Esta semana, la NSA (
Agencia de Seguridad Nacional ) de repente hizo un regalo a la humanidad, abriendo las fuentes de su marco de ingeniería inversa de software. La comunidad de ingenieros de ingeniería inversa y expertos en seguridad con gran entusiasmo comenzó a explorar el nuevo juguete. Según los comentarios, es una herramienta realmente sorprendente, capaz de competir con las soluciones existentes, como IDA Pro, R2 y JEB. La herramienta se llama Ghidra y los recursos profesionales están llenos de impresiones de los investigadores. En realidad, tenían una buena razón: no todos los días las organizaciones gubernamentales brindan acceso a sus herramientas internas. Yo como ingeniero inverso profesional y analista de malware no podía pasar por alto también. Decidí pasar un fin de semana o dos y obtener una primera impresión de la herramienta. Jugué un poco con el desmontaje y decidí verificar la extensibilidad de la herramienta. En esta serie de artículos, explicaré el desarrollo del complemento Ghidra, que carga el formato personalizado, utilizado para resolver la tarea CTF. Como es un marco grande y he elegido una tarea bastante complicada, dividiré el artículo en varias partes.
Al final de esta parte, espero configurar el entorno de desarrollo y crear un módulo mínimo, que pueda reconocer el formato del archivo WebAssembly y sugerir el desensamblador adecuado para procesarlo.
Comencemos con la descripción de la tarea. El año pasado, la compañía de seguridad FireEye organizó el concurso CTF, llamado flare-on. Durante el concurso, los investigadores tuvieron que resolver doce tareas relacionadas con la ingeniería inversa. Una de las tareas era investigar la aplicación web, construida con WebAssembly. Es un formato ejecutable relativamente nuevo, y que yo sepa, no hay herramientas perfectas para manejarlo. Durante el desafío, probé varias herramientas diferentes tratando de derrotarlo. Esos eran simples guiones de github y descompiladores conocidos, como IDA pro y JEB. Sorprendentemente, me detuve en Chrome, que proporciona un muy buen desensamblador y depurador para WebAssembly. Mi objetivo es resolver el desafío con la ghidra. Voy a describir el estudio lo más completo posible y daré toda la información posible para reproducir mis pasos. Tal vez, como persona que no tiene mucha experiencia con el instrumento, podría entrar en algunos detalles innecesarios, pero así es como es.
La tarea que voy a utilizar para estudiar se puede descargar del
sitio de desafío flareon5. Hay un archivo 05_web2point0.7z: archivo cifrado con una palabra aterradora
infectada . Hay tres archivos en el archivo: index.html, main.js y test.wasm. Abramos el archivo index.html en un navegador y verifiquemos el resultado:
Bueno, con eso trabajaré. Comencemos con el estudio html, especialmente porque es la parte más fácil del desafío. El código html no contiene nada excepto la carga del script main.js.
<!DOCTYPE html> <html> <body> <span id="container"></span> <script src="./main.js"></script> </body> </html>
El guión tampoco hace nada complicado, a pesar de que parece un poco más detallado. Simplemente carga el archivo test.wasm y lo usa para crear una instancia de WebAssembly. Luego lee el parámetro "q" de la url y lo pasa al método match, exportado por la instancia. Si la cadena en el parámetro es incorrecta, el script muestra la imagen que hemos visto anteriormente, en términos de los desarrolladores de FireEye llamados "Pila de popó".
let b = new Uint8Array(new TextEncoder().encode(getParameterByName("q"))); let pa = wasm_alloc(instance, 0x200); wasm_write(instance, pa, a); let pb = wasm_alloc(instance, 0x200); wasm_write(instance, pb, b); if (instance.exports.Match(pa, a.byteLength, pb, b.byteLength) == 1) {
La solución de la tarea es encontrar el valor del parámetro q que hace que la función "match" devuelva "True". Para hacer esto, voy a desmontar el archivo test.wasm y analizar el algoritmo de la función Match.
No hay sorpresas, e intentaré hacerlo en Ghidra. Pero primero tengo que instalarlo. La instalación puede (y debe) descargarse de
https://ghidra-sre.org/ . Como está escrito en Java, casi no hay requisitos especiales para la instalación, no requiere ningún esfuerzo especial para instalarlo. Todo lo que necesita es descomprimir el archivo y ejecutar la aplicación. Lo único que se requiere es actualizar JDK y JRE a la versión 11.
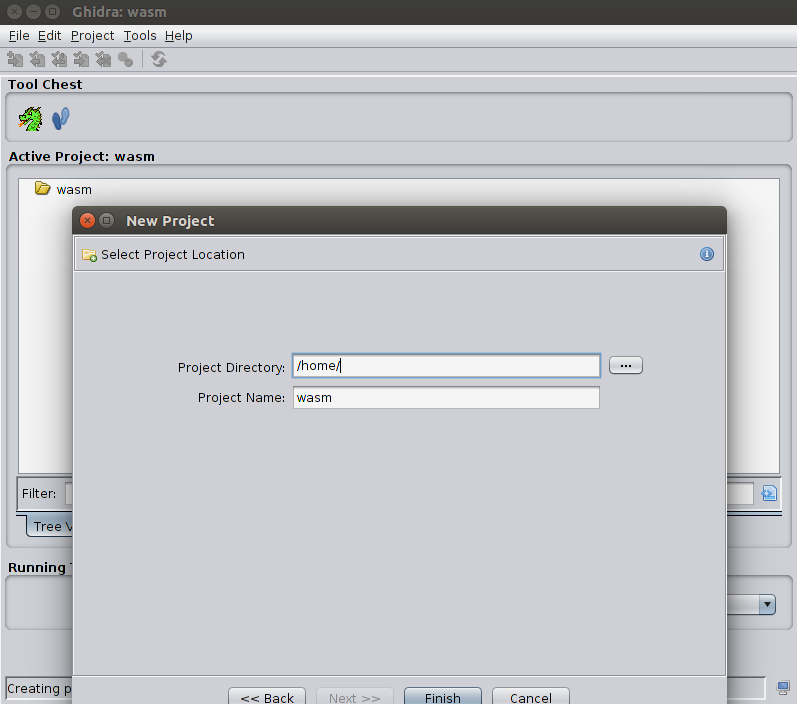
Creemos un nuevo proyecto ghidra (Archivo-
> Nuevo proyecto ), y llamémoslo "wasm" /
Luego agregue al proyecto el archivo test.wasm (
Archivo → Importar archivo ) y vea cómo ghidra puede manejarlo
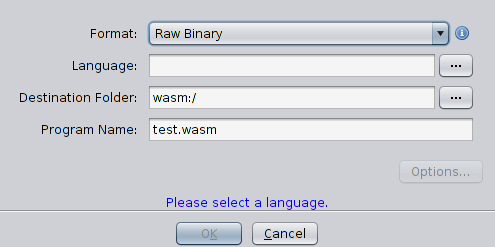
Bueno, no puede hacer nada. No reconoce el formato y no puede desmontar nada, por lo tanto, es absolutamente impotente para hacer frente a esta tarea. Finalmente hemos llegado al tema del artículo. No queda nada por hacer, pero escriba un módulo que pueda cargar el archivo wasm, analizarlo y desmontar su código.
En primer lugar, he estudiado toda la documentación disponible. En realidad, solo hay un documento adecuado que muestra el proceso de desarrollo de complementos: diapositivas GhidraAdvancedDevelopment. Voy a seguir el documento, dando una descripción detallada.
Desafortunadamente, el desarrollo de complementos requiere el uso de eclipse. Toda mi experiencia con eclipse es el desarrollo de dos juegos gdx para Android en 2012. Habían pasado dos semanas llenas de dolor y sufrimiento, después de lo cual lo borré de mi mente. Espero que después de 7 años de desarrollo sea mejor de lo que solía ser.
Descarguemos e instalemos eclipse desde el
sitio oficial.
Luego, instale la extensión para el desarrollo de ghidra:
Ir a eclipse
Ayuda → Instalar nuevo menú de
software , haga clic en el botón
Agregar y seleccione GhidraDev.zip desde / Extensions / Eclipse / GhidraDev /. Instálelo y reinicie la extensión. La extensión, agrega plantillas al nuevo menú del proyecto, permite depurar módulos del eclipse y compilar el módulo al paquete de distribución.
Como se desprende de los documentos de los desarrolladores, se deben seguir los siguientes pasos para agregar un módulo para procesar un nuevo formato binario:
- Crear clases, describiendo estructuras de datos.
- Desarrollar cargador. El cargador debe heredarse de la clase AbstractLibrarySupportLoader . Lee todos los datos necesarios del archivo, verifica la integridad de los datos y convierte los datos binarios en representación interna, preparándolos para el análisis
- Desarrollar analizador. El analizador se hereda de la clase AbstractAnalyzer . Toma las estructuras de datos preparadas por el cargador y las anota (no estoy muy seguro de lo que significa, pero espero entender durante el desarrollo)
- Añadir procesador. Ghidra tiene una abstracción: procesador. Está escrito en lenguaje declarativo interno y describe el conjunto de instrucciones, el diseño de la memoria y otras características arquitectónicas. Voy a cubrir este tema, escribiendo el desensamblador.
Ahora, cuando tenemos toda la teoría necesaria, es hora de crear el proyecto del módulo. Gracias a la extensión de eclipse previamente instalada GhidraDev, tenemos la plantilla del módulo directamente en el
menú Archivo-> Nuevo proyecto .
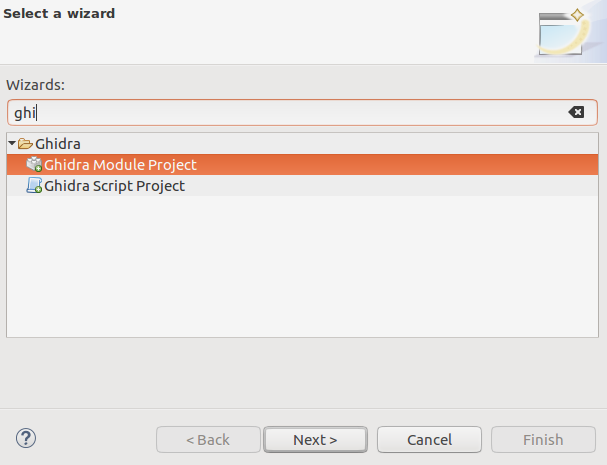
El asistente pregunta qué componentes son necesarios. Como se describió anteriormente, necesitaríamos dos de ellos: cargador y analizador.
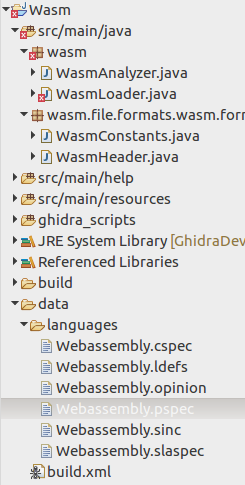
El asistente crea un esqueleto de proyecto con todas las partes necesarias: analizador en blanco en el archivo WasmAnalyzer.java, cargador en blanco en el archivo WasmLoader.java y esqueleto de idioma en el directorio / datos / idiomas.
Comencemos con el cargador. Como se mencionó, debe heredarse de la clase AbstractLibrarySupportLoader y tiene tres métodos para sobrecargarse:
- getName: este método debe incluir el nombre interno del cargador. Ghidra lo usa en varios lugares, por ejemplo, para vincular el cargador al procesador
- findSupportedLoadSpecs: devolución de llamada, ejecutada, cuando el usuario elige el archivo para importar. En este cargador de devolución de llamada debe decidir si es capaz de procesar el archivo y devolver la instancia de la clase LoadSpec, diciéndole al usuario cómo se puede procesar el archivo
- carga: devolución de llamada, ejecutada, después del archivo cargado por el usuario. En este método, el cargador analiza la estructura del archivo y se carga en ghidra. Lo describiremos con más detalles en el próximo artículo.
El primer método y el más simple es getName, solo devuelve el nombre del cargador
public String getName() { return "WebAssembly"; }
El segundo método para implementar es findSupportedLoadSpecs. La herramienta lo llama durante la importación del archivo y debe verificar si el cargador puede procesar el archivo. Si su método capaz devuelve el objeto de la clase
LoadSpec , indica qué objeto se usa para cargar el archivo y qué procesador desarmará su código.
El método comienza desde la verificación del formato. Como se desprende de la
especificación , los primeros ocho bytes del archivo wasm deben ser la firma "\ 0asm" y la versión.
Para analizar el encabezado, creé la clase WasmHeader, implementando la interfaz
StructConverter , que es la interfaz base para describir datos estructurados. El constructor de WasmHeader recibe el objeto
BinaryReader - abstracción, utilizada para leer datos de la fuente binaria que se analiza. El constructor lo usa para leer el encabezado del archivo de entrada
private byte[] magic; private byte [] version; public WasmHeader(BinaryReader reader) throws IOException { magic = reader.readNextByteArray(WASM_MAGIC_BASE.length()); version = reader.readNextByteArray(WASM_VERSION_LENGTH); }
Loader usa este objeto para verificar la firma del archivo. Luego, en caso de éxito, busca el procesador apropiado. Llama a la consulta de método de la clase
QueryOpinionService y le pasa el nombre del cargador ("Webassembly"). OpinionService está buscando un procesador asociado con este cargador y lo devuelve.
List<QueryResult> queries = QueryOpinionService.query(getName(), MACHINE, null);
Claro que no devuelve nada, porque ghidra no conoce el procesador, llamado WebAssembly y es necesario definirlo. Como dije antes, el asistente creó el esqueleto de idioma en los datos / idiomas del directorio.
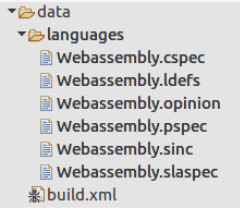
En la etapa actual, hay dos archivos que pueden ser interesantes: Webassembly.opinion y Wbassembly.ldefs. El archivo .opinon establece la correspondencia entre el cargador y el procesador.
<opinions> <constraint loader="WebAssembly" compilerSpecID="default"> <constraint primary="1" processor="Webassembly" size="16" /> </constraint> </opinions>
Contiene xml simple con pocos atributos. Es necesario establecer el nombre del cargador en el atributo "cargador" y el nombre del procesador en el atributo "procesador", ambos son "Webassembly". En este paso rellenaré otros parámetros con los valores aleatorios. Tan pronto como sepa más sobre el arquitecto del procesador Webassembly, los cambiaré a los valores correctos.
El archivo .ldefs describe las características del procesador, que debe ejecutar el código del archivo.
<language_definitions> <language processor="Webassembly" endian="little" size="16" variant="default" version="1.0" slafile="Webassembly.sla" processorspec="Webassembly.pspec" id="wasm:LE:16:default"> <description>Webassembly Language Module</description> <compiler name="default" spec="Webassembly.cspec" id="default"/> </language> </language_definitions>
El "procesador" de atributos debe ser el mismo que el procesador de atributos del archivo .opinion. Dejemos otros campos intactos. Pero recuerde la próxima vez que es posible establecer bittness de registro (atributo "tamaño"), archivo que describe la arquitectura del procesador "processorspec" y el archivo, que contiene la descripción del código en lenguaje declarativo especial "slafile". Será útil trabajar en el desmontaje.
Ahora, es hora de volver al cargador y devolver la especificación del cargador.
Todo está listo para la prueba. El complemento para GhidraDev ha agregado la opción de ejecución “
Ejecutar → Ejecutar como → Ghidra ” para eclipsar:
Ejecuta ghidra en modo de depuración y despliega su módulo, dando una gran oportunidad para trabajar con la herramienta y al mismo tiempo usar el depurador para corregir errores en el módulo que se está desarrollando. Pero en esta etapa simple no hay razón para usar un depurador. Como antes, crearé un nuevo proyecto, importaré un archivo y veré si mis esfuerzos dieron resultado. A diferencia de la última vez, el archivo se reconoce como WebAssembly, y el cargador propone el procesador correspondiente. Eso significa que todo funciona, y mi módulo puede reconocer el formato.
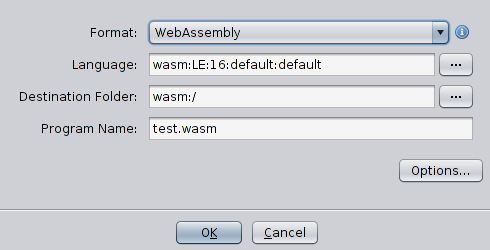
En el siguiente artículo, extenderé el cargador y haré que no solo reconozca, sino que también describa la estructura del archivo wasm. Creo que en esta etapa, después de configurar el entorno, será fácil de hacer.
El código del módulo está disponible en el repositorio de
github .