Hola Habr! Les traigo a su atención una traducción del artículo
“Los 20 principales errores de subprocesos múltiples
de C ++ y cómo evitarlos” por Deb Haldar.
\"") Escena de la película "The Loop of Time" (2012)
Escena de la película "The Loop of Time" (2012)El subprocesamiento múltiple es una de las áreas más difíciles en la programación, especialmente en C ++. Con los años de desarrollo, cometí muchos errores. Afortunadamente, la mayoría de ellos fueron identificados por el código de revisión y las pruebas. Sin embargo, de alguna manera se deslizó en lo productivo, y tuvimos que editar los sistemas operativos, que siempre es costoso.
En este artículo, traté de clasificar todos los errores que conozco con posibles soluciones. Si tiene conocimiento de cualquier otra dificultad o tiene sugerencias para resolver los errores descritos, deje sus comentarios en el artículo.
Error n. ° 1: no utilice join () para esperar subprocesos en segundo plano antes de salir de la aplicación
Si olvida unirse a la secuencia (
join () ) o desanclarla (
detach () ) (hacer que no se pueda unir) antes de que finalice el programa, esto provocará un bloqueo. (La traducción contendrá las palabras join en el contexto de
join () y
detach en el contexto de
detach () , aunque esto no es del todo correcto. De hecho,
join () es el punto en el que un hilo de ejecución espera la finalización de otro, y no se produce una unión o fusión de hilos. [traductor de comentarios]).
En el siguiente ejemplo, olvidamos ejecutar
join () del hilo t1 en el hilo principal:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
//t1.join(); // join-
return 0 ;
}¿Por qué se bloqueó el programa? Porque al final de la función
main () , la variable t1 quedó fuera de alcance y se llamó al destructor de subprocesos. El destructor verifica si el hilo t1 es
unible . Se puede
unir un hilo si no se ha separado. En este caso,
std :: terminate se llama en su destructor. Esto es lo que hace, por ejemplo, el compilador MSVC ++.
~thread ( ) _NOEXCEPT
{ // clean up
if ( joinable ( ) )
XSTD terminate ( ) ;
}
Hay dos formas de solucionar el problema, dependiendo de la tarea:
1. Llame a
join () del hilo t1 en el hilo principal:
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. join ( ) ; // join t1,
return 0 ;
}
2. Separe la secuencia t1 de la secuencia principal, permita que continúe funcionando como una secuencia "demonizada":
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ; // t1
return 0 ;
}Error # 2: Intentando adjuntar un hilo que fue previamente desconectado
Si en algún momento del trabajo del programa tiene una transmisión
separada , no puede volver a adjuntarla a la transmisión principal. Este es un error muy obvio. El problema es que puede desanclar la transmisión y luego escribir unos cientos de líneas de código e intentar volver a conectarla. Después de todo, ¿quién recuerda que escribió 300 líneas, verdad?
El problema es que esto no causará un error de compilación, sino que el programa se bloqueará al inicio. Por ejemplo:
#include "stdafx.h"
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
t1. join ( ) ; // CRASH !!!
return 0 ;
}
La solución es verificar siempre el hilo para
unir () antes de intentar adjuntarlo al hilo de llamada.
int main ( )
{
thread t1 ( LaunchRocket ) ;
t1. detach ( ) ;
//..... 100 -
if ( t1. joinable ( ) )
{
t1. join ( ) ;
}
return 0 ;
}
Error # 3: malentendido que std :: thread :: join () bloquea el hilo de ejecución de la llamada
En aplicaciones reales, a menudo necesita separar las operaciones de "larga duración" de procesamiento de E / S de red o esperar a que un usuario haga clic en un botón, etc. Una llamada a
join () para dichos flujos de trabajo (por ejemplo, el subproceso de representación de la interfaz de usuario) puede hacer que la interfaz de usuario se bloquee. Existen métodos de implementación más adecuados.
Por ejemplo, en las aplicaciones GUI, un subproceso de trabajo, al finalizar, puede enviar un mensaje al subproceso de la interfaz de usuario. La transmisión UI tiene su propio ciclo de procesamiento de eventos, como: mover el mouse, presionar teclas, etc. Este bucle también puede recibir mensajes de subprocesos de trabajo y responder a ellos sin tener que llamar al método de
unión de bloqueo
() .
Por esta misma razón, casi todas las interacciones del usuario en la plataforma
WinRT de Microsoft se hacen asíncronas, y las alternativas sincrónicas no están disponibles. Estas decisiones se tomaron para garantizar que los desarrolladores utilizarán la API que proporciona la mejor experiencia posible para el usuario final. Puede consultar el manual "
Aplicaciones modernas de C ++ y Windows Store " para obtener más información sobre este tema.
Error # 4: suponiendo que los argumentos de la función de flujo se pasan por referencia por defecto
Los argumentos de la función de flujo se pasan por valor de forma predeterminada. Si necesita realizar cambios en los argumentos pasados, debe pasarlos por referencia utilizando la función
std :: ref () .
Bajo el spoiler, ejemplos de otro
artículo de C ++ 11 Tutorial de subprocesos múltiples a través de preguntas y respuestas - Conceptos básicos de administración de subprocesos (Deb Haldar) , que ilustran el paso de parámetros [aprox. traductor].
mas detalles:Al ejecutar el código:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, targetCity ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
Se mostrará en la terminal:
Changing The Target City To Metropolis
Current Target City is Star City
Como puede ver, el valor de la variable targetCity recibida por la función llamada en la secuencia por referencia no ha cambiado.
Reescribe el código usando std :: ref () para pasar el argumento:
#include "stdafx.h"
#include <string>
#include <thread>
#include <iostream>
#include <functional>
using namespace std ;
void ChangeCurrentMissileTarget ( string & targetCity )
{
targetCity = "Metropolis" ;
cout << " Changing The Target City To " << targetCity << endl ;
}
int main ( )
{
string targetCity = "Star City" ;
thread t1 ( ChangeCurrentMissileTarget, std :: ref ( targetCity ) ) ;
t1. join ( ) ;
cout << "Current Target City is " << targetCity << endl ;
return 0 ;
}
Producirá:
Changing The Target City To Metropolis
Current Target City is Metropolis
Los cambios realizados en el nuevo hilo afectarán el valor de la variable targetCity declarada e inicializada en la función principal .
Error # 5: no proteja los datos y recursos compartidos con una sección crítica (por ejemplo, un mutex)
En un entorno de subprocesos múltiples, generalmente más de un subproceso compite por recursos y datos compartidos. A menudo, esto conduce a un estado incierto para los recursos y los datos, excepto cuando el acceso a ellos está protegido por algún mecanismo que permite que solo un hilo de ejecución realice operaciones en ellos en cualquier momento.
En el ejemplo a continuación,
std :: cout es un recurso compartido con el que funcionan 6 subprocesos (t1-t5 + main).
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex mu ;
void CallHome ( string message )
{
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
}
int main ( )
{
thread t1 ( CallHome, "Hello from Jupiter" ) ;
thread t2 ( CallHome, "Hello from Pluto" ) ;
thread t3 ( CallHome, "Hello from Moon" ) ;
CallHome ( "Hello from Main/Earth" ) ;
thread t4 ( CallHome, "Hello from Uranus" ) ;
thread t5 ( CallHome, "Hello from Neptune" ) ;
t1. join ( ) ;
t2. join ( ) ;
t3. join ( ) ;
t4. join ( ) ;
t5. join ( ) ;
return 0 ;
}
Si ejecutamos este programa, obtenemos la conclusión:
Thread 0x1000fb5c0 says Hello from Main/Earth
Thread Thread Thread 0x700005bd20000x700005b4f000 says says Thread Thread Hello from Pluto0x700005c55000Hello from Jupiter says 0x700005d5b000Hello from Moon
0x700005cd8000 says says Hello from Uranus
Hello from Neptune
Esto se debe a que cinco subprocesos acceden simultáneamente a la secuencia de salida en orden aleatorio. Para hacer la conclusión más específica, debe proteger el acceso al recurso compartido utilizando
std :: mutex . Simplemente cambie la función
CallHome () para que capture el mutex antes de usar
std :: cout y lo libere después.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
mu. unlock ( ) ;
}Error # 6: Olvídate de liberar el bloqueo después de salir de la sección crítica
En el párrafo anterior, viste cómo proteger una sección crítica con un mutex. Sin embargo, llamar a los métodos
lock () y
unlock () directamente en el mutex no es la opción preferida porque puede olvidarse de activar el bloqueo retenido. ¿Qué pasará después? Todos los demás subprocesos que esperan la liberación del recurso se bloquearán infinitamente y el programa puede bloquearse.
