Traducción de redes neuronales convolucionales desmitificantes . Redes neuronales convolucionales.
Redes neuronales convolucionales.En la última década, hemos visto avances sorprendentes y sin precedentes en la visión por computadora. Hoy en día, las computadoras pueden reconocer objetos en imágenes y cuadros de video con una precisión del 98%, ya por delante de una persona con su 97%. Fueron las funciones del cerebro humano las que inspiraron a los desarrolladores a crear y mejorar las técnicas de reconocimiento.
Una vez que los neurólogos realizaron experimentos con gatos y descubrieron que las mismas partes de la imagen activan las mismas partes del cerebro del gato. Es decir, cuando el gato mira el círculo, la zona alfa se activa en su cerebro, y cuando mira el cuadrado, se activa la zona beta. Los investigadores concluyeron que en el cerebro de los animales hay áreas de neuronas que responden a características específicas de la imagen. En otras palabras, los animales perciben el medio ambiente a través de la arquitectura neuronal multicapa del cerebro. Y cada escena, cada imagen pasa a través de un bloque peculiar de selección de signos, y solo entonces se transmite a las estructuras más profundas del cerebro.
Inspirados por esto, los matemáticos han desarrollado un sistema en el que se emulan grupos de neuronas que operan en diferentes propiedades de imagen e interactúan entre sí para formar una imagen común.
Recuperando propiedades
La idea de un grupo de neuronas activadas que se suministran con datos de entrada específicos se convirtió en una expresión matemática de una matriz multidimensional que desempeña el papel de determinante de un conjunto de propiedades: se denomina filtro o núcleo. Cada uno de estos filtros busca alguna peculiaridad en la imagen. Por ejemplo, puede haber un filtro para definir límites. Las propiedades encontradas se transfieren a otro conjunto de filtros que pueden determinar las propiedades de nivel superior de la imagen, por ejemplo, ojos, nariz, etc.
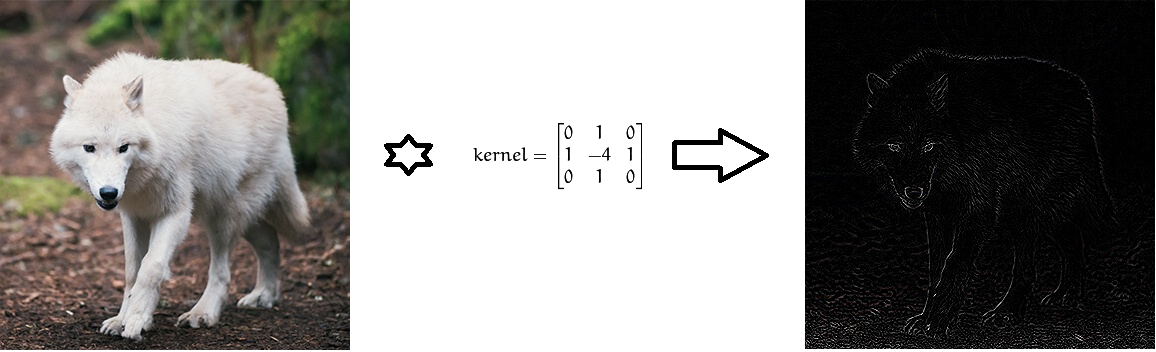 Convolución de la imagen usando filtros de Laplace para determinar los límites.
Convolución de la imagen usando filtros de Laplace para determinar los límites.Desde el punto de vista de las matemáticas, entre la imagen de entrada, presentada en forma de una matriz de intensidad de píxeles, y el filtro, realizamos una operación de convolución, dando como resultado un llamado mapa de propiedades (mapa de características). Este mapa servirá como entrada para la siguiente capa de filtro.
¿Por qué una convolución?
La convolución es un proceso en el que la red intenta marcar la señal de entrada comparándola con información previamente conocida. Si la señal de entrada se parece a imágenes anteriores de gatos, redes ya conocidas, entonces la señal de referencia "gato" se minimizará, mezclará, con la señal de entrada. La señal resultante se transmite a la siguiente capa. En este caso, la señal de entrada significa una representación tridimensional de la imagen en forma de intensidades de píxeles RGB, y el núcleo aprende la señal de referencia "gato" para reconocer a los gatos.
