 Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArt
Publicado por Denis Tsyplakov , arquitecto de soluciones, DataArtCon los años, descubrí que los programadores repiten los mismos errores de vez en cuando. Desafortunadamente, los libros sobre aspectos teóricos del desarrollo no ayudan a evitarlos: los libros generalmente no tienen consejos concretos y prácticos. Y hasta adivino por qué ...
La primera recomendación que viene a la mente cuando se trata, por ejemplo, de
registro o diseño de clase es muy simple: "No hagas tonterías". Pero la experiencia muestra que definitivamente no es suficiente. Solo el diseño de clases en este caso es un buen ejemplo: un dolor de cabeza eterno que surge del hecho de que todos analizan este tema a su manera. Por lo tanto, decidí reunir consejos básicos en un artículo, después de lo cual evitará una serie de problemas típicos y, lo más importante, salvará a sus colegas de ellos. Si algunos principios te parecen banales (¡porque son realmente banales!), Bueno, entonces ya se han asentado en tu subcorteza y puedes felicitar a tu equipo.
Haré una reserva, de hecho, nos centraremos en las clases únicamente por simplicidad. Casi lo mismo se puede decir sobre las funciones o cualquier otro componente básico de la aplicación.
Si la aplicación funciona y realiza la tarea, entonces su diseño es bueno. O no? Depende de la función objetivo de la aplicación; lo que es bastante adecuado para una aplicación móvil que debe mostrarse una vez en la exposición puede no ser adecuado para la plataforma de negociación que cualquier banco ha estado desarrollando durante años. Hasta cierto punto, la respuesta a esta pregunta puede llamarse el principio
SÓLIDO , pero es demasiado general: quiero algunas instrucciones más específicas a las que se pueda hacer referencia en una conversación con colegas.
Aplicación de destino
Como no puede haber una respuesta universal, propongo reducir el alcance. Supongamos que estamos escribiendo una aplicación comercial estándar que acepta solicitudes a través de HTTP u otra interfaz, implementa cierta lógica por encima de ellas y luego realiza una solicitud al siguiente servicio de la cadena o almacena los datos recibidos en algún lugar. Para simplificar, supongamos que estamos utilizando Spring IoC Framework, ya que es bastante común ahora y el resto de los marcos son bastante similares. ¿Qué podemos decir sobre tal aplicación?
- El tiempo que el procesador pasa procesando una solicitud es importante, pero no crítico; un aumento del 0.1% en el clima no lo hará.
- No hay terabytes de memoria a nuestra disposición, pero si la aplicación requiere 50-100 Kbytes adicionales, esto no será un desastre.
- Por supuesto, cuanto más corto sea el tiempo de inicio, mejor. Pero no hay una diferencia fundamental entre 6 segundos y 5,9 segundos.
Criterios de optimización.
¿Qué es importante para nosotros en este caso?
Es probable que la empresa utilice el código del proyecto durante varios años, tal vez más de diez años.
El código en diferentes momentos será modificado por varios desarrolladores que no están familiarizados entre sí.
Es posible que en unos años, los desarrolladores quieran usar la nueva biblioteca LibXYZ o el marco FrABC.
En algún momento, parte del código o todo el proyecto pueden fusionarse con la base del código de otro proyecto.
En medio de los gerentes, generalmente se acepta que tales problemas se resuelven con la ayuda de la documentación. La documentación, por supuesto, es buena y útil, porque es tan genial cuando comienzas a trabajar en el proyecto que tienes cinco tickets abiertos, el gerente del proyecto pregunta cómo has progresado y necesitas leer (y recordar) unos 150 páginas de texto escritas lejos de escritores brillantes. Por supuesto, tuvo unos días o incluso un par de semanas para dedicar al proyecto, pero, si usa aritmética simple, por un lado, 5,000,000 bytes de código, por el otro, digamos, 50 horas de trabajo. Resulta que, en promedio, era necesario inyectar 100 Kb de código por hora. Y aquí todo depende mucho de la calidad del código. Si está limpio: fácil de ensamblar, bien estructurado y predecible, entonces verterlo en un proyecto parece ser un proceso notablemente menos doloroso. No es el último papel en esto el diseño de clase. No es el último
Lo que queremos del diseño de clase
De todo lo anterior, se pueden sacar muchas conclusiones interesantes sobre la arquitectura general, la pila de tecnología, el proceso de desarrollo, etc. Pero desde el principio decidimos hablar sobre el diseño de la clase, veamos qué cosas útiles podemos aprender de lo que se dijo anteriormente con respecto a él.
