
Hola a todos!
Soy un desarrollador de backend en el equipo del servidor Badoo. En la conferencia HighLoad del año pasado, hice
una presentación , una versión de texto que quiero compartir con ustedes. Esta publicación será más útil para aquellos que escriben pruebas para el backend y experimentan problemas con las pruebas de código heredado, así como para aquellos que desean probar la lógica empresarial compleja.
¿De qué hablaremos? Primero, hablaré brevemente sobre nuestro proceso de desarrollo y cómo afecta nuestra necesidad de pruebas y el deseo de escribir estas pruebas. Luego, subiremos y bajaremos la pirámide de automatización de pruebas, discutiremos los tipos de pruebas que usamos, hablaremos sobre las herramientas dentro de cada una de ellas y qué problemas resolvemos con su ayuda. Al final, considere cómo mantener y ejecutar todo esto.
Nuestro proceso de desarrollo
Hemos ilustrado nuestro proceso de desarrollo:
Un golfista es un desarrollador de backend. En algún momento, una tarea de desarrollo se traslada a él, generalmente en forma de dos documentos: requisitos del lado comercial y un documento técnico que describe los cambios en nuestro protocolo de interacción entre el servidor y los clientes (aplicaciones móviles y el sitio).
El desarrollador escribe el código y lo pone en funcionamiento, y antes que todas las aplicaciones cliente. Toda la funcionalidad está protegida por algunos indicadores de características o pruebas A / B, esto se prescribe en un documento técnico. Después de eso, de acuerdo con las prioridades actuales y la hoja de ruta del producto, se lanzan las aplicaciones del cliente. Para nosotros, los desarrolladores de back-end, es completamente impredecible cuándo se implementará una característica particular en los clientes. El ciclo de lanzamiento para las aplicaciones del cliente es algo más complicado y más largo que el nuestro, por lo que nuestros gerentes de producto literalmente hacen malabares con las prioridades.
La cultura de desarrollo adoptada por la compañía es de gran importancia: el desarrollador de back-end es responsable de la característica desde el momento de su implementación en el back-end hasta la última integración en la última plataforma en la que originalmente se planeó implementar esta característica.
Esta situación es bastante posible: hace seis meses, implementó alguna característica, los equipos de clientes no la implementaron durante mucho tiempo, porque las prioridades de la empresa han cambiado, ya está ocupado trabajando en otras tareas, tiene nuevos plazos, prioridades, y aquí vienen sus colegas y dicen: "¿Recuerdas esto que te lavaste hace seis meses? Ella no está trabajando ". Y en lugar de involucrarse en nuevas tareas, apaga los incendios.

Por lo tanto, nuestros desarrolladores tienen una motivación inusual para los programadores de PHP: asegurarse de que haya la menor cantidad de problemas posible durante la fase de integración.
¿Qué quiere hacer en primer lugar para asegurarse de que la función funcione?
Por supuesto, lo primero que viene a la mente es realizar pruebas manuales. Recoge la aplicación, pero no sabe cómo: debido a que la función es nueva, los clientes se ocuparán de ella en seis meses. Bueno, las pruebas manuales no garantizan que, durante el tiempo que transcurrirá desde el lanzamiento del backend hasta el inicio de la integración, nadie romperá nada con los clientes.
Y aquí las pruebas automatizadas vienen en nuestra ayuda.
Pruebas unitarias
Las pruebas más simples que escribimos son pruebas unitarias. Usamos PHP como lenguaje principal para el backend, y PHPUnit como marco para pruebas unitarias. Mirando hacia el futuro, diré que todas nuestras pruebas de back-end están escritas sobre la base de este marco.
Las pruebas unitarias a menudo cubrimos algunos pequeños fragmentos de código aislados, verificamos el rendimiento de métodos o funciones, es decir, estamos hablando de pequeñas unidades de lógica de negocios. Nuestras pruebas unitarias no deben interactuar con nada, acceder a bases de datos o servicios.
Softmocks
La principal dificultad que enfrentan los desarrolladores al escribir pruebas unitarias es el código no comprobable, y este suele ser el código heredado.
Un simple ejemplo. Badoo tiene 12 años, una vez fue una startup muy pequeña, que fue desarrollada por varias personas. El inicio existió con bastante éxito sin ninguna prueba en absoluto. Luego nos volvimos lo suficientemente grandes y nos dimos cuenta de que no puedes vivir sin pruebas. Pero para entonces se había escrito mucho código que funcionaba. ¡No lo reescribas solo por probar! Eso no sería muy razonable desde el punto de vista comercial.
