crear la API:
- Crear una API de calidad a partir de un código de espagueti es casi imposible, por lo tanto, use su conocimiento en aprendizaje automático para crear una API útil y conveniente.
- Intente usar el control de versiones para modelos y código API. Tenga en cuenta que Flask no proporciona soporte para herramientas de control de versiones. Guardar y rastrear modelos ML es una tarea difícil, encuentre una manera conveniente para usted. Aquí hay un artículo que habla sobre cómo hacer esto.
- Debido a las características específicas de los modelos de aprendizaje de scikit, debe asegurarse de que el evaluador y el código de capacitación estén uno al lado del otro (si está utilizando un evaluador personalizado para el preprocesamiento u otras tareas similares). Por lo tanto, el modelo enlatado tendrá un evaluador de clase al lado.
El siguiente paso lógico es crear mecanismos para implementar tal API en una pequeña máquina virtual. Hay varias formas de hacer esto, pero las cubriremos en el próximo artículo.
Código y explicación de este artículo.Fuentes utiles:[1]
No conserve sus datos.[2]
Construcción de transformadores compatibles con Scikit Learn .
[3]
Usando jsonify en Flask .
[4]
Flask-QuickStart.Aquí hay tal material. Suscríbase a nosotros si le gustó la publicación e inscríbase en un
seminario web abierto y gratuito sobre el tema: "Algoritmos de clasificación métrica", que tendrá lugar el 12 de marzo el desarrollador y científico de datos con 5 años de experiencia:
Alexander Nikitin .