- Me gustaría que un desarrollador que no esté completamente familiarizado con el código de la aplicación pueda comprender lo que esta clase está haciendo cuando mira una clase. Y viceversa: al observar un requisito funcional o no funcional, pude adivinar rápidamente dónde se encuentra la aplicación en las clases responsables. Bueno, es deseable que la implementación de los requisitos no se “extienda” en toda la aplicación, sino que se concentre en una clase o en un grupo compacto de clases. Permítanme explicar con un ejemplo a qué tipo de antipatrón me refiero. Supongamos que necesitamos verificar que 10 solicitudes de cierto tipo solo puedan ser ejecutadas por usuarios que tengan más de 20 puntos en su cuenta (sin importar lo que eso signifique). Una mala manera de implementar dicho requisito es insertar un cheque al comienzo de cada solicitud. Entonces la lógica se extenderá por 10 métodos, en diferentes controladores. Una buena manera es crear un filtro o WebRequestInterceptor y verificar todo en un solo lugar.
- Quiero que los cambios en una clase que no afectan el contrato de clase no afecten, bueno, o (¡seamos realistas!) Al menos no afectan mucho a otras clases. En otras palabras, quiero encapsular la implementación de un contrato de clase.
- Me gustaría que fuera posible, al cambiar el contrato de clase, al pasar por la cadena de llamadas y al hacer el uso de encontrar, encontrar las clases a las que afecta este cambio. Es decir, quiero que las clases no tengan dependencias indirectas.
- Si es posible, me gustaría ver que los procesos de procesamiento de solicitudes que consisten en varios pasos de un solo nivel no están manchados por el código de varias clases, sino que se describen en el mismo nivel. Es muy bueno si el código que describe dicho proceso de procesamiento cabe en una pantalla dentro de un método con un nombre claro. Por ejemplo, necesitamos encontrar todas las palabras en una línea, hacer una llamada a un servicio de terceros para cada palabra, obtener una descripción de la palabra, aplicar formato a la descripción y guardar los resultados en la base de datos. Esta es una secuencia de acciones en 4 pasos. Es muy conveniente entender el código y cambiar su lógica cuando hay un método en el que estos pasos van uno tras otro.
- Realmente quiero que las mismas cosas en el código se implementen de la misma manera. Por ejemplo, si accedemos a la base de datos inmediatamente desde el controlador, es mejor hacerlo en todas partes (aunque no llamaría una buena práctica de diseño). Y si ya hemos ingresado a los niveles de servicios y repositorios, entonces es mejor no contactar a la base de datos directamente desde el controlador.
- Me gustaría que el número de clases / interfaces no directamente responsables de los requisitos funcionales y no funcionales no sea muy grande. Trabajar con un proyecto en el que hay dos interfaces para cada clase con lógica, una jerarquía compleja de herencia de cinco clases, una fábrica de clases y una fábrica de clases abstractas, es bastante difícil.
Recomendaciones prácticas
Una vez formulados los deseos, podemos esbozar pasos específicos que nos permitirán alcanzar nuestros objetivos.
Métodos estáticos
Como calentamiento, comenzaré con una regla relativamente simple. No debe crear métodos estáticos a menos que sean necesarios para el funcionamiento de una de las bibliotecas utilizadas (por ejemplo, debe crear un serializador para un tipo de datos).
En principio, no hay nada de malo en usar métodos estáticos. Si el comportamiento de un método depende completamente de sus parámetros, ¿por qué no hacerlo realmente estático? Pero debe tener en cuenta el hecho de que utilizamos Spring IoC, que sirve para vincular los componentes de nuestra aplicación. Spring IoC se ocupa de los conceptos de frijoles y su alcance. Este enfoque se puede mezclar con métodos estáticos agrupados en clases, pero comprender esta aplicación e incluso cambiar algo en ella (si, por ejemplo, necesita pasar algún parámetro global a un método o clase) puede ser muy difícil.