En nuestro ejemplo sintético, si olvidó desbloquear el mutex en la llamada a la función
CallHome () , el primer mensaje del flujo t1 se enviará al flujo estándar y el programa se bloqueará. Esto se debe al hecho de que el subproceso t1 recibió un bloqueo de exclusión mutua y los subprocesos restantes esperan a que se libere este bloqueo.
void CallHome ( string message )
{
mu. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
//mu.unlock();
}La siguiente es la salida de este código: el programa se bloqueó, mostrando el único mensaje en el terminal y no terminó:
Thread 0x700005986000 says Hello from Pluto
Tales errores a menudo ocurren, por lo que no es deseable usar los métodos
lock () / unlock () directamente desde el mutex. En su lugar, use la clase de plantilla
std :: lock_guard , que usa el lenguaje
RAII para controlar la vida útil del bloqueo. Cuando se crea el objeto
lock_guard , intenta hacerse cargo del mutex. Cuando el programa abandona el alcance del objeto
lock_guard , se llama al destructor, que libera el mutex.
Reescribimos la función
CallHome () usando el objeto
std :: lock_guard :
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; //
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guardError # 7: aumentar el tamaño de la sección crítica más de lo necesario
Cuando un hilo se ejecuta dentro de una sección crítica, todos los demás que intentan ingresar están esencialmente bloqueados. Deberíamos mantener la menor cantidad de instrucciones posible en la sección crítica. Para ilustrar, se da un ejemplo de código incorrecto con una sección crítica grande:
void CallHome ( string message )
{
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
ReadFifyThousandRecords ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muEl método
ReadFifyThousandRecords () no modifica los datos. No hay razón para ejecutarlo bajo bloqueo. Si este método se ejecuta durante 10 segundos, leyendo 50 mil filas de la base de datos, todos los otros hilos se bloquearán innecesariamente durante todo este período. Esto puede afectar seriamente el rendimiento del programa.
La solución correcta sería mantenerse en la sección crítica solo trabajando con
std :: cout .
void CallHome ( string message )
{
ReadFifyThousandRecords ( ) ; // ..
std :: lock_guard < std :: mutex > lock ( mu ) ; // , std::cout
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
} // lock_guard muError # 8: tomar múltiples bloqueos en un orden diferente
Esta es una de las causas más comunes de
punto muerto , una situación en la que los subprocesos se bloquean infinitamente debido a la espera de acceso a los recursos bloqueados por otros subprocesos. Considere un ejemplo:
| corriente 1 | corriente 2 |
|---|
| bloquear A | cerradura B |
| // ... algunas operaciones | // ... algunas operaciones |
| cerradura B | bloquear A |
| // ... algunas otras operaciones | // ... algunas otras operaciones |
| desbloquear B | desbloquear A |
| desbloquear A | desbloquear B |
Puede surgir una situación en la que el subproceso 1 intentará capturar el bloqueo B y se bloqueará porque el subproceso 2 ya lo ha capturado. Al mismo tiempo, el segundo subproceso está intentando capturar el bloqueo A, pero no puede hacerlo, porque fue capturado por el primer subproceso. El hilo 1 no puede liberar el bloqueo A hasta que bloquee B, etc. En otras palabras, el programa se congela.
Este ejemplo de código te ayudará a reproducir un
punto muerto :
#include "stdafx.h"
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std ;
std :: mutex muA ;
std :: mutex muB ;
void CallHome_Th1 ( string message )
{
muA. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muB. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muB. unlock ( ) ;
muA. unlock ( ) ;
}
void CallHome_Th2 ( string message )
{
muB. lock ( ) ;
// -
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
muA. lock ( ) ;
cout << "Thread " << this_thread :: get_id ( ) << " says " << message << endl ;
muA. unlock ( ) ;
muB. unlock ( ) ;
}
int main ( )
{
thread t1 ( CallHome_Th1, "Hello from Jupiter" ) ;
thread t2 ( CallHome_Th2, "Hello from Pluto" ) ;
t1. join ( ) ;
t2. join ( ) ;
return 0 ;
}Si ejecuta este código, se bloqueará. Si profundiza en el depurador en la ventana de subprocesos, verá que el primer subproceso (llamado desde
CallHome_Th1 () ) está intentando bloquear el mutex B, mientras que el subproceso 2 (llamado desde
CallHome_Th2 () ) está intentando bloquear el mutex A. Ninguno de los subprocesos. no puede tener éxito, lo que lleva a un punto muerto!