Por lo tanto, desarrollamos una pequeña
biblioteca de código abierto SoftMocks , que hace que nuestro proceso de escritura de pruebas sea más barato y más rápido. Intercepta todos los archivos PHP de incluir / requerir y sobre la marcha reemplaza el archivo fuente con contenido modificado, es decir, código reescrito. Esto nos permite crear talones para cualquier código. Detalla cómo funciona la biblioteca.
Esto es lo que parece para un desarrollador:
Con la ayuda de construcciones tan simples, podemos redefinir globalmente todo lo que queramos. En particular, nos permiten sortear las limitaciones del creador estándar de PHPUnit. Es decir, podemos burlarnos de métodos estáticos y privados, redefinir constantes y hacer mucho más, lo cual es imposible en PHPUnit ordinario.
Sin embargo, nos encontramos con un problema: a los desarrolladores les parece que si hay SoftMocks, no hay necesidad de escribir el código probado; siempre se puede "peinar" el código con nuestros simulacros globales, y todo funcionará bien. Pero este enfoque conduce a un código más complejo y a la acumulación de "muletas". Por lo tanto, adoptamos varias reglas que nos permiten mantener la situación bajo control:
- Todo el código nuevo debe probarse fácilmente con simulacros estándar de PHPUnit. Si se cumple esta condición, entonces el código es comprobable y puede seleccionar fácilmente una pieza pequeña y probarla solo.
- SoftMocks se puede usar con código antiguo que está escrito de una manera que no es adecuada para pruebas unitarias, así como en casos donde es demasiado costoso / largo / difícil de hacer de otra manera (enfatice lo necesario).
El cumplimiento de estas reglas se supervisa cuidadosamente en la etapa de revisión del código.
Prueba de mutación
Por separado, quiero decir sobre la calidad de las pruebas unitarias. Creo que muchos de ustedes usan métricas como la cobertura de código. Pero ella, desafortunadamente, no responde una pregunta: "¿He escrito una buena prueba de unidad?" Es posible que haya escrito una prueba de este tipo, que en realidad no verifica nada, no contiene una sola afirmación, pero genera una excelente cobertura de código. Por supuesto, el ejemplo es exagerado, pero la situación no está tan lejos de la realidad.
Recientemente, comenzamos a introducir pruebas mutacionales. Este es un concepto bastante antiguo, pero no muy conocido. El algoritmo para tales pruebas es bastante simple:
- tomar el código y la cobertura del código;
- parsim y comenzar a cambiar el código: verdadero a falso,> a> =, + a - (en general, daño en todos los sentidos);
- para cada cambio de mutación, ejecute conjuntos de pruebas que cubran la cadena modificada;
- si las pruebas caen, entonces son buenas y realmente no nos permiten romper el código;
- si las pruebas han pasado, lo más probable es que no sean lo suficientemente efectivas, a pesar de la cobertura, y puede valer la pena mirarlas más de cerca, para afirmar algo (o hay un área no cubierta por la prueba).
Hay varios frameworks listos para PHP, como Humbug e Infection. Desafortunadamente, no nos convenían, porque son incompatibles con SoftMocks. Por lo tanto, escribimos nuestra propia pequeña consola, que hace lo mismo, pero usa nuestro formato de cobertura de código interno y es amigo de SoftMocks. Ahora el desarrollador lo inicia manualmente y analiza las pruebas escritas por él, pero estamos trabajando para introducir la herramienta en nuestro proceso de desarrollo.
Pruebas de integración
Con la ayuda de pruebas de integración, verificamos la interacción con varios servicios y bases de datos.
Para comprender mejor la historia, desarrollemos una promoción ficticia y cúbrala con pruebas. Imagine que nuestros gerentes de producto decidieron distribuir boletos de conferencia a nuestros usuarios más dedicados:
La promoción debe mostrarse si:
- el usuario en el campo "Trabajo" indica "programador",
- el usuario participa en la prueba A / B HL18_promo,
- El usuario está registrado hace más de dos años.
Al hacer clic en el botón "Obtener un boleto", debemos guardar los datos de este usuario en una lista para transferirlos a nuestros gerentes que distribuyen los boletos.
