En la industria, los requisitos de LAN son cada vez más graves a medida que ICS adquiere más y más funcionalidades, y la pérdida de datos puede generar costos serios.
Por ejemplo, en el sector de la energía, si los datos de los transductores de medición no llegan a tiempo al terminal del relé, esto puede verse afectado por la propagación de un cortocircuito a las secciones adyacentes de la red de suministro de energía, lo que resultará en pérdidas mucho más graves que en caso de desconexión oportuna de la sección del cortocircuito. Por lo tanto, a menudo en proyectos de energía puede cumplir con el requisito "Tiempo de recuperación inferior a 1 ms".
La redundancia de red basada en protocolos de toda la industria como RSTP, MRP, DLR y similares, se basa en un cambio en la topología en caso de mal funcionamiento en la transmisión de datos. Cambiar la topología lleva cierto tiempo (de milisegundos a segundos, según el protocolo), que se denomina "tiempo de recuperación". Durante este tiempo, no hay comunicación con parte de la red y, en consecuencia, se pierden datos. Es decir Las tecnologías de redundancia de anillo convencionales no permiten tiempos de recuperación de menos de 1 ms.
En vista de esto, las llamadas tecnologías de redundancia "perfectas" (PRP y HSR) están ganando popularidad. La redundancia basada en PRP y HSR se lleva a cabo, en contraste con los protocolos anteriores, no mediante la reconstrucción de la topología, sino mediante la duplicación de marcos. Cada cuadro es duplicado por el emisor, y ambos cuadros se transmiten de diferentes maneras, y el nodo receptor procesa el cuadro que entró primero y descarta el segundo. Este principio de funcionamiento no requiere la reestructuración de la topología y, en consecuencia, este protocolo funciona casi "sin problemas". Debajo del corte encontrará detalles de la implementación de estos protocolos.
Estructura de red
La redundancia continua se implementa en nodos finales, no en componentes de red. Esta es una de las principales diferencias entre PRP y HSR de otros protocolos de respaldo como RSTP o MRP. Considere las características de la estructura de red para PRP y HSR.
PRP - estructura de red
El nodo final tiene dos interfaces Ethernet que se conectan a dos redes aisladas entre sí, que funcionan en paralelo y tienen una topología independiente (es decir, las topologías de estas dos redes pueden ser iguales o diferentes). Las redes deben estar aisladas para que cualquier mal funcionamiento y detención de la transmisión de datos en una red no afecten a la segunda, es decir. Incluso la energía de la red se suministra desde diferentes fuentes. No debe haber conexiones directas entre estas redes.
 Estructura de red PRP
Estructura de red PRPEstas dos redes generalmente se denominan LAN A y LAN B. Como ya se indicó, pueden tener diferentes topologías y un rendimiento diferente. Los retrasos en la transmisión de datos también pueden variar.
La red puede contener los siguientes elementos:
- DAN (nodo adjunto dual): un nodo que se conecta a ambas redes y envía / recibe tramas duplicadas.
- SAN (nodo adjunto único): un nodo que se conecta a una sola red (LAN A o LAN B) y envía / recibe tramas normales.
- En el caso de que sea necesario conectar de forma redundante un dispositivo que tenga una interfaz Ethernet y no admita el protocolo PRP a la red RPR, se utiliza la denominada Redundancy Box (generalmente RedBox). En RedBox, el paquete del dispositivo se duplica y se transmite a la red PRP, como si los datos se transmitieran desde el DAN. Además, el dispositivo detrás de RedBox es visto como un DAN para otros dispositivos. Tal nodo se llama DAN virtual o VDAN (DAN virtual).
