Alexander Rubin trabaja en Percona y ha actuado en
HighLoad ++ más de una vez, familiar para los participantes como experto en MySQL. Es lógico suponer que hoy hablaremos de algo relacionado con MySQL. Esto es así, pero solo en parte, porque también hablaremos sobre
Internet de las cosas . La historia será medio entretenida, especialmente su primera parte, en la que miramos el dispositivo que Alexander creó para cosechar albaricoques. Tal es la naturaleza de un verdadero ingeniero: si quieres fruta, compras una tarifa.

Antecedentes
Todo comenzó con un simple deseo de plantar un árbol frutal en su área. Parecería muy simple hacer esto: vienes a la tienda y compras una plántula. Pero en Estados Unidos, la primera pregunta que hacen los vendedores es cuánta luz solar recibirá el árbol. Para Alexander, esto resultó ser un misterio gigante: es completamente desconocido la cantidad de luz solar que hay en el sitio.
Para averiguarlo, un estudiante podría salir al patio todos los días, ver la cantidad de luz solar y escribirlo en un cuaderno. Pero este no es el caso: debe equipar todo y automatizarlo.
Durante la presentación, se ejecutaron muchos ejemplos y se tocaron en vivo. Si desea una imagen más completa que en el texto, cambie a ver el video.Entonces, para no registrar las observaciones climáticas en una computadora portátil, hay una gran cantidad de dispositivos para cosas de Internet: Raspberry Pi, la nueva Raspberry Pi, Arduino, miles de plataformas diferentes. Pero elegí un dispositivo llamado
Particle Photon para este proyecto. Es muy fácil de usar, cuesta $ 19 en el sitio web oficial.
Lo bueno de Particle Photon es:
- Solución 100% en la nube;
- Cualquier sensor es adecuado, por ejemplo, para Arduino. Todos cuestan menos de un dólar.
Hice un dispositivo así y lo puse en la hierba en el sitio. Tiene una nube de dispositivos de partículas y una consola. Este dispositivo se conecta a través de un punto de acceso Wi-Fi y envía datos: luz, temperatura y humedad. El probador duró 24 horas con una batería pequeña, lo cual es bastante bueno.
Además, no solo necesito medir la iluminación, etc., y transferirlos al teléfono (lo cual es realmente bueno, puedo ver en tiempo real qué tipo de iluminación tengo), sino también
almacenar datos . Para esto, naturalmente, como un veterano de MySQL, elegí MySQL.
¿Cómo escribimos datos en MySQL?
Elegí un esquema bastante complicado:
- Obtengo datos de la consola Particle;
- Yo uso Node.js para escribirlos en MySQL.
Estoy usando la API de Particle JS, que se puede descargar desde el sitio web de Particle. Establezco una conexión con MySQL y escribo, es decir, solo hago los valores INSERT INTO. Tal tubería.
Por lo tanto, el dispositivo se encuentra en el patio, se conecta a través de Wi-Fi al enrutador doméstico y utiliza el protocolo MQTT para transferir datos a Particle. Luego, el esquema: el programa en Node.js se ejecuta en la máquina virtual, que recibe datos de Particle y los escribe en MySQL.
Para comenzar, construí los gráficos a partir de los datos en bruto en R. Los gráficos muestran que la temperatura y la iluminación aumentan durante el día, caen de noche y aumenta la humedad; esto es natural. Pero también hay ruido en el gráfico, que es típico de los dispositivos de Internet de las cosas. Por ejemplo, cuando un error se arrastra sobre un dispositivo y lo cierra, el sensor puede transmitir datos completamente irrelevantes. Esto será importante para una mayor consideración.
Ahora hablemos de MySQL y JSON, lo que ha cambiado al trabajar con JSON de MySQL 5.7 a MySQL 8. Luego mostraré una demostración para la que uso MySQL 8 (en el momento del informe, esta versión aún no estaba lista para la producción, ya se ha lanzado una versión estable).
Almacenamiento de datos MySQL
Cuando intentamos almacenar los datos recibidos de los sensores, nuestro primer pensamiento es
crear una tabla en MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
Aquí para cada sensor y para cada tipo de datos hay una columna: luz, temperatura, humedad.
Esto es lo suficientemente lógico, pero
hay un problema: no es flexible . Supongamos que queremos agregar otro sensor y medir otra cosa. Por ejemplo, algunas personas miden la cerveza restante en un barril. ¿Qué hacer en este caso?
alter table sensor_wide add water level double ...;
¿Cómo pervertir para agregar algo a la tabla? Necesitas hacer una tabla alternativa, pero si hiciste una tabla alternativa en MySQL, entonces sabes de lo que estoy hablando, esto es completamente difícil. Alterar la tabla en MySQL 8 y MariaDB es mucho más simple, pero históricamente este es un gran problema. Entonces, si necesitamos agregar una columna, por ejemplo, con el nombre de la cerveza, entonces no será tan simple.
Una vez más, los sensores aparecen, desaparecen, ¿qué debemos hacer con los datos antiguos? Por ejemplo, dejamos de recibir información sobre iluminación. ¿O estamos creando una nueva columna: cómo almacenar lo que no estaba allí antes? El enfoque estándar es nulo, pero para el análisis no será muy conveniente.
Otra opción es un almacén de clave / valor.
Almacenamiento de datos MySQL: clave / valor
Esto será
más flexible : en clave / valor habrá un nombre, por ejemplo, temperatura y, en consecuencia, datos.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
En este caso, aparece
otro problema: no hay tipos . No sabemos lo que estamos almacenando en el campo 'datos'. Tendremos que declararlo como un campo de texto. Cuando creo mi dispositivo de Internet de las cosas, sé qué tipo de sensor hay y, en consecuencia, el tipo, pero si necesita almacenar los datos de otra persona en la misma tabla, no sabré qué datos se recopilan.
Puede almacenar muchas tablas, pero crear una tabla completamente nueva para cada sensor no es muy bueno.
Que se puede hacer - Usa JSON.
Almacenamiento de datos MySQL: JSON
La buena noticia es que en MySQL 5.7 puede almacenar JSON como un campo.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
Antes de que apareciera MySQL 5.7, la gente también almacenaba JSON, pero como un campo de texto. El campo JSON en MySQL le permite almacenar JSON de la manera más eficiente. Además, según JSON, puede crear columnas virtuales e índices basados en ellos.
El único problema menor es
que la tabla crecerá en tamaño durante el almacenamiento . Pero luego tenemos mucha más flexibilidad.
El campo JSON es mejor para almacenar JSON que el campo de texto porque:
- Proporciona validación automática de documentos . Es decir, si intentamos escribir algo que no es válido allí, se producirá un error.
- Este es un formato de almacenamiento optimizado . JSON se almacena en formato binario, lo que le permite cambiar de un documento JSON a otro, lo que se llama omitir.
Para almacenar datos en JSON, simplemente podemos usar SQL: hacer un INSERT, poner 'datos' allí y obtener datos del dispositivo.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
Demo
Para demostrar (
aquí comienza en el video), el ejemplo utiliza una máquina virtual en la que hay SQL.

A continuación se muestra un fragmento del programa.
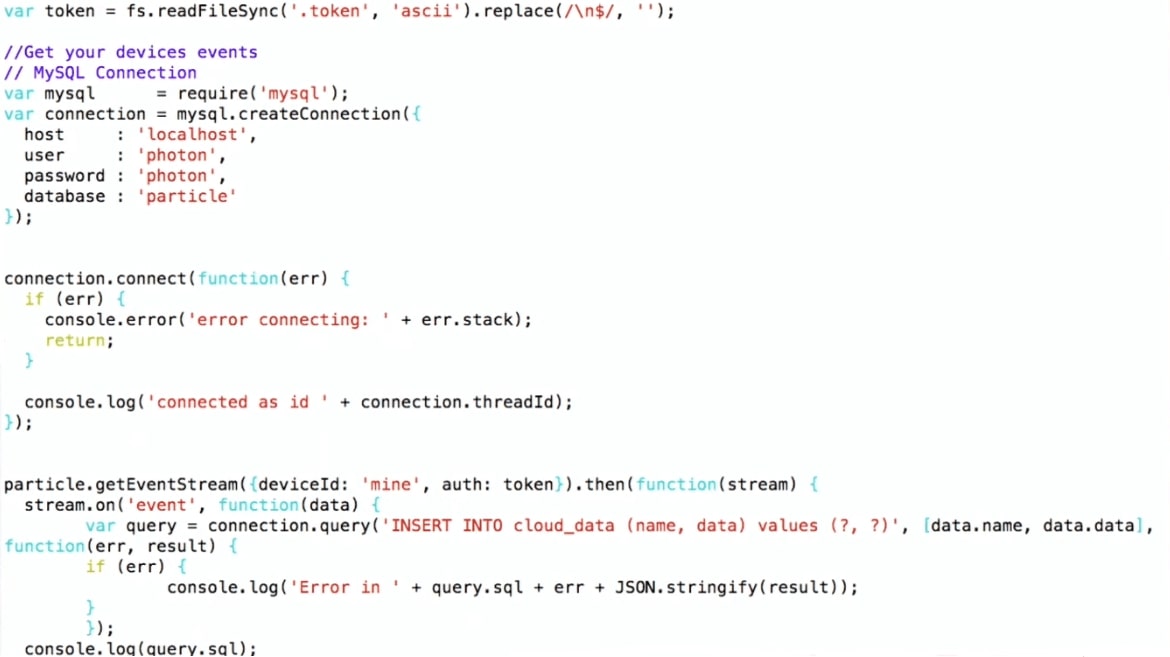
INSERT INTO cloud_data (name, data) , obtengo los datos ya en formato JSON, y puedo escribirlos directamente en MySQL tal como están, sin pensar en lo que hay dentro.
