Hola Habr!
Mi nombre es Anton Markelov, soy ingeniero de operaciones en United Traders. Estamos involucrados en proyectos de una forma u otra relacionados con inversiones, intercambios y otros asuntos financieros. No somos una empresa muy grande, unos 30 ingenieros de desarrollo, las escalas son apropiadas, un poco menos de cien servidores. Durante el crecimiento cuantitativo y cualitativo de nuestra infraestructura, la solución clásica "mantenemos tanto la aplicación como su base de datos en el mismo servidor" dejó de satisfacernos tanto en términos de confiabilidad como de velocidad. Por parte de los analistas, era necesario crear consultas entre bases de datos, el departamento de operaciones estaba cansado de perder el tiempo haciendo copias de seguridad y monitoreando una gran cantidad de servidores de bases de datos. Además de eso, almacenar el estado en la misma máquina que la aplicación en sí misma redujo en gran medida la flexibilidad de la planificación de recursos y la resistencia de la infraestructura.
El proceso de transición a la arquitectura actual fue evolutivo, se probaron varias soluciones para proporcionar una interfaz conveniente para desarrolladores y analistas, y para aumentar la confiabilidad y la capacidad de administración de toda esta economía. Quiero hablar sobre las principales etapas de la modernización de nuestro DBMS, a qué nivel hemos llegado y qué decisiones hemos tomado, como resultado, un entorno independiente tolerante a fallas que proporciona formas convenientes de interacción para ingenieros de operaciones, desarrolladores y analistas. Espero que nuestra experiencia sea útil para los ingenieros de empresas de nuestra escala.
Este artículo es un resumen de mi
informe en la conferencia UPTIMEDAY, quizás el formato de video sea más cómodo para alguien, aunque el escritor es un poco mejor con mis manos que un orador.
El "Hombre del copo de nieve" con KDPV fue
prestado descaradamente de Maxim Dorofeev.
Enfermedades de crecimiento
Tenemos una arquitectura de microservicio, los servicios se escriben principalmente en Java o Kotlin utilizando el marco Spring. Al lado de cada microservicio hay una base PostgreSQL, todo está cubierto por nginx en la parte superior para proporcionar acceso. Un microservicio típico es una aplicación en Spring Boot que escribe sus datos en PostgreSQL (parte de las aplicaciones al mismo tiempo y en ClickHouse), se comunica con los vecinos a través de Kafka y tiene algunos puntos finales REST o GraphQL para comunicarse con el mundo exterior.
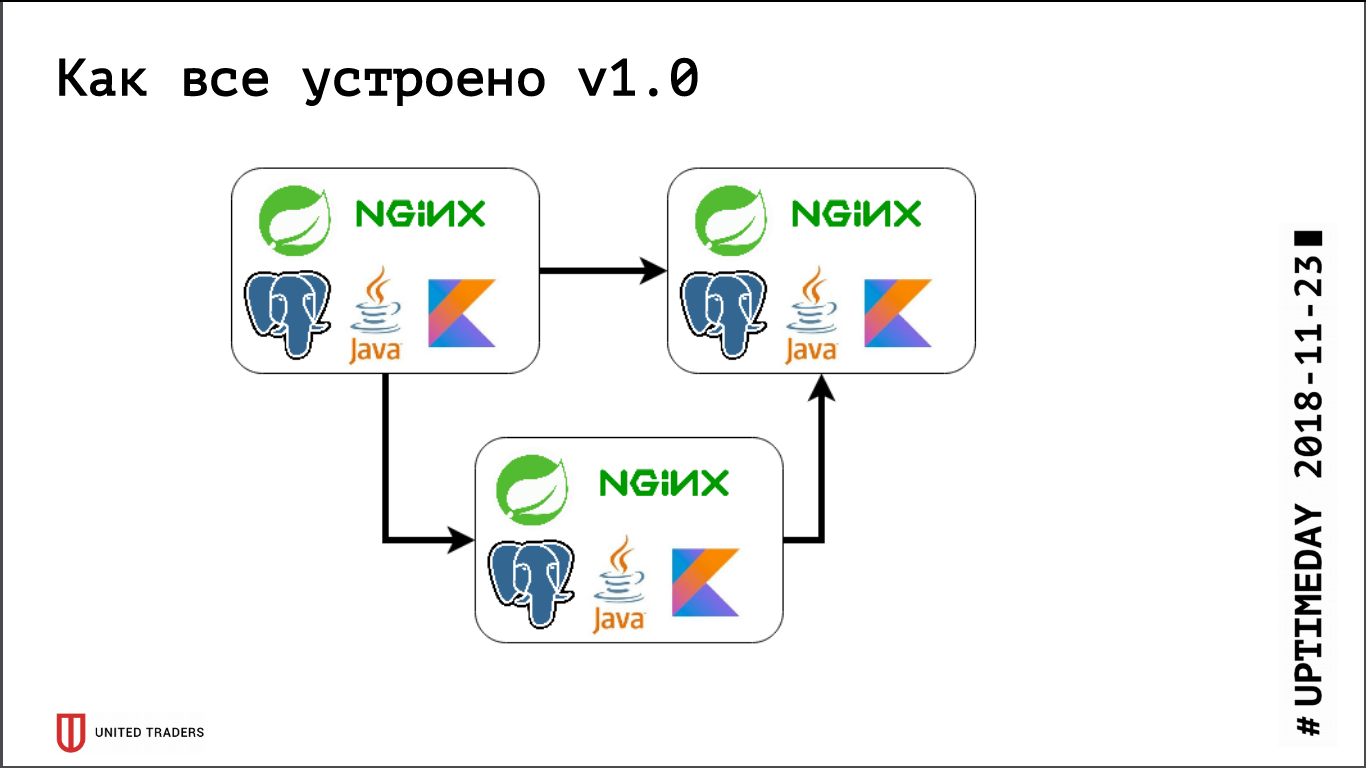