Incluso en este ejemplo bastante simple, hay algo que no se puede verificar mediante pruebas unitarias: la interacción con la base de datos. Para hacer esto, necesitamos usar pruebas de integración.
Considere la forma estándar de probar la interacción de la base de datos ofrecida por PHPUnit:
- Eleve la base de datos de prueba.
- Preparamos DataTables y DataSets.
- Ejecute la prueba
- Limpiamos la base de datos de prueba.
¿Qué dificultades acechan con este enfoque?
- Debe admitir las estructuras de DataTables y DataSets. Si cambiamos el diseño de la tabla, entonces es necesario reflejar estos cambios en la prueba, lo que no siempre es conveniente y requiere tiempo adicional.
- Lleva tiempo preparar la base de datos. Cada vez que configuramos la prueba, necesitamos cargar algo allí, crear algunas tablas, y esto es largo y problemático si hay muchas pruebas.
- Y el inconveniente más importante: ejecutar estas pruebas en paralelo las hace inestables. Comenzamos la prueba A, él comenzó a escribir en la tabla de prueba, que él creó. Al mismo tiempo, lanzamos la prueba B, que quiere trabajar con la misma tabla de prueba. Como resultado, surgen bloqueos mutuos y otras situaciones imprevistas.
Para evitar estos problemas, desarrollamos nuestra propia biblioteca pequeña DBMocks.
DBMocks
El principio de funcionamiento es el siguiente:
- Con la ayuda de SoftMocks, interceptamos todos los contenedores a través de los cuales trabajamos con bases de datos.
- Cuando
la consulta pasa por simulacro, analiza la consulta SQL y extrae DB + TableName de ella, y obtiene el host de la conexión.
- En el mismo host en tmpfs creamos una tabla temporal con la misma estructura que la original (copiamos la estructura usando SHOW CREATE TABLE).
- Después de eso, redirigiremos todas las solicitudes que pasarán por simulacro a esta tabla a una temporal recién creada.
¿Qué nos da esto?
- no es necesario cuidar constantemente las estructuras;
- las pruebas ya no pueden dañar los datos en las tablas de origen, porque los redirigimos a tablas temporales sobre la marcha;
- todavía estamos probando la compatibilidad con la versión de MySQL con la que estamos trabajando, y si la solicitud deja de ser compatible con la nueva versión, nuestra prueba lo verá y la bloqueará.
- y lo más importante, las pruebas ahora están aisladas, e incluso si las ejecuta en paralelo, los subprocesos se dispersarán en diferentes tablas temporales, ya que agregamos una clave única para cada prueba en los nombres de las tablas de prueba.
Pruebas de API
La diferencia entre las pruebas unitarias y API está bien ilustrada en este GIF:
 La cerradura funciona bien, pero está unida a la puerta equivocada.
La cerradura funciona bien, pero está unida a la puerta equivocada.Nuestras pruebas simulan una sesión de cliente, pueden enviar solicitudes al backend, siguiendo nuestro protocolo, y el backend responde a ellas como un cliente real.
Probar grupo de usuarios
¿Qué necesitamos para escribir con éxito tales pruebas? Volvamos a las condiciones del espectáculo de nuestra promoción:
- el usuario en el campo "Trabajo" indica "programador",
- el usuario participa en la prueba A / B HL18_promo,
- El usuario está registrado hace más de dos años.
Aparentemente, aquí todo se trata del usuario. Y en realidad, el 99% de las pruebas de API requieren un usuario registrado autorizado, que está presente en todos los servicios y bases de datos.
¿Dónde conseguirlo? Puede intentar registrarlo en el momento de la prueba, pero:
- es largo y consume muchos recursos;
- después de completar la prueba, este usuario debe ser eliminado de alguna manera, lo cual es una tarea bastante trivial si hablamos de proyectos grandes;
- finalmente, como en muchos otros proyectos altamente cargados, realizamos muchas operaciones en segundo plano (agregando un usuario a varios servicios, replicación a otros centros de datos, etc.); Las pruebas no saben nada sobre tales procesos, pero si se basan implícitamente en los resultados de su ejecución, existe el riesgo de inestabilidad.