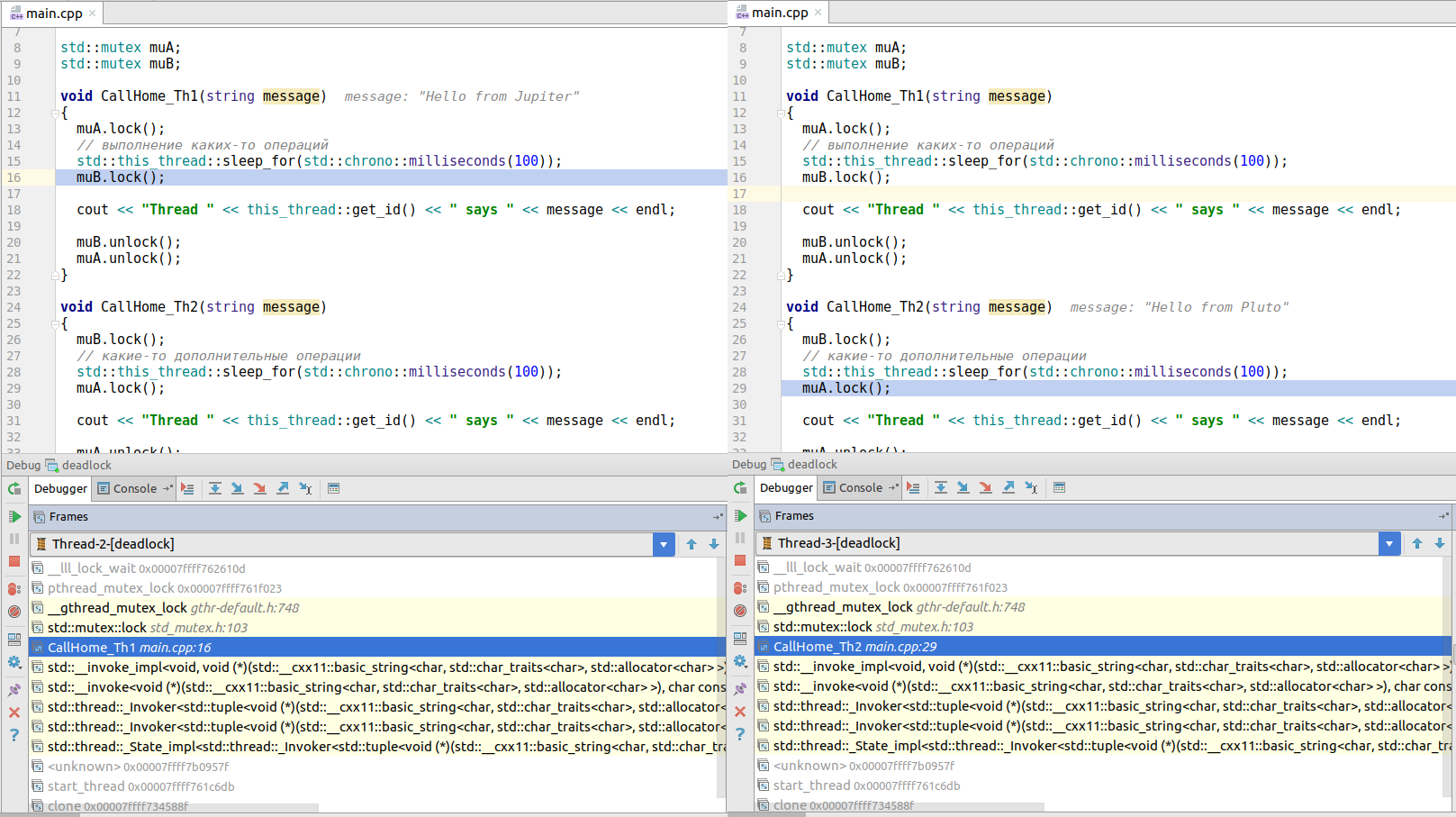
(se puede hacer clic en la imagen)
¿Qué puedes hacer al respecto? La mejor solución sería reestructurar el código para que los bloqueos de bloqueo ocurran en el mismo orden cada vez.
Dependiendo de la situación, puede usar otras estrategias:
1. Utilice la
clase de contenedor
std :: scoped_lock para capturar conjuntamente varios bloqueos:
std :: scoped_lock lock { muA, muB } ;2. Utilice la
clase std :: timed_mutex , en la que puede especificar un tiempo de espera, después del cual se liberará el bloqueo si el recurso no está disponible.
std :: timed_mutex m ;
void DoSome ( ) {
std :: chrono :: milliseconds timeout ( 100 ) ;
while ( true ) {
if ( m. try_lock_for ( timeout ) ) {
std :: cout << std :: this_thread :: get_id ( ) << ": acquire mutex successfully" << std :: endl ;
m. unlock ( ) ;
} else {
std :: cout << std :: this_thread :: get_id ( ) << ": can't acquire mutex, do something else" << std :: endl ;
}
}
}Error # 9: Tratando de agarrar un bloqueo std :: mutex dos veces
Intentar bloquear el bloqueo dos veces resultará en un comportamiento indefinido. En la mayoría de las implementaciones de depuración, esto se bloqueará. Por ejemplo, en el siguiente código,
LaunchRocket () bloqueará el mutex y luego llamará a
StartThruster () . Lo curioso es que en el código anterior no encontrará este problema durante el funcionamiento normal del programa, el problema solo ocurre cuando se produce una excepción, que se acompaña de un comportamiento indefinido o el programa finaliza de manera anormal.
#include "stdafx.h"
#include <iostream>
#include <thread>
#include <mutex>
std :: mutex mu ;
static int counter = 0 ;
void StartThruster ( )
{
try
{
// -
}
catch ( ... )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
std :: cout << "Launching rocket" << std :: endl ;
}
}
void LaunchRocket ( )
{
std :: lock_guard < std :: mutex > lock ( mu ) ;
counter ++ ;
StartThruster ( ) ;
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
return 0 ;
}
Para resolver este problema, debe corregir el código de manera que se evite la recuperación de bloqueos recibidos anteriormente. Puede usar
std :: recursive_mutex como una solución de muleta, pero tal solución casi siempre indica una mala arquitectura del programa.
Error # 10: Use mutexes cuando los tipos std :: atomic sean suficientes
Cuando necesite cambiar tipos de datos simples, como un valor booleano o un contador de enteros, el uso de
std: atomic generalmente brindará un mejor rendimiento que el uso de mutexes.
Por ejemplo, en lugar de usar la siguiente construcción:
int counter ;
...
mu. lock ( ) ;
counter ++ ;
mu. unlock ( ) ;
Es mejor declarar una variable como
std :: atomic :
std :: atomic < int > counter ;
...
counter ++ ;Para una comparación detallada de mutex y atómica, vea
Comparación: programación sin bloqueo con atómica en C ++ 11 vs. mutex y cerraduras RW »Error # 11: crear y destruir una gran cantidad de hilos directamente, en lugar de usar un grupo de hilos libres
Crear y destruir subprocesos es una operación costosa en términos de tiempo de procesador. Imagine un intento de crear una secuencia mientras el sistema realiza operaciones computacionalmente intensivas, por ejemplo, renderizando gráficos o física de juegos de computación. El enfoque utilizado a menudo para tales tareas es crear un grupo de subprocesos previamente asignados que puedan manejar tareas rutinarias, como escribir en el disco o enviar datos a través de la red durante todo el ciclo de vida del proceso.
Otra ventaja del grupo de subprocesos en comparación con el desove y la destrucción de subprocesos es que no necesita preocuparse por la
suscripción excesiva de subprocesos (una situación en la que el número de subprocesos excede el número de núcleos disponibles y una parte significativa del tiempo del procesador se pasa cambiando de contexto [aprox. traductor]). Esto puede afectar el rendimiento del sistema.
Además, el uso de la agrupación nos salva de las molestias de administrar el ciclo de vida de los subprocesos, lo que finalmente se traduce en un código más compacto con menos errores.
Las dos bibliotecas más populares que implementan el grupo de subprocesos son
Intel Thread Building Blocks (TBB) y
Microsoft Parallel Patterns Library (PPL) .
Error No. 12: no maneje las excepciones que ocurren en subprocesos en segundo plano
Las excepciones generadas en un hilo no se pueden manejar en otro hilo. Imaginemos que tenemos una función que arroja una excepción. Si ejecutamos esta función en un hilo separado que se bifurca del hilo principal de ejecución, y esperamos que detectemos cualquier excepción lanzada desde el hilo adicional, entonces esto no funcionará. Considere un ejemplo:
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr teptr = nullptr ;
void LaunchRocket ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
int main ( )
{
try
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
return 0 ;
}
Cuando se ejecuta este programa, se bloqueará, sin embargo, el bloque catch en la función main () no se ejecutará y no manejará la excepción lanzada en el hilo t1.
