
Parte 1/3 aquí .
Parte 2/3 aquí .
Hola a todos! ¡Y aquí está la tercera parte de la guía de Kubernetes sobre metal desnudo! Prestaré atención al monitoreo del clúster y la recopilación de registros, también lanzaremos una aplicación de prueba para usar los componentes del clúster preconfigurados. Luego realizaremos varias pruebas de estrés y verificaremos la estabilidad de este esquema de clúster.
La herramienta más popular que ofrece la comunidad de Kubernetes para proporcionar una interfaz basada en la web y obtener estadísticas de clúster es el Panel de Kubernetes . De hecho, todavía está en desarrollo, pero incluso ahora puede proporcionar algunos datos adicionales para solucionar problemas de aplicaciones y administrar recursos de clúster.
El tema es en parte controvertido. ¿Es cierto que necesita algún tipo de interfaz web para administrar el clúster, o es suficiente para usar la herramienta de consola kubectl ? Bueno, a veces estas opciones se complementan entre sí.
Expandamos nuestro Panel de Kubernetes y veamos. Con una implementación estándar, este panel solo comenzará en la dirección del host local. Por lo tanto, debe usar el comando proxy kubectl para la expansión , pero todavía está disponible solo en su dispositivo de control kubectl local. No está mal desde el punto de vista de la seguridad, pero quiero tener acceso en el navegador, fuera del clúster, y estoy listo para asumir algunos riesgos (después de todo, se usa SSL con un token efectivo).
Para aplicar mi método, debe modificar ligeramente el archivo de implementación estándar en la sección de servicio. Para abrir este panel en una dirección abierta, utilizamos nuestro equilibrador de carga.
Ingresamos al sistema de la máquina con la utilidad kubectl configurada y creamos:
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
Luego corre:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
Bueno, como puede ver, nuestro BN agregó IP 192.168.0.240 para este servicio. Ahora intente abrir https://192.168.0.240 para ver el Panel de Kubernetes.
Hay 2 formas de obtener acceso: use el archivo admin.conf de nuestro nodo maestro, que usamos antes al configurar kubectl, o cree una cuenta de servicio especial con un token de seguridad.
Creemos un usuario administrador:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
Ahora necesita un token para ingresar al sistema:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
Copie el token y péguelo en el campo del token en la pantalla de inicio de sesión.
Después de ingresar al sistema, puede estudiar el clúster un poco más profundo: me gusta esta herramienta.
El siguiente paso hacia la profundización del sistema de monitoreo de nuestro clúster es instalar heapster .
Heapster le permite monitorear el clúster de contenedores y analizar el rendimiento de Kubernetes (versión v1.0.6 y superior). Ofrece plataformas apropiadas.
Esta herramienta ofrece estadísticas sobre el uso del clúster a través de la consola y también agrega más información sobre los recursos de nodo y hogar al Panel de Kubernetes.
Hay pocas dificultades para instalarlo en metal desnudo, y necesitaba realizar una investigación: por qué la herramienta no funciona en la versión original, pero encontré una solución.
Entonces, continuemos y respaldemos este complemento:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
Este es el archivo de implementación estándar más común de la comunidad Heapster, con solo una ligera diferencia: para que funcione en nuestro clúster, la línea " source = " en la implementación de heapster cambia de la siguiente manera:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
En esta descripción encontrará todas estas opciones. Cambié el puerto de Kubelet a 10250 y apagué la verificación del certificado SSL (había un pequeño problema con él).
También necesitamos agregar permisos para obtener estadísticas de nodo en el rol Heapster RBAC; agregue estas pocas líneas al final del rol:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
En resumen, su rol RBAC debería verse así:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
Ok, ahora ejecutemos el comando para asegurarnos de que la implementación del generador se haya iniciado correctamente.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
Bueno, si recibió algunos datos en la salida, entonces todo se hace correctamente. Volvamos a nuestra página de tablero y veamos los nuevos gráficos que ahora están disponibles.
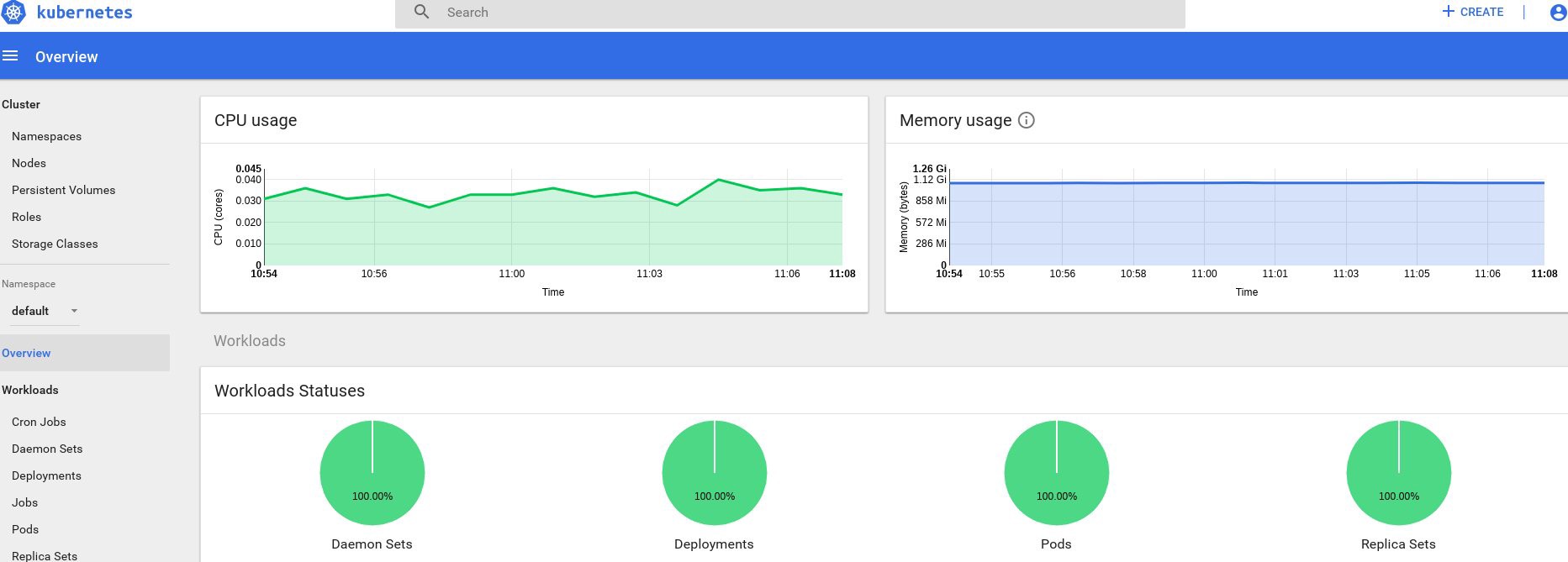

De ahora en adelante, también podemos rastrear el uso real de los recursos para nodos de clúster, hogares, etc.
Si esto no es suficiente, puede mejorar aún más las estadísticas agregando InfluxDB + Grafana. Esto agregará la capacidad de dibujar sus propios paneles Grafana.
Utilizaremos esta versión de la instalación de InfluxDB + Grafana desde la página Heapster Git, pero, como de costumbre, haremos las correcciones. Como ya habíamos configurado el despliegue de la fuente de alimentación, solo necesitamos agregar Grafana e InfluxDB, y luego modificar la implementación de la fuente de alimentación existente para que también ponga métricas en Influx.
Ok, creemos las implementaciones de InfluxDB y Grafana:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
El siguiente es Grafana, y no olvide cambiar la configuración del servicio para habilitar el equilibrador de carga MetaLB y obtener la dirección IP externa para el servicio Grafana.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
Y créalos:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
Es hora de cambiar la implementación del cargador y agregarle la conexión InfluxDB; necesitas agregar solo una línea:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
Edite la implementación del heapster:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Ahora encuentre la dirección IP externa del servicio Grafana e inicie sesión en el sistema que se encuentra dentro de él:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
Abra http://192.168.0.241 en un navegador, por primera vez use las credenciales admin / admin:

Cuando inicié sesión, mi Grafana estaba vacía, pero, afortunadamente, podemos obtener todos los paneles necesarios de grafana.com . Debe importar los paneles No. 3649 y 3646. Al importar, seleccione la fuente de datos correcta.
Después de eso, controle el uso de los recursos de nodos y hogares y, por supuesto, cree sus propios paneles únicos.
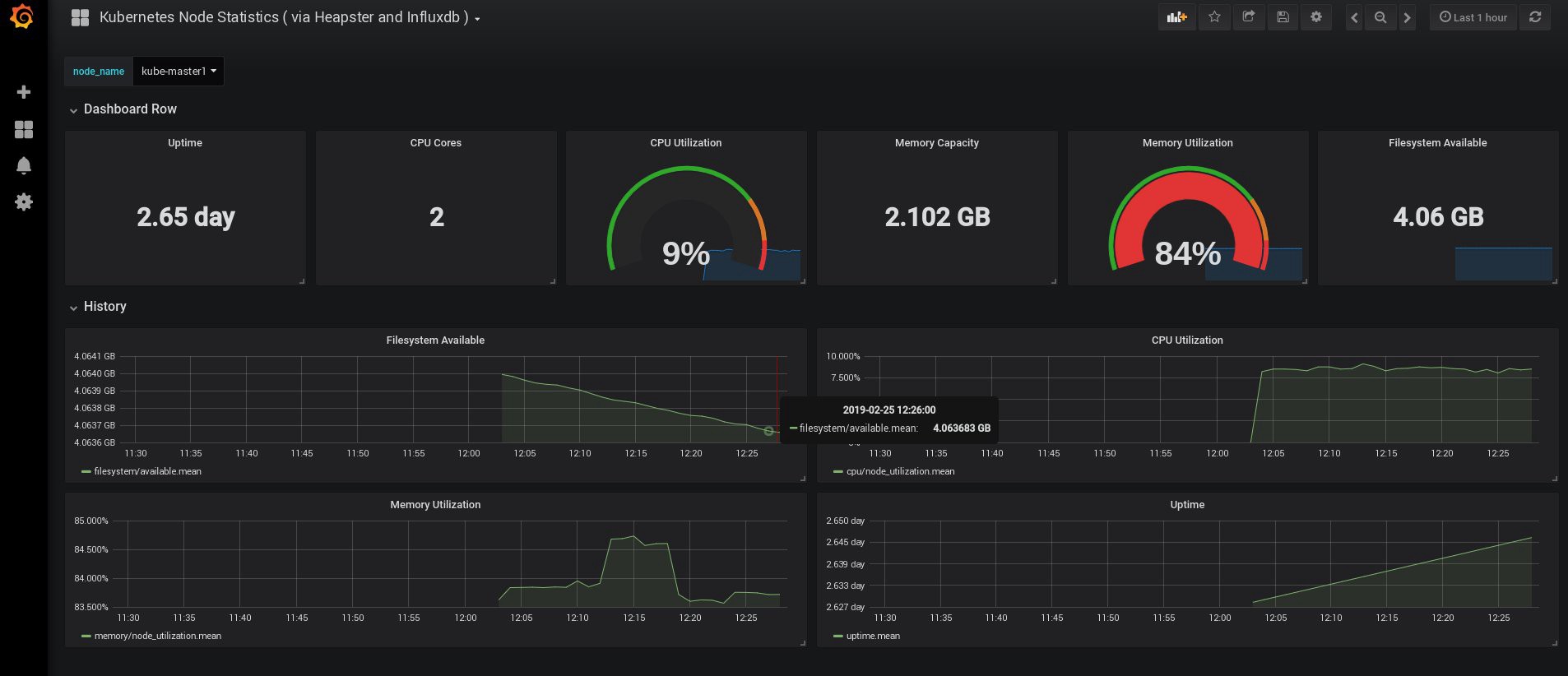
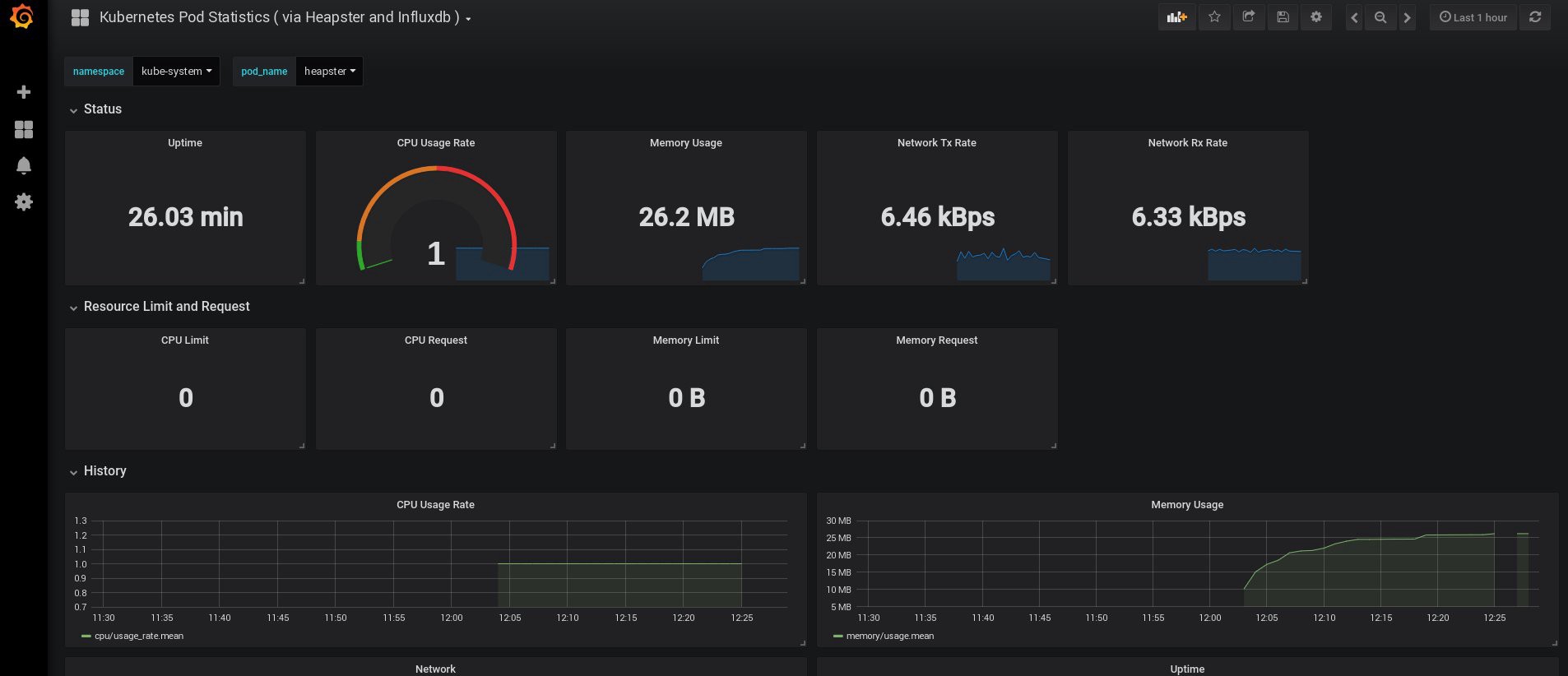
Bueno, por ahora, terminemos con el monitoreo; Los siguientes elementos que podemos necesitar son los registros para almacenar nuestras aplicaciones y el clúster. Hay varias formas de implementar esto, y todas se describen en la documentación de Kubernetes. Según mi propia experiencia, prefiero usar instalaciones externas de los servicios Elasticsearch y Kibana, así como solo agentes de registro que se ejecutan en cada nodo de trabajo de Kubernetes. Esto protegerá al clúster de sobrecargas asociadas con una gran cantidad de registros y otros problemas, y permitirá recibir registros, incluso si el clúster se vuelve completamente no funcional.
La pila de recopilación de registros más popular para los fanáticos de Kubernetes es Elasticsearch, Fluentd y Kibana (pila EFK). En este ejemplo, ejecutaremos Elasticsearch y Kibana en un nodo externo (puede usar la pila ELK existente), así como Fluentd dentro de nuestro clúster como conjunto de demonios para cada nodo como agente de recopilación de registros.
Me saltearé la parte sobre la creación de una VM con instalaciones Elasticsearch y Kibana; Este es un tema bastante popular, por lo que puede encontrar mucho material sobre la mejor manera de hacerlo. Por ejemplo, en mi artículo . Simplemente elimine el fragmento de configuración logstash del archivo docker-compose.yml , y también elimine 127.0.0.1 de la sección de puertos elasticsearch.
