
Parte 1/3 aquí
Parte 3/3 aquí
Hola y bienvenido de nuevo! Esta es la segunda parte del artículo sobre la configuración de un clúster de Kubernetes en metal desnudo. Anteriormente, configuramos el clúster de Kubernetes HA mediante un etcd externo, maestro-maestro y equilibrio de carga. Bueno, ahora es el momento de configurar un entorno y utilidades adicionales para hacer que el clúster sea más útil y lo más cercano posible al estado de trabajo.
En esta parte del artículo, nos centraremos en la configuración del equilibrador de carga interno de los servicios de clúster: este será MetalLB. También instalaremos y configuraremos el almacenamiento de archivos distribuidos entre nuestros nodos de trabajo. Usaremos GlusterFS para volúmenes persistentes que están disponibles en Kubernetes.
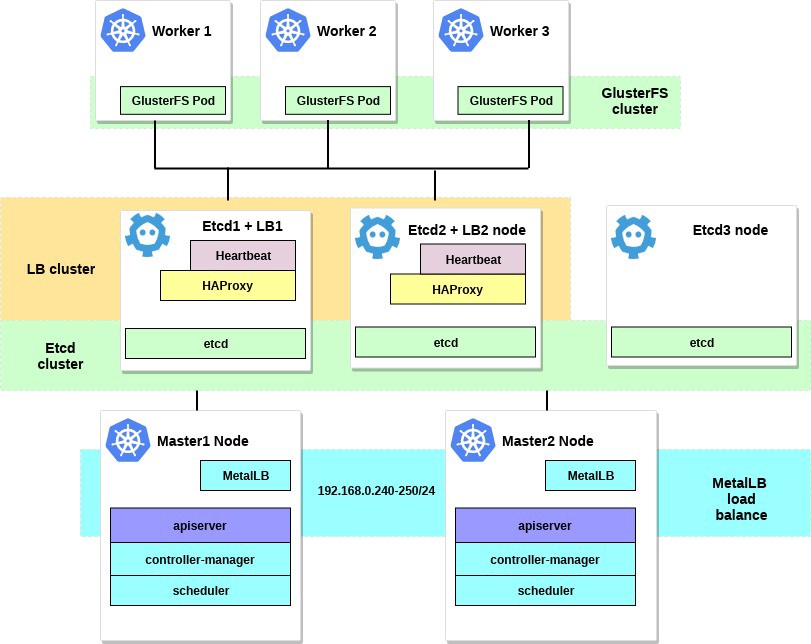
Después de completar todos los pasos, nuestro diagrama de clúster se verá así:
Algunas palabras sobre MetalLB, directamente desde la página del documento:
MetalLB es una implementación de equilibrador de carga para clústeres de metal desnudo de Kubernetes con protocolos de enrutamiento estándar.
Kubernetes no ofrece la implementación de equilibradores de carga de red ( tipo de servicio LoadBalancer ) para metal desnudo. Todas las opciones de implementación de Network LB que Kubernetes incluye son middleware, y accede a varias plataformas IaaS (GCP, AWS, Azure, etc.). Si no trabaja en una plataforma compatible con IaaS (GCP, AWS, Azure, etc.), LoadBalancer permanecerá en el estado "en espera" durante un período indefinido tras la creación.
Los operadores de servidores BM tienen dos herramientas menos efectivas para ingresar el tráfico de usuarios en sus clústeres, NodePort y servicios de IP externos. Ambas opciones tienen importantes deficiencias en la producción, lo que convierte a los grupos de BM en ciudadanos de segunda clase en el ecosistema de Kubernetes.
MetalLB busca corregir este desequilibrio ofreciendo una implementación de Network LB que se integra con el equipo de red estándar, por lo que los servicios externos en los clústeres BM también "funcionan" a la máxima velocidad.
Por lo tanto, utilizando esta herramienta, lanzamos servicios en el clúster de Kubernetes utilizando un equilibrador de carga, por lo que muchas gracias al equipo de MetalLB. El proceso de configuración es realmente simple y directo.
Anteriormente en el ejemplo, seleccionamos la subred 192.168.0.0/24 para las necesidades de nuestro clúster. Ahora tome parte de esta subred para el futuro equilibrador de carga.
Ingresamos al sistema de la máquina con la utilidad kubectl configurada y ejecutamos:
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
Esto desplegará MetalLB en el clúster, en el metallb-system . Asegúrese de que todos los componentes de MetalLB funcionen correctamente:
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
Ahora configure MetalLB usando configmap. En este ejemplo, estamos utilizando la personalización de Capa 2. Para obtener información sobre otras opciones de personalización, consulte la documentación de MetalLB.
Cree el archivo metallb-config.yaml en cualquier directorio dentro del rango de IP seleccionado de la subred de nuestro clúster:
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
Y aplique esta configuración:
control# kubectl apply -f metallb-config.yaml
Verifique y modifique el mapa de configuración más adelante si es necesario:
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
Ahora tenemos nuestro propio equilibrador de carga local configurado. Veamos cómo funciona, utilizando el servicio Nginx como ejemplo.
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
Luego cree una implementación de prueba y un servicio Nginx:
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
Y ahora, verifique el resultado:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
Creé 3 pods Nginx, como indicamos en la implementación anterior. El servicio Nginx dirigirá el tráfico a todos estos pods de acuerdo con el esquema de equilibrio cíclico. Y también puede ver la IP externa recibida de nuestro equilibrador de carga MetalLB.
Ahora intente pasar a la dirección IP 192.168.0.240 y verá la página Nginx index.html. Recuerde eliminar la implementación de prueba y el servicio Nginx.
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
Bueno, eso es todo con MetalLB, sigamos adelante: configuraremos GlusterFS para los volúmenes de Kubernetes.
2. Configuración de GlusterFS con Heketi en nodos de trabajo.
De hecho, el clúster de Kubernetes no se puede usar sin volúmenes dentro de él. Como saben, los hogares son efímeros, es decir. Se pueden crear y eliminar en cualquier momento. Todos los datos dentro de ellos se perderán. Por lo tanto, en un clúster real, se requiere almacenamiento distribuido para garantizar el intercambio de configuraciones y datos entre nodos y aplicaciones dentro de él.
En Kubernetes, los volúmenes están disponibles de varias maneras; elija los que desee. En este ejemplo, demostraré cómo crear almacenamiento GlusterFS para cualquier aplicación interna, es como volúmenes persistentes. Anteriormente, usé la instalación del "sistema" de GlusterFS en todos los nodos de trabajo de Kubernetes para esto, y luego simplemente creé volúmenes como hostPath en los directorios de GlusterFS.
Ahora tenemos una nueva herramienta práctica de Heketi .
Algunas palabras de la documentación de Heketi:
Infraestructura de gestión de volumen RESTful para GlusterFS.
Heketi ofrece una interfaz de administración RESTful que se puede utilizar para administrar el ciclo de vida de los volúmenes GlusterFS. Gracias a Heketi, los servicios en la nube como OpenStack Manila, Kubernetes y OpenShift pueden proporcionar dinámicamente volúmenes GlusterFS con cualquier tipo de confiabilidad compatible. Heketi determina automáticamente la ubicación de los bloques en un clúster, proporcionando la ubicación de los bloques y sus réplicas en diferentes áreas de falla. Heketi también admite cualquier cantidad de clústeres de GlusterFS, lo que permite que los servicios en la nube ofrezcan almacenamiento de archivos en línea, no solo un clúster de GlusterFS.
Suena bien y, además, esta herramienta acercará nuestro clúster de VM a los grandes clústeres de nube de Kubernetes. Al final, podrás crear PersistentVolumeClaims , que se generará automáticamente y mucho más.
Puede tomar discos duros del sistema adicionales para configurar GlusterFS o simplemente crear algunos dispositivos de bloques ficticios. En este ejemplo, usaré el segundo método.
Cree dispositivos de bloques ficticios en los tres nodos de trabajo:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
Obtendrá un archivo de aproximadamente 10 GB de tamaño. Luego use losetup - para agregarlo a estos nodos, como un dispositivo de bucle invertido:
worker1-3# losetup /dev/loop0 /home/gluster/image
Tenga en cuenta: si ya tiene algún tipo de dispositivo de bucle invertido 0, deberá elegir cualquier otro número.
Me tomé el tiempo y descubrí por qué Heketi no quiere trabajar correctamente. Por lo tanto, para evitar cualquier problema en futuras configuraciones, primero asegúrese de haber cargado el módulo del núcleo dm_thin_pool e instalado el paquete glusterfs-client en todos los nodos de trabajo.
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
Bueno, ahora necesita que el archivo / home / gluster / image y el dispositivo / dev / loop0 estén presentes en todos los nodos de trabajo. Recuerde crear un servicio systemd que automáticamente inicie losetup y modprobe cada vez que estos servidores se inicien.
