En este artículo hablaré sobre las minas colocadas bajo el rendimiento, así como su detección (preferiblemente antes de la explosión) y su eliminación.
Una imagen para llamar la atención. ¿Qué es una mina?
Comencemos con lo que está en los orígenes de cualquier conocimiento, con definición. Los antiguos decían que nombrar correctamente significa entender correctamente. Creo que la definición de una mina bajo rendimiento se expresa mejor al contrastarla con un error obvio, por ejemplo, esto:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
Incluso los desarrolladores novatos saben que las líneas son inmutables, y pegarlas juntas en un bucle no significa agregar datos al final de una línea existente, sino crear una nueva línea con cada pasada. Si se equivoca, no se desanime: la "Idea" le advertirá inmediatamente sobre el peligro, y el "Sonar" seguramente inundará su asamblea.
Pero este código atraerá mucha menos atención, y la Idea ( antes de la versión 2018.2 ) permanecerá en silencio:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
El problema aquí es el mismo: los envoltorios para tipos simples son inmutables, lo que significa agregar 5 unidades al número de objeto significa crear un nuevo envoltorio y escribir el número 6 en él.
La broma aquí es la presencia en Java de dos representaciones de ciertos tipos de datos: simple y objeto, así como su transformación automática por medio del lenguaje mismo. Debido a esto, muchos desarrolladores novatos piensan algo como esto: "Bueno, la ejecución de alguna manera los transforma allí por sí mismo, es solo un número".
De hecho, no todo es tan simple. Tome el punto de referencia e intente agregar los números de la manera especificada:
De repente, salió muy, muy barato (en adelante JDK 11, a menos que se indique explícitamente lo contrario) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
Compare con un tipo simple:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
De aquí derivamos una de las definiciones de minas bajo rendimiento: este es un código que no llama la atención, no es detectado (al menos en el momento en que lo encontraste) por analizadores estáticos, pero puede ralentizarse en algunos usos. En nuestro caso, mientras que la suma no excede 127, los objetos se toman del caché y Long solo 4 veces más lento que long . Sin embargo, para una matriz de tamaño 100, la velocidad es casi 10 veces menor.
Pequeñas cosas grandes
A veces, un pequeño cambio, que casi no cambia el significado de la ejecución, en algunas circunstancias se convierte en un freno fuerte.
Supongamos que tenemos un código:
¿Cómo se ve la lógica del método?