Al mismo tiempo, los métodos estáticos en comparación con los contenedores de IoC ofrecen una ventaja muy insignificante en la velocidad de invocación de métodos. Y sobre esto, tal vez, las ventajas terminan.
Si no está creando una función empresarial que requiera una gran cantidad de llamadas ultrarrápidas entre diferentes clases, es mejor no utilizar métodos estáticos.
Aquí el lector puede preguntar: "¿Pero qué pasa con las clases StringUtils e IOUtils?" De hecho, se ha desarrollado una tradición en el mundo de Java: poner funciones auxiliares para trabajar con cadenas y flujos de entrada-salida en métodos estáticos y recopilarlos bajo el paraguas de las clases SomethingUtils. Pero esta tradición me parece bastante musgosa. Si lo sigue, por supuesto, no se espera un gran daño: todos los programadores de Java están acostumbrados. Pero no tiene sentido en una acción tan ritual. Por un lado, por qué no hacer que el bean StringUtils, por otro lado, si no hace que el bean y todos los métodos auxiliares sean estáticos, hagamos las clases paraguas estáticas StockTradingUtils y BlockChainUtils. Comenzar a poner la lógica en métodos estáticos, dibujar un borde y detenerse es difícil. Te aconsejo que no comiences.
Finalmente, no olvide que con Java 11 muchos de los métodos auxiliares que habían estado desviando a los desarrolladores de un proyecto a otro durante décadas, se convirtieron en parte de la biblioteca estándar o se fusionaron en bibliotecas, por ejemplo, en Google Guava.
Contrato de clase atómico, compacto
Hay una regla simple que se aplica al desarrollo de cualquier sistema de software. Al observar cualquier clase, debería ser capaz de explicar de manera rápida y compacta, sin recurrir a largas excavaciones, lo que hace esta clase. Si es imposible encajar la explicación en un párrafo (no es necesario, sin embargo, expresado en una oración), podría valer la pena pensar y dividir esta clase en varias clases atómicas. Por ejemplo, la clase "Busca archivos de texto en un disco y cuenta el número de letras Z en cada uno de ellos" - un buen candidato para la descomposición "busca en un disco" + "cuenta el número de letras".
Por otro lado, no haga clases demasiado pequeñas, cada una de las cuales está diseñada para una acción. ¿Pero de qué tamaño debería ser la clase entonces? Las reglas básicas son las siguientes:
- Idealmente, cuando el contrato de clase coincide con la descripción de la función comercial (o subfunción, dependiendo de cómo se arreglen los requisitos). Esto no siempre es posible: si un intento de cumplir con esta regla lleva a la creación de código engorroso y no obvio, es mejor dividir la clase en partes más pequeñas.
- Una buena métrica para evaluar la calidad de un contrato de clase es la relación entre su complejidad intrínseca y la complejidad del contrato. Por ejemplo, un contrato de clase muy bueno (aunque fantástico) puede verse así: "La clase tiene un método que recibe una línea con una descripción del tema en ruso en la entrada y, como resultado, compone una historia de calidad o incluso una historia sobre un tema determinado". Aquí, el contrato es simple y generalmente entendido. Su implementación es extremadamente compleja, pero la complejidad está oculta dentro de la clase.
¿Por qué es importante esta regla?
- En primer lugar, la capacidad de explicarse claramente lo que hace cada una de las clases siempre es útil. Desafortunadamente, lejos de cada proyecto, los desarrolladores pueden hacer esto. A menudo puede escuchar algo como: “Bueno, este es un envoltorio sobre la clase Path, que de alguna manera creamos y a veces usamos en lugar de Path. También tiene un método que puede duplicar todas las rutas de File.separator. Necesitamos este método para guardar informes en la nube y, por alguna razón, terminó en la clase Ruta ".
- El cerebro humano es capaz de operar simultáneamente con no más de cinco a diez objetos. La mayoría de las personas no tienen más de siete. En consecuencia, si un desarrollador necesita operar con más de siete objetos para resolver un problema, perderá algo o se verá obligado a empaquetar varios objetos bajo un "paraguas" lógico. Y si todavía tiene que empacarlo, ¿por qué no hacerlo de inmediato, conscientemente, y darle a este paraguas un nombre significativo y un contrato claro?
¿Cómo verificar que todo sea lo suficientemente granular? Pídale a un colega que le dé 5 (cinco) minutos. Tome parte de la aplicación que está trabajando actualmente en crear. Para cada clase, explique a un colega qué hace exactamente esta clase. Si no encaja en 5 minutos, o un colega no puede entender por qué se necesita esta o aquella clase, tal vez debería cambiar algo. Bueno, o no cambiar y volver a realizar el experimento, con otro colega.
Dependencias de clase
Supongamos que necesitamos seleccionar secciones de texto vinculadas de más de 100 bytes para un archivo PDF empaquetado en un archivo ZIP y guardarlas en la base de datos. Un antipatrón popular en tales casos se ve así:
- Hay una clase que abre un archivo ZIP, busca un archivo PDF y lo devuelve como InputStream.
- Esta clase tiene un enlace a una clase que busca en párrafos de texto PDF.
- La clase que funciona con PDF, a su vez, tiene un enlace a la clase que almacena datos en la base de datos.
Por un lado, todo parece lógico: datos recibidos, llamados directamente a la siguiente clase en la cadena. Pero al mismo tiempo, los contratos de la clase en la parte superior de la cadena se mezclan en los contratos y las dependencias de todas las clases que van en la cadena detrás de ella. Es mucho más correcto hacer que estas clases sean atómicas e independientes entre sí, y crear otra clase que realmente implemente la lógica de procesamiento conectando estas tres clases entre sí.
Cómo no hacerlo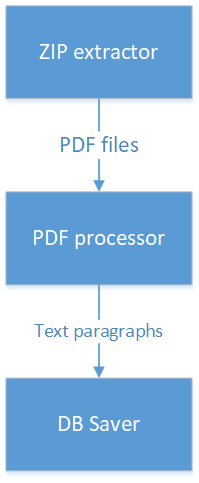
¿Qué está mal aquí? La clase que funciona con archivos ZIP pasa datos a la clase que procesa el PDF, y que, a su vez, pasa los datos a la clase que trabaja con la base de datos. Esto significa que la clase que funciona con ZIP, como resultado, por alguna razón depende de las clases que funcionan con la base de datos. Además, la lógica de procesamiento se distribuye en tres clases y, para comprenderla, debemos repasar las tres clases. ¿Qué sucede si necesita párrafos de texto obtenidos de PDF para pasar a un servicio de terceros a través de una llamada REST? Deberá cambiar la clase que funciona con PDF, y dibujar en ella también funciona con REST.
Cómo hacerlo: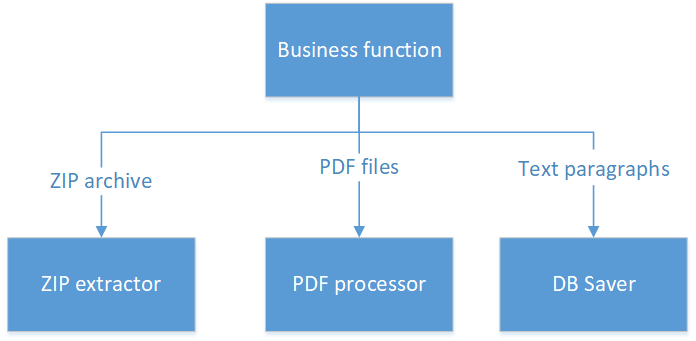
Aquí tenemos cuatro clases:
- Una clase que funciona solo con un archivo ZIP y devuelve una lista de archivos PDF (se puede argumentar, devolver archivos es malo, son grandes y romperán la aplicación. Pero en este caso, leamos la palabra "retornos" en sentido amplio. Por ejemplo, devuelve Stream desde InputStream )
- La segunda clase es responsable de trabajar con PDF.
- La tercera clase no sabe y no puede hacer nada excepto guardar párrafos en la base de datos.
- Y la cuarta clase, que consiste literalmente en varias líneas de código, contiene toda la lógica de negocios que cabe en una pantalla.
Destaco una vez más que en 2019 en Java hay al menos dos buenas (y algo menos
bueno) formas de no transferir archivos y una lista completa de todos los párrafos como objetos en la memoria. Esto es:
- API Java Stream
- Devoluciones de llamada Es decir, una clase con una función empresarial no transfiere datos directamente, pero dice ZIP Extractor: aquí hay una devolución de llamada para usted, busque archivos PDF en un archivo ZIP, cree un InputStream para cada archivo y llame a la devolución de llamada transferida con él.