La solución a este problema es usar las características de C ++ 11:
std :: exception_ptr se usa para manejar la excepción lanzada en el hilo de fondo. Estos son los pasos que debe seguir:
- Cree una instancia global de la clase std :: exception_ptr inicializada en nullptr
- Dentro de una función que se ejecuta en un hilo separado, maneje todas las excepciones y establezca el valor std :: current_exception () de la variable global std :: exception_ptr declarada en el paso anterior
- Verifique el valor de una variable global dentro del hilo principal
- Si se establece el valor, use la función std :: rethrow_exception (exception_ptr p) para llamar repetidamente a la excepción capturada anteriormente, pasándola por referencia como parámetro
La recuperación de una excepción por referencia no se produce en el subproceso en el que se creó, por lo que esta característica es excelente para manejar excepciones en diferentes subprocesos.
En el siguiente código, puede manejar con seguridad la excepción lanzada en el hilo de fondo.
#include "stdafx.h"
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std :: exception_ptr globalExceptionPtr = nullptr ;
void LaunchRocket ( )
{
try
{
std :: this_thread :: sleep_for ( std :: chrono :: milliseconds ( 100 ) ) ;
throw std :: runtime_error ( "Catch me in MAIN" ) ;
}
catch ( ... )
{
//
globalExceptionPtr = std :: current_exception ( ) ;
}
}
int main ( )
{
std :: thread t1 ( LaunchRocket ) ;
t1. join ( ) ;
if ( globalExceptionPtr )
{
try
{
std :: rethrow_exception ( globalExceptionPtr ) ;
}
catch ( const std :: exception & ex )
{
std :: cout << "Thread exited with exception: " << ex. what ( ) << " \n " ;
}
}
return 0 ;
}
Error # 13: Use hilos para simular operaciones asincrónicas, en lugar de usar std :: async
Si necesita que el código se ejecute de forma asincrónica, es decir sin bloquear el hilo principal de ejecución, la mejor opción sería usar
std :: async () . Esto es equivalente a crear una secuencia y pasar el código necesario para ejecutar en esta secuencia a través de un puntero a una función o parámetro en forma de una función lambda. Sin embargo, en el último caso, debe supervisar la creación, la conexión / separación de este hilo, así como el manejo de todas las excepciones que puedan ocurrir en este hilo. Si usa
std :: async () , se alivia de estos problemas y también reduce drásticamente sus posibilidades de llegar a un
punto muerto .
Otra ventaja significativa de usar
std :: async es la capacidad de obtener el resultado de una operación asincrónica de nuevo al hilo de llamada usando el objeto
std :: future . Imagine que tenemos una función
ConjureMagic () que devuelve un int. Podemos comenzar una operación asincrónica, que establecerá el valor en el futuro para el objeto
futuro , cuando la tarea se complete, y podemos extraer el resultado de la ejecución de este objeto en el flujo de ejecución desde el que se llamó la operación.
// future
std :: future asyncResult2 = std :: async ( & ConjureMagic ) ;
//... - future
// future
int v = asyncResult2. get ( ) ;Obtener el resultado del hilo en ejecución a la persona que llama es más engorroso. Son posibles dos formas:
- Pasar una referencia a la variable de salida a la secuencia en la que guardará el resultado.
- Almacene el resultado en la variable de campo del objeto de flujo de trabajo, que puede leerse tan pronto como el hilo complete la ejecución.
Kurt Guntheroth descubrió que, en términos de rendimiento, la sobrecarga de crear una transmisión es 14 veces mayor que el uso de
asíncrono .
En pocas palabras: use
std :: async () por defecto hasta que encuentre argumentos sólidos a favor de usar
std :: thread directamente.
Error No. 14: No use std :: launch :: async si se requiere asincronía
La función
std :: async () no es exactamente el nombre correcto, porque por defecto puede que no se ejecute de forma asincrónica.
Hay dos políticas
std :: async runtime:
- std :: launch :: async : la función pasada comienza a ejecutarse inmediatamente en un hilo separado
- std :: launch :: deferred : la función pasada no se inicia inmediatamente, su lanzamiento se retrasa antes de que se realicen las llamadas get () o wait () en el objeto std :: future , que se devolverá de la llamada std :: async . En lugar de llamar a estos métodos, la función se ejecutará sincrónicamente.
Cuando llamamos a
std :: async () con parámetros predeterminados, comienza con una combinación de estos dos parámetros, lo que de hecho conduce a un comportamiento impredecible. Hay otras dificultades asociadas con el uso de
std: async () con la política de inicio predeterminada:
- incapacidad para predecir el acceso correcto a las variables de flujo local
- una tarea asincrónica puede no iniciarse en absoluto debido al hecho de que las llamadas a los métodos get () y wait () pueden no llamarse durante la ejecución del programa
- cuando se usa en bucles en los que la condición de salida espera que el objeto std :: future esté listo, es posible que estos bucles nunca terminen, porque std :: future devuelto por la llamada a std :: async puede comenzar en estado diferido.