Resultó que, utilizando esta nube, puede acceder no solo a los datos de mi dispositivo, sino a
todos los datos que utiliza esta Partícula. Parece funcionar hasta ahora. Las personas que usan Particle Photon en todo el mundo están enviando algunos datos: la puerta del garaje está abierta, o el resto de la cerveza es tal o cual, o algo más. No se sabe dónde se encuentran estos dispositivos, pero se pueden obtener dichos datos. La única diferencia es que cuando obtengo mis datos, escribo algo como:
deviceId: 'mine' .
Cuando ejecutamos el código, obtenemos una secuencia de algunos datos de los dispositivos de otra persona que están haciendo algo.
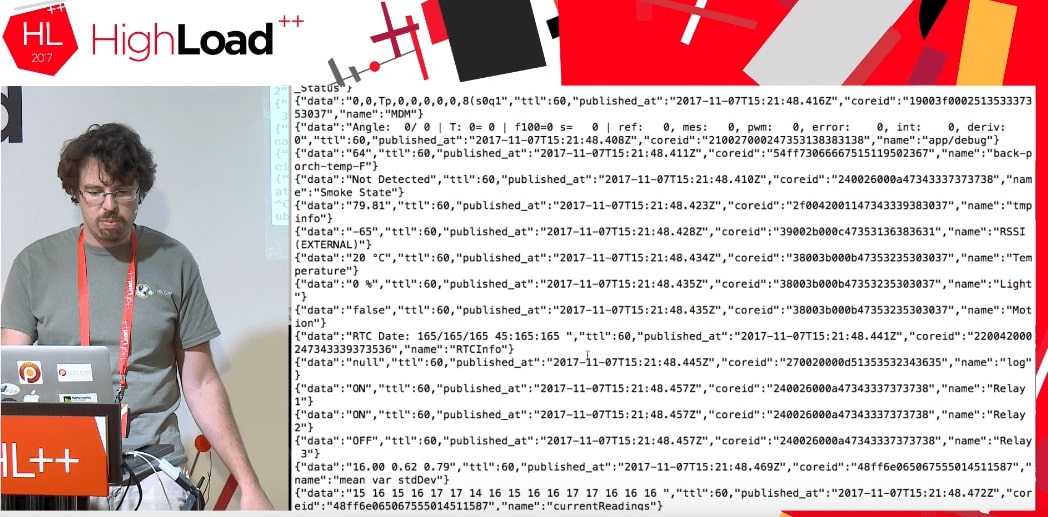
Absolutamente no sabemos cuáles son estos datos: TTL, publicado en, coreid, estado de la puerta (puerta abierta), relé activado.
Este es un gran ejemplo. Supongamos que trato de poner esto en MySQL en una estructura de datos normal. Debería saber cuál es la puerta, por qué está abierta y qué parámetros generales puede tomar. Si tengo JSON, entonces lo escribo directamente en MySQL como un campo JSON.
