Las redes neuronales convolucionales hacen un excelente trabajo al clasificar imágenes distorsionadas, a diferencia de los humanos.

En este artículo mostraré por qué las redes neuronales profundas avanzadas pueden reconocer perfectamente las imágenes distorsionadas y cómo esto ayuda a revelar la estrategia sorprendentemente simple utilizada por las redes neuronales para clasificar las fotografías naturales. Estos descubrimientos,
publicados en ICLR 2019, tienen muchas consecuencias: en primer lugar, demuestran que es mucho más fácil encontrar una solución "
ImageNet " de lo que se pensaba. En segundo lugar, nos ayudan a crear sistemas de clasificación de imágenes más interpretables y comprensibles. En tercer lugar, explican varios fenómenos observados en las redes neuronales convolucionales modernas (SNA), por ejemplo, su tendencia a buscar texturas (vea nuestro otro
trabajo en ICLR 2019 y la
entrada correspondiente del
blog ), e ignoran la disposición espacial de las partes del objeto.
Buenos viejos modelos "bolsa de palabras"
En los viejos tiempos, antes del advenimiento del aprendizaje profundo, el reconocimiento de imágenes naturales era bastante simple: definimos un conjunto de características visuales clave ("palabras"), determinamos con qué frecuencia cada característica visual ocurre en una imagen ("bolsa") y clasificamos la imagen en función de estos números Por lo tanto, dichos modelos en visión artificial se denominan "bolsa de palabras" (bolsa de palabras o BoW). Por ejemplo, supongamos que tenemos dos características visuales, el ojo humano y el lápiz, y queremos clasificar las imágenes en dos clases, "personas" y "pájaros". El modelo de BoW más simple sería este: por cada ojo encontrado en la imagen, aumentamos el testimonio a favor de la "persona" en 1. Y viceversa, para cada pluma aumentamos el testimonio a favor del "pájaro" en 1. Qué clase gana más evidencia, esta será.