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
Y enciéndelo:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
El trabajo preparatorio se ha completado y estamos listos para implementar GlusterFS y Heketi en nuestro clúster. Para esto, usaré esta guía genial. La mayoría de los comandos se inician desde una computadora de control externa, y se ejecutan comandos muy pequeños desde cualquier nodo maestro dentro del clúster.
Primero, copie el repositorio y cree DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
Ahora marquemos nuestros tres nodos de trabajo para GlusterFS; después de etiquetarlos, se crearán pods GlusterFS:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
Ahora cree una cuenta de servicio Heketi:
control# kubectl create -f heketi-service-account.json
Brindamos a esta cuenta de servicio la capacidad de administrar cápsulas de brillo. Para hacer esto, cree una función de clúster requerida para nuestra cuenta de servicio recién creada:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
Ahora creemos una clave secreta de Kubernetes que bloquea la configuración de nuestra instancia de Heketi:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
Cree la primera fuente en Heketi, que usamos para las primeras operaciones de configuración y luego elimine:
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
Después de crear e iniciar el servicio Bootstrap Heketi, tendremos que cambiar a uno de nuestros nodos maestros, allí ejecutaremos varios comandos, ya que nuestro nodo de control externo no está dentro de nuestro clúster, por lo que no podemos acceder a los pods de trabajo ni a la red interna del clúster.
Primero, descarguemos la utilidad heketi-client y cópiela en la carpeta del sistema bin:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
Ahora busque la dirección IP del pod heketi y expórtela como una variable del sistema:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
Ahora proporcionemos a Heketi información sobre el clúster GlusterFS que debe administrar. Lo proporcionamos a través de un archivo de topología. Una topología es un manifiesto JSON con una lista de todos los nodos, discos y clústeres utilizados por GlusterFS.
NOTA Asegúrese de que hostnames/manage indique el nombre exacto, como en la sección de kubectl get node , y que hostnames/storage es la dirección IP de los nodos de almacenamiento.
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
Luego descargue este archivo:
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
Luego, utilizamos Heketi para proporcionar volúmenes para almacenar la base de datos. El nombre del equipo es un poco extraño, pero todo está en orden. También cree un repositorio heketi:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
Estos son todos los comandos que necesita ejecutar desde el nodo maestro. Volvamos al nodo de control y continuemos desde allí; En primer lugar, asegúrese de que el último comando en ejecución se ejecutó correctamente:
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
Y el trabajo heketi-storage-copy-job está hecho.
Si actualmente no hay un paquete glusterfs-client instalado instalado en sus nodos de trabajo, entonces se produce un error.
Es hora de eliminar el archivo de instalación de Heketi Bootstrap y hacer una pequeña limpieza:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
En la última etapa, necesitamos crear una copia a largo plazo de Heketi:
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
Si actualmente no hay un paquete glusterfs-client instalado instalado en sus nodos de trabajo, entonces se produce un error. Y casi hemos terminado, ahora la base de datos Heketi se almacena en el volumen GlusterFS y no se restablece cada vez que se reinicia el hogar Heketi.
Para comenzar a usar el clúster GlusterFS con asignación dinámica de recursos, necesitamos crear una StorageClass.
Primero, busquemos el punto final de almacenamiento de Gluster, que se pasará a StorageClass como parámetro (heketi-storage-endpoints):
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
Ahora crea algunos archivos:
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
Use estos archivos para crear clase y pvc:
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
También podemos ver el volumen PV:
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
Ahora tenemos un volumen GlusterFS creado dinámicamente asociado con PersistentVolumeClaim , y podemos usar esta declaración en cualquier subtrama.
Cree uno simple en Nginx y pruébelo:
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
Examine en (espere unos minutos, es posible que deba descargar la imagen si aún no existe):
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
Ahora vaya al contenedor y cree el archivo index.html:
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
Necesitará encontrar la dirección IP interna del hogar y enroscarse desde cualquier nodo maestro:
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
Al hacerlo, simplemente probamos nuestro nuevo volumen persistente.
Algunos comandos útiles para verificar el nuevo clúster de GlusterFS son: heketi-cli cluster list heketi-cli volume list . Se pueden ejecutar en su computadora si heketi-cli está instalado . En este ejemplo, este es el nodo master1 .
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
En esta etapa, configuramos con éxito un equilibrador de carga interno con almacenamiento de archivos, y nuestro clúster ahora está más cerca del estado operativo.
En la siguiente parte del artículo, nos enfocaremos en crear un sistema de monitoreo de clúster, y también lanzaremos un proyecto de prueba para usar todos los recursos que configuramos.
¡Manténgase en contacto y todo lo mejor!