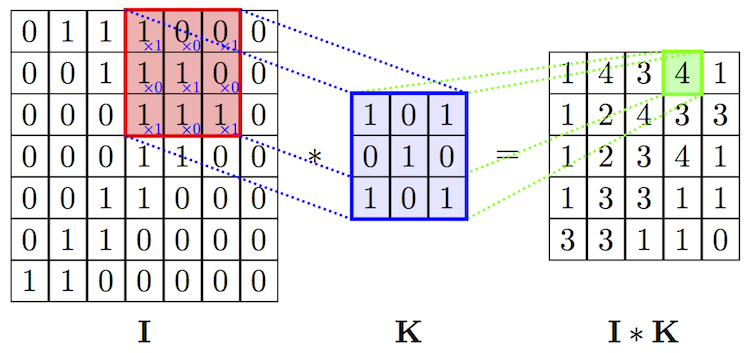 Operación de convolución de imagen y filtro. Fuente
Operación de convolución de imagen y filtro. FuenteLa operación de convolución tiene una excelente propiedad: traducción invariante. Esto significa que cada filtro de convolución refleja un cierto conjunto de propiedades, por ejemplo, ojos, oídos, etc., y el algoritmo de red neuronal convolucional aprende a determinar qué conjunto de propiedades corresponde a la referencia de, por ejemplo, un gato. La intensidad de la señal de salida no depende de la ubicación de las propiedades, sino de su presencia. Por lo tanto, el gato puede representarse en varias poses, pero el algoritmo aún puede reconocerlo.
Agrupación
Siguiendo el principio del cerebro biológico, los científicos pudieron desarrollar un aparato matemático para extraer propiedades. Pero después de evaluar el número total de capas y propiedades que deben analizarse para rastrear formas geométricas complejas, los científicos se dieron cuenta de que las computadoras no tendrían suficiente memoria para almacenar todos los datos. Además, la cantidad de recursos informáticos necesarios crece exponencialmente con el aumento en el número de propiedades. Para resolver este problema, se desarrolló una técnica de agrupación. Su idea es muy simple: si un área determinada contiene propiedades pronunciadas, entonces podemos negarnos a buscar otras propiedades en esta área.
 Ejemplo de agrupación del valor máximo.
Ejemplo de agrupación del valor máximo.La operación de agrupación no solo ahorra memoria y potencia de procesamiento, sino que también ayuda a eliminar imágenes del ruido.
Capa completamente unida
De acuerdo, ¿por qué sería útil una red neuronal si solo puede definir conjuntos de propiedades de imagen? Necesitamos enseñarle de alguna manera a clasificar las imágenes. Y el enfoque tradicional para la formación de redes neuronales nos ayudará en esto. En particular, los mapas de propiedades obtenidos en capas anteriores se pueden recopilar en una capa que esté completamente asociada con todas las etiquetas que preparamos para la categorización. Esta última capa asignará las probabilidades de hacer coincidir cada clase. Y en base a estas probabilidades finales, podemos atribuir la imagen a alguna categoría.
 Capa totalmente unida. Fuente
Capa totalmente unida. FuenteArquitectura final
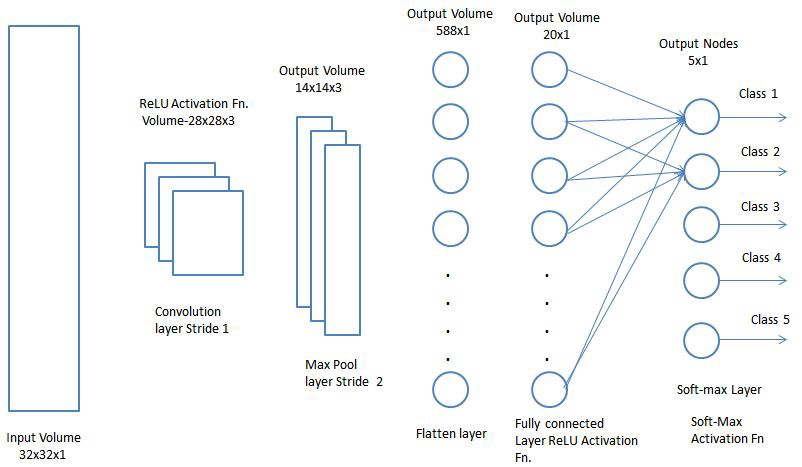
Ahora solo queda combinar todos los conceptos estudiados por la red en un solo marco: la red neuronal convolucional (Convolution Neural Network, CNN). CNN consiste en una serie de capas convolucionales que se pueden combinar con capas de agrupación para generar un mapa de propiedades que se pasa a capas completamente conectadas para determinar las probabilidades de que coincida cualquier clase. Recuperando los errores que obtenemos, podemos entrenar esta red neuronal hasta obtener resultados precisos.
Ahora que entendemos las perspectivas funcionales de CNN, echemos un vistazo más de cerca a los aspectos del uso de CNN.
Redes neuronales convolucionales
 Capa convolucional.
Capa convolucional.La capa convolucional es el principal bloque de construcción de CNN. Cada capa incluye un conjunto de filtros independientes, cada uno de los cuales busca su propio conjunto de propiedades en la imagen entrante.
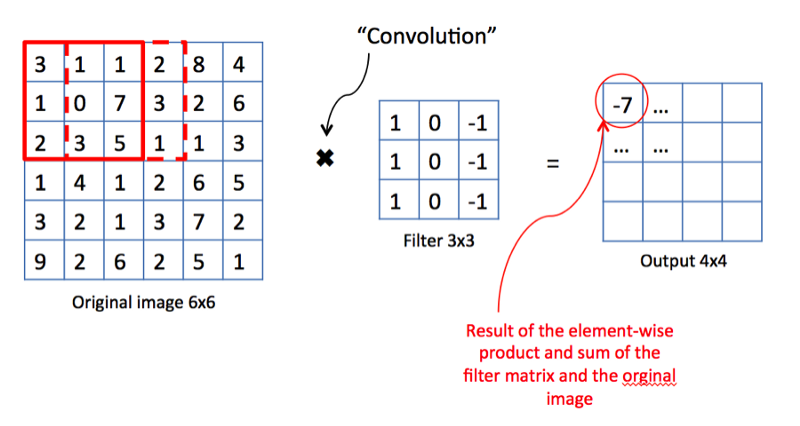 Operación de convolución. Fuente
Operación de convolución. FuenteDesde el punto de vista de las matemáticas, tomamos un filtro de tamaño fijo, lo superponemos en la imagen y calculamos el producto escalar del filtro y una parte de la imagen de entrada. Los resultados del trabajo se colocan en el mapa final de propiedades. Luego, movemos el filtro hacia la derecha y repetimos la operación, agregando también el resultado del cálculo al mapa de propiedades. Después de la convolución de toda la imagen con la ayuda de un filtro, obtenemos un mapa de propiedades, que es un conjunto de signos explícitos y se alimenta como entrada a la siguiente capa.
Zancadas
Stride es la cantidad de desplazamiento del filtro. En la ilustración anterior, cambiamos el filtro por un factor de 1. Pero a veces es necesario aumentar el tamaño del desplazamiento. Por ejemplo, si los píxeles vecinos se correlacionan fuertemente entre sí (especialmente en las capas inferiores), entonces tiene sentido reducir el tamaño de la salida utilizando el paso apropiado. Pero si el paso es demasiado grande, se perderá mucha información, así que tenga cuidado.
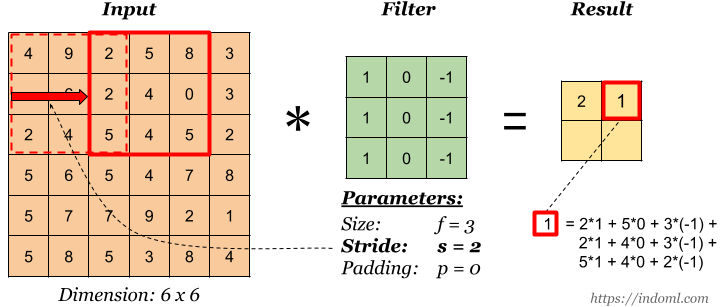 Stride es 2. Fuente .
Stride es 2. Fuente .Acolchado
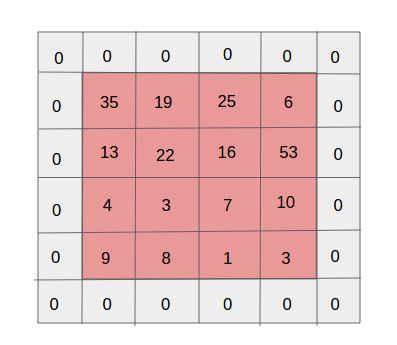 Acolchado de una sola capa. Fuente
Acolchado de una sola capa. FuenteUno de los efectos secundarios del paso es la disminución constante en el mapa de propiedades a medida que se realizan más y más convoluciones nuevas. Esto puede ser indeseable ya que "reducción" significa pérdida de información. Para hacerlo más claro, preste atención a la cantidad de veces que se aplica el filtro a la celda en el medio y en la esquina. Resulta que sin ninguna razón la información en la parte media es más importante que en los bordes. Y para extraer información útil de capas anteriores, puede rodear la matriz con capas de ceros.
Parámetros compartidos
¿Por qué necesitamos redes convolucionales si ya tenemos buenas redes neuronales de aprendizaje profundo? Cabe destacar que si usamos redes de aprendizaje profundo para clasificar imágenes, el número de parámetros en cada capa será mil veces mayor que el de la red neuronal convolucional.
 Compartir parámetros en una red neuronal convolucional.
Compartir parámetros en una red neuronal convolucional.