
A lo largo de los años de operación de Kubernetes en producción, hemos acumulado muchas historias interesantes, ya que los errores en varios componentes del sistema llevaron a consecuencias desagradables y / o incomprensibles que afectan el funcionamiento de contenedores y contenedores. En este artículo, hemos hecho una selección de algunos de los más frecuentes o interesantes. Incluso si nunca tienes la suerte de enfrentarte a tales situaciones, leer acerca de detectives tan breves, sobre todo de primera mano, siempre es entretenido, ¿no?
Historia 1. Docker supercrónico y congelante
En uno de los grupos, recibimos periódicamente un Docker "congelado", que interfiere con el funcionamiento normal del grupo. Al mismo tiempo, se observó lo siguiente en los registros de Docker
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
En este error, estamos más interesados en el mensaje:
pthread_create failed: No space left on device . Un estudio rápido de la
documentación explicó que Docker no podía bifurcar el proceso, lo que ocasionaba que se "congelara" periódicamente.
Al monitorear lo que está sucediendo, la siguiente imagen corresponde:

Una situación similar se observa en otros nodos:


En los mismos nodos vemos:
root@kube-node-1 ~
Resultó que este comportamiento es una consecuencia del trabajo del
pod con
supercronic (la utilidad en Go que usamos para ejecutar tareas cron en pods):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
El problema es este: cuando una tarea comienza en supercrónica, el proceso generado por ella
no puede completarse correctamente , convirtiéndose en un
zombie .
Nota : Para ser más precisos, los procesos son generados por tareas cron, sin embargo, supercronic no es un sistema init y no puede "adoptar" los procesos que generaron sus hijos. Cuando se producen señales SIGHUP o SIGTERM, no se transmiten a los procesos generados, como resultado de lo cual los procesos secundarios no terminan, quedando en estado zombie. Puede leer más sobre todo esto, por ejemplo, en dicho artículo .Hay un par de formas de resolver problemas:
- Como solución temporal: aumente el número de PID en el sistema en un solo momento:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- O bien, realice el inicio de tareas en supercrónico no directamente, sino con la ayuda del mismo tini , que puede finalizar correctamente los procesos y no generar un zombi.
Historia 2. "Zombis" al eliminar cgroup
Kubelet comenzó a consumir mucha CPU:
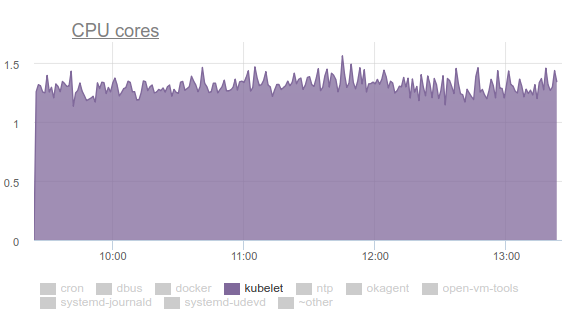
A nadie le gusta esto, así que nos armamos con
perf y comenzamos a lidiar con el problema. Los resultados de la investigación fueron los siguientes:
- Kubelet gasta más de un tercio del tiempo de CPU extrayendo datos de memoria de todos los cgroups:

- En la lista de correo de desarrolladores de kernel puede encontrar una discusión del problema . En resumen, la conclusión es que los diferentes archivos tmpfs y otras cosas similares no se eliminan por completo del sistema cuando se elimina cgroup; el llamado zombie memcg permanece. Tarde o temprano, sin embargo, se eliminarán de la caché de la página, sin embargo, la memoria en el servidor es grande y el núcleo no ve el punto de perder el tiempo eliminándolos. Por lo tanto, continúan acumulándose. ¿Por qué está pasando esto? Este es un servidor con trabajos cron que constantemente crea nuevos trabajos, y con ellos nuevos pods. Por lo tanto, se crean nuevos cgroups para contenedores en ellos, que se eliminarán pronto.
- ¿Por qué cAdvisor en kubelet pasa tanto tiempo? Esto se ve fácilmente en la ejecución más simple de
time cat /sys/fs/cgroup/memory/memory.stat . Si la operación toma 0.01 segundos en una máquina en buen estado, luego 1.2 segundos en un cron02 problemático. La cuestión es que cAdvisor, que lee los datos de sysfs muy lentamente, también trata de tener en cuenta la memoria utilizada en los grupos de zombies. - Para eliminar a la fuerza los zombies, intentamos borrar los cachés, como se recomienda en LKML:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches , pero el núcleo resultó ser más complicado y bloqueó la máquina.
Que hacer El problema se soluciona (
confirmar y la descripción, ver
el mensaje de lanzamiento ) actualizando el kernel de Linux a la versión 4.16.
Historia 3. Systemd y su montura
Nuevamente, kubelet consume demasiados recursos en algunos nodos, pero esta vez ya es memoria:

Resultó que hay un problema en el systemd usado en Ubuntu 16.04, y ocurre cuando se controlan los montajes que se crean para conectar
subPath desde ConfigMaps o secretos. Una vez que se completa el pod, el
servicio systemd y su soporte de servicio permanecen en el sistema. Con el tiempo, acumulan una gran cantidad. Incluso hay problemas sobre este tema:
- kops # 5916 ;
- Kubernetes # 57345 .
... en el último de los cuales se refieren a PR en systemd:
# 7811 (el problema en systemd es
# 7798 ).
El problema ya no está en Ubuntu 18.04, pero si desea continuar usando Ubuntu 16.04, nuestra solución sobre este tema puede ser útil.
Entonces, hicimos el siguiente DaemonSet:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... y utiliza el siguiente script:
... y comienza cada 5 minutos con el supercrónico ya mencionado. Su Dockerfile se ve así:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
Historia 4. Competencia en vainas de planificación
Se señaló que: si se coloca una cápsula en nuestro nodo y su imagen se bombea durante mucho tiempo, entonces la otra cápsula que "llegó" al mismo nodo simplemente
no comienza a extraer la imagen de la nueva cápsula . En cambio, espera a que se extraiga la imagen de la cápsula anterior. Como resultado, un pod que ya ha sido planeado y cuya imagen podría descargarse en solo un minuto terminará en el estado de creación de
containerCreating durante mucho tiempo.
En eventos, habrá algo como esto:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
Resulta que
una sola imagen del registro lento puede bloquear la implementación en el nodo.
Desafortunadamente, no hay muchas maneras de salir de la situación:
- Intente utilizar su Docker Registry directamente en el clúster o directamente con el clúster (por ejemplo, GitLab Registry, Nexus, etc.);
- Use utilidades como kraken .
Historia 5. Nodos colgantes sin memoria
Durante el funcionamiento de varias aplicaciones, también recibimos una situación en la que el nodo deja de ser accesible por completo: SSH no responde, todos los demonios de monitoreo se caen y luego nada (o casi nada) es anormal en los registros.
Te diré en las imágenes el ejemplo de un nodo donde funcionó MongoDB.
Así es como se ve
antes del accidente:

Y así,
después del accidente:

También en la supervisión, hay un salto brusco en el que el nodo deja de ser accesible:
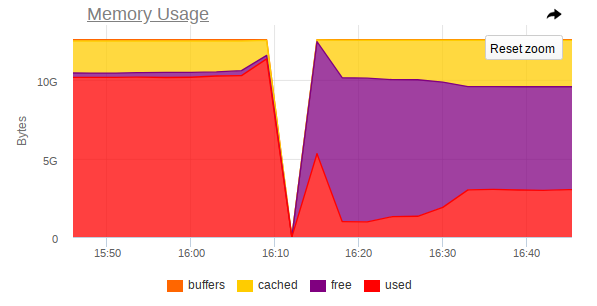
Por lo tanto, las capturas de pantalla muestran que:
- RAM en la máquina está cerca del final;
- Se observa un salto brusco en el consumo de RAM, después de lo cual el acceso a toda la máquina se deshabilita bruscamente;
- Una gran tarea llega a Mongo, que obliga al proceso DBMS a usar más memoria y leer activamente desde el disco.
Resulta que si Linux se queda sin memoria libre (se produce presión de memoria) y no hay intercambio, entonces
antes de que llegue el asesino OOM, puede ocurrir un equilibrio entre tirar páginas en el caché de páginas y volver a escribirlas en el disco. Esto se hace mediante kswapd, que con valentía libera tantas páginas de memoria como sea posible para su posterior distribución.
Desafortunadamente, con una gran carga de E / S, junto con una pequeña cantidad de memoria libre,
kswapd se convierte en el cuello de botella de todo el sistema , porque
todas las fallas de página de las páginas de memoria en el sistema están vinculadas a él. Esto puede continuar durante mucho tiempo si los procesos ya no quieren usar memoria, pero se arreglan en el borde del abismo asesino de OOM.
La pregunta lógica es: ¿por qué el asesino OOM llega tan tarde? En la iteración actual de OOM, killer es extremadamente estúpido: matará el proceso solo cuando el intento de asignar una página de memoria falle, es decir Si falla la página. Esto no sucede durante mucho tiempo, porque kswapd libera valientemente páginas de memoria volcando el caché de páginas (de hecho, todas las E / S de disco en el sistema) de nuevo al disco. Con más detalle, con una descripción de los pasos necesarios para eliminar tales problemas en el núcleo, puede leer
aquí .
Este comportamiento
debería mejorar con el kernel Linux 4.6+.
Historia 6. Las vainas están pendientes
En algunos grupos, en los que hay muchas cápsulas, comenzamos a notar que la mayoría de ellos estuvieron colgados en el estado
Pending durante mucho tiempo, aunque los contenedores Docker ya se estaban ejecutando en los nodos y se podía trabajar manualmente con ellos.
No hay nada malo con
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
Después de investigar, asumimos que Kubelet simplemente no tiene tiempo para enviar al servidor API toda la información sobre el estado de los pods, muestras de vida / disponibilidad.
Y después de estudiar ayuda, encontramos los siguientes parámetros:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
Como puede ver, los
valores predeterminados son bastante pequeños , y en un 90% cubren todas las necesidades ... Sin embargo, en nuestro caso esto no fue suficiente. Por lo tanto, establecemos estos valores:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... y reiniciaron los kubelets, después de lo cual vieron la siguiente imagen en los gráficos de acceso al servidor API:

... y sí, ¡todo comenzó a volar!
PS
Para obtener ayuda en la recolección de errores y la preparación del artículo, expreso mi profunda gratitud a los numerosos ingenieros de nuestra empresa, y en particular a Andrei Klimentyev (colega de nuestro equipo de I + D) (
zuzzas ).
PPS
Lea también en nuestro blog: