En respuesta a un aumento en la cantidad de aplicaciones en ejecución y la cantidad de dispositivos de red, el ancho de banda de la red aumenta y los requisitos de entrega de paquetes son más estrictos. En una escala de centros de datos críticos para la nube críticos para los negocios, el enfoque tradicional para el mantenimiento de la infraestructura ya no permite resolver tareas típicas. Por lo tanto, nació el concepto de AIOps (Algorithmic IT Operations).
Según Gartner, alrededor del 50% de las empresas utilizarán AIOps para el próximo año. Podemos hablar sobre lo que pueden hacer hoy herramientas similares, utilizando el ejemplo de Huawei FabricInsight, un analizador de red que es parte de una solución integral para los centros de datos de Huawei CloudFabric.
La transformación digital de las empresas ofrece nuevas oportunidades: la introducción del análisis de Big Data, el desarrollo de algoritmos de aprendizaje automático, ya no es solo una moda, sino una necesidad consciente, cuyo cierre genera ganancias reales. Sin embargo, las nuevas implementaciones implican un aumento múltiple en la complejidad de la infraestructura, que al mismo tiempo plantea nuevos desafíos en términos de mantenimiento.
El principal problema de mantener una gran infraestructura hoy en día es la cantidad de datos que se deben recopilar y procesar para obtener información sobre el estado del centro de datos, así como la velocidad con la que se debe dar una respuesta relevante a las causas de las fallas. Por un lado, el número de parámetros monitoreados está en constante crecimiento, por otro, el tiempo juega en contra de las organizaciones, porque el objetivo de cualquier empresa es restaurar la disponibilidad de sus servicios lo antes posible si algo sale mal (especialmente teniendo en cuenta los estrictos requisitos de SLA). La velocidad del "aumento" del servicio después del colapso está determinada en gran medida por la velocidad de la investigación del incidente. Y, a su vez, depende de la integridad de la información sobre lo que está sucediendo. Pero si se instalan al menos 50 a 100 racks de servidores en el centro de datos, los mecanismos de monitoreo estándar no pueden hacer frente a los requisitos de gran ancho de banda y la entrega oportuna de paquetes.
¿Por qué falla SNMP?
Los mecanismos estándar (SNMP y xFlow) recopilan datos solo cada 5-15 minutos, muestreando información. Originalmente se desarrollaron teniendo en cuenta las limitaciones del procesamiento posterior de los datos acumulados sin la tarea de identificar problemas en tiempo real. E incluso dicha recopilación de datos limitada afecta el funcionamiento de los dispositivos de red.
Teniendo en cuenta que el tráfico problemático es solo del 3.65%, el enfoque tradicional, basado en los resultados del análisis, revela solo el 30% de los problemas de red, el 70% no es visible para los sistemas de monitoreo.
Se necesitan administradores experimentados que sepan qué y dónde buscar para identificar la raíz del problema a partir de los datos recopilados por SNMP y xFlow. Los problemas deben identificarse analizando registros enormes y múltiples mensajes de error, y luego haciendo cambios de configuración manualmente. Pero con el desarrollo de SDN, con la virtualización de recursos físicos, la configuración manual es cosa del pasado. Hoy, incluso un equipo completo de administradores de sistemas ya no puede garantizar el cumplimiento continuo de los parámetros de infraestructura con los requisitos comerciales.
FabricInsight funciona de manera diferente
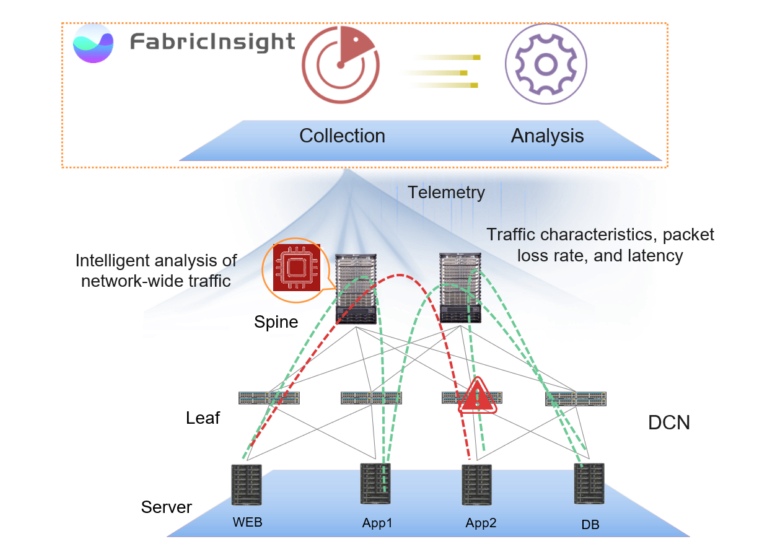
FabricInsight Network Analysis Platform ofrece un enfoque diferente, automatizando el mantenimiento de la red y la detección de puntos de falla. FabricInsight analiza el comportamiento de las aplicaciones, identifica las rutas de red que utilizan y rastrea el estado de los dispositivos en ellas.

Este enfoque se basa en dos componentes clave: la recopilación de todos los datos disponibles y su análisis automático. Complementado con visualización funcional y una política de apertura de datos, este enfoque nos permite resolver muchos de los problemas que antes eran callejones sin salida.
Recopila todos los datos disponibles.
La clave para una respuesta rápida a la situación es la imagen completa de lo que sucede dentro del centro de datos a nivel de red. FabricInsight utiliza un mecanismo de suscripción de telemetría push para recopilar todos los datos de servicio de segundo nivel de manera oportuna y sin muestreo. Para obtener una imagen completa de la red, se recopilan datos sobre el funcionamiento de los dispositivos, las aplicaciones y el paso del tráfico de la red (paquetes TCP SYN, FIN y RST): ERSPAN es compatible para duplicar paquetes sin usar la CPU del dispositivo y el GRPC de Google para informar el rendimiento de los dispositivos mismos.
Los datos recopilados a través de FabricInsight LEAF se transmiten al FabricInsight Collector, que monitorea los parámetros temporales del paquete que pasa a través de la red. Collector proporciona datos de tráfico de red con marcas de tiempo, codificaciones y envíos a través de HTTP a FabricInsight Analyzer. Este enfoque le permite recopilar la máxima información sobre la red, capturando incluso ráfagas de tráfico a corto plazo que no pueden ser detectadas por soluciones "clásicas".
Al mismo tiempo, FabricInsight no mira dentro de los paquetes IP (no captura su contenido), utilizando solo encabezados en su trabajo. Por lo tanto, se puede usar en áreas críticas para los negocios, por ejemplo, donde hay trabajo con datos personales.
Análisis en tiempo real
El segundo elemento integral del sistema es el analizador FabricInsight. Al recibir los datos recopilados, identifica las rutas de tráfico y ejecuta algoritmos que analizan la situación en tiempo casi real. En general, FabricInsight Analyzer correlaciona el tráfico de red con las aplicaciones, lo que le permite identificar y solucionar problemas rápidamente. Debido al aprendizaje automático, los algoritmos están "capacitados" para identificar el comportamiento normal y anormal de la infraestructura.
NetworkInsight refleja los resultados del análisis de red en su interfaz en forma de mapas de estado de red, interacciones de aplicaciones, análisis para aplicaciones individuales, etc., actualizados en tiempo real. La interfaz se implementa de tal manera que relaciona visualmente el nivel de aplicaciones y dispositivos físicos específicos responsables de la operatividad de la red, lo que acelera la resolución de problemas y los métodos para resolverlos.
Si se detectan anomalías, la información inicial se guarda automáticamente, de acuerdo con los problemas que se han identificado (la duración del almacenamiento es ajustable), si es necesario, FabricInsight advierte al usuario. Además, se inicializan los procedimientos para corregir la situación "con un clic con el mouse" a través de la interfaz gráfica. Al mismo tiempo, se analizan varios patrones de corrección de errores para encontrar el enfoque más relevante.
Casos
Para identificar las anomalías del centro de datos, se utiliza un análisis de correlación del funcionamiento de las aplicaciones, dispositivos y rutas de tráfico, por lo que se registran varios tipos de anomalías, tanto temporales como a largo plazo.

Por cierto, la mayoría de las anomalías temporales mencionadas anteriormente no se pueden solucionar con el enfoque clásico. Esto también se aplica a algunas anomalías a largo plazo. Un ejemplo bastante común es una actualización de software "torcida". Supongamos que una determinada aplicación funciona en el centro de datos que genera cierto tráfico. Después de actualizarlo, el volumen de este tráfico ha cambiado drásticamente, por ejemplo, el rendimiento de la aplicación ha disminuido, los retrasos han aumentado. FabricInsight corregirá esta anomalía.
Otro ejemplo es la degradación gradual del módulo de comunicación óptica (pérdida de rendimiento), que precede a la falla. La degradación determina la inestabilidad de la transmisión, que durante largos períodos de tiempo puede indicar la necesidad de un reemplazo temprano del equipo. Pero identificar esto con un enfoque estándar es extremadamente difícil.

Como respuesta a este problema, la interfaz FabricInsight muestra los estados de todos los módulos ópticos en el sistema junto con una estimación de la probabilidad de falla.

Integración
Aunque FabricInsight apareció en el mercado ruso en enero de este año, ya se ha implementado en ICBC, China UnionPay, China Merchants Bank, PICC y otros grandes centros de datos basados en la infraestructura de Huawei.
Hasta ahora, la solución solo es compatible con nuestros conmutadores (en los conjuntos de chips Broadcom), pero en el futuro se planea ir más allá del ecosistema de un fabricante. Además, cuando trabajamos en FabricInsight, inicialmente nos enfocamos en estándares abiertos para poder hacer amigos con herramientas de terceros normalmente. Por ejemplo, Druid se puede usar para exportar datos desde FabricInsight, a través del cual puede enviar información a visualizadores de terceros. FabricInsight también está integrado con la herramienta de renderizado abierto de Grafana.
En general, las herramientas de AIOps como nuestro FabricInsight son una forma lógica de desarrollar herramientas de monitoreo y mantenimiento de infraestructura. Nos parece que esta es la única forma de continuar cumpliendo con SLA para servicios.