
Apache Spark hoy es quizás la plataforma más popular para analizar datos de gran volumen. La posibilidad de usarlo desde debajo de Python hace una contribución considerable a su popularidad. Al mismo tiempo, todos están de acuerdo en que, dentro del marco de la API estándar, el rendimiento del código Python y Scala / Java es comparable, pero no existe un punto de vista único con respecto a las funciones definidas por el usuario (Función definida por el usuario, UDF). Intentemos descubrir cómo aumentan los costos generales en este caso, utilizando el ejemplo de la tarea de verificar la solución SNA Hackathon 2019 .
Como parte de la competencia, los participantes resuelven el problema de clasificar las noticias de una red social y suben soluciones en forma de un conjunto de listas ordenadas. Para verificar la calidad de la solución obtenida, primero, para cada una de las listas cargadas, se calcula el ROC AUC y luego se muestra el valor promedio. Tenga en cuenta que necesita calcular no un AUC ROC común, sino uno personal para cada usuario: no hay un diseño listo para resolver este problema, por lo que deberá escribir una función especializada. Una buena razón para comparar los dos enfoques en la práctica.
Como plataforma de comparación, utilizaremos un contenedor en la nube con cuatro núcleos y Spark lanzado en modo local, y trabajaremos con él a través de Apache Zeppelin . Para comparar la funcionalidad, reflejaremos el mismo código en PySpark y Scala Spark. [aquí] Comencemos cargando los datos.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
Cuando se usa la API estándar, la identidad casi completa del código es notable, hasta la palabra clave val . El tiempo de operación no es significativamente diferente. Ahora intentemos determinar el UDF que necesitamos.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
Al implementar una función específica, está claro que Python es más conciso, principalmente debido a la capacidad de usar la función incorporada scikit-learn . Sin embargo, hay momentos desagradables: debe especificar explícitamente el tipo del valor de retorno, mientras que en Scala se determina automáticamente. Realicemos la operación:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
El código parece casi idéntico, pero los resultados son desalentadores.

La implementación en PySpark funcionó un minuto y medio en lugar de dos segundos en Scala, es decir, Python resultó ser 45 veces más lento . Mientras se ejecuta, la parte superior muestra 4 procesos activos de Python que se ejecutan a toda velocidad, y esto sugiere que el bloqueo global del intérprete no crea problemas aquí. Pero! Quizás el problema esté en la implementación interna de scikit-learn: intentemos reproducir el código de Python literalmente, sin recurrir a bibliotecas estándar.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

El experimento muestra resultados interesantes. Por un lado, con este enfoque, la productividad se niveló, pero por otro, el laconismo desapareció. Los resultados obtenidos pueden indicar que cuando se trabaja en Python usando módulos C ++ adicionales, aparecen gastos generales significativos para cambiar entre contextos. Por supuesto, hay una sobrecarga similar al usar JNI en Java / Scala, sin embargo, no tuve que lidiar con ejemplos de degradación 45 veces al usarlos.
Para un análisis más detallado, realizaremos dos experimentos adicionales: usar Python puro sin Spark para medir la contribución de la llamada del paquete, y con un mayor tamaño de datos en Spark para amortizar los gastos generales y obtener una comparación más precisa.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
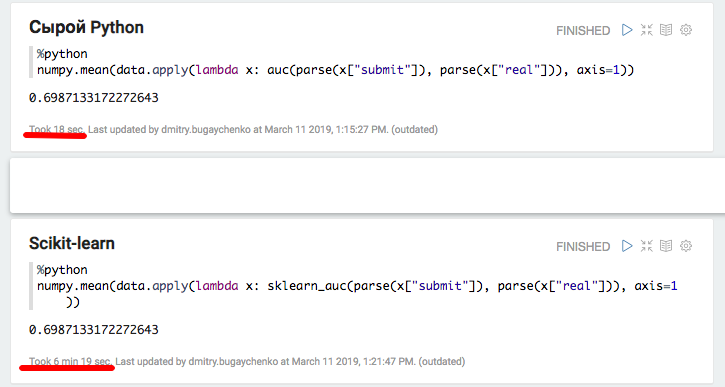
El experimento con Python y Pandas locales confirmó la suposición de una sobrecarga significativa al usar paquetes adicionales: cuando se usa scikit-learn, la velocidad disminuye en más de 20 veces. Sin embargo, 20 no es 45: intentemos "inflar" los datos y comparar el rendimiento de Spark nuevamente.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

La nueva comparación muestra la ventaja de velocidad de una implementación de Scala sobre Python en 7-8 veces, 7 segundos frente a 55. Finalmente, intentemos "lo más rápido que hay en Python", numpy para calcular la suma de la matriz:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
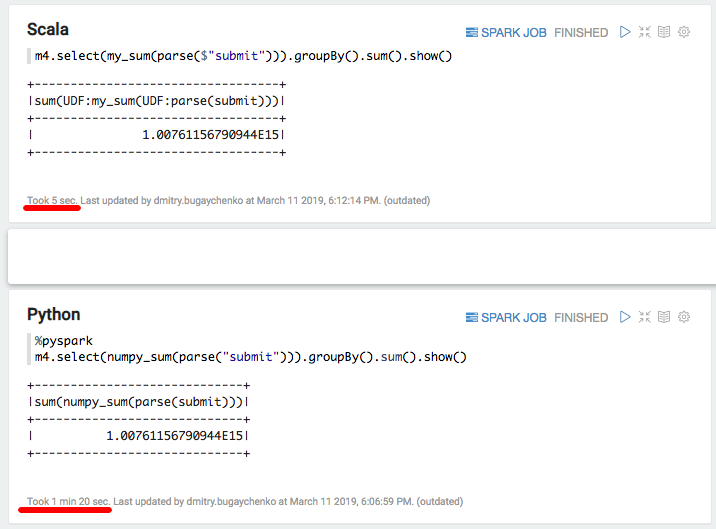
Nuevamente, una desaceleración significativa: 5 segundos de Scala frente a 80 segundos de Python. En resumen, podemos sacar las siguientes conclusiones:
- Si bien PySpark opera dentro del marco de la API estándar, realmente puede ser comparable en velocidad a Scala.
- Cuando aparece una lógica específica en forma de funciones definidas por el usuario, el rendimiento de PySpark disminuye notablemente. Con suficiente información, cuando el tiempo de procesamiento para un bloque de datos excede varios segundos, la implementación de Python es 5-10 más lenta debido a la necesidad de mover datos entre procesos y desperdiciar recursos al interpretar Python.
- Si aparece el uso de funciones adicionales implementadas en módulos C ++, entonces surgen costos de llamadas adicionales, y la diferencia entre Python y Scala aumenta hasta 10-50 veces.
Como resultado, a pesar de todo el encanto de Python, su uso en conjunto con Spark no siempre parece justificado. Si no hay tantos datos para hacer que la sobrecarga de Python sea significativa, entonces debería pensar si se necesita Spark aquí. Si hay muchos datos, pero el procesamiento se produce dentro del marco de la API estándar de Spark SQL, ¿se necesita Python aquí?
Si hay una gran cantidad de datos y a menudo tiene que lidiar con tareas que van más allá de los límites de la API de SQL, entonces para realizar la misma cantidad de trabajo cuando se usa PySpark, tendrá que aumentar el clúster en ocasiones. Por ejemplo, para Odnoklassniki, el costo de los gastos de capital para el grupo Spark aumentaría en muchos cientos de millones de rublos. Y si intenta aprovechar las capacidades avanzadas de las bibliotecas del ecosistema Python, es decir, el riesgo de desaceleración no es solo a veces, sino un orden de magnitud.
Se puede obtener cierta aceleración utilizando la funcionalidad relativamente nueva de las funciones vectorizadas. En este caso, no se alimenta una sola fila a la entrada UDF, sino un paquete de varias filas en forma de un marco de datos de Pandas. Sin embargo, el desarrollo de esta funcionalidad aún no se ha completado , e incluso en este caso la diferencia será significativa .
Una alternativa sería mantener un amplio equipo de ingenieros de datos, capaces de abordar rápidamente las necesidades de los científicos de datos con funciones adicionales. O sumergirse en el mundo Scala, ya que no es tan difícil: muchas de las herramientas necesarias ya existen , aparecen programas de capacitación que van más allá de PySpark.