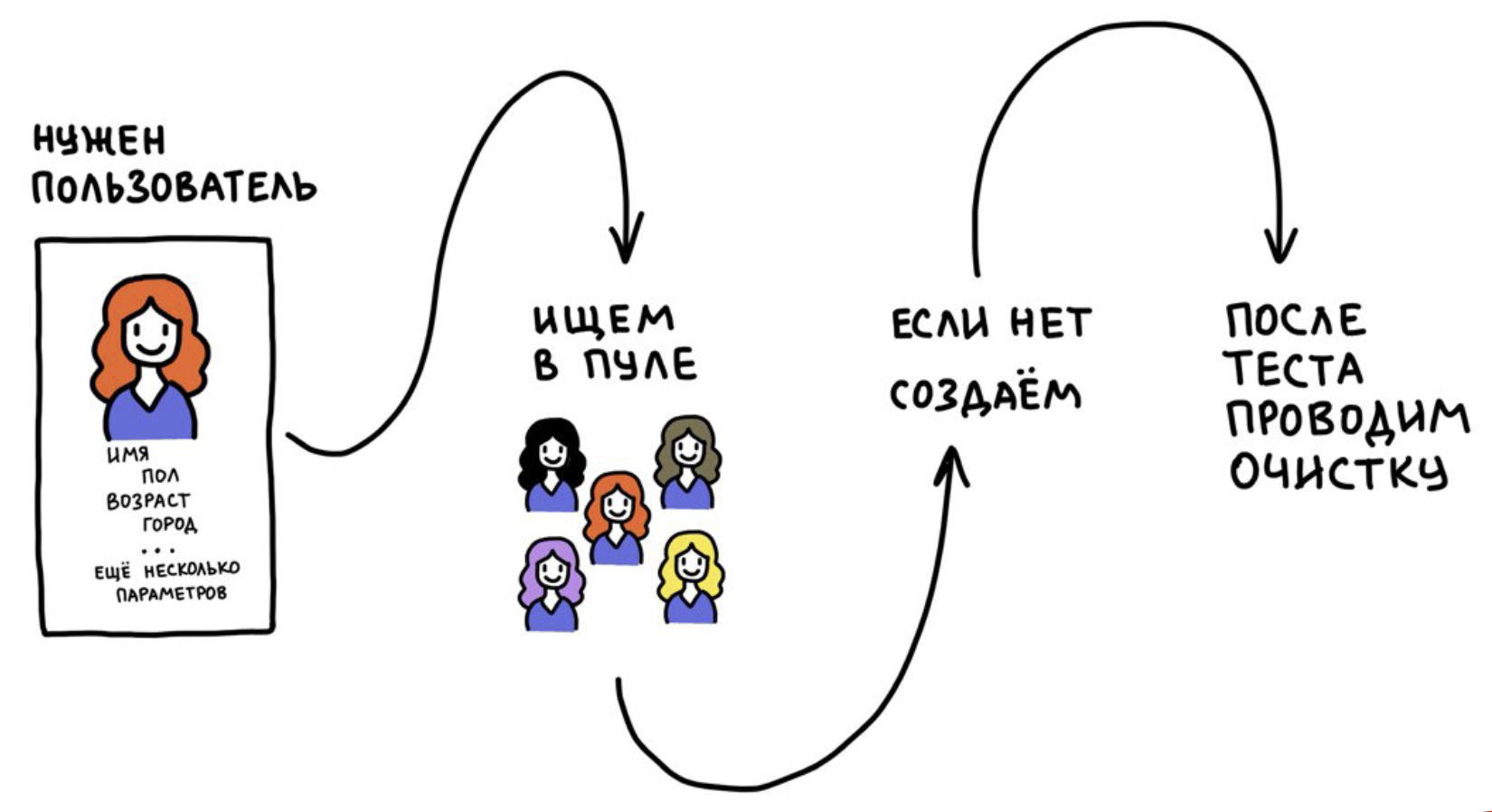
Desarrollamos una herramienta llamada Test Users Pool. Se basa en dos ideas:
- No registramos usuarios cada vez, pero lo usamos muchas veces.
- Después de la prueba, restablecemos los datos del usuario a su estado original (en el momento del registro). Si no se hace esto, las pruebas se volverán inestables con el tiempo, porque los usuarios estarán "contaminados" con la información de otras pruebas.
Funciona algo como esto:
En algún momento, queríamos ejecutar nuestras pruebas de API en un entorno de producción. ¿Por qué queremos esto? Porque la infraestructura de desarrollo no es lo mismo que la producción.
Aunque estamos tratando de repetir constantemente la infraestructura de producción en un tamaño reducido, el desarrollo nunca será una copia completa de la misma. Para estar absolutamente seguro de que la nueva compilación cumple con las expectativas y no hay problemas, cargamos el nuevo código en el clúster de preproducción, que funciona con datos y servicios de producción, y ejecutamos nuestras pruebas de API allí.
En este caso, es muy importante pensar en cómo aislar a los usuarios de prueba de los reales.
Qué sucederá si los usuarios de prueba comienzan a aparecer reales en nuestra aplicación. ¿Cómo aislar? Cada uno de nuestros usuarios tiene una bandera
is_test_user . En la etapa de registro, se convierte en
yes o
no , y ya no cambia. Con esta bandera, aislamos a los usuarios en todos los servicios. También es importante que excluyamos a los usuarios de prueba del análisis empresarial y los resultados de las pruebas A / B para no distorsionar las estadísticas.
Puede ir de una manera más simple: comenzamos con el hecho de que todos los usuarios de prueba fueron "reubicados" en la Antártida. Si tiene un geoservicio, esta es una forma completamente funcional.
API de control de calidad
No solo necesitamos un usuario, lo necesitamos con ciertos parámetros: para trabajar como programador, participar en una determinada prueba A / B y fue registrado hace más de dos años. Para los usuarios de prueba, podemos asignar fácilmente una profesión usando nuestra API de back-end, pero entrar en las pruebas A / B es probabilístico. Y la condición de registro hace más de dos años es generalmente difícil de cumplir, porque no sabemos cuándo apareció el usuario en el grupo.
Para resolver estos problemas, tenemos una API de control de calidad. Esto, de hecho, es una puerta trasera para las pruebas, que es un método API bien documentado que le permite administrar rápida y fácilmente los datos del usuario y cambiar su estado sin pasar por el protocolo principal de nuestra comunicación con los clientes. Los desarrolladores de backend escriben los métodos para ingenieros de control de calidad y para su uso en pruebas de interfaz de usuario y API.
QA API solo se puede aplicar en el caso de usuarios de prueba: si no hay un indicador correspondiente, la prueba caerá inmediatamente. Este es uno de nuestros métodos de API de control de calidad que le permite cambiar la fecha de registro del usuario a una arbitraria:
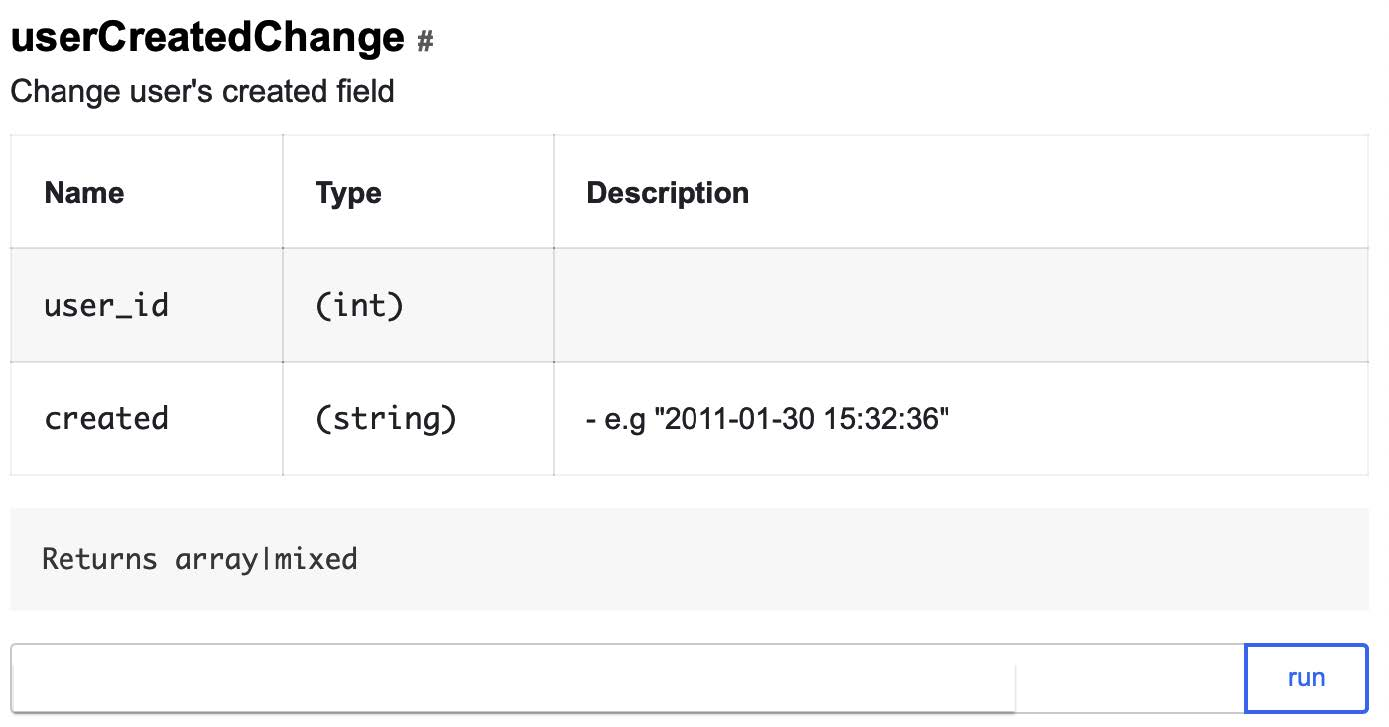
Por lo tanto, se verán como tres llamadas que le permitirán cambiar rápidamente los datos del usuario de prueba para que cumplan las condiciones para mostrar la promoción:
- En el campo "Trabajo" se indica el "programador":
addUserWorkEducation?user_id=ID&works[]=Badoo,
- El usuario participa en la prueba A / B HL18_promo:
forceSplitTest?user_id=ID&test=HL18_promo
- Registrado hace más de dos años:
userCreatedChange?user_id=ID&created=2016-09-01
Como se trata de una puerta trasera, es imperativo pensar en la seguridad. Protegimos nuestro servicio de varias maneras:
- aislado a nivel de red: solo se puede acceder a los servicios desde la red de la oficina;
- con cada solicitud pasamos un secreto, sin el cual es imposible acceder a la API de QA incluso desde la red de la oficina;
- Los métodos solo funcionan con usuarios de prueba.
Remotemocks
Para trabajar con el back-end remoto de las pruebas API, es posible que necesitemos simulacros. Para que? Por ejemplo, si la prueba de API en el entorno de producción comienza a acceder a la base de datos, debemos asegurarnos de que los datos en ella se borren de los datos de prueba. Además, los simulacros ayudan a que la respuesta de la prueba sea más adecuada para la prueba.
Tenemos tres textos:
Badoo es una aplicación multilingüe, tenemos un componente complejo de localización que le permite traducir y recibir traducciones rápidamente para la ubicación actual del usuario. Nuestros localizadores trabajan constantemente para mejorar las traducciones, realizar pruebas A / B con tokens y buscar formulaciones más exitosas. Y, mientras realizamos la prueba, no podemos saber qué texto devolverá el servidor; puede cambiar en cualquier momento. Pero podemos usar RemoteMocks para verificar si se accede correctamente al componente de localización.
¿Cómo funcionan los RemoteMocks? La prueba le pide al servidor que los inicialice para su sesión, y al recibir todas las solicitudes posteriores, el servidor comprueba si hay simulacros para la sesión actual. Si lo son, simplemente los inicializa usando SoftMocks.
Si queremos crear una simulación remota, indicamos qué clase o método necesita ser reemplazado y con qué. Todas las solicitudes de backend posteriores se ejecutarán teniendo en cuenta este simulacro:
$this->remoteInterceptMethod( \Promo\HighLoadConference::class, 'saveUserEmailToDb', true );
Bueno, ahora recopilemos nuestra prueba de API:
De una manera tan simple, podemos probar cualquier funcionalidad que se desarrolle en el backend y requiera cambios en el protocolo móvil.
Reglas de uso de prueba de API
Todo parece estar bien, pero nuevamente encontramos un problema: las pruebas de API resultaron ser demasiado convenientes para el desarrollo y hubo la tentación de usarlas en todas partes. Como resultado, una vez que nos dimos cuenta de que estábamos empezando a resolver problemas con la ayuda de las pruebas API para las cuales no estaban destinados.
¿Por qué es esto malo? Porque las pruebas de API son muy lentas. Se conectan a la red, se dirigen al backend, que recoge la sesión, va a la base de datos y a un conjunto de servicios. Por lo tanto, desarrollamos un conjunto de reglas para usar pruebas API:
- El propósito de las pruebas de API es verificar el protocolo de interacción entre el cliente y el servidor, así como la correcta integración del nuevo código;
- está permitido cubrir procesos complejos con ellos, por ejemplo, cadenas de acciones;
- no pueden usarse para probar la pequeña variabilidad de la respuesta del servidor; esta es la tarea de las pruebas unitarias;
- durante la revisión del código, verificamos las pruebas incluidas.
Pruebas de IU
Como estamos considerando una pirámide de automatización, te contaré un poco sobre las pruebas de IU.
Los desarrolladores de backend en Badoo no escriben pruebas de interfaz de usuario; para esto tenemos un equipo dedicado en el departamento de control de calidad. Cubrimos la función con las pruebas de IU cuando ya se nos viene a la mente y se estabiliza, porque creemos que no es razonable gastar recursos en una automatización bastante costosa de la función, que, tal vez, no vaya más allá de la prueba A / B.
Utilizamos Calabash para pruebas automáticas móviles y Selenium para la web. Habla sobre nuestra plataforma de automatización y pruebas.
Prueba de funcionamiento
Ahora tenemos 100,000 pruebas unitarias, 6,000 - pruebas de integración y 14,000 pruebas API. Si intenta ejecutarlos en un hilo, incluso en nuestra máquina más poderosa, una ejecución completa de todos tomará: modular - 40 minutos, integración - 90 minutos, pruebas API - diez horas. Es muy largo
Paralelización
Hablamos sobre nuestra experiencia de paralelizar pruebas unitarias en este artículo .La primera solución, que parece obvia, es ejecutar pruebas en múltiples hilos. Pero fuimos más allá e hicimos una nube para el lanzamiento paralelo para poder escalar los recursos de hardware. Simplificado, su trabajo se ve así:
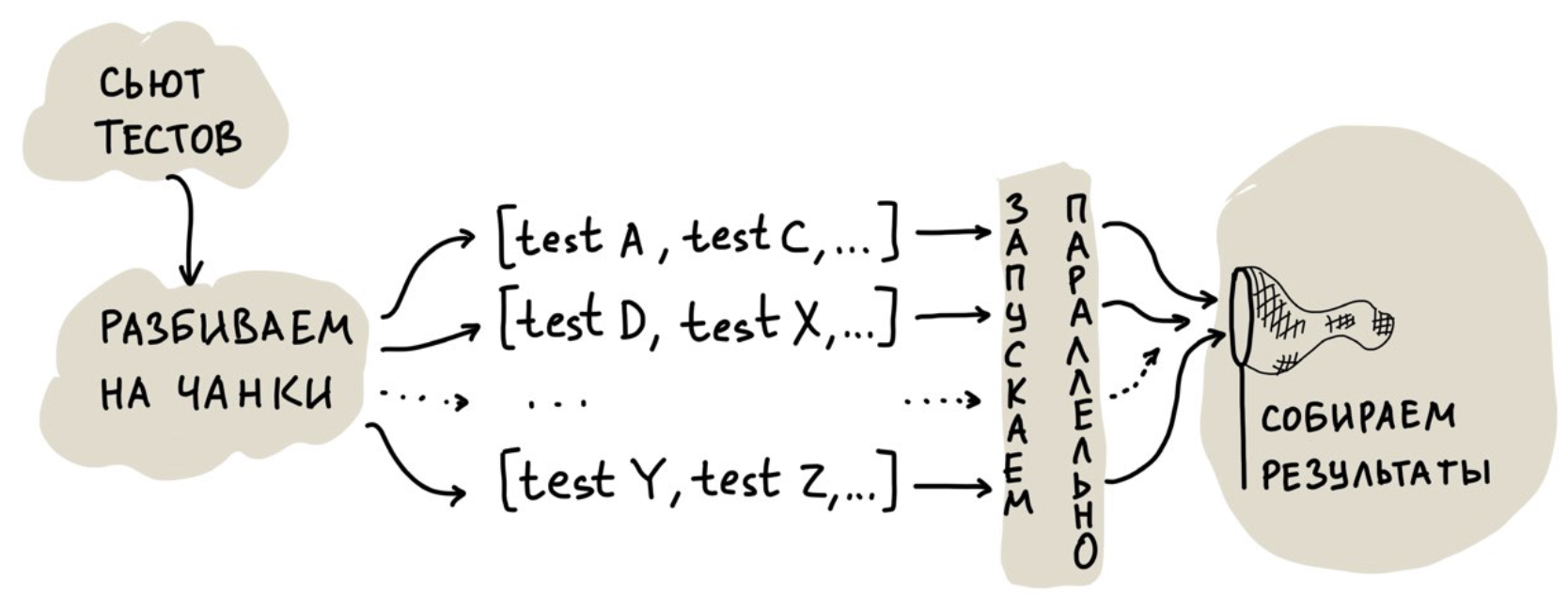
La tarea más interesante aquí es la distribución de pruebas entre hilos, es decir, su desglose en trozos.