 Principio de funcionamiento de RedBox
Principio de funcionamiento de RedBoxHSR - estructura de red
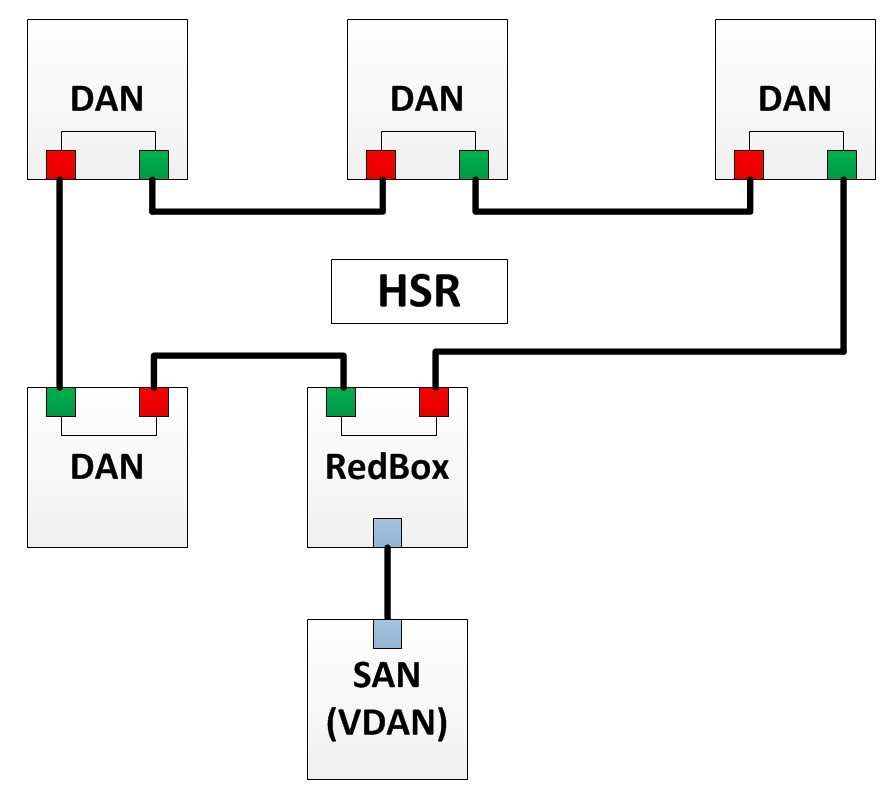 Estructura de red HSR
Estructura de red HSREl principio de funcionamiento de HSR es que todos los dispositivos se combinan en un anillo y todos los mensajes, así como en PRP, se duplican. El dispositivo envía ambos fotogramas a través del anillo: una copia en el sentido de las agujas del reloj y la otra en el sentido contrario. El receptor recibe ambas copias, pero procesa solo la primera y elimina la segunda. Si algo le sucede a uno de los enlaces, y uno de los cuadros duplicados no aparece, entonces el otro simplemente se acepta. Todos los dispositivos HSR tienen dos interfaces Ethernet: puerto A y puerto B.
Según el protocolo HSR, los siguientes elementos pueden existir en una red:
- SAN es un nodo que solo tiene una interfaz Ethernet. Tal nodo se puede conectar a la red HSR exclusivamente a través de RedBox.
- DAN: un nodo que puede intercambiar datos dentro de un anillo HSR (puede enviar / recibir tramas duplicadas).
- RedBox: al igual que en PRP, RedBox le permite conectar un dispositivo que tiene una interfaz Ethernet a una red HSR. El dispositivo detrás de RedBox se ve como un DAN para otros dispositivos. Tal nodo se llama DAN virtual o VDAN (DAN virtual).
- QuadBox - HSR también presenta un nuevo elemento: QuadBox. Este dispositivo tiene cuatro puertos HSR. Le permite combinar dos anillos HSR. En cada anillo, el QuadBox actúa como un DAN y puede transferir datos de un anillo a otro.
 Ejemplo de QuadBox
Ejemplo de QuadBoxEstructura DAN
Para PRP y para HSR, la estructura DAN es similar. Cada DAN tiene dos interfaces que operan en paralelo y conectadas al nivel superior de una pila de comunicación a través de la llamada capa LRE - entidad de redundancia de enlace. En este nivel, se realizan todas las funciones de respaldo.
Ambas interfaces DAN tienen la misma dirección MAC y una dirección IP. Esto le permite hacer la reserva transparente para el nivel superior. Especialmente importante es el hecho de que esto permite el uso de ARP para DAN, así como para cualquier nodo no redundante.
Sin embargo, por supuesto, hay matices en la estructura DAN para PRP y para HSR.
PRP - Estructura DAN
Cuando se envía un marco desde el nivel superior, el LRE lo duplica y envía ambos paquetes a través de los puertos casi simultáneamente. Ambas tramas se transmiten en paralelo a través de dos redes con diferentes retrasos. En una situación ideal, se entregan al nodo de destino con una diferencia de tiempo mínima. Al recibir el LRE, el receptor envía la primera trama recibida a la capa superior y descarta la segunda.
LRE crea marcos duplicados al enviarlos y los procesa al recibirlos. Este nivel, en relación con el nivel superior, representa la interfaz habitual de un adaptador de red no redundante. LRE realiza dos tareas: manejar marcos duplicados y administrar redundancia. Para implementar el control, LRE agrega un tráiler de control de redundancia (RCT) de 32 bits a cada cuadro y lo elimina cuando se recibe el cuadro.
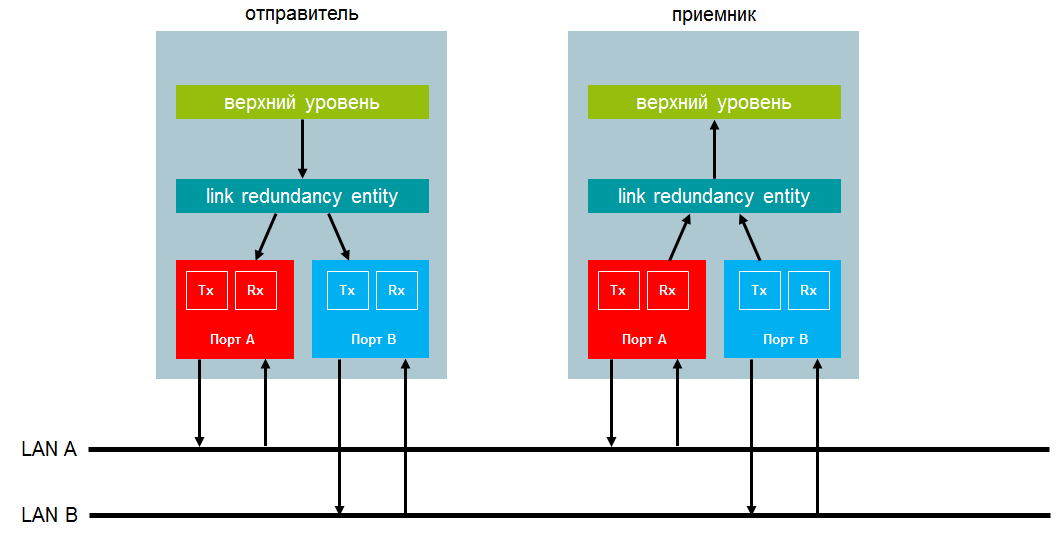 Transferencia de datos entre dos DAN en PRP
Transferencia de datos entre dos DAN en PRPHSR - Estructura DAN
Una trama enviada desde la capa superior es duplicada por la capa LRE, y los paquetes se envían a través del puerto A y el puerto B casi simultáneamente. (1 y 2 en el diagrama).
Al recibir la trama, el receptor la transfiere al nivel LRE, y también la redirige a otro puerto y la pasa más allá en el anillo. (3, 4).
Si una trama llega al remitente, esta trama no se transmite más, sino que se destruye (5, 6).
Ambas tramas llegan al nivel LRE, pero la que se envió más rápido se transfiere al nivel superior, y la trama duplicada se descarta.
LRE agrega una etiqueta HSR de 48 bits a cada trama (similar a agregar una etiqueta VLAN) y elimina esta etiqueta al recibirla.
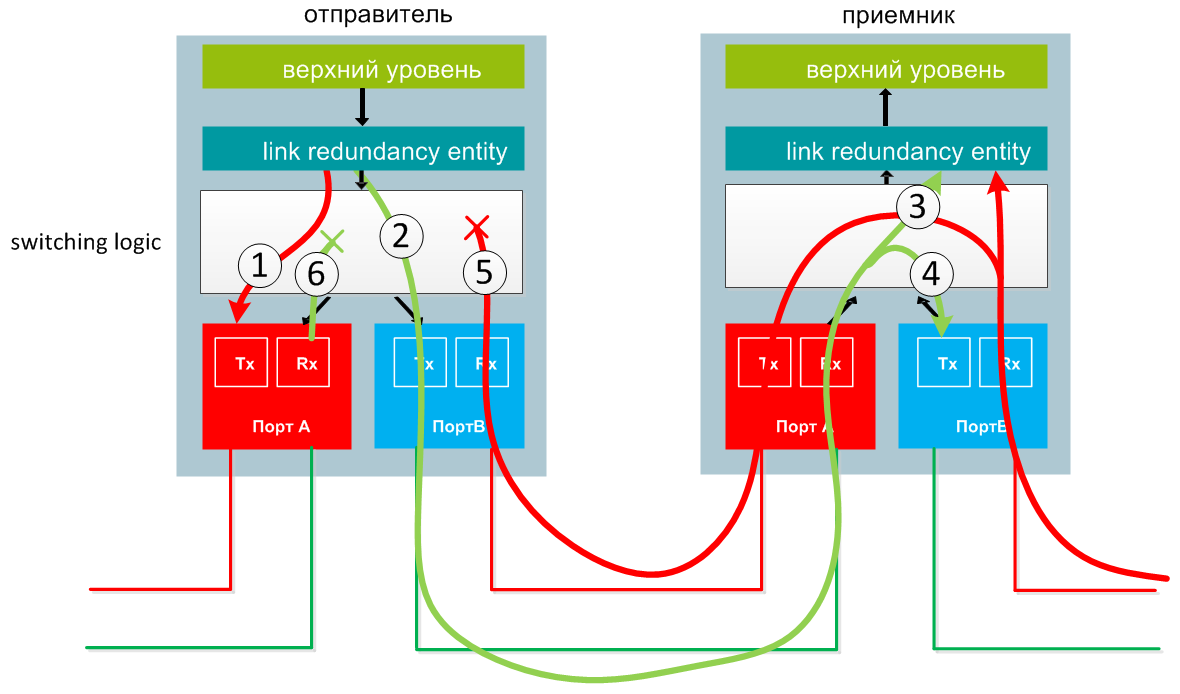 Transferencia de datos entre dos DAN en un HSR
Transferencia de datos entre dos DAN en un HSRInteroperabilidad entre SAN y DAN
En PRP, una SAN se puede conectar a cualquier red, LAN A o LAN B, pero dicho nodo no admite funciones de respaldo. Por lo tanto, una SAN conectada a una red no puede comunicarse con otro nodo similar conectado a una segunda red. Para interactuar con SAN, DAN genera marcos especiales. Esta necesidad se debe al hecho de que la SAN en la trama normal del dispositivo redundante debe ignorar el RCT, lo que no es posible, ya que la SAN no puede distinguir el RCT del bloque de datos IEEE 802.3 normal. A su vez, el DAN entiende que envía la trama a la SAN y no agrega RCT a la trama. Simplemente reenvía un fotograma desde el nivel superior a la interfaz a la que está conectada la SAN. En otras palabras, si el DAN no puede determinar qué está intercambiando datos con otro DAN, entonces no agrega RCT a la trama.
En HSR, una SAN no se puede conectar directamente a la red. Se puede conectar exclusivamente a través de RedBox.
Modos DAN
Al trabajar con tramas duplicadas recibidas en ambas interfaces (si son reparables), el DAN debe aceptar una de las tramas y descartar la segunda. Hay dos métodos de procesamiento en PRP:
- La aceptación duplicada es un método en el que ambas tramas entrantes se reciben y se redirigen al nivel superior.
- Descarte duplicado: un método en el que el nodo receptor lee información del RCT de la trama entrante para determinar qué trama descartar.
Para HSR, considere los modos U y X más populares.
Duplicar aceptar
Un DAN que funciona en este modo no deja caer ninguna de las tramas cuando se procesa en la capa de enlace de datos.
Los marcos se envían a LAN A y LAN B sin RCT. El LRE del receptor simplemente redirige ambas tramas al nivel superior, suponiendo que una mayor transmisión destruirá los duplicados (IEEE 802.1D establece claramente que los protocolos de nivel superior deben ser capaces de manejar tramas duplicadas).
Por ejemplo, TCP y UDP tienen un alto nivel de resistencia para duplicar tramas.
Este método es muy sencillo de implementar, pero tiene un serio inconveniente: no proporciona ninguna capacidad de control de red, ya que La recepción de ambas tramas no se controla de ninguna manera.
Descarte duplicado a nivel de canal
Cuando se utiliza el segundo método, se agrega un campo que consta de cuatro octetos a la trama: RCT (control de redundancia). Se agrega un avance en el nivel LRE cuando el marco se recibe desde el nivel superior. El ECA consta de los siguientes parámetros:
- Número de secuencia de 16 bits;
- Identificador de red de 4 bits, 1010 (0xA) para LAN A y 1011 (0xB) para LAN B;
- Tamaño de cuadro de 12 bits.
Debido a la adición de un tráiler RCT al marco, su tamaño es mayor que el tamaño máximo de marco definido en el estándar IEEE 802.3-2005. Para transmitir datos dentro de la red con PRP, el equipo debe estar configurado para transmitir datos en el tamaño de 1496 octetos. Debido a esto, no todos los conmutadores son adecuados para su uso en LAN A o LAN B.
 Marco con RCT agregado
Marco con RCT agregadoCada vez que la capa de enlace envía una trama a una dirección específica, el emisor aumenta el número de secuencia para el nodo correspondiente y envía tramas idénticas a través de ambas interfaces.
El nodo receptor debe determinar duplicados en función de la información del ECA.
Algoritmo de método de descarte duplicado
El receptor supone que las tramas enviadas desde cualquier fuente utilizando el protocolo PRP se envían secuencialmente con un número cada vez mayor. El número de secuencia esperado para el siguiente cuadro se almacena en las variables ExpectedSeqA y, en consecuencia, ExpectedSeqB.
Al recibirlo, la corrección de la secuencia se puede verificar comparando el valor de ExpectedSeqA (ExpectedSeqB) con el número de secuencia de la trama recibida, almacenada en la variable currentSeq en RCT. Si el resultado es positivo, la variable ExpectedSeq se establece en uno más que currentSeq para que sea posible realizar una verificación correcta en esta línea.
 Intervalo de caída de trama (ventana de caída)
Intervalo de caída de trama (ventana de caída)Para ambas interfaces, hay un intervalo dinámico de caída de trama para los números de secuencia emparejados. El límite superior de este intervalo es ExpectedSeq (el siguiente número de secuencia esperado en esta interfaz), excluyendo el valor dado en sí, y el límite inferior de este intervalo es startSeq (el número de secuencia más pequeño en el que se descarta la trama duplicada con este número de secuencia).
Después de verificar el número de secuencia, el receptor decide descartar la trama o no. Suponga que LAN A tiene un tamaño de intervalo de caída de trama distinto de cero (Fig. 5). Se descartará una trama de LAN B cuyo número se encuentre en este intervalo. Todas las demás tramas de LAN B serán aceptadas y enviadas al nivel superior.
Dejar caer una trama de LAN B reduce el tamaño de LAN A, porque después de recibir este marco, no se esperan marcos con un número menor en esta interfaz. En consecuencia, startSeqA se establece en uno más que currentSeqB. En este caso, el tamaño del intervalo de caída de la trama LAN B se restablece a 0 (startSeqB =pectedSeqB), porque Obviamente, las tramas LAN B están "detrás" de LAN LAN y no se deben descartar tramas de LAN A.
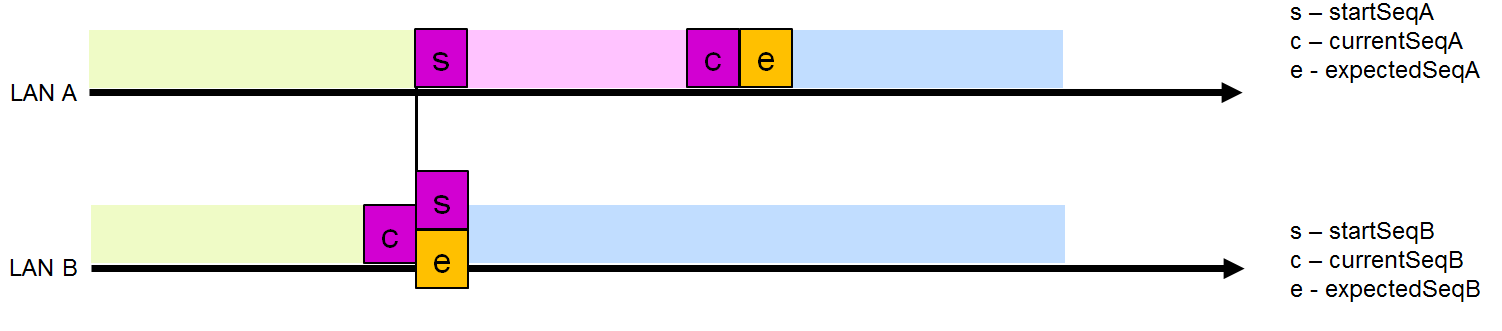 Disminuya el intervalo LAN A después de soltar el marco de LAN B
Disminuya el intervalo LAN A después de soltar el marco de LAN BEn la situación de la Fig. 7, cuando varias tramas de LAN A vienen en una fila, pero nada proviene de LAN B, se aceptan, porque su currentSeq está fuera del intervalo de descarte de la trama LAN B y el intervalo LAN A se incrementa en una posición. Si las tramas de la LAN A continúan llegando, pero aún no sale nada de la LAN B, cuando se alcanza el tamaño de intervalo máximo, startSeqA también comienza a aumentar en uno.
Cuando la trama recibida está fuera del intervalo de descarte de la trama de otra LAN, se guarda esta trama y el tamaño del intervalo de esta interfaz se establece en 1, lo que significa que solo se descartará una trama de otra LAN con el mismo número de secuencia, mientras que la ventana desplegable de la otra interfaz se establece en 0, lo que significa que no se eliminarán cuadros (Fig. 7).
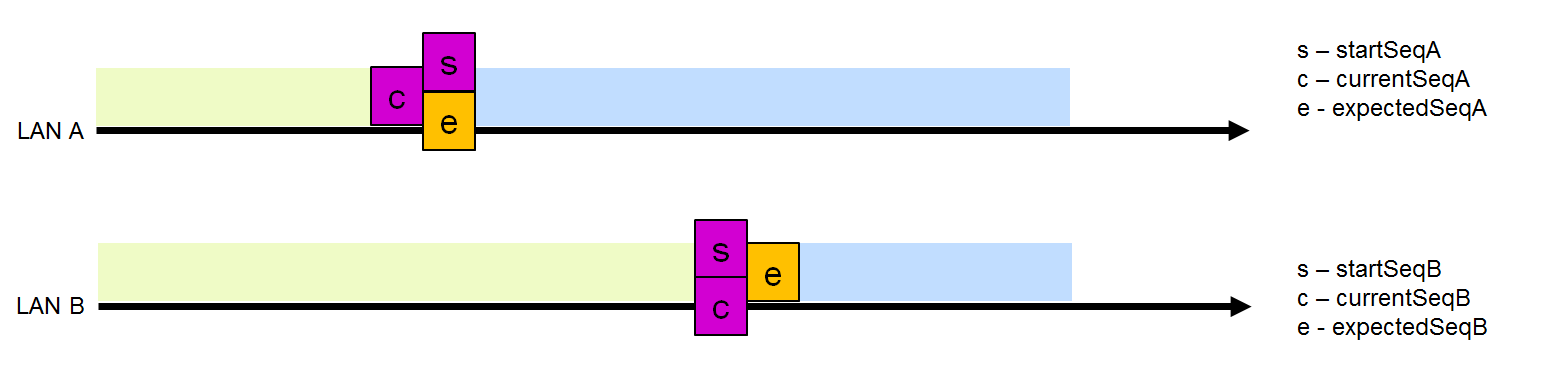
La trama de LAN B no se cayó
La situación más común es cuando ambas interfaces están sincronizadas y el tamaño de ambos intervalos es 0 (Fig. 8), lo que significa que el marco de la interfaz que viene primero será aceptado y el intervalo de esta interfaz se incrementará a 1, lo que permitirá que el marco se caiga de otra interfaz con mismo número de secuencia
 LAN sincronizada
LAN sincronizadaDebido a la presencia de un identificador LAN en RCT, las tramas duplicadas difieren en un bit (y tienen diferentes sumas de verificación). El receptor comprueba que la trama pertenece a la interfaz (es decir, comprueba que la trama con el identificador LAN A ha llegado a la interfaz A). El receptor no soltará este marco, ya que puede contener información útil en el bloque de datos, pero en este caso el contador cntWrongLanA o cntWrongLanB se incrementará en uno. Dado que tales errores no son únicos (mezclados por LAN A y LAN B), el contador aumentará constantemente.
Enlace de tráfico HSR
Al transferir datos dentro de la red HSR, se agrega una etiqueta HSR a cada trama.
La etiqueta HSR consta de los siguientes parámetros:
- Ethertype HSR de 16 bits
- Indicador de ruta de 4 bits
- Tamaño de cuadro de 12 bits
- Número de secuencia de 16 bits
El remitente inserta los mismos números de secuencia en las tramas duplicadas que se envían, y luego incrementa el número de secuencia para cada mensaje enviado desde este nodo.
El receptor monitorea los números de secuencia de todas las tramas de cada fuente de la que recibe datos (distingue las fuentes por la dirección MAC). Si los cuadros provienen de diferentes líneas y tienen la misma fuente y número de secuencia, entonces se acepta uno de ellos y se descarta el segundo.
Para controlar la red, cada dispositivo mantiene una tabla de todos los nodos en la red desde la cual recibe datos. Esto le permite detectar la desaparición de nodos y errores en el bus.
El nodo define la trama que envió por fuente y por número de secuencia.
 Marco con etiqueta HSR agregada
Marco con etiqueta HSR agregadaUn nodo HSR nunca descarta una trama que no ha recibido previamente. El nodo define casi todos los cuadros duplicados, pero si hay algunos de ellos, no los elimina, es decir, el marco solo atraviesa todo el anillo y se destruye en el remitente.
En el estándar, el algoritmo para determinar cuadros duplicados no está definido. Como métodos posibles, se pueden usar tablas hash, colas y seguimiento de números de secuencia.
Modo U
En este modo, el nodo que recibe la trama destruye el duplicado y no permite que se propague más. Sin embargo, si la trama se transfirió aún más, se destruye en los siguientes nodos. Este modo le permite descargar el anillo del tráfico de unidifusión.
En el diagrama, las flechas rojas indican paquetes con la etiqueta HSR enviada desde el puerto "A" (en adelante, marco "A").
Las flechas verdes indican paquetes con una etiqueta HSR enviada desde el puerto "B" (en adelante - trama "B").
Las flechas vacías indican tráfico caído, es decir tramas que se transmitirían durante el funcionamiento normal, pero en este modo se descartaron.
La cruz indica la eliminación del tráfico del anillo (en cualquier caso).
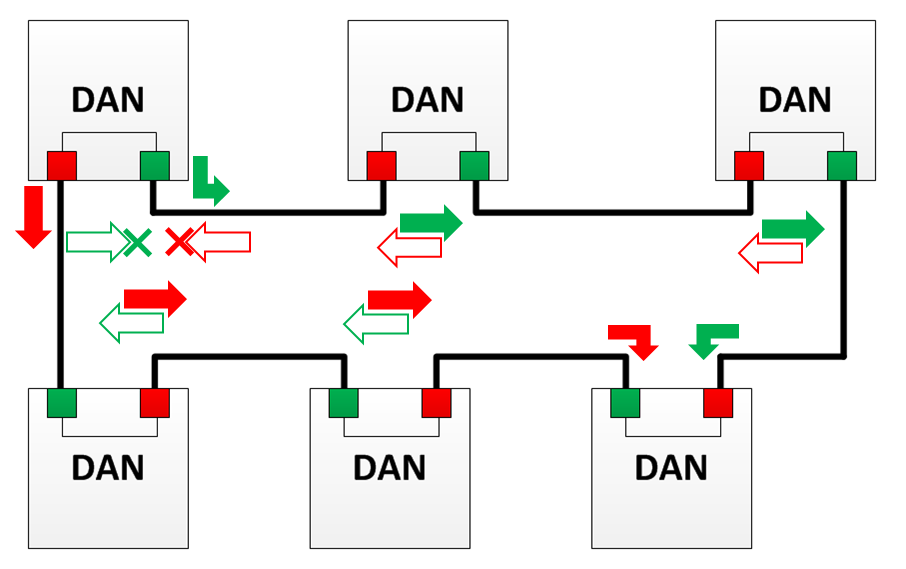
Modo X
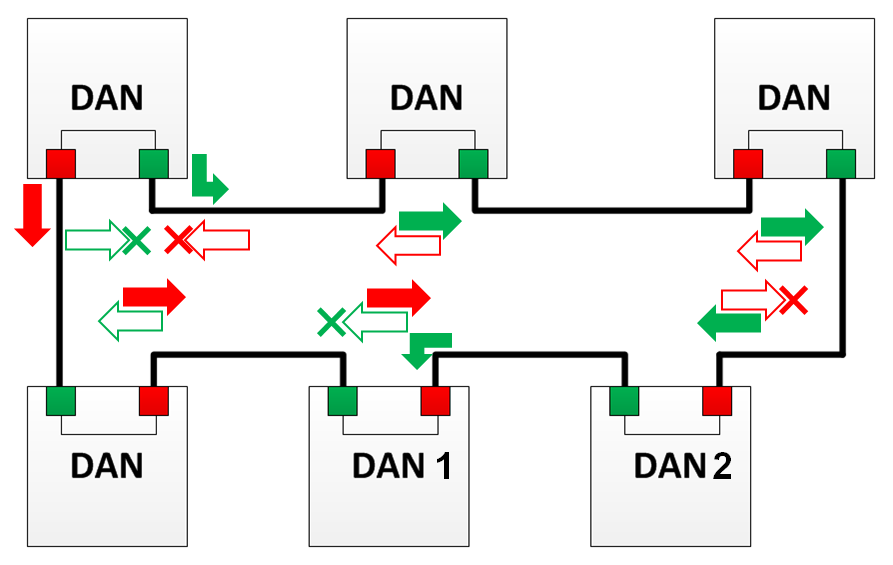
En este modo, el nodo no reenvía la trama más allá y la descarta si dicha trama se recibió desde otra dirección.