No te apresures a espiar, piensaEste es ConcurrentHashMap::computeIfAbsent !
Tenemos el "ocho" y podemos mejorar fríamente el código: reemplace 6 líneas con una, haciendo que el código sea más corto y fácil de entender. Por cierto, los conocedores de subprocesos ConcurrentHashMap::computeIfAbsent probablemente señalarán una mejora más que ConcurrentHashMap::computeIfAbsent trae consigo, pero un poco más tarde;)
Hagamos un gran pensamiento realidad:
Se reunieron, comenzaron, lloraronPara ver el tamaño completo, haga clic derecho en la imagen y seleccione "Abrir imagen en una pestaña nueva"
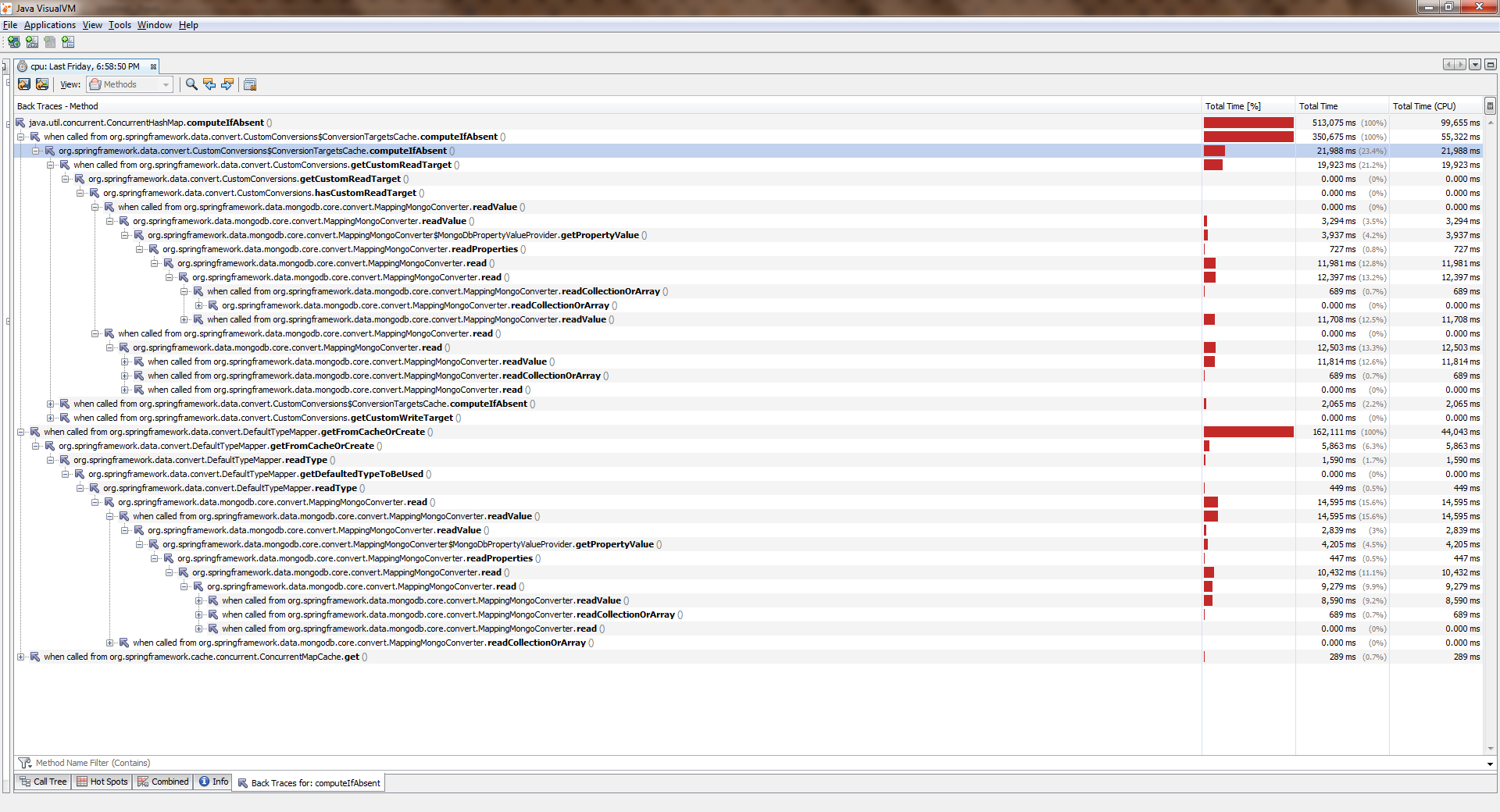
Si bien la aplicación funcionaba con un hilo, todo era más o menos bueno. Las corrientes se hicieron más y empeoraron significativamente. ConcurrentHashMap::computeIfAbsent que ConcurrentHashMap::computeIfAbsent bloqueado, incluso si la clave ya se ha agregado al diccionario . Y esto se convirtió en la razón de un gran error en Spring Date Mongo.
Puede verificar esto con una medida simple ("ocho"). Aquí está su conclusión:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
¿Pueden los desarrolladores considerarlo claramente un error? En mi humilde opinión, no, no. La documentación dice:
Algunos intentos de actualización en este mapa por otros subprocesos pueden bloquearse mientras el cálculo está en progreso, por lo que el cálculo debe ser breve y simple, y no debe intentar actualizar ninguna otra asignación de este mapa
En otras palabras, ConcurrentHashMap::computeIfAbsent cierra la celda que contiene la clave del mundo exterior (a diferencia de ConcurrentHashMap::get ), lo que generalmente es cierto, ya que le permite esquivar la carrera mientras llama a un método desde diferentes hilos cuando la clave aún no se ha agregado.
Por otro lado, en el modo de operación más común, el cálculo del valor y su vinculación con la tecla se produce solo en la primera llamada, y todas las llamadas posteriores solo devuelven el valor calculado previamente. Por lo tanto, tiene sentido cambiar la lógica para que el bloqueo se establezca solo al cambiar. Fue hecho aquí .
En ediciones más recientes (> 8), ConcurrentHashMap::computeIfAbsent vuelto ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
Preste atención a lo insidioso de este ejemplo: el contenido semántico no ha cambiado mucho, porque a primera vista simplemente usamos una sintaxis más avanzada. Al mismo tiempo, mientras la aplicación se ejecuta en un hilo, ¡el usuario casi no siente la diferencia! Así es como los cambios aparentemente inofensivos el cerdo mía bajo nuestro desempeño.
Por qué escribí 'casi sin cambios'ConcurrentHashMap::computeIfAbsent no siempre es intercambiable con la expresión getAndPut , porque ConcurrentHashMap::computeIfAbsent es una operación atómica. En el mismo código
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
Debido a la falta de sincronización externa , aparece una carrera . Si la función pasada a ConcurrentHashMap::computeIfAbsent para la clave dada siempre devuelve el mismo valor, entonces esta es una carrera "segura", lo máximo que enfrentamos es calcular el mismo valor 2 o más veces. Si no existen tales garantías, entonces un reemplazo mecánico está plagado de un desglose de la aplicación. Ten cuidado
Estas manos no cambiaron nada
También sucede que el código no cambia en absoluto, pero de repente comienza a disminuir.
Imagine que nos enfrentamos a la tarea de mover los elementos de una matriz a una colección. Lo más lógico sería usar el Collection::addAll listo para usar, pero aquí está la mala suerte: acepta la colección:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
La forma más fácil es envolver la matriz en Arrays::asList . Resultara algo como
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
Durante la revisión, los colegas conscientes del rendimiento probablemente nos dirán que hay dos problemas en este código a la vez:
- envolver una matriz en una lista (objeto adicional)
- crear un iterador (otro objeto extra) y pasarlo
De hecho, en la implementación de referencia de Collection::addAll veremos esto:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
Entonces se crea un iterador aquí y los elementos se ordenan con él. Por lo tanto, los camaradas experimentados ofrecen su solución:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Dentro del código, con razón parece más productivo:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
Primero, no se crea un iterador. En segundo lugar, el pase se realiza en el ciclo de conteo habitual, además, las matrices se ajustan bien a los cachés, sus elementos se ubican en la memoria secuencialmente (lo que significa que habrá pocos errores de caché) y el acceso a ellos por índice es muy rápido. Bueno, tampoco se crea una lista de contenedor. Suena bien y suena.
Finalmente, los colegas citan ultima ratio regum: documentación. Y allí, gris sobre blanco (o verde sobre negro) dice:
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
Es decir, los propios desarrolladores (¿y a quién deberían creer, si no a ellos?) Escriba que para la mayoría de las implementaciones el método de utilidad funciona mucho más rápido. Y él es realmente más rápido. A veces
El punto de referencia , que HashSet para el HashSet en el G8, ayudará a HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
Parece que los camaradas más experimentados tenían razón. Casi.
En ediciones posteriores (por ejemplo, en 11) la brillantez del método de utilidad se desvanecerá un poco:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
Se puede ver que no estamos hablando de ninguno "mucho más rápido". Y si repetimos el experimento para ArrayList -a, entonces resulta que el método de utilidad comienza a perder mucho (cuanto más fuerte es):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
Aquí no hay nada inesperado, ArrayList construido alrededor de una matriz, por lo que los desarrolladores han redefinido con visión de Collection::addAll :
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
Ahora de vuelta a nuestras minas. Supongamos que, sin embargo, aceptamos la solución propuesta para la corrección de pruebas y dejamos este código:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Por el momento, todo está bien, pero después de agregar una nueva funcionalidad, el método a veces se calienta y comienza a disminuir. Abrimos códigos fuente, el código no cambió. La cantidad de datos es la misma. Y el rendimiento se hundió mucho. Este es otro tipo de mina.
Descubre el depurador y encuentra lo hermoso:

Tenga en cuenta: no cambiamos el algoritmo, la cantidad de datos procesados no cambió, pero su naturaleza cambió y se inició un problema de rendimiento en nuestro código:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
En matrices grandes, la diferencia entre Collections::addAll y Collection::addAll es modesta 500 veces. El hecho es que COWList no solo expande la matriz existente, sino que crea una nueva cada vez que se agregan elementos:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
¿Quién tiene la culpa?
El principal problema aquí es que el Collections::addAll acepta una interfaz, mientras que el método addAll no addAll cuerpo. Sin cuerpo: sin negocio, por lo tanto, la documentación está escrita en base a la implementación existente en AbstractCollection::addAll , que es un algoritmo generalizado aplicable a todas las colecciones. Esto significa que implementaciones más específicas de estructuras de datos que están en un nivel inferior de abstracción pueden alterar este comportamiento.
Ahora humanamente Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
Más sobre abstracciones
Como estamos hablando de los niveles de abstracción, te contaré un ejemplo de la vida.
Comparemos estas dos formas de guardar el enésimo número de entidades en la base de datos:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
A primera vista, el rendimiento de ambos métodos no debería ser muy diferente, porque
- en ambos casos se almacenará el mismo número de entidades en la base de datos
- Si la clave se toma de la secuencia, el número de llamadas será el mismo.