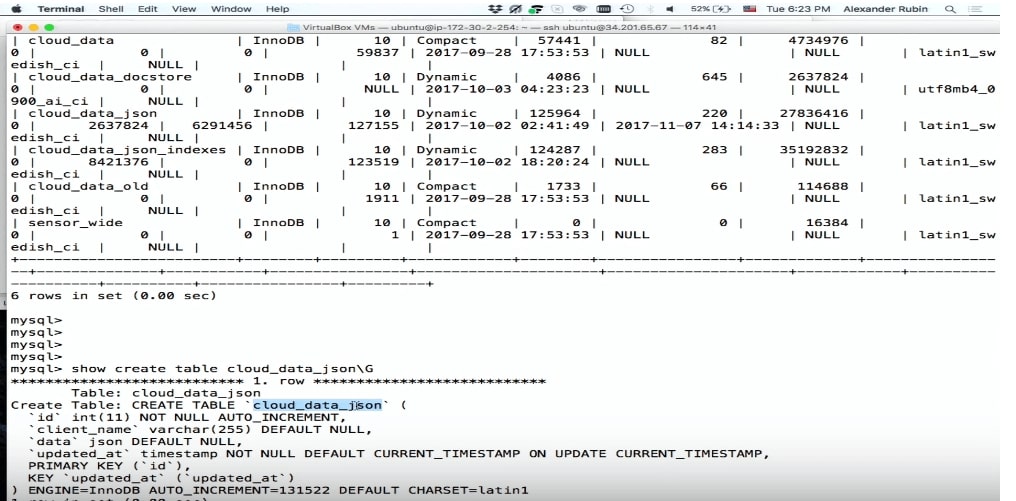
Por favor, todo ha sido grabado.
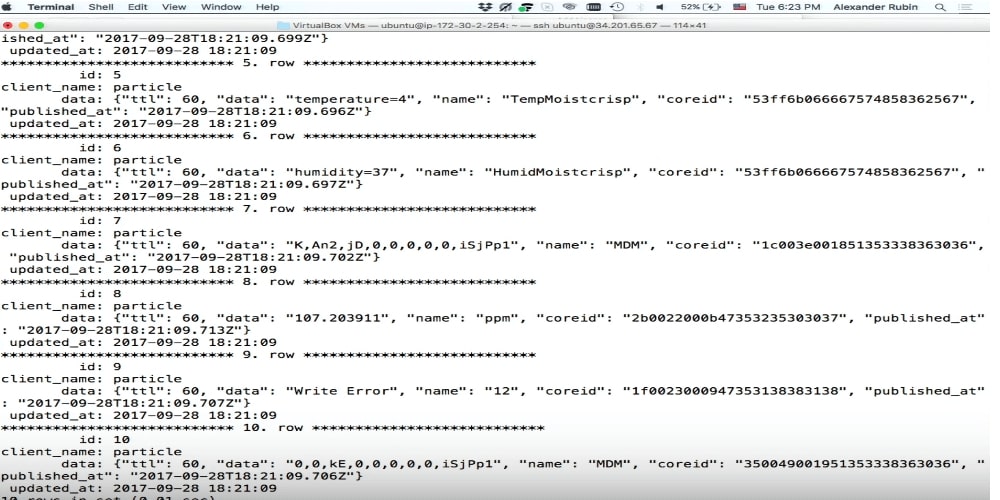
Tienda de documentos
Document store es un intento en MySQL para hacer almacenamiento para JSON. Realmente amo SQL, lo conozco bien, puedo hacer cualquier consulta SQL, etc. Pero a muchas personas no les gusta SQL por varias razones, y el almacén de documentos puede ser una solución para ellos, porque con él puedes abstraer de SQL, conectarte a MySQL y escribir JSON directamente allí.

Existe otra posibilidad que apareció en MySQL 5.7: usar un protocolo diferente, un puerto diferente y también se necesita otro controlador. Para Node.js (de hecho, para cualquier lenguaje de programación: PHP, Java, etc.), nos conectamos a MySQL usando un protocolo diferente y podemos transferir datos en formato JSON. Una vez más, no sé lo que tengo en este JSON: información sobre puertas u otra cosa, simplemente descargo los datos en MySQL y luego lo resolveremos.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
Si desea experimentar con esto, puede configurar MySQL 5.7 para que comprenda y escuche en el puerto apropiado Document store o X DevAPI. Usé connector-nodejs.
Este es un ejemplo de lo que escribo allí: cerveza, etc. No sé absolutamente qué hay allí. Ahora solo lo escribimos y lo analizamos más tarde.

El siguiente punto de nuestro programa es cómo ver qué hay allí.
Almacenamiento de datos MySQL: índices JSON +
Hay una gran característica en JSON y MySQL 5.7 que puede extraer campos de JSON. Este es el azúcar sintáctico en la función JSON_EXTRACT. Creo que esto es muy conveniente.
Los datos en nuestro caso son el nombre de la columna en la que se almacena JSON, y el nombre es nuestro campo. Nombre, datos, publicado en: esto es todo lo que podemos sacar de esta manera.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
En este ejemplo, quiero ver lo que he escrito en la tabla MySQL y los últimos 10 registros. Hago una solicitud de este tipo e intento ejecutarla. Lamentablemente,
esto funcionará durante mucho tiempo .
De manera lógica, MySQL no utilizará ningún índice en este caso. Extraemos los datos de JSON e intentamos aplicar algún tipo de filtro y clasificación. En este caso, obtenemos el uso de ordenar archivos.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
Usar filesort es muy malo, es un tipo externo.
La buena noticia es que puedes tomar 2 pasos para acelerarlo.
Paso 1. Crear una columna virtual
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Extraigo, es decir, extraigo datos de JSON y, en base a ellos, creo una columna virtual. La columna virtual no se almacena en MySQL 5.7 y MySQL 8: es solo la capacidad de crear una columna separada.
Si preguntas cómo es, dijiste que ALTER TABLE es una operación tan larga. Pero aquí no está tan mal.
Crear una columna virtual es rápido . Hay lok allí, pero en realidad en MySQL hay un bloqueo en todas las operaciones DDL. ALTER TABLE es una operación bastante rápida y no reconstruye toda la tabla.
Hemos creado una columna virtual aquí. Tuve que convertir la fecha, porque en JSON se almacena en formato iso, pero aquí MySQL usa un formato completamente diferente. Para crear una columna, lo nombré, le di un tipo y dije que grabaría allí.
Para optimizar la consulta original, debe extraer updated_at y name. Publicado_en ya existe, el nombre es más fácil, solo haga una columna virtual.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Paso 2. Crear un índice
En el siguiente código, creo un índice en updated_at y ejecuto la consulta:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
Puede ver que MySQL realmente usa el índice. Esta es una optimización por pedido. En este ejemplo, los datos y el nombre no están indexados. MySQL usa el orden por datos, y dado que tenemos un índice en updated_at, lo usa.
Además, podría usar la misma sintaxis azúcar
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") lugar de publicada_at en orden. MySQL aún entendería que hay un índice en esta columna y comenzaría a usarlo.
En realidad hay un pequeño problema con esto. Supongamos que quiero ordenar los datos no solo por updated_at, sino también por nombre.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
Si su dispositivo procesa decenas de miles de eventos por segundo, updated_at no dará una buena clasificación, ya que habrá duplicados. Por lo tanto, agregamos otra clasificación por data_name. Esta es una consulta típica no solo para Internet de las cosas: déme los últimos 10 eventos, sino que los clasifique por fecha y luego, por ejemplo, por el apellido de la persona en orden ascendente. Para hacer esto, en el ejemplo anterior, hay dos campos y se especifican dos claves de clasificación: descendente y ascendente.
En primer lugar, en este caso, MySQL no usará índices. En este caso particular, MySQL decide que un escaneo completo de la tabla será más rentable que usar un índice, y nuevamente se utiliza la operación de clasificación de archivos muy lenta.
Nuevo en MySQL 8.0
descendente / ascendente
En MySQL 5.7, dicha consulta no puede optimizarse, aunque solo sea a expensas de otras cosas. En MySQL 8, había una oportunidad real para especificar la ordenación de cada campo.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
Lo más interesante es que la clave descendente / ascendente después del nombre del índice ha estado durante mucho tiempo en SQL. Incluso en la primera versión de MySQL 3.23, puede especificar updated_at descennding o shown_at ascending. MySQL aceptó esto,
pero no hizo nada , es decir, siempre se ordenó en una dirección.
En MySQL 8, esto se solucionó y ahora existe tal característica. Puede crear un campo en orden descendente y con clasificación predeterminada.
Volvamos un segundo y miremos el ejemplo del paso 2 nuevamente.
¿Por qué funciona, de lo contrario no funciona? Esto funciona porque en los índices MySQL es un árbol B, y los índices del árbol B se pueden leer tanto desde el principio como desde el final. En este caso, MySQL lee el índice desde el final y todo está bien. Pero si hacemos descender y ascender, entonces no puedes leer. Puede leer en el mismo orden, pero
no puede combinar dos tipos : debe volver a ordenarlos.
Como estamos optimizando un caso muy específico, podemos crear un índice para él y especificar un tipo específico: aquí updated_at es descendente, data_name es ascendente. MySQL usa este índice, y todo estará bien y rápido.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
Esta es una característica de MySQL 8, que ahora, en el momento de la publicación, ya está disponible y lista para usar en producción.
Resultados de salida
Hay dos cosas más interesantes que quiero mostrar:
1. Impresión bonita, es decir, una hermosa salida de datos a la pantalla. Con SELECT normal, JSON no se formateará.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. Podemos decir que MySQL generará el resultado en forma de una matriz JSON o un objeto JSON, especificará los campos y luego la salida se formateará como JSON.
Búsqueda de texto completo dentro de documentos JSON
Si utilizamos un sistema de almacenamiento flexible y no sabemos qué hay dentro de nuestro JSON, sería lógico utilizar la búsqueda de texto completo.
Desafortunadamente,
la búsqueda de texto completo tiene sus limitaciones . Lo primero que intenté fue crear una clave de texto completo. Traté de hacer tal cosa:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
Lamentablemente esto no funciona. Incluso en MySQL 8, desafortunadamente es imposible crear un índice de texto completo simplemente por el campo JSON. Por supuesto, me gustaría tener esa función: la capacidad de buscar al menos por teclas JSON sería muy útil.
Pero si esto aún no es posible, creemos una columna virtual. En nuestro caso, hay un campo de datos, y sería interesante para nosotros ver qué hay dentro.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
Desafortunadamente, esto tampoco funciona:
no puede crear un índice de texto completo en una columna virtual .
Si es así, creemos una columna almacenada. MySQL 5.7 le permite declarar una columna como un campo almacenado.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
En los ejemplos anteriores, creamos columnas virtuales que no se almacenan, pero se crean y almacenan índices. En este caso, tuve que decirle a MySQL que se trata de una columna ALMACENADA, es decir, se creará y se copiarán los datos. Después de eso, MySQL creó un índice de texto completo, para esto tuvimos que recrear la tabla. Pero esta limitación es en realidad la búsqueda de texto completo de InnoDB e InnoDB: debe volver a crear la tabla para agregar un identificador de búsqueda de texto completo especial.
Curiosamente, en MySQL 8 había una
nueva codificación UTF8 MB4 para emoticones . Por supuesto, no del todo para ellos, pero porque en UTF8MB3 hay algunos problemas con el ruso, chino, japonés y otros idiomas.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
En consecuencia, MySQL 8 debería almacenar datos JSON en UTF8MB4. Pero ya sea por el hecho de que Node.js se conecta a Device Cloud, y algo está escrito allí incorrectamente, o es un error de versión beta, esto no sucedió. Por lo tanto, tuve que convertir los datos antes de escribirlos en una columna almacenada.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
Después de eso, pude crear una búsqueda de texto completo en dos campos: en el nombre JSON y en los datos JSON.
No solo IoT
JSON no es solo el Internet de las cosas. Se puede usar para otras cosas interesantes:
- Campos personalizados (CMS);
- Estructuras complejas, etc.
Algunas cosas pueden implementarse de manera mucho más conveniente utilizando un esquema de almacenamiento de datos flexible. Oracle OpenWorld proporcionó un excelente ejemplo: reservas de cine. Es muy difícil implementar esto en el modelo relacional: obtienes muchas tablas dependientes, uniones, etc. Por otro lado, podemos almacenar toda la sala como una estructura JSON, respectivamente, escribirla en MySQL en otras tablas y usarla de la manera habitual: crear índices basados en JSON, etc.
Las estructuras complejas se almacenan convenientemente en formato JSON.
Este es un árbol que se ha plantado con éxito. Desafortunadamente, unos años más tarde, los ciervos se lo comieron, pero esta es una historia completamente diferente.
Este informe es un excelente ejemplo de cómo una sección completa se desarrolla a partir de un tema en una conferencia grande, y luego un evento separado por separado. En el caso de Internet de las cosas, obtuvimos InoThings ++ , una conferencia para profesionales en el mercado de Internet de las cosas, que se realizará por segunda vez el 4 de abril.
Parece que el evento central de la conferencia será la mesa redonda "¿Necesitamos estándares nacionales en Internet de las cosas?", Que orgánicamente se complementará con informes completos aplicados. Ven si tus sistemas con mucha carga se están moviendo correctamente a IIoT.