Para evitar todas estas dificultades,
siempre llame a
std :: async con la política de
inicio std :: launch :: async .
No hagas esto:
// myFunction std::async
auto myFuture = std :: async ( myFunction ) ;En cambio, haz esto:
// myFunction
auto myFuture = std :: async ( std :: launch :: async , myFunction ) ;Este punto se considera con más detalle en el libro de Scott Meyers "C ++ efectivo y moderno".
Error # 15: llamar al método get () de un objeto std :: future en un bloque de código cuyo tiempo de ejecución es crítico
El siguiente código procesa el resultado obtenido del objeto
std :: future de una operación asincrónica. Sin embargo, el
ciclo while estará bloqueado hasta que se complete la operación asincrónica (en este caso, durante 10 segundos). Si desea utilizar este bucle para mostrar información en la pantalla, esto puede ocasionar retrasos desagradables en la representación de la interfaz de usuario.
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
int val = myFuture. get ( ) ; // 10
// - Val
}
return 0 ;
}
Nota : otro problema del código anterior es que intenta acceder al objeto
std :: future por segunda vez, aunque el estado del objeto
std :: future se recuperó en la primera iteración del bucle y no se pudo recuperar.
La solución correcta sería verificar la validez del objeto
std :: future antes de llamar al método
get () . Por lo tanto, no bloqueamos la finalización de la tarea asincrónica y no intentamos interrogar el objeto
std :: future ya extraído.
Este fragmento de código le permite lograr esto:
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
std :: this_thread :: sleep_for ( std :: chrono :: seconds ( 10 ) ) ;
return 8 ;
} ) ;
//
while ( true )
{
//
std :: cout << "Rendering Data" << std :: endl ;
if ( myFuture. valid ( ) )
{
int val = myFuture. get ( ) ; // 10
// - Val
}
}
return 0 ;
}
№16: , , , std::future::get()
Imagine que tenemos el siguiente fragmento de código, ¿cuál cree que será el resultado de llamar a std :: future :: get () ? Si asume que el programa se bloqueará, ¡tiene toda la razón! La excepción lanzada en la operación asincrónica se lanza solo cuando se llama al método get () en el objeto std :: future . Y si no se llama al método get () , la excepción se ignorará y se lanzará cuando el objeto std :: future quede fuera de alcance. Si su operación asincrónica puede generar una excepción, siempre debe ajustar la llamada a std :: future :: get () en un bloque try / catch . Un ejemplo de cómo se vería esto:#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
int result = myFuture. get ( ) ;
}
return 0 ;
}
#include "stdafx.h"
#include <future>
#include <iostream>
int main ( )
{
std :: future < int > myFuture = std :: async ( std :: launch :: async , [ ] ( )
{
throw std :: runtime_error ( "Catch me in MAIN" ) ;
return 8 ;
} ) ;
if ( myFuture. valid ( ) )
{
try
{
int result = myFuture. get ( ) ;
}
catch ( const std :: runtime_error & e )
{
std :: cout << "Async task threw exception: " << e. what ( ) << std :: endl ;
}
}
return 0 ;
}
№17: std::async,
Aunque std :: async () es suficiente en la mayoría de los casos, hay situaciones en las que puede necesitar un control cuidadoso sobre la ejecución de su código en una secuencia. Por ejemplo, si desea vincular un subproceso específico a un núcleo de procesador específico en un sistema multiprocesador (por ejemplo, Xbox).El fragmento de código dado establece la unión del hilo al quinto núcleo del procesador en el sistema. Esto es posible gracias al método native_handle () del objeto std :: thread y pasarlo a la función de secuencia de API Win32 . Hay muchas otras características proporcionadas a través de la API Win32 de transmisión que no están disponibles en std :: thread o std :: async () . Cuando trabaje a través de#include "stdafx.h"
#include <windows.h>
#include <iostream>
#include <thread>
using namespace std ;
void LaunchRocket ( )
{
cout << "Launching Rocket" << endl ;
}
int main ( )
{
thread t1 ( LaunchRocket ) ;
DWORD result = :: SetThreadIdealProcessor ( t1. native_handle ( ) , 5 ) ;
t1. join ( ) ;
return 0 ;
}
std :: async (), estas funciones básicas de la plataforma no están disponibles, lo que hace que este método no sea adecuado para tareas más complejas.Una alternativa es crear std :: packaged_task y moverlo al hilo de ejecución deseado después de establecer las propiedades del hilo.Error # 18: Crear muchos más hilos "en ejecución" que núcleos disponibles
Desde un punto de vista arquitectónico, los flujos se pueden clasificar en dos grupos: "en ejecución" y "en espera".Los subprocesos en ejecución utilizan el 100% del tiempo de procesador del núcleo en el que se ejecutan. Cuando se asigna más de un hilo en ejecución a un núcleo, la eficiencia de utilización de la CPU disminuye. No obtenemos una ganancia de rendimiento si ejecutamos más de un subproceso en ejecución en un núcleo de procesador; en realidad, el rendimiento disminuye debido a cambios de contexto adicionales.Los subprocesos en espera utilizan solo unos pocos ciclos de reloj en los que se ejecutan mientras esperan eventos del sistema o E / S de red, etc. En este caso, la mayor parte del tiempo de procesador disponible del núcleo permanece sin usar. Un subproceso en espera puede procesar datos, mientras que los otros esperan que se activen los eventos; es por eso que es ventajoso distribuir varios subprocesos en espera a un núcleo. La programación de múltiples subprocesos pendientes por núcleo puede proporcionar un rendimiento de programa mucho mayor.Entonces, ¿cómo entender cuántos hilos en ejecución admite el sistema? Use el método std :: thread :: hardware_concurrency () . Esta función generalmente devuelve el número de núcleos de procesador, pero tiene en cuenta los núcleos que se comportan como dos o más núcleos lógicos debido agipertredinga .Debe utilizar el valor obtenido de la plataforma de destino para planificar la cantidad máxima de subprocesos de su programa que se ejecutan simultáneamente. También puede asignar un núcleo para todos los subprocesos pendientes y utilizar el número restante de núcleos para ejecutar subprocesos. Por ejemplo, en un sistema de cuatro núcleos, use un núcleo para TODOS los subprocesos pendientes y para los tres núcleos restantes, tres subprocesos en ejecución. Dependiendo de la eficiencia de su programador de subprocesos, algunos de sus subprocesos ejecutables pueden cambiar de contexto (debido a fallas de acceso a la página, etc.), dejando el núcleo inactivo por algún tiempo. Si observa esta situación durante la creación de perfiles, debe crear un número ligeramente mayor de subprocesos ejecutados que el número de núcleos y configurar este valor para su sistema.Error # 19: uso de la palabra clave volátil para sincronización
La palabra clave volátil , antes de especificar el tipo de una variable, no hace que las operaciones en esta variable sean atómicas o seguras para subprocesos. Lo que probablemente quiera es std :: atomic .Vea la discusión sobre stackoverflow para más detalles.Error # 20: uso de la arquitectura sin bloqueo a menos que sea absolutamente necesario
Hay algo en complejidad que le gusta a todo ingeniero. Crear programas sin bloqueo suena muy tentador en comparación con los mecanismos de sincronización regulares como mutex, variables condicionales, asincronía, etc. Sin embargo, cada desarrollador experimentado de C ++ con el que hablé tenía una opinión que el uso de la programación sin bloqueo como una opción inicial es una especie de optimización prematura que puede ir de lado en el momento más inoportuno (¡piense en una falla en un sistema operativo cuando no tiene un volcado de memoria dinámico completo!).En mi carrera en C ++, solo había una situación que requería la ejecución de código sin bloqueos, porque trabajamos en un sistema con recursos limitados, donde cada transacción en nuestro componente no debería tomar más de 10 microsegundos.Antes de pensar en aplicar un enfoque de desarrollo sin bloqueo, responda tres preguntas:- ¿Ha intentado diseñar la arquitectura de su sistema para que no necesite un mecanismo de sincronización? Como regla general, la mejor sincronización es la falta de sincronización.
- Si necesita sincronización, ¿ha perfilado su código para comprender las características de rendimiento? Si es así, ¿ha intentado optimizar los cuellos de botella?
- ¿Se puede escalar horizontalmente en lugar de escalar verticalmente?
En resumen, para el desarrollo normal de aplicaciones, considere la programación sin bloqueo solo cuando haya agotado todas las demás alternativas. Otra forma de ver esto es que si todavía está cometiendo algunos de los 19 errores anteriores, probablemente debería mantenerse alejado de la programación sin bloquear.[De. traductor: muchas gracias a vovo4K por ayudarme a preparar este artículo.]