- la cantidad de datos transferidos es la misma
SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
El punto oscuro aquí es el método flush() . ¿Por qué tonto? Me parece que su divulgación en la interfaz JpaRepository fue un error de los desarrolladores. Trataré de justificar mi pensamiento. Por lo general, el desarrollador no utiliza este método en absoluto, porque la llamada a EntityManager::flush vinculada a la finalización de una transacción controlada por Spring:
Tenga en cuenta: EntityManager es parte de la especificación JPA implementada en Hibernate como una sesión (interfaz de sesión y clase SessionImpl, respectivamente). Spring Date es un marco que se ejecuta sobre un ORM, en este caso, sobre Hibernate. Resulta que el JpaRepository::saveAndFlush nos da acceso a los niveles inferiores de la API, aunque la tarea del marco es ocultar los detalles de bajo nivel (la situación es algo similar a la historia insegura en el JDK).
En nuestro caso, cuando usamos JpaRepository::saveAndFlush nos JpaRepository::saveAndFlush en las capas inferiores de la aplicación, rompiendo así algo.
Tómate tu tiempo para mirar, piensa por ti mismoLa capacidad de Hibernate para enviar datos en lotes está rota, un múltiplo de la configuración jdbc.batch_size , que se especifica en application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
El trabajo de Hibernate se basa en eventos, por lo que cuando guarda 1000 entidades como esta
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
llamar a repository.save(e) no guarda instantáneamente. En su lugar, se crea un evento que está en cola. Una vez completada la transacción, los datos se fusionan utilizando EntityManager::flush , que divide las inserciones / actualizaciones en paquetes múltiples de jdbc.batch_size y crea solicitudes a partir de ellas. En nuestro caso, jdbc.batch_size: 500 , por lo que guardar 1000 entidades en realidad significa solo 2 solicitudes.
Pero con una descarga manual de la sesión en cada paso del ciclo
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
la cola se borra y guardar 1000 entidades significa 1000 consultas.
Por lo tanto, interferir con las capas inferiores de la aplicación puede convertirse fácilmente en una mina, y no solo en una mina de productividad (vea Inseguro y su uso incontrolado).
¿Cuánto se ralentiza? Tomemos el mejor caso (para nosotros): la base de datos está en el mismo host que la aplicación. Mi medida muestra la siguiente imagen:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
Obviamente, si la base de datos se encuentra en un host remoto, el costo de la transferencia de datos degradará cada vez más el rendimiento a medida que aumenta el volumen de datos.
Por lo tanto, trabajar en el nivel incorrecto de abstracción puede crear fácilmente una bomba de tiempo. Por cierto, en uno de mis artículos anteriores hablé sobre un curioso intento de mejorar StringBuilder -a: allí no tuve éxito al intentar ingresar a un nivel de código más abstracto.
Fronteras de campo minado
¿Juguemos a un zapador? Encuentra el mío:
¿Lo encontraste? Verifica la respuesta correcta. "¿Estás bromeando?", Exclama el crítico. "¿Pero solo hay un pegado de dos líneas? ¿Qué significa esto en la sangrienta E.?" Permítanme llamar su atención sobre el hecho de que destaqué no solo el pegado de las cadenas, sino también el nombre de la clase y el nombre del método. De hecho, el peligro de pegar cadenas no está en pegarse, sino en lo que sucede en el método que crea las claves para el caché, es decir, en ciertos escenarios tendremos muchos accesos a este método, lo que significa muchas líneas de basura.
Por lo tanto, se debe crear un mensaje de error solo cuando este error se produce realmente:
Por lo tanto, los campos minados tienen límites: esta es la cantidad de datos, la frecuencia de acceso al método, etc. indicadores cuantitativos, al alcanzar y exceder un ligero inconveniente que se vuelve estadísticamente significativo.
Por otro lado, esta es la característica hasta que la intersección de la que complica el código no proporcione una mejora significativa (medible).
Esta es otra conclusión para el desarrollador: en la mayoría de los casos, el engaño es malo, lo que lleva a una complicación sin sentido del código. En 99 casos de cada 100, no ganamos nada.
Debe recordarse que siempre hay
El centésimo caso
Aquí está el código que Nitzan Wakart da en su artículo La volátil sorpresa de lectura :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
Cuando configuremos la experiencia, descubriremos una sorprendente diferencia entre las dos formas de iterar sobre una matriz:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Aquí, un desarrollador inexperto puede llegar a una conclusión tan obvia y comparada: pasar a través de una matriz usando la nueva sintaxis funciona más rápido que un ciclo de conteo. Esta es la conclusión incorrecta, porque vale la pena cambiar un goodOldLoop método goodOldLoop :
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
y su rendimiento es comparable al del método sweetLoop "más rápido":
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .