
El código se usa para crear interfaces. Pero el código en sí es una interfaz.
A pesar del hecho de que la legibilidad del código es muy importante, este concepto está mal definido, y a menudo en forma de un conjunto de reglas: use nombres de variables significativos, divida las funciones grandes en otras más pequeñas y use patrones de diseño estándar.
Al mismo tiempo, seguro, todos tuvieron que lidiar con un código que cumple con estas reglas, pero por alguna razón es una especie de desastre.
Puede intentar resolver este problema agregando nuevas reglas: si los nombres de las variables se vuelven muy largos, necesita refactorizar la lógica principal; si se han acumulado muchos métodos auxiliares en una clase, tal vez debería dividirse en dos; Los patrones de diseño no pueden aplicarse en el contexto incorrecto.
Dichas instrucciones se convierten en un laberinto de decisiones subjetivas, y para navegarlo, necesitará un desarrollador que pueda tomar la decisión correcta, es decir, que ya debe ser capaz de escribir código legible.
Por lo tanto, un conjunto de instrucciones no es una opción. Por lo tanto, tendremos que formular una imagen más amplia de la legibilidad del código.
Por qué se necesita legibilidad
En la práctica, una buena legibilidad generalmente significa que el código es agradable de leer. Sin embargo, uno no puede llegar lejos en esa definición: en primer lugar, es subjetiva y, en segundo lugar, nos obliga a leer un texto ordinario.
Un código ilegible se percibe como una novela que pretende ser un código: muchos comentarios que revelan la esencia de lo que está sucediendo, hojas de texto que deben leerse secuencialmente, formulaciones inteligentes, cuyo único significado es ser "inteligente", miedo a reutilizar palabras. El desarrollador está tratando de hacer que el código sea legible, pero está apuntando al tipo incorrecto de lectores.
La legibilidad del texto y la legibilidad del código no son lo mismo.
Traducido a AlconostEl código se usa para crear interfaces. Pero el código en sí es una interfaz.
Si el código se ve hermoso, ¿significa que es legible? La estética es un agradable efecto secundario de la legibilidad, pero como criterio no es muy útil. Quizás en casos extremos, la estética del código en el proyecto ayudará a retener a los empleados, pero con el mismo éxito, puede ofrecer un buen paquete social. Además, todos tienen su propia idea de lo que significa "código hermoso". Y con el tiempo, esta definición de legibilidad se convierte en un torbellino de disputas sobre tabulación, espacios, corchetes, "notación de camello", etc. Es poco probable que alguien pierda la conciencia cuando vean la sangría incorrecta, aunque esto atrae la atención al verificar el código.
Si el código produce menos errores, ¿puede considerarse más legible? Cuantos menos errores, mejor, pero ¿qué mecanismo hay? ¿Cómo puedo atribuir las vagas sensaciones agradables que experimentas cuando lees el código? Además, no importa cuán fruncidas sean las cejas mientras lee el código, esto no agregará errores.
Si el código es fácil de editar, ¿es legible? Pero esta, quizás, es la dirección correcta del pensamiento. Los requisitos cambian, se agregan funciones, surgen errores, y en algún momento alguien tiene que editar su código. Y para no causar nuevos problemas, el desarrollador necesita comprender exactamente qué está editando y cómo los cambios cambiarán el comportamiento del código. Entonces, encontramos una nueva regla heurística: el código legible debería ser fácil de editar.
¿Qué código es más fácil de editar?
Inmediatamente quiero difuminar: "El código es más fácil de editar cuando los nombres de las variables se dan significativamente", pero simplemente cambiamos el nombre de "legibilidad" a "facilidad de edición". Necesitamos una comprensión más profunda, y no el mismo conjunto de reglas en una forma diferente.
Comencemos olvidando por un momento que estamos hablando de código. La programación, que tiene varias décadas de antigüedad, es solo un punto en la escala de la historia humana. Limitándonos a este "punto", no podemos profundizar.
Por lo tanto, veamos la legibilidad a través del prisma del diseño de interfaces que encontramos en casi todos los pasos, y no solo con las digitales. El juguete tiene una funcionalidad que lo hace andar o chirriar. La puerta tiene una interfaz que le permite abrirla, cerrarla y bloquearla. Los datos del libro se recopilan en páginas, lo que proporciona un acceso aleatorio más rápido que el desplazamiento. Al estudiar diseño, puede aprender mucho más sobre estas interfaces; pregunte al equipo de diseño si puede. En el caso general, todos preferimos buenas interfaces, incluso si no siempre sabemos qué las hace buenas.
El código se usa para crear interfaces. Pero el código en sí, combinado con el IDE, es una interfaz. Una interfaz diseñada para un grupo muy pequeño de usuarios: nuestros colegas. Además, los llamaremos "usuarios", para permanecer en el espacio de diseño de la interfaz de usuario.
Con esto en mente, considere estos ejemplos de rutas de usuario:
- El usuario quiere agregar una nueva función. Esto requiere encontrar el lugar correcto y agregar una función sin generar nuevos errores.
- El usuario quiere corregir el error. Necesitará encontrar la fuente del problema y editar el código para que el error desaparezca y no aparezcan nuevos errores.
- El usuario quiere asegurarse de que, en casos límite, el código se comporte de cierta manera. Necesitará encontrar un código específico, luego rastrear la lógica y simular lo que sucede.
Y así sucesivamente: la mayoría de los caminos siguen un patrón similar. Para no complicar las cosas, considere ejemplos específicos, pero no olvide que esta es una búsqueda de principios generales, no una lista de reglas.
Podemos suponer con seguridad que el usuario no podrá abrir inmediatamente la sección de código deseada. Esto también se aplica a sus propios proyectos de pasatiempos: incluso si la función la ha escrito usted, es muy fácil olvidar dónde se encuentra. Por lo tanto, el código debe ser tal que sea fácil encontrar el correcto en él.
Para implementar una búsqueda conveniente, necesitará un poco de optimización de motor de búsqueda; aquí es para nosotros que los nombres de variables significativas vienen al rescate. Si el usuario no puede encontrar la función, moviéndose a lo largo de la pila de llamadas desde un punto conocido, puede comenzar una búsqueda por palabras clave. Sin embargo, no puede incluir demasiadas palabras clave en los nombres. Al buscar por código, se busca el único punto de entrada, desde donde puede continuar trabajando más. Por lo tanto, el usuario debe ayudar a llegar a un lugar específico, y si se excede con las palabras clave, habrá demasiados resultados de búsqueda inútiles.
Si el usuario puede asegurarse de inmediato de que todo está correcto en un nivel particular de lógica, puede olvidar las capas anteriores de abstracción y liberar su mente para la siguiente.
También puede buscar usando la finalización automática: si tiene una idea general de a qué función desea llamar o qué enumeración usar, puede comenzar a escribir el nombre deseado y luego seleccionar la opción adecuada de la lista de finalización automática. Si la función está destinada solo a ciertos casos o si necesita leer cuidadosamente su implementación debido a las características de su uso, puede indicarlo dándole un nombre más auténtico: al desplazarse por la lista de autocompletado, el usuario evitará lo que parece complicado, a menos que, por supuesto, esté seguro que hace
Por lo tanto, es más probable que los nombres cortos y regulares se perciban como opciones predeterminadas, adecuadas para usuarios "casuales". No debería haber sorpresas en las funciones con tales nombres: no puede insertar setters en funciones que parecen simples getters, por la misma razón que el botón Ver en la interfaz no debería cambiar los datos del usuario.

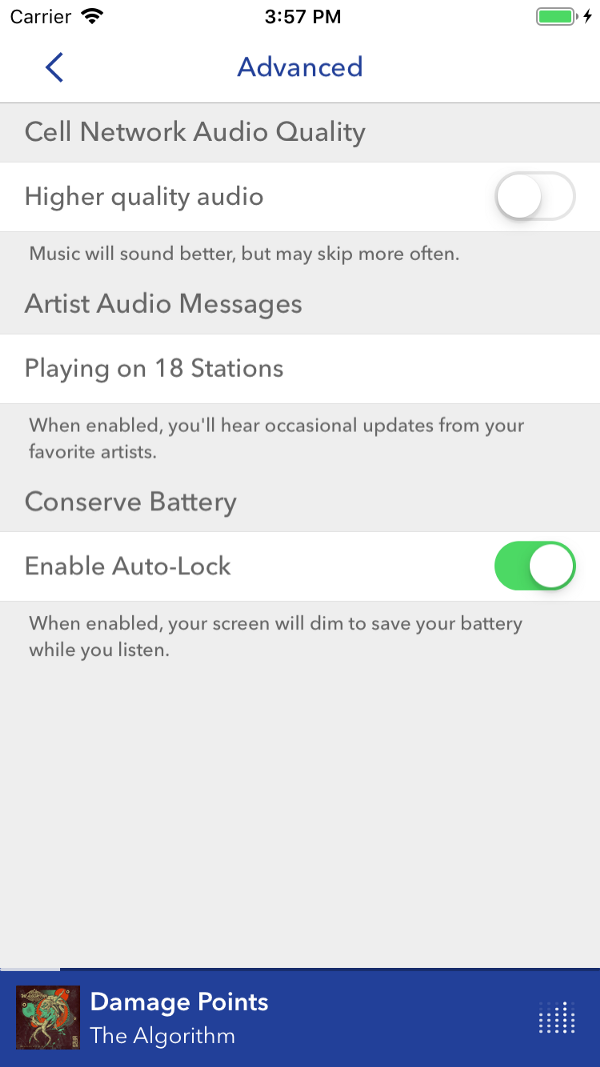 En la interfaz orientada al cliente, las funciones familiares, como una pausa, funcionan casi sin texto. A medida que la funcionalidad se vuelve más compleja, los nombres se alargan, lo que hace que los usuarios disminuyan la velocidad y piensen. Captura de pantalla - Pandora
En la interfaz orientada al cliente, las funciones familiares, como una pausa, funcionan casi sin texto. A medida que la funcionalidad se vuelve más compleja, los nombres se alargan, lo que hace que los usuarios disminuyan la velocidad y piensen. Captura de pantalla - PandoraLos usuarios desean encontrar la información correcta rápidamente. En la mayoría de los casos, la compilación lleva una cantidad considerable de tiempo, y en una aplicación en ejecución tendrá que verificar manualmente muchos casos de borde diferentes. Si es posible, nuestros usuarios preferirán leer el código y comprender cómo se comporta, en lugar de establecer puntos de interrupción y ejecutar el código.
Para hacerlo sin ejecutar el código, se deben cumplir dos condiciones:
- El usuario entiende lo que el código está tratando de hacer.
- El usuario está seguro de que el código hace lo que dice.
Las abstracciones ayudan a satisfacer la primera condición: los usuarios deberían poder sumergirse en capas de abstracción al nivel de detalle deseado. Imagine una interfaz de usuario jerárquica: en los primeros niveles, la navegación se lleva a cabo en secciones extensas, y luego se concreta cada vez más, hasta el nivel de lógica que debe estudiarse con más detalle.
La lectura secuencial de un archivo o método se realiza en tiempo lineal. Pero si el usuario puede subir y bajar las pilas de llamadas, esta es una búsqueda en el árbol, y si la jerarquía está bien equilibrada, esta acción se realiza en un tiempo logarítmico. Ciertamente hay espacio para listas en las interfaces, pero debe considerar cuidadosamente si debe haber más de dos o tres llamadas a métodos en algún contexto.
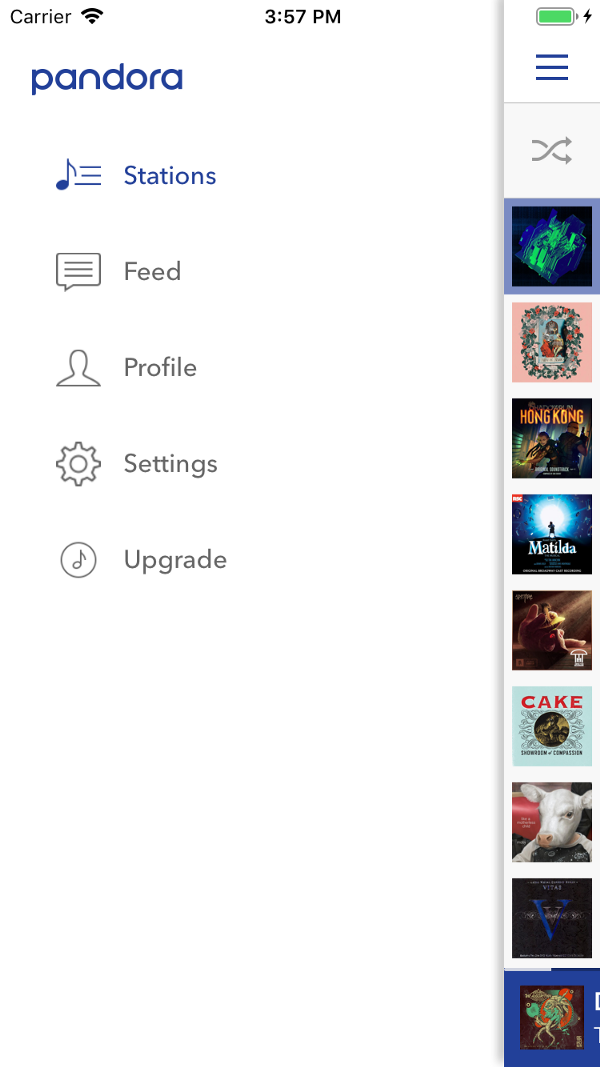
 En menús cortos, la navegación jerárquica es mucho más rápida. En el menú "largo" a la derecha, solo 11 líneas. ¿Con qué frecuencia encajamos en este número en el código del método? Captura de pantalla - Pandora
En menús cortos, la navegación jerárquica es mucho más rápida. En el menú "largo" a la derecha, solo 11 líneas. ¿Con qué frecuencia encajamos en este número en el código del método? Captura de pantalla - PandoraDiferentes usuarios tienen diferentes estrategias para la segunda condición. En situaciones de bajo riesgo, los comentarios o los nombres de los métodos son evidencia suficiente. En áreas más arriesgadas y complejas, así como cuando el código está sobrecargado con comentarios irrelevantes, es probable que estos últimos sean ignorados. A veces, incluso los nombres de métodos y variables estarán en duda. En tales casos, el usuario debe leer mucho más código y tener en cuenta un modelo lógico más amplio. Limitar el contexto a áreas pequeñas que son fáciles de mantener también ayudará aquí. Si el usuario puede verificar de inmediato que todo está correcto en un nivel particular de lógica, puede olvidar las capas anteriores de abstracción y liberar su mente para el siguiente.
En este modo de operación, los tokens individuales comienzan a tener mayor importancia. Por ejemplo, una bandera booleana
element.visible = true/false
es fácil de entender aisladamente del resto del código, pero esto requiere combinar dos tokens diferentes en la mente. Si utilizar
element.visibility = .visible/.hidden
entonces el valor de la bandera se puede entender de inmediato: en este caso, no es necesario leer el nombre de la variable para descubrir que está relacionado con la visibilidad. Vimos enfoques similares en el diseño de interfaces orientadas al cliente. En las últimas décadas, los botones Aceptar y Cancelar se han convertido en elementos de interfaz más descriptivos: "Guardar" y "Cancelar", "Enviar" y "Continuar editando", etc., para comprender lo que se hará, es suficiente para que el usuario vea las opciones propuestas sin leer todo el contexto.
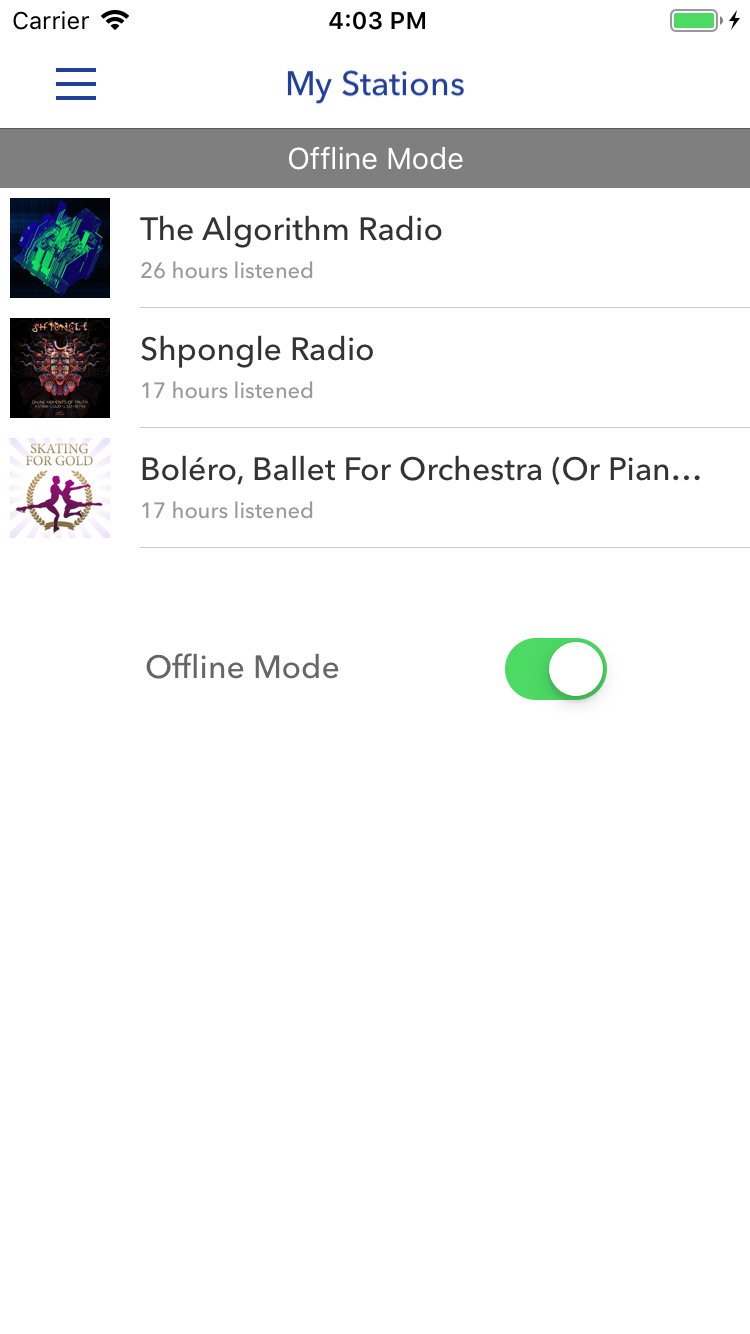 La línea "Modo sin conexión" en el ejemplo anterior indica que la aplicación está fuera de línea. El cambio en el ejemplo a continuación tiene el mismo significado, pero para entenderlo, debe mirar el contexto. Captura de pantalla - Pandora
La línea "Modo sin conexión" en el ejemplo anterior indica que la aplicación está fuera de línea. El cambio en el ejemplo a continuación tiene el mismo significado, pero para entenderlo, debe mirar el contexto. Captura de pantalla - PandoraLas pruebas unitarias también ayudan a confirmar el comportamiento esperado del código: actúan como comentarios, que, sin embargo, se puede confiar en mayor medida, ya que son más relevantes. Es cierto que también necesitan completar el ensamblaje. Pero en el caso de una canalización de CI bien establecida, las pruebas se ejecutan regularmente, por lo que puede omitir este paso al realizar cambios en el código existente.
En teoría, la seguridad se deriva de una comprensión suficiente: tan pronto como nuestro usuario comprenda el comportamiento del código, podrá realizar cambios de forma segura. En la práctica, debes considerar que los desarrolladores son personas comunes: nuestro cerebro usa los mismos trucos y también es perezoso. Por lo tanto, cuanto menos esfuerzo deba dedicar a comprender el código, más seguras serán nuestras acciones.
El código legible debería pasar la mayoría de las verificaciones de error a la computadora. Una de las formas de hacer esto es usar las comprobaciones de depuración "aserción", pero también requieren ensamblaje y arranque. Peor aún, si el usuario se ha olvidado de los casos límite, afirmar no ayudará. Las pruebas unitarias para verificar los casos fronterizos que se olvidan con frecuencia pueden mejorar, pero una vez que el usuario haya realizado cambios, tendrá que esperar a que se ejecuten las pruebas.
En resumen: el código legible debería ser fácil de usar. Y, como efecto secundario, puede verse hermoso.
Para acelerar el ciclo de desarrollo, utilizamos la función de verificación de errores integrada en el compilador. Por lo general, en tales casos, no se requiere un ensamblaje completo y los errores se muestran en tiempo real. ¿Cómo aprovechar esta oportunidad? En términos generales, debe encontrar situaciones en las que las comprobaciones del compilador se vuelven muy estrictas. Por ejemplo, la mayoría de los compiladores no observan cuán exhaustivamente se describe la declaración "if", sino que comprueban cuidadosamente el "interruptor" para ver si faltan condiciones. Si un usuario intenta agregar o cambiar una condición, será más seguro si todos los operadores similares anteriores fueran exhaustivos. Y cuando la condición de "caso" cambia, el compilador marcará todas las demás condiciones que deben verificarse.
Otro problema común de legibilidad es el uso de primitivas en expresiones condicionales. Este problema es especialmente grave cuando la aplicación analiza JSON, porque solo desea agregar declaraciones "if" alrededor de la cadena o la igualdad de enteros. Esto no solo aumenta la probabilidad de errores tipográficos, sino que también complica la tarea de los usuarios de determinar los posibles valores. Al verificar los casos límite, existe una gran diferencia entre cuándo es posible cualquier línea y cuándo, solo dos o tres opciones separadas. Incluso si las primitivas se fijan en constantes, debe darse prisa una vez, tratando de terminar el proyecto a tiempo, y aparecerá un valor arbitrario. Pero si usa objetos o enumeraciones especialmente creados, el compilador bloquea los argumentos no válidos y le da una lista específica de los válidos.
Del mismo modo, si algunas combinaciones de banderas booleanas no están permitidas, reemplácelas con una sola enumeración. Tomemos, por ejemplo, una composición que puede estar en los siguientes estados: está almacenada en búfer, completamente cargada y reproducida. Si imagina los estados de carga y reproducción como dos banderas booleanas
(loaded, playing)
el compilador permitirá la entrada de valores no válidos
(loaded: false, playing: true)
Y si usas la enumeración
(.buffering/.loaded/.playing)
entonces será imposible indicar un estado no válido. En la interfaz orientada al cliente, lo predeterminado debería ser prohibir combinaciones inválidas de configuraciones. Pero cuando escribimos código dentro de la aplicación, a menudo olvidamos brindarnos la misma protección.
 Las combinaciones no válidas se deshabilitan de antemano; los usuarios no necesitan pensar qué configuraciones son incompatibles. Captura de pantalla - Apple
Las combinaciones no válidas se deshabilitan de antemano; los usuarios no necesitan pensar qué configuraciones son incompatibles. Captura de pantalla - AppleSiguiendo las rutas de usuario consideradas, llegamos a las mismas reglas que al principio. Pero ahora tenemos un principio por el cual pueden formularse independientemente y cambiarse de acuerdo con la situación. Para hacer esto, nos preguntamos:
- ¿Será fácil para el usuario buscar el código deseado? ¿Los resultados de la búsqueda estarán saturados de funciones no relacionadas con la consulta?
- ¿Puede un usuario, habiendo encontrado el código necesario, verificar rápidamente la corrección de su comportamiento?
- ¿El entorno de desarrollo proporciona edición segura y reutilización de código?
En resumen: el código legible debería ser fácil de usar. Y, como efecto secundario, puede verse hermoso.
Nota
- Puede parecer que las variables booleanas son más convenientes para reutilizar, pero esta opción de reutilización implica intercambiabilidad. Tomemos, por ejemplo, los indicadores tappables y en caché , que representan conceptos ubicados en planos completamente diferentes: la capacidad de hacer clic en un elemento y el estado de almacenamiento en caché. Pero si ambas banderas son booleanas, puede intercambiarlas accidentalmente, obteniendo una expresión no trivial en una línea de código, lo que significará que el almacenamiento en caché está asociado con la capacidad de hacer clic en un elemento. Al usar enumeraciones, para formar tales relaciones, nos veremos obligados a crear una lógica explícita y verificable para la conversión de las "unidades de medida" que utilizamos.
Sobre el traductorEl artículo fue traducido por Alconost.
Alconost
localiza juegos ,
aplicaciones y sitios en 70 idiomas. Traductores nativos, pruebas lingüísticas, plataforma en la nube con API, localización continua, gerentes de proyecto 24/7, cualquier formato de recursos de cadena.
También hacemos
videos de publicidad y capacitación , para sitios que venden, imágenes, publicidad, capacitación, teasers, expliner, trailers de Google Play y App Store.
→
Leer más