Anteriormente, cuando éramos muy pequeños, solo teníamos varios servidores en DigitalOcean, Kafka aún no estaba allí, toda la comunicación se realizó a través de REST. Es decir, tomamos una gotita, instalamos Java, PostgreSQL, nginx allí, lanzamos Zabbix allí para que monitoree los recursos del servidor y la disponibilidad de puntos finales de servicio. Implementaron todo con la ayuda de Ansible, teníamos libros de jugadas estandarizados, cuatro o cinco roles implementaron todo el servicio. Mientras tuviéramos, relativamente hablando, 6 servidores en producción y 3 en prueba, de alguna manera podrías vivir con él.
Luego comenzó la fase de desarrollo activo, el número de aplicaciones creció, diez microservicios se convirtieron en cuarenta, su funcionalidad comenzó a cambiar, además apareció la integración con sistemas externos como CRM, sitios de clientes y similares. Tenemos el primer dolor. Algunas aplicaciones comenzaron a consumir más recursos, dejaron de ingresar a los servidores existentes, obtuvimos gotitas, arrastramos aplicaciones de un lado a otro, tomamos muchas manos. Me dolió bastante, a nadie le gusta el estúpido trabajo mecánico, quería decidir rápidamente. Así que fuimos de frente: solo tomamos 3 servidores dedicados grandes en lugar de 10 gotas de nube. Esto cerró el problema por un tiempo, pero se hizo evidente que era hora de encontrar opciones para algún tipo de orquestación y reequilibrio del servidor. Comenzamos a analizar de cerca las soluciones como DC / OS y Kubernetes, y aumentamos gradualmente nuestra experiencia en esta área.
Casi al mismo tiempo, teníamos un departamento analítico, que necesitaba hacer solicitudes difíciles con regularidad, preparar informes, tener tableros hermosos, y esto nos trajo un segundo dolor. En primer lugar, los analistas cargaron mucho la base y, en segundo lugar, necesitaban consultas entre bases de datos, porque cada microservicio mantuvo un segmento de datos bastante estrecho. Probamos varios sistemas, al principio intentamos resolverlo todo a través de la replicación a nivel de tabla (estaba de vuelta en el noveno PostgreSQL, no había una réplica lógica lista para usar), pero las artesanías resultantes basadas en pglogical, Presto, Slony-I y Bucardo no lo hicieron por completo. arreglado Por ejemplo, pglogical no era compatible con la migración: se implementó una nueva versión del microservicio, la estructura de la base de datos cambió, Java cambió la estructura usando Flyway y en las réplicas en pglogical todo debe cambiarse manualmente. De lo contrario, faltaba algo o era demasiado difícil.
Súper esclavo
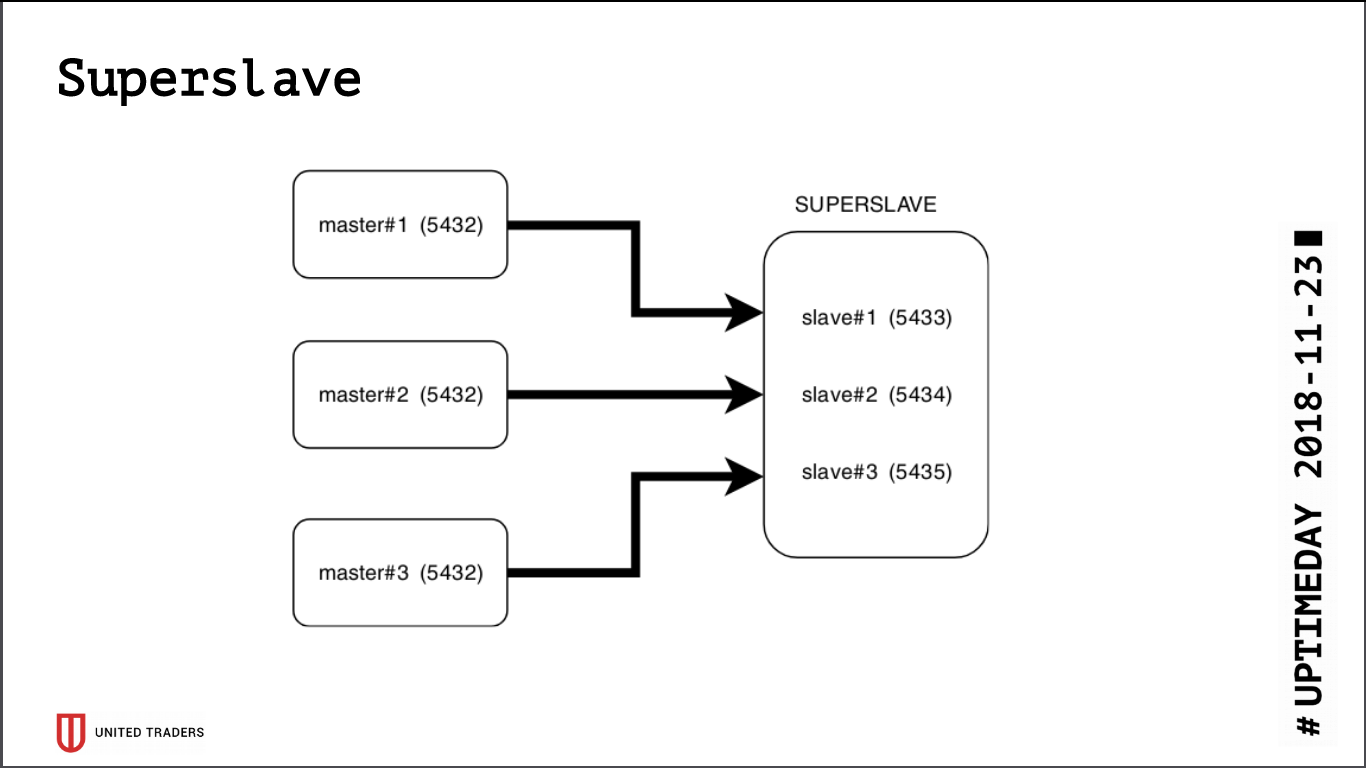
Como resultado de la investigación, nació una solución simple y brutal llamada Superslave: tomamos un servidor separado, configuramos un esclavo para cada servidor de producción en diferentes puertos y creamos una base de datos virtual que combina las bases de datos de los esclavos a través de postgres_fdw (contenedor de datos extranjeros). Es decir, todo esto se implementó por medios estándar de postgres sin introducir entidades adicionales, de manera simple y confiable: con una sola solicitud fue posible obtener datos de varias bases de datos. Dimos esta base cruzada virtual a los analistas. Una ventaja adicional es que la réplica de solo lectura, incluso con un error con derechos de acceso, no pudo escribir nada allí.
Llevamos a
Redash para visualización, sabe cómo dibujar gráficos, ejecutar solicitudes en un horario, por ejemplo, una vez al día, y tiene un sistema de derechos pesado, por lo que dejamos que los analistas y desarrolladores vayan allí.

Paralelamente, el crecimiento continuó, Kafka apareció en la infraestructura como un bus y ClickHouse para el almacenamiento de análisis. Se agrupan fácilmente fuera de la caja, nuestro súper esclavo contra su fondo parecía un fósil torpe. Además, PostgreSQL, de hecho, seguía siendo el único estado que tenía que arrastrarse después de la aplicación (si aún tenía que transferirse a otro servidor), y realmente queríamos obtener una aplicación sin estado para participar de cerca en experimentos con Kubernetes y él. plataformas similares
Comenzamos a buscar una solución que cumpla con los siguientes requisitos:
- tolerancia a fallas: cuando caen N servidores, el clúster continúa funcionando;
- para las aplicaciones, todo debe permanecer como antes, sin cambios en el código;
- facilidad de despliegue y gestión;
- menos capas de abstracción sobre PostgreSQL regular;
- idealmente, balanceo de carga para que no todas las solicitudes vayan a un servidor;
- Idealmente, está escrito en un lenguaje familiar.
No había muchos candidatos:
- replicación de transmisión estándar (repmgr, Patroni, Stolon);
- replicación basada en disparador (Londiste, Slony);
- replicación de consultas de capa media (pgpool-II);
- replicación sincrónica con múltiples servidores centrales (Bucardo).
En gran parte, ya tuvimos malas experiencias durante la construcción de la base cruzada, por lo que Patroni y Stolon se quedaron. Patroni está escrito en Python, Stolon in Go, tenemos suficiente experiencia en ambos idiomas. Además, tienen una arquitectura y funcionalidad similares, por lo que la elección se hizo por razones subjetivas: Patroni fue desarrollado por Zalando, y una vez intentamos trabajar con su proyecto Nakadi (REST API para Kafka), donde encontramos una grave falta de documentación.
Estolón
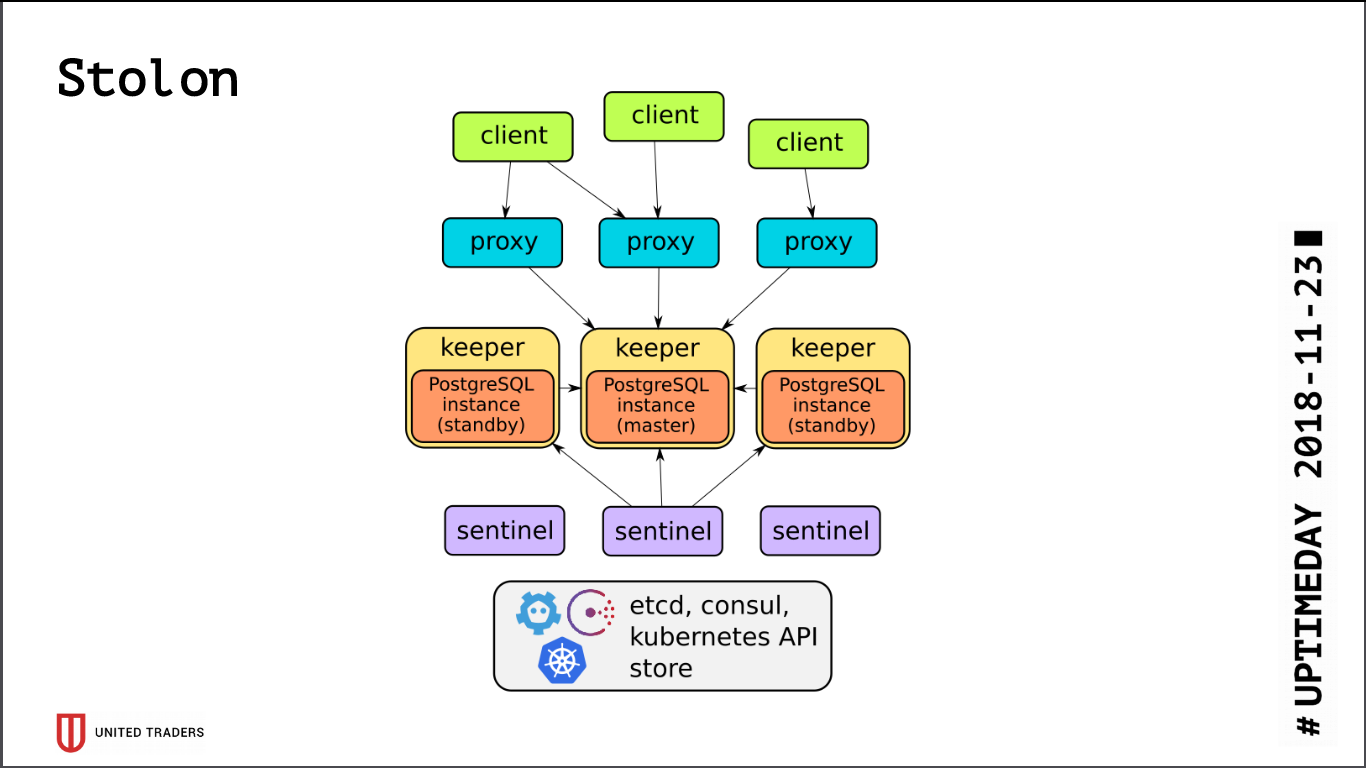
La arquitectura de
Stolon es bastante simple: hay N servidores, el líder se selecciona usando etcd / consul, PostgreSQL se inicia en modo asistente y se replica a otros servidores. Luego, los proxies stolon van a este PostgreSQL-master, pretendiendo ser aplicaciones con postgres ordinarios, y los clientes van a estos proxies. En caso de desaparición de un maestro, se realizan reelecciones, alguien más se convierte en maestro, el resto se convierte en stand-by. Hay pocas capas de abstracción, PostgreSQL se instala como de costumbre, la única advertencia es que la configuración de PostgreSQL se almacena en etcd, y se configura de manera algo diferente.
Al probar el clúster, detectamos bastantes problemas:
- Stolon no sabe cómo trabajar sobre ZooKeeper, solo cónsul o etcd;
- etcd es muy sensible a IO. Si mantiene PostgreSQL y etcd en el mismo servidor, definitivamente necesita SSD rápidos;
- incluso en SSD es necesario configurar tiempos de espera de etcd, de lo contrario todo se romperá bajo carga: el clúster pensará que el maestro se ha caído y romperá las conexiones constantemente;
- De forma predeterminada, max_ connections en PostgreSQL es pequeño (200), debe aumentarlo según sus necesidades;
- un grupo de tres, etc. sobrevivirá a la muerte de un solo servidor, idealmente debe tener una configuración, por ejemplo, 5 etcd + 3 Stolon;
- fuera de la caja, todas las conexiones van al maestro, los esclavos no son accesibles para la conexión.
Dado que todas las conexiones a PostgreSQL van al asistente, nuevamente nos encontramos con un problema con solicitudes de análisis pesadas. etcd a veces reaccionó dolorosamente a la alta carga en el maestro y lo cambió. Y cambiar al asistente siempre es romper las conexiones. La solicitud se reinició, todo comenzó de nuevo. Para una solución alternativa, se escribió
un script de Python que solicitó direcciones stolonctl de esclavos vivos y generó una configuración para HAProxy, redirigiendo las solicitudes a ellos.
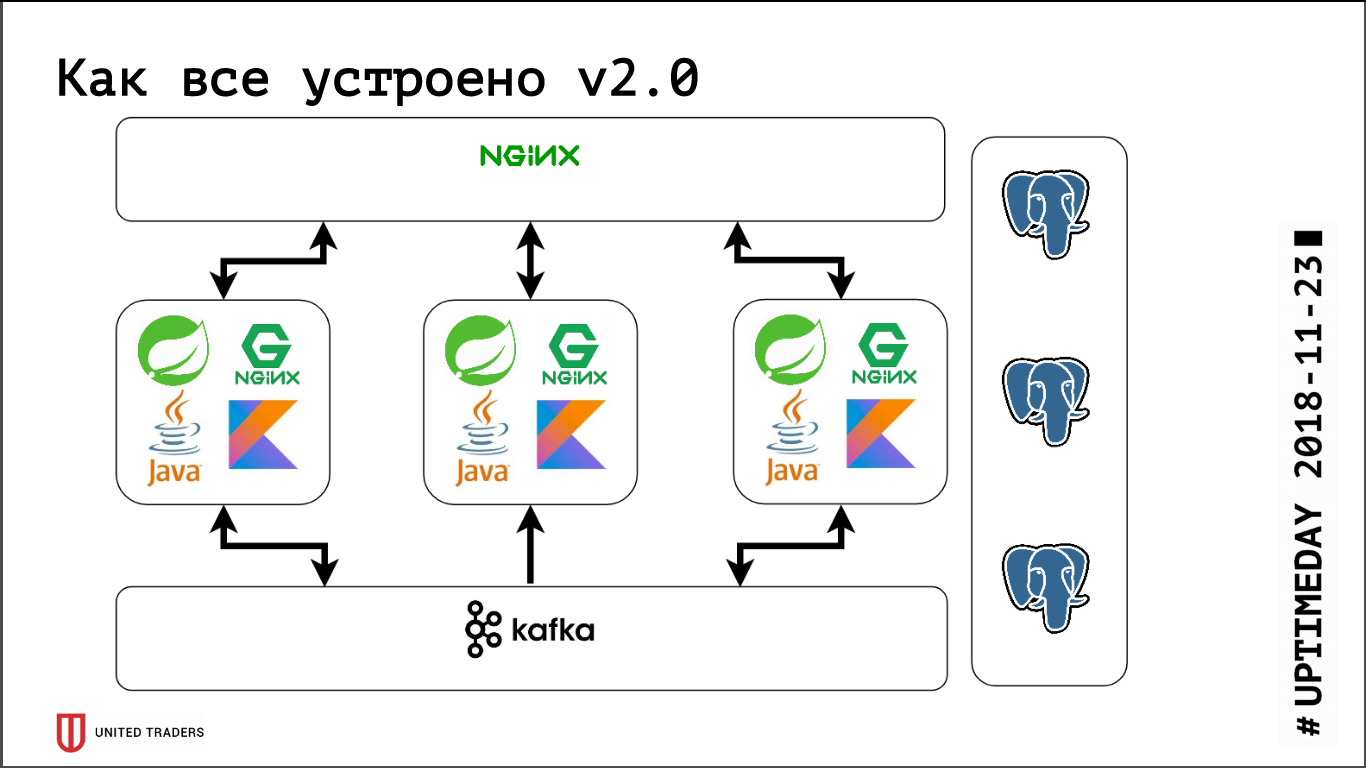
Resultó la siguiente imagen: las solicitudes de las aplicaciones van al puerto stolon-proxy, que las redirige al maestro, y las solicitudes de los analistas (siempre son de solo lectura) van al puerto HAProxy, que las transfiere a algún esclavo.
Además, literalmente hoy, se adoptó un RP en Stolon, que permitió enviar información sobre instancias de Stolon a un descubrimiento de servicios de terceros.
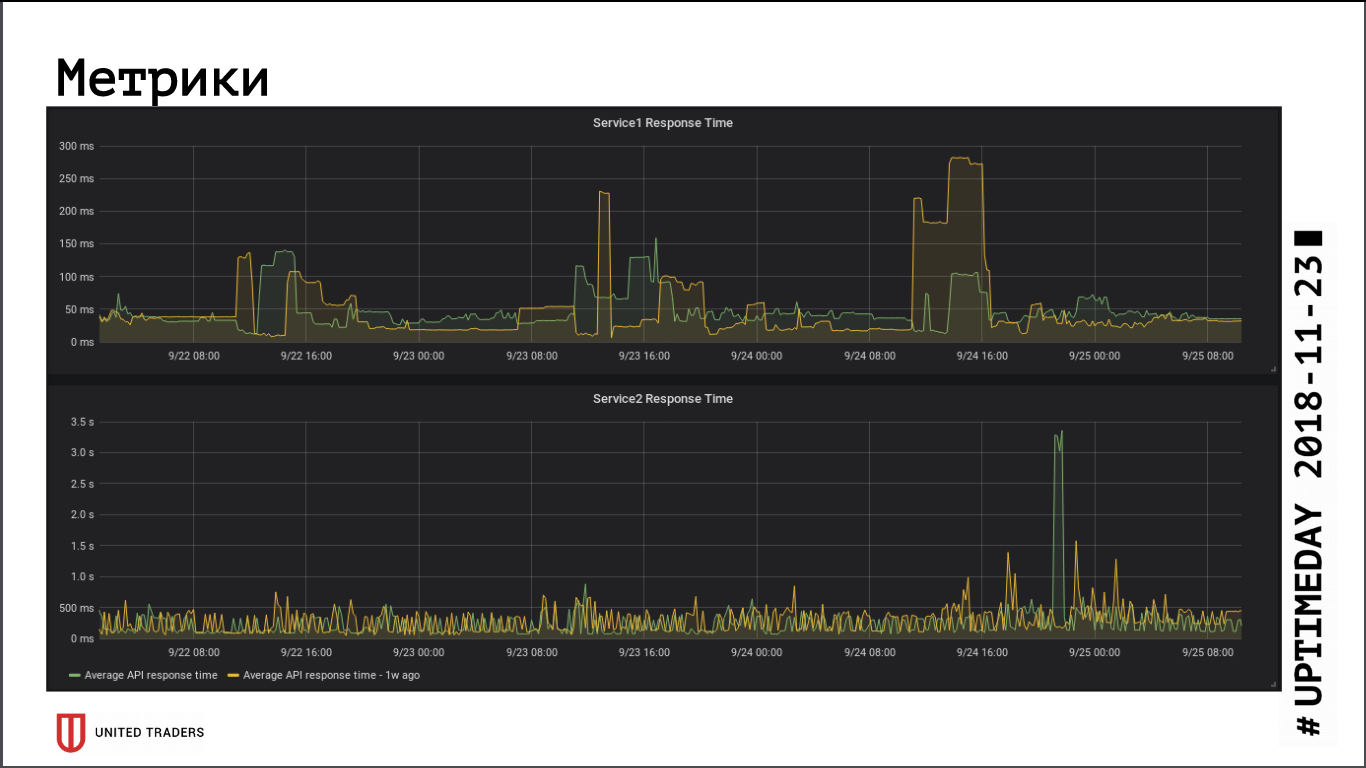
En cuanto a juzgar por las métricas de velocidad de respuesta de la aplicación, la transición a un clúster remoto no tuvo un impacto significativo en el rendimiento, el tiempo de respuesta promedio no ha cambiado. La latencia de red resultante, aparentemente, fue compensada por el hecho de que la base de datos ahora está en un servidor dedicado.
Stolon sin problemas sobrevive a un bloqueo del asistente (pérdida de servidor, pérdida de red, pérdida de disco), cuando el servidor cobra vida: restablece automáticamente la réplica. El punto más débil en Stolon es etcd, las fallas en él ponen el clúster. Tuvimos un accidente típico: un grupo de tres nodos, etc., dos fueron cortados. Todo, el quórum se rompió, etcd entró en estado no saludable, el clúster Stolon no acepta ninguna conexión, incluidas las solicitudes de stolonctl. Esquema de recuperación: convierta etcd en el servidor sobreviviente en un clúster de nodo único, luego agregue los miembros nuevamente. Conclusión: para sobrevivir a la muerte de dos servidores, debe tener al menos 5 instancias, etc.
Monitoreo y captura de errores
Con el crecimiento de la infraestructura y la complejidad de los microservicios, quería recopilar más información sobre lo que está sucediendo dentro de la aplicación y la máquina Java. No pudimos adaptar Zabbix al nuevo entorno: es muy inconveniente en las condiciones de una infraestructura cambiante. Tuve que moler muletas a través de su API o subir con mis manos, lo que es aún peor. Su base de datos está mal adaptada a cargas pesadas, y en general es muy inconveniente poner todo esto en una base de datos relacional.
Como resultado, elegimos Prometheus para el monitoreo. Él tiene un actuador listo para usar para aplicaciones Spring para proporcionar métricas, para Kafka atornillaron a JMX Exporter, que también proporciona métricas de una manera cómoda. Aquellos exportadores que no se encontraron "en la caja", nos escribimos en Python, hay unos diez de ellos. Visualizamos a Grafana, recopilamos los registros con Graylog (ya que ahora es compatible con Beats).
Utilizamos
Sentry para recopilar errores. Escribe todo de forma estructurada, dibuja gráficos, muestra lo que sucedió con más frecuencia, con menos frecuencia. Por lo general, los desarrolladores van inmediatamente a Sentry inmediatamente después de la implementación, para ver si hay algún pico o si necesitan revertirlo urgentemente. Resulta detectar rápidamente los errores sin recoger los registros.
Eso es todo por ahora, si el formato de los artículos se adapta a los lectores, seguiremos hablando más sobre nuestra infraestructura, todavía hay mucha diversión: Kafka y soluciones analíticas para eventos que lo atraviesan, canal CI / CD para aplicaciones de Windows y aventuras con Openshift.