Por ejemplo, DAN 1 en la imagen no reenviará el cuadro "B" más adelante, porque ya recibió la trama "A", y DAN 2 no transmitirá la trama "A" más adelante, porque marco ya recibido "B".
En el caso de que ocurriera un error en algún lugar del algoritmo y las tramas se transmitieran más, se descartarán en los siguientes nodos o en el nodo en el que se crearon.
El modo X no es aplicable para mensajes PTP y para transmisión de trama de supervisión.
Control de red
PRP
El receptor verifica que todas las tramas lleguen secuencialmente y se reciban correctamente en ambos canales. Admite contadores de errores que se pueden leer, por ejemplo, a través de SNMP.
Todos los dispositivos admiten tablas de nodos con los que intercambian datos. Estas tablas contienen información sobre el momento en que se envió o recibió la última trama de un nodo en particular y otra información sobre el protocolo PRP.
Al mismo tiempo, estas tablas permiten detectar compuestos en los que es necesario sincronizar números de secuencia, así como detectar secuencias rotas y nodos faltantes.
El diagnóstico se basa en el hecho de que cada DAN envía periódicamente un marco de diagnóstico (marco de supervisión), que le permite verificar la integridad de la red y la presencia de nodos. Al mismo tiempo, estos marcos le permiten verificar qué dispositivos actúan como DAN, determinar sus direcciones MAC y en qué modo funcionan: duplicar aceptar o duplicar descartar.
Hsr
Cada nodo comprueba constantemente todos los enlaces.
Cada nodo envía periódicamente una trama de diagnóstico (a ambos puertos) que contiene información sobre el estado del nodo. Este marco es aceptado por todos los nodos, incluido el remitente. Cuando el remitente recibe su propio mensaje de diagnóstico, se realiza una verificación de integridad del canal físico.
El intervalo para enviar una trama de diagnóstico es relativamente grande (unos segundos), porque no es necesario proporcionar redundancia, pero solo es necesario para fines de diagnóstico.
Todos los nodos se ingresan en la tabla de todos los socios que se encontraron, y el tiempo se registra cuando el nodo estuvo activo por última vez, así como todos los marcos omitidos y los marcos que no se enviaron secuencialmente.
Todos los cambios de topología que se han producido también se registran y toda la información se puede obtener a través de SNMP.
HSR y PRP: Pros y contras
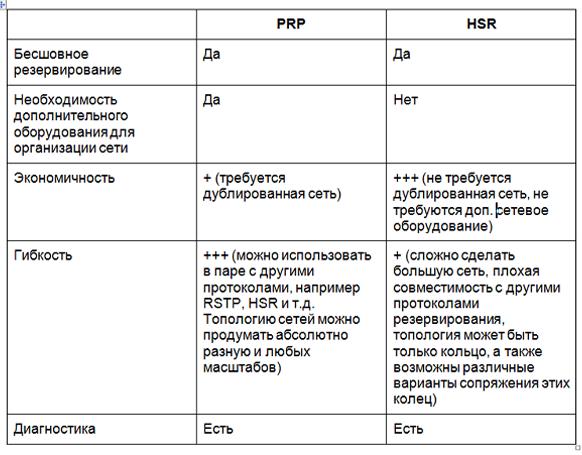
Conclusión
Esto no quiere decir que un protocolo sea mejor que otro: están diseñados un poco para diferentes aplicaciones. Tanto HSR como PRP permiten una redundancia de red sin interrupciones, pero HSR le permite crear soluciones más rentables. Pero tal rentabilidad conlleva dificultades, porque Una red basada en HSR es difícil de escalar y las aplicaciones no son muy flexibles. La baja flexibilidad es causada por una topología limitada (anillo, emparejamiento de anillos), así como la poca compatibilidad del protocolo con otras tecnologías. Por lo tanto, HSR es más adecuado para la redundancia de sistemas pequeños y la integración en una red grande. La copia de seguridad basada en HSR de toda la red es problemática. PRP, a su vez, es una solución más costosa, pero le permite organizar una red a gran escala, que en el futuro se puede ampliar sin problemas, porque
Este protocolo permite integrar convenientemente casi cualquier tecnología e implementar topologías completamente diferentes.Encuentra una solución