Después de eso, debe tener una búsqueda elástica de trabajo conectada al puerto VM-IP: 9200. Para mayor seguridad, configure login: pass o claves de seguridad entre fluentd y elasticsearch. Sin embargo, a menudo los protejo simplemente con las reglas de iptables.
Todo lo que queda por hacer es crear un conjunto de demonios fluido en Kubernetes y especificar el nodo elástico de búsqueda : dirección externa del puerto en la configuración.
Usamos el complemento oficial de Kubernetes con la configuración yaml desde aquí , con modificaciones menores:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
Luego haremos una configuración específica de fluentd:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
La configuración es elemental, pero es suficiente para un inicio rápido; recopilará registros del sistema y de la aplicación. Si necesita algo más complicado, puede consultar la documentación oficial sobre complementos fluidos y configuraciones de Kubernetes.
Ahora creemos un conjunto de demonios fluido en nuestro clúster:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
Asegúrese de que todos los módulos fluidos y otros recursos se estén ejecutando correctamente, luego abra Kibana. En Kibana, busque y agregue un nuevo índice de fluentd. Si encuentra algo, entonces todo se hace correctamente; de lo contrario, verifique los pasos anteriores y vuelva a crear el conjunto de demonios o edite el mapa de configuración:

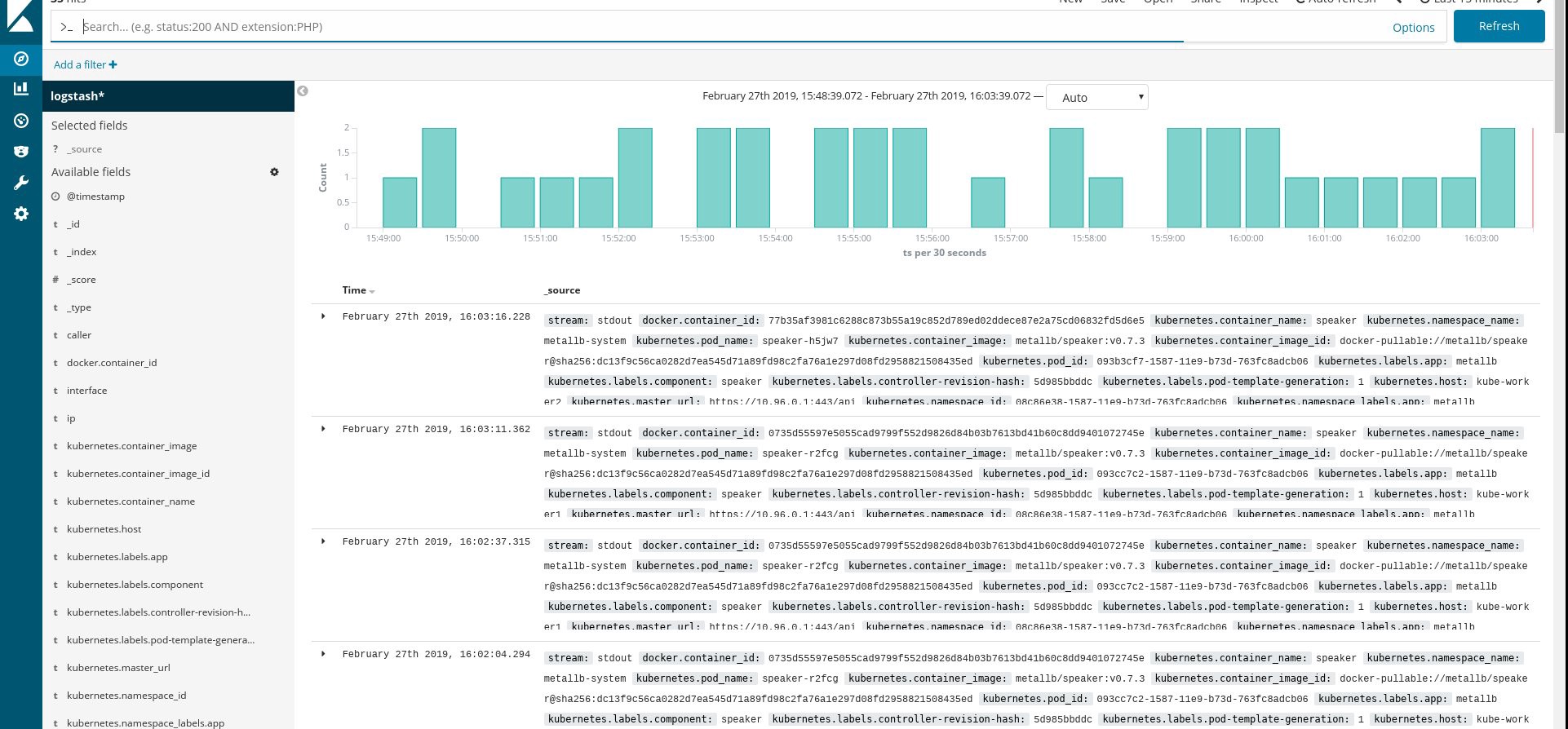
Bueno, ahora que obtenemos los registros del clúster, puede crear cualquier panel de control. Por supuesto, la configuración es la más simple, por lo que probablemente deba cambiarla usted mismo. El objetivo principal era mostrar cómo se hace esto.
Después de completar todos los pasos anteriores, obtuvimos un clúster de Kubernetes realmente bueno y listo para usar. Es hora de incrustar alguna aplicación de prueba y ver qué sucede.
Para este ejemplo, tome mi pequeña aplicación Python / Flask Kubyk, que ya tiene un contenedor Docker, así que tómela del registro abierto de Docker. Ahora agregaremos un archivo de base de datos externo a esta aplicación, para esto utilizaremos el almacenamiento GlusterFS configurado.
Primero, creamos un nuevo volumen de pvc para esta aplicación (solicitud de volumen permanente), donde almacenaremos la base de datos SQLite con credenciales de usuario. Puede usar la clase de memoria pre-creada de la parte 2 de esta guía.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
Habiendo creado un nuevo PVC para la aplicación, estamos listos para la implementación.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
Ahora creemos una implementación y servicio:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
Verifique la nueva dirección IP asignada al servicio, así como el estado del sub:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
Entonces, parece que hemos lanzado con éxito una nueva aplicación; Si abrimos la dirección IP http://192.168.0.242 en el navegador, deberíamos ver la página de inicio de sesión de esta aplicación. Puede usar las credenciales admin / admin para iniciar sesión, pero si intentamos iniciar sesión en esta etapa, obtendremos un error porque todavía no hay una base de datos disponible.
Aquí hay un ejemplo de un mensaje de error de registro del hogar en el panel de control de Kubernetes:
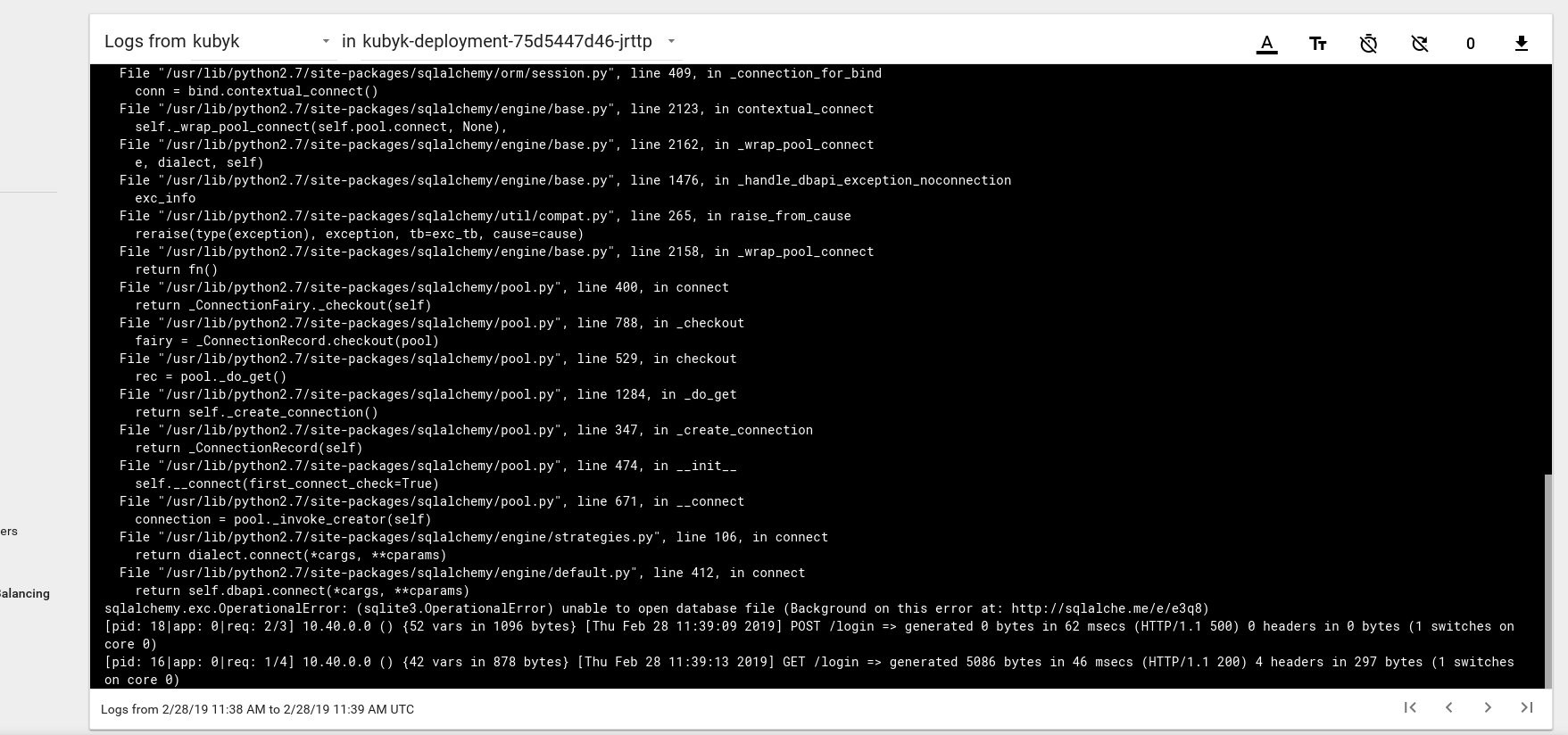
Para solucionar esto, debe copiar el archivo SQlite DB de mi repositorio de git al volumen de pvc creado anteriormente. La aplicación comenzará a usar esta base de datos.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
Usamos el under de la aplicación y el comando kubectl cp para copiar este archivo al volumen.
También debe dar acceso de escritura de usuario nginx a este directorio; mi aplicación se inicia a través del usuario nginx usando supervisord .
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
Intentemos iniciar sesión nuevamente:
Genial, ahora nuestra aplicación funciona correctamente, y podemos escalar el despliegue de kubyk a 3 réplicas, por ejemplo, para poner una copia de la aplicación en un nodo de trabajo. Como creamos previamente el volumen de pvc, todos nuestros pods con réplicas de aplicaciones usarán la misma base de datos, y el servicio distribuirá el tráfico entre las réplicas de manera cíclica.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
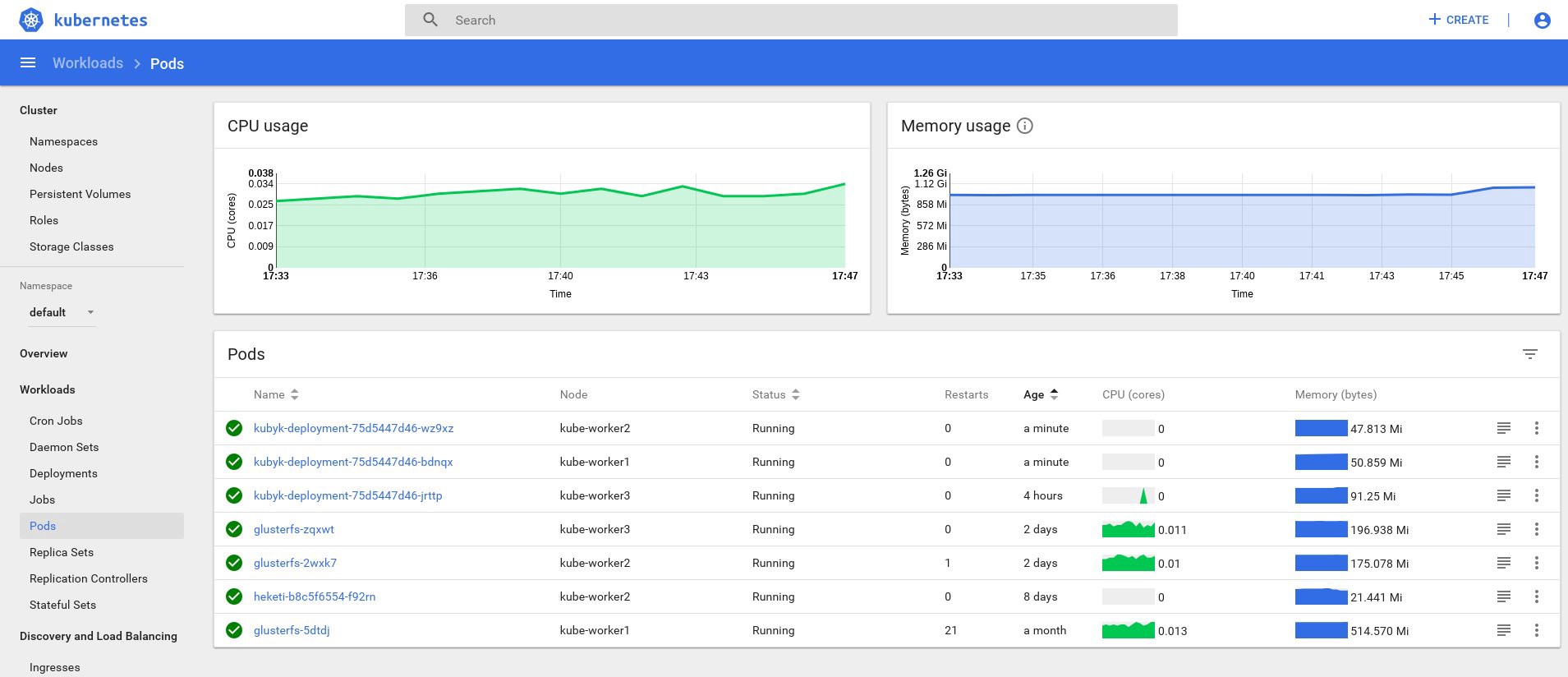
Ahora tenemos réplicas de aplicaciones para cada nodo de trabajo, por lo que la aplicación no dejará de funcionar si pierde nodos. Además, obtenemos una forma sencilla de equilibrar la carga, como dije anteriormente. No es un mal lugar para comenzar.
Creemos un nuevo usuario en nuestra aplicación:
Todas las solicitudes nuevas serán procesadas por el siguiente hogar en la lista. Esto puede ser verificado por los registros de los hogares. Por ejemplo, la aplicación crea un nuevo usuario en un sub, luego el siguiente sub responde a la siguiente solicitud, y así sucesivamente. Debido a que esta aplicación utiliza un único volumen persistente para almacenar la base de datos, todos los datos estarán seguros incluso si se pierden todas las réplicas.