Puede dividirlos por igual, pero las pruebas son diferentes, por lo que puede haber un fuerte sesgo en el tiempo de ejecución de un hilo: todos los hilos ya han llegado y uno se cuelga durante media hora, ya que fue "afortunado" con pruebas muy lentas.
Puede iniciar varios subprocesos y alimentarlos con pruebas de uno en uno. En este caso, el inconveniente es menos obvio: existen costos generales para inicializar el entorno, que, con una gran cantidad de pruebas y este enfoque, comienzan a desempeñar un papel importante.
Que hemos hecho Comenzamos a recopilar estadísticas sobre el tiempo necesario para ejecutar cada prueba, y luego comenzamos a componer fragmentos de tal manera que, según las estadísticas, un subproceso se ejecute por no más de 30 segundos. Al mismo tiempo, empaquetamos las pruebas bastante bien en trozos para hacerlas más pequeñas.
Sin embargo, nuestro enfoque también tiene un inconveniente. Está asociado con las pruebas de API: son muy lentas y consumen muchos recursos, evitando que se ejecuten pruebas rápidas.
Por lo tanto, dividimos la nube en dos partes: en la primera, solo se lanzan pruebas rápidas, y en la segunda, se pueden iniciar tanto rápido como lento. Con este enfoque, siempre tenemos una parte de la nube que puede manejar pruebas rápidas.
Como resultado, las pruebas unitarias comenzaron a ejecutarse en un minuto, las pruebas de integración en cinco minutos y las pruebas de API en 15 minutos. Es decir, una carrera completa en lugar de 12 horas no lleva más de 22 minutos.
Ejecución de prueba de cobertura de código
Tenemos un gran monolito complejo y, en el buen sentido, necesitamos ejecutar constantemente todas las pruebas, ya que un cambio en un lugar puede romper algo en otro. Esta es una de las principales desventajas de la arquitectura monolítica.
En algún momento, llegamos a la conclusión de que no es necesario ejecutar todas las pruebas cada vez; puede realizar ejecuciones basadas en la cobertura del código:
- Toma nuestra rama diff.
- Creamos una lista de archivos modificados.
- Para cada archivo obtenemos una lista de pruebas,
que lo cubren
- A partir de estas pruebas, creamos un conjunto y lo ejecutamos en una nube de prueba.
¿Dónde obtener cobertura? Recopilamos datos una vez al día cuando la infraestructura del entorno de desarrollo está inactiva. El número de pruebas ejecutadas ha disminuido notablemente, la velocidad de recibir comentarios de ellos, por el contrario, ha aumentado significativamente. Beneficio!
Una ventaja adicional fue la capacidad de ejecutar pruebas para parches. A pesar del hecho de que Badoo no ha sido una startup durante mucho tiempo, aún podemos implementar rápidamente cambios en la producción, verter soluciones rápidas, implementar características y cambiar la configuración. Como regla general, la velocidad de implementación de parches es muy importante para nosotros.
El nuevo enfoque dio un gran aumento en la velocidad de retroalimentación de las pruebas, porque ahora no necesitamos esperar mucho para una ejecución completa.Pero sin los defectos en ninguna parte. Lanzaremos el back-end dos veces al día, y la cobertura es relevante solo para la primera versión, hasta la primera compilación, después de lo cual comienza a retrasarse una compilación. Por lo tanto, para las compilaciones, ejecutamos un conjunto de pruebas completo. Para nosotros, esto es una garantía de que la cobertura del código no se queda atrás y que se han completado todas las pruebas necesarias. Lo peor que puede suceder es que atraparemos algunas pruebas fallidas en la etapa de construcción de la construcción, y no en las etapas anteriores. Pero esto sucede muy raramente.API-, code coverage. , , . - , API- .
Conclusión
- , . - , , - .
- ≠ . code review , .
- , , . .
- . .
- , ! , .
, Badoo PHP Meetup 16 . PHP-. , . ! 12:00, — YouTube- .