Una propiedad conveniente de un modelo de BoW tan simple es la interpretabilidad y la claridad del proceso de toma de decisiones: podemos verificar con precisión qué características particulares de la imagen hablan a favor de una clase en particular, la integración espacial de características es muy simple (en comparación con la integración no lineal de características en redes neuronales profundas), por lo tanto solo entienda cómo el modelo toma sus decisiones.
Los modelos BoW tradicionales eran extremadamente populares y funcionaban muy bien antes de la invasión del aprendizaje profundo, pero rápidamente pasaron de moda debido a la eficiencia relativamente baja. Pero, ¿estamos seguros de que las redes neuronales utilizan una estrategia de decisión fundamentalmente diferente de BoW?
Red interpretada en profundidad con características de bolsa (BagNet)
Para probar esta suposición, combinamos la interpretabilidad y la claridad de los modelos BoW con la eficiencia de las redes neuronales. La estrategia se ve así:
- Divide la imagen en pedazos pequeños qx q.
- Pasamos las piezas a través de la red neuronal para obtener evidencia de pertenencia a la clase (logits) para cada pieza.
- Resuma la evidencia en todas las piezas para obtener una solución a nivel de toda la imagen.
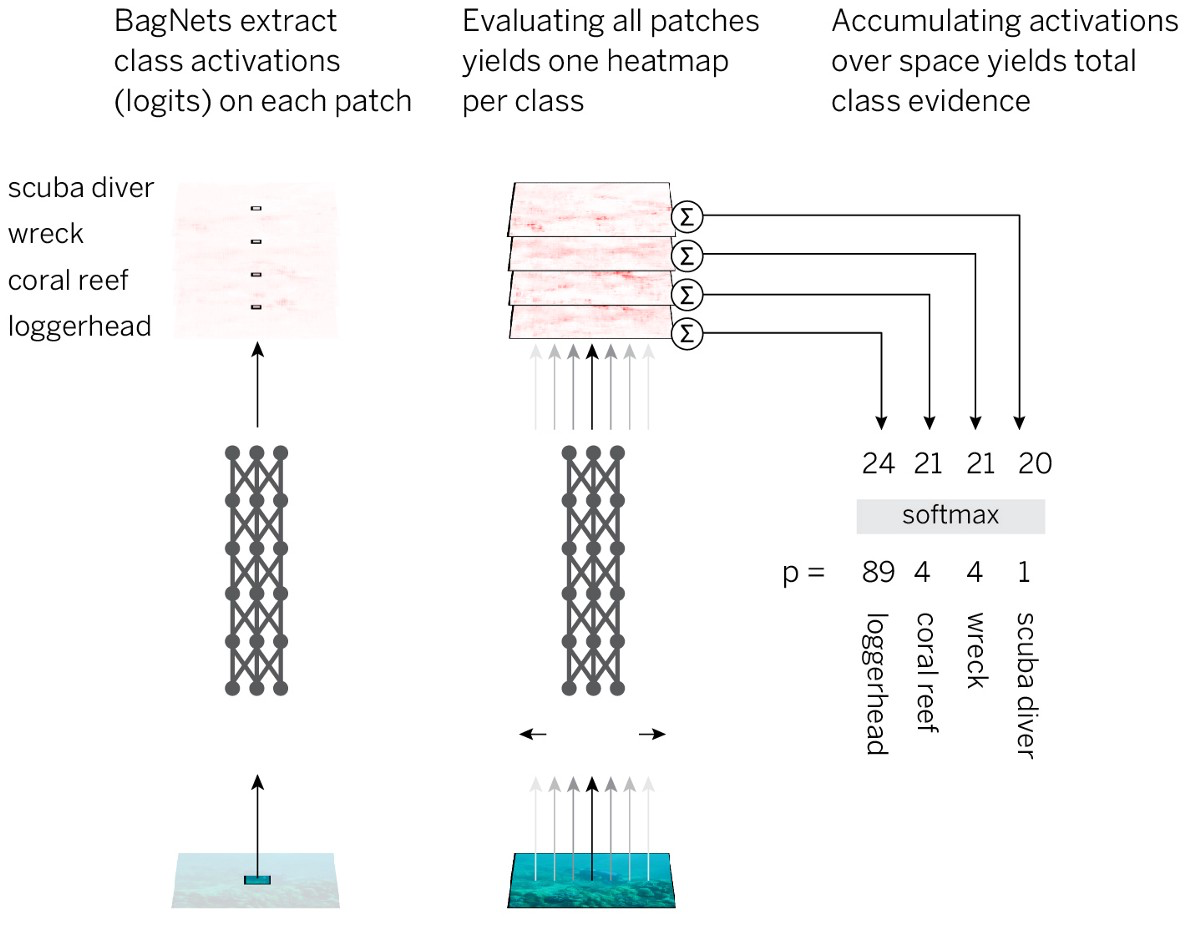
Para implementar esta estrategia, de la manera más simple, tomamos la arquitectura estándar ResNet-50 y reemplazamos casi todas las convoluciones de 3x3 con convoluciones de 1x1. Como resultado, cada elemento oculto en la última capa convolucional "ve" solo una pequeña parte de la imagen (es decir, su campo de percepción es mucho más pequeño que el tamaño de la imagen). Por lo tanto, evitamos el marcado impuesto de la imagen y lo más cerca posible del SNA estándar, mientras aplicamos una estrategia planificada previamente. Llamamos a la arquitectura resultante BagNet-q, donde q denota el tamaño del campo de percepción de la capa superior (probamos el modelo con q = 9, 17 y 33). BagNet-q corre aproximadamente 2.5 más tiempo que el ResNet-50.
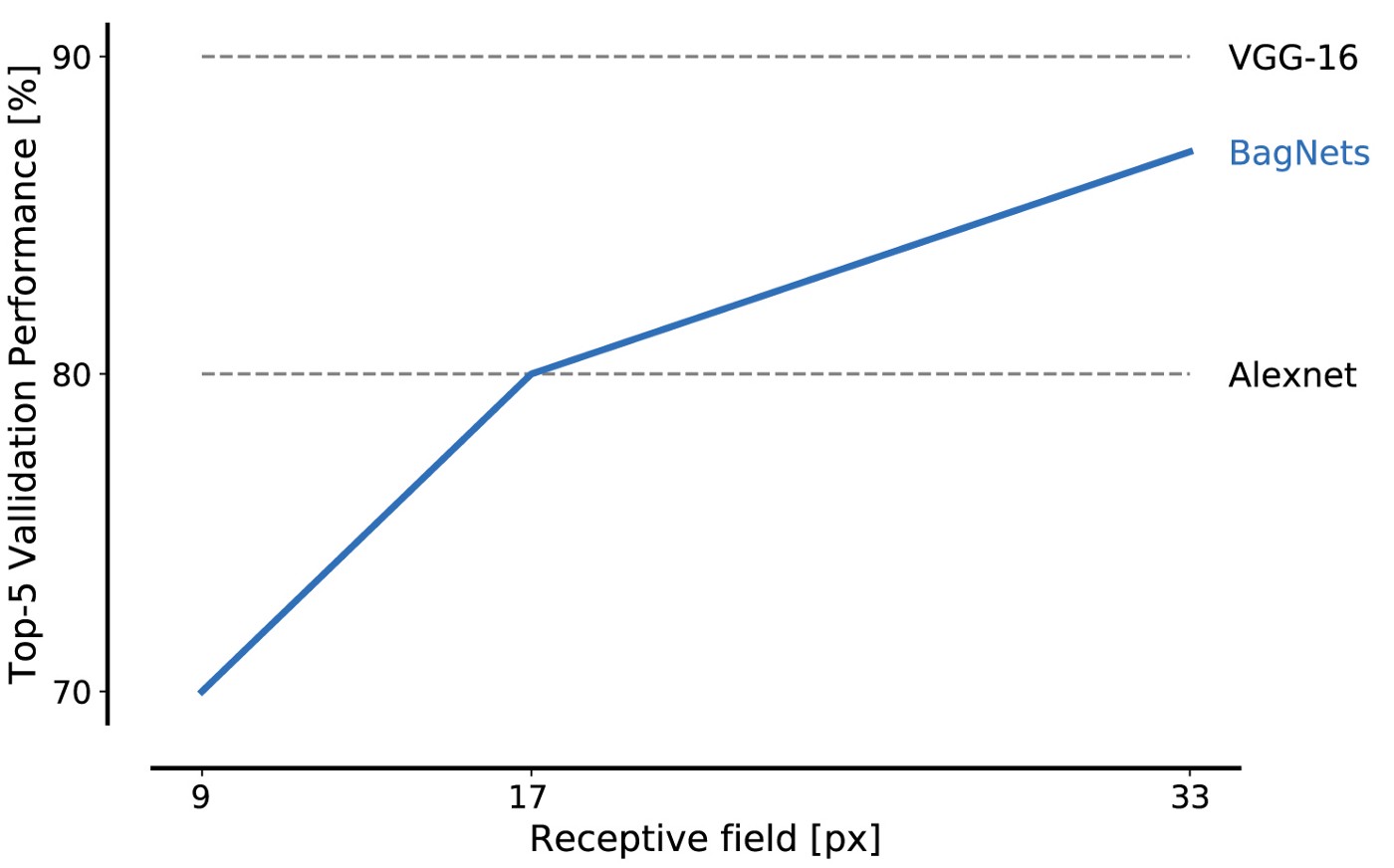
El rendimiento de BagNet en los datos de la base de datos ImageNet es impresionante incluso cuando se usan piezas pequeñas: los fragmentos de 17x17 píxeles son suficientes para lograr la eficiencia del nivel AlexNet, y los fragmentos de 33x33 píxeles son suficientes para lograr un 87% de precisión, ingresando en el top 5. Puede aumentar la eficiencia colocando los paquetes 3x3 con más cuidado y ajustando los hiperparámetros.
Este es nuestro primer resultado importante: ImageNet se puede resolver utilizando solo un conjunto de características de imagen pequeña. Las relaciones espaciales distantes de las partes de la composición, como la forma de los objetos o la interacción entre partes del objeto, pueden ignorarse por completo; no son absolutamente necesarios para resolver el problema.
Una característica notable de BagNet'ov es la transparencia de su sistema de toma de decisiones. Por ejemplo, puede averiguar qué características de las imágenes serán más características para una clase determinada. Por ejemplo, la tenca, un pez grande, generalmente se reconoce por la imagen de los dedos sobre un fondo verde. Por qué Porque en la mayoría de las fotos de esta categoría hay un pescador sosteniendo una tenca como su trofeo. Y cuando BagNet reconoce incorrectamente la imagen como una línea, esto generalmente ocurre porque en algún lugar de la foto hay dedos sobre un fondo verde.
 Las partes más características de las imágenes. La fila superior en cada celda corresponde al reconocimiento correcto, y la inferior a los fragmentos que distraen y que condujeron a un reconocimiento incorrecto.
Las partes más características de las imágenes. La fila superior en cada celda corresponde al reconocimiento correcto, y la inferior a los fragmentos que distraen y que condujeron a un reconocimiento incorrecto.También obtenemos el "mapa de calor" exacto, que muestra qué partes de la imagen contribuyeron a la decisión.
 Los mapas de calor no son una aproximación; muestran con precisión la contribución de cada parte de la imagen.
Los mapas de calor no son una aproximación; muestran con precisión la contribución de cada parte de la imagen.BagNet demuestra que puede obtener una alta precisión con ImageNet solo sobre la base de correlaciones estadísticas débiles entre las características locales de las imágenes y la categoría de los objetos. Si esto es suficiente, ¿por qué las redes neuronales estándar ResNet-50 aprenderían algo fundamentalmente diferente? ¿Por qué ResNet-50 debería estudiar relaciones complejas a gran escala, como la forma de un objeto, si la abundancia de características locales de la imagen es suficiente para resolver el problema?
Para probar la hipótesis de que los SNA modernos se adhieren a una estrategia similar al funcionamiento de las redes BoW más simples, probamos diferentes redes: ResNet, DenseNet y VGG en los siguientes "signos" de BagNet:
- Las soluciones son independientes de la combinación espacial de las características de la imagen (esto solo se puede verificar en los modelos VGG).
- Las modificaciones de diferentes partes de la imagen no deberían depender unas de otras (en el sentido de su influencia en la membresía de la clase).
- Los errores cometidos por SNA estándar y BagNet'ami deberían ser similares.
- El SNS estándar y BagNet deberían ser sensibles a características similares.
En los cuatro experimentos, encontramos comportamientos sorprendentemente similares de SNS y BagNet. Por ejemplo, en el último experimento, mostramos que BagNet es más sensible (si, por ejemplo, se superponen) a los mismos lugares en las imágenes que el SNA. De hecho, los mapas de calor BagNet (mapas de sensibilidad espacial) predicen mejor la sensibilidad de DenseNet-169 que los mapas de calor obtenidos por métodos de atribución como DeepLift (cálculo directo de mapas de calor para DenseNet-169). Por supuesto, el SCN no repite exactamente el comportamiento de BagNet, pero ciertas desviaciones demuestran. En particular, cuanto más profundas se vuelven las redes, mayores son los tamaños de las características y más se extienden las dependencias. Por lo tanto, las redes neuronales profundas son de hecho una mejora con respecto a los modelos BagNet, pero no creo que la base de su clasificación esté cambiando de alguna manera.
Ir más allá de la clasificación BoW
Observar la toma de decisiones del SCN al estilo de las estrategias de BoW puede explicar algunas de las características extrañas del SCN. En primer lugar, esto explica por qué el SNA está tan
ligado a las texturas . En segundo lugar, por qué el SNA no es sensible a
mezclar partes de la imagen. Esto incluso puede explicar la existencia de adhesivos adversos y perturbaciones adversas: se pueden colocar señales confusas en cualquier lugar de la imagen, y el SNS seguramente captará esta señal, independientemente de si se ajusta al resto de la imagen.
De hecho, nuestro trabajo muestra que el SCN, al reconocer imágenes, utiliza muchas leyes estadísticas débiles y no procede a integrar partes de la imagen a nivel de objetos, como lo hace la gente. Lo mismo es probablemente cierto para otras tareas y modalidades sensoriales.
Necesitamos planificar cuidadosamente nuestras arquitecturas, tareas y métodos de capacitación para superar la tendencia a usar correlaciones estadísticas débiles. Un enfoque es traducir la distorsión de la capacitación SNA de pequeñas características locales a otras más globales. El otro es eliminar o reemplazar aquellas características en las que la red neuronal no debe confiar, lo cual hicimos en otra
publicación para ICLR 2019, utilizando el preprocesamiento de transferencia de estilo para eliminar la textura de un objeto natural.
Sin embargo, uno de los mayores problemas sigue siendo la clasificación de las imágenes: si las características locales son suficientes, no hay incentivo para estudiar la verdadera "física" del mundo natural. Necesitamos reestructurar la tarea de tal manera que mueva modelos para estudiar la naturaleza física de los objetos. Para hacer esto, lo más probable es que tenga que ir más allá de la enseñanza puramente observacional a las correlaciones de los datos de entrada y salida para que los modelos puedan extraer relaciones causales.
Juntos, nuestros resultados sugieren que el SCN puede seguir una estrategia de clasificación extremadamente simple. El hecho de que tal descubrimiento se pueda hacer en 2019 enfatiza cuán poco entendemos las características internas del trabajo de las redes neuronales profundas. La falta de comprensión no nos permite desarrollar modelos y arquitecturas fundamentalmente mejoradas que cierren la brecha entre la percepción del hombre y la máquina. Profundizar nuestra comprensión nos permitirá descubrir formas de reducir esta brecha. Esto puede ser extremadamente útil: al tratar de cambiar el SNA hacia las propiedades físicas de los objetos, de repente logramos
resistencia al ruido a nivel humano. Espero la aparición de una gran cantidad de otros resultados interesantes en nuestro camino hacia el desarrollo del SCN, que realmente comprenden la naturaleza física y causal de nuestro mundo.