En aplicaciones grandes y complejas, necesitará no solo un volumen designado para la base de datos, sino varios volúmenes para acomodar información persistente y muchos otros elementos.
Bueno, ya casi hemos terminado. Puede agregar muchos más aspectos, ya que Kubernetes es un tema voluminoso y dinámico, pero nos detendremos allí. El objetivo principal de esta serie de artículos era mostrar cómo crear su propio clúster de Kubernetes, y espero que esta información le haya sido útil.
PS
Pruebas de estabilidad y pruebas de estrés, por supuesto.
El diagrama de clúster de nuestro ejemplo funciona sin 2 nodos de trabajo, 1 nodos maestros y 1 nodos etcd. Si lo desea, deshabilítelos y verifique si la aplicación de prueba funcionará.
Al compilar estas guías, preparé un clúster de producción para un esquema casi similar. Una vez, después de haber creado un clúster y haber implementado una aplicación en él, me topé con un fallo de alimentación importante; absolutamente todos los servidores del clúster fueron cortados, una pesadilla animada del administrador del sistema. Algunos servidores se apagaron durante mucho tiempo y luego se produjeron errores en el sistema de archivos. Pero el relanzamiento me sorprendió mucho: el clúster de Kubernetes se recuperó por completo. Todos los volúmenes e implementaciones de GlusterFS fueron lanzados. Para mí, esta es una demostración del gran potencial de esta tecnología.
Todo lo mejor y, espero, nos vemos pronto!