Comportamiento implícito
Cuando no estamos tratando de resolver un problema completamente nuevo que nadie resolvió anteriormente, sino que, por el contrario, hacemos algo que otros desarrolladores ya han hecho varios cientos (o cientos de miles) antes, todos los miembros del equipo tienen algunas expectativas con respecto a la complejidad ciclomática y el consumo de recursos de la solución. . Por ejemplo, si necesitamos encontrar en un archivo todas las palabras que comienzan con la letra z, esta es una lectura secuencial y única del archivo en bloques del disco. Es decir, si se enfoca en
https://gist.github.com/jboner/2841832, tal operación tomará varios microsegundos por 1 MB, bueno, tal vez, dependiendo del entorno de programación y la carga del sistema, varias decenas o incluso cien microsegundos, pero Ni un segundo en absoluto. Tomará varias decenas de kilobytes de memoria (omitimos la pregunta de qué estamos haciendo con los resultados, esta es la preocupación de otra clase), y el código probablemente ocupará aproximadamente una pantalla. Al mismo tiempo, esperamos que no se utilicen otros recursos del sistema. Es decir, el código no creará hilos, escribirá datos en el disco, enviará paquetes a través de la red y guardará datos en la base de datos.
Esta es la expectativa habitual de una llamada al método:
zWordFinder.findZWords(inputStream). ...
Si el código de su clase no cumple con estos requisitos por alguna razón razonable, por ejemplo, para clasificar una palabra en z y no en z, debe llamar al método REST cada vez (no sé por qué esto podría ser necesario, pero imaginemos esto) es necesario escribir con mucho cuidado en el contrato de clase, y es muy bueno si el nombre del método indica que el método se está ejecutando en algún lugar para consultar.
Si no tiene una razón razonable para un comportamiento implícito, reescriba la clase.
¿Cómo entender las expectativas de la complejidad y la intensidad de los recursos del método? Debe recurrir a una de estas formas simples:
- Con experiencia, gane horizontes bastante amplios.
- Pregúntele a un colega: esto siempre se puede hacer.
- Antes de comenzar el desarrollo, hable con los miembros del equipo sobre el plan de implementación.
- Para hacerse la pregunta: "¿Pero no uso demasiados recursos redundantes en este método?" Esto suele ser suficiente.
No necesita involucrarse en la optimización también: guardar 100 bytes cuando los usa la clase 100,000 no tiene mucho sentido para la mayoría de las aplicaciones.
Esta regla abre una ventana al rico mundo de la sobre ingeniería, ocultando respuestas a preguntas como "¿por qué no debería pasar un mes para ahorrar 10 bytes de memoria en una aplicación que necesita 10 GB para funcionar"? Pero no desarrollaré este tema aquí. Ella merece un artículo separado.
Nombres de métodos implícitos
En la programación Java, actualmente hay varias convenciones implícitas con respecto a los nombres de clase y su comportamiento. No hay muchos de ellos, pero es mejor no romperlos. Trataré de enumerar los que se me ocurren:
- Constructor: crea una instancia de la clase, puede crear algunas estructuras de datos bastante ramificadas, pero no funciona con la base de datos, no escribe en el disco, no envía datos a través de la red (diré, el registrador incorporado puede hacer todo esto, pero esta es una historia diferente en en cualquier caso, recae en la conciencia del configurador de registro).
- Getter - getSomething () - devuelve algún tipo de estructura de memoria desde las profundidades del objeto. Nuevamente, no escribe en el disco, no realiza cálculos complejos, no envía datos a través de la red, no funciona con la base de datos (excepto cuando este es un campo ORM lento, y esta es solo una de las razones por las que los campos perezosos deben usarse con mucho cuidado) .
- Setter - setSomething (Algo algo) - establece el valor de la estructura de datos, no hace cálculos complejos, no envía datos a través de la red, no funciona con la base de datos. Por lo general, no se espera que el emisor implique un comportamiento o consumo de recursos informáticos significativos.
- equals () y hashcode (): no se espera nada, excepto cálculos simples y comparaciones en una cantidad que depende linealmente del tamaño de la estructura de datos. Es decir, si llamamos a hashcode para un objeto de tres campos primitivos, se espera que se ejecuten N * 3 instrucciones computacionales simples.
- toSomething (): también se espera que sea un método que convierta un tipo de datos en otro, y para la conversión solo necesita una cantidad de memoria comparable al tamaño de las estructuras y el tiempo del procesador que depende linealmente del tamaño de las estructuras. Aquí debe tenerse en cuenta que la conversión de tipos no siempre se puede realizar de forma lineal, por ejemplo, convertir una imagen de píxeles a un formato SVG puede ser una acción muy poco trivial, pero en este caso es mejor nombrar el método de manera diferente. Por ejemplo, el nombre computeAndConvertToSVG () parece algo incómodo, pero inmediatamente sugiere que se están realizando algunos cálculos significativos en el interior.
Daré un ejemplo. Recientemente hice una auditoría de la aplicación. Por la lógica del trabajo, sé que la aplicación en algún lugar del código se suscribe a la cola RabbitMQ. Estoy caminando por el código, no puedo encontrar este lugar. Estoy buscando directamente un atractivo para el conejo, estoy empezando a subir, voy al lugar en el flujo de negocios, donde la suscripción realmente se lleva a cabo, estoy empezando a jurar. Cómo se ve en el código:
- Se llama al método service.getQueueListener (tickerName): se ignora el resultado devuelto. Esto puede alertar, pero ese código en el que se ignoran los resultados del método no es el único en la aplicación.
- En el interior, tickerName se verifica para nulo y se llama a otro método getQueueListenerByName (tickerName).
- En su interior, una instancia de la clase QueueListener se toma del hash con el nombre del ticker (si no es así, se crea), y se llama al método getSubscription ().
- Y ahora, dentro del método getSubscription (), la suscripción realmente tiene lugar. Y sucede en algún lugar en medio de un método del tamaño de tres pantallas.
Te diré francamente: sin recorrer toda la cadena y sin leer una docena de pantallas atentas de código, no era realista adivinar dónde está la suscripción. Si el método se llamara subscribeToQueueByTicker (tickerName), me ahorraría mucho tiempo.
Clases de utilidad
Hay un maravilloso libro Design Patterns: Elements of Reusable Object-Oriented Software (1994), a menudo se llama GOF (Gang of Four, por el número de autores). El beneficio de este libro radica principalmente en que brindó a los desarrolladores de diferentes países un solo idioma para describir los patrones de diseño de clase. Ahora, en lugar de "se garantiza que la clase existe en una sola instancia y que tiene un punto de acceso estático", podemos decir "singleton". El mismo libro causó daños notables a las mentes frágiles. Este daño está bien descrito por una cita de uno de los foros "Colegas, necesito crear una tienda web, díganme con qué plantillas debo comenzar". En otras palabras, algunos programadores tienden a abusar de los patrones de diseño, y donde sea que se pueda administrar con una clase, a veces crean cinco o seis a la vez, por si acaso, "para mayor flexibilidad".
¿Cómo decidir si necesita una fábrica de clases abstractas (u otro patrón más complicado que una interfaz) o no? Hay algunas consideraciones simples:
- Si está escribiendo una solicitud en Spring, no se necesita el 99% del tiempo. Spring te ofrece bloques de construcción de nivel superior, úsalos. Lo máximo que puede encontrar útil es una clase abstracta.
- Si el punto 1 aún no le dio una respuesta clara, recuerde que cada plantilla es +1000 puntos a la complejidad de la aplicación. Analice cuidadosamente si los beneficios de usar la plantilla son mayores que los daños causados por ella. Volviendo a una metáfora, recuerde que cada medicamento no solo cura, sino que también daña levemente. No tome todas las pastillas a la vez.
Un buen ejemplo de cómo no lo necesita, puede ver
aquí .
Conclusión
Para resumir, quiero señalar que he enumerado las recomendaciones más básicas. Ni siquiera los sacaría en forma de artículo, son tan obvios. Pero durante el año pasado, me he encontrado con aplicaciones muy a menudo en las que se han violado muchas de estas recomendaciones. Escribamos un código simple que sea fácil de leer y fácil de mantener.