Soy un gran admirador de todo lo que hace
Fabien Sanglard , me gusta su blog y leí sus
dos libros de principio a fin (descritos en un reciente
podcast de Hansleminutes ).
Fabien recientemente escribió una gran publicación en la que
descifró un rastreador de rayos
diminutos , desofuscando el código y explicando las matemáticas fantásticamente. ¡Realmente recomiendo tomarse el tiempo de leer esto!
¿Pero me hizo preguntarme
si es posible portar este código de C ++ a C # ? Como últimamente tuve que escribir mucho C ++ en mi
trabajo principal , pensé que podría probarlo.
Pero lo que es más importante, ¿quería tener una mejor idea de
si C # es un lenguaje de bajo nivel ?
Una pregunta ligeramente diferente, pero relacionada: ¿cuánto es C # adecuado para la "programación del sistema"? Sobre este tema, realmente recomiendo
la excelente publicación de Joe Duffy de 2013 .
Puerto de línea
Comencé simplemente portando
código C ++ desofuscado línea por línea a C #. Fue bastante simple: ¡parece que la verdad todavía se dice que C # es C ++++!
El ejemplo muestra la estructura de datos principal: 'vector', aquí hay una comparación, C ++ a la izquierda, C # a la derecha:

Por lo tanto, hay algunas diferencias sintácticas, pero como .NET le permite definir
sus propios tipos de valor , pude obtener la misma funcionalidad. Esto es importante porque tratar el "vector" como una estructura significa que podemos obtener una mejor "localidad de datos" y no necesitamos involucrar al recolector de basura .NET, porque los datos se enviarán a la pila (sí, sé que esto es un detalle de implementación).
Para obtener más información sobre
structs o "tipos de valor" en .NET, consulte aquí:
En particular, en la última publicación de Eric Lippert, encontramos una cita tan útil que deja en claro qué son realmente los "tipos de valor":
Por supuesto, el hecho más importante sobre los tipos de valores no son los detalles de implementación, cómo se asignan , sino más bien el significado semántico original del "tipo de valor", es decir, que siempre se copia "por valor" . Si la información de asignación fuera importante, los llamaríamos "tipos de montón" y "tipos de pila". Pero en la mayoría de los casos no importa. La mayoría de las veces, la semántica de la copia y la identificación son relevantes.
Ahora veamos cómo se ven algunos otros métodos en comparación (de nuevo C ++ a la izquierda, C # a la derecha), primero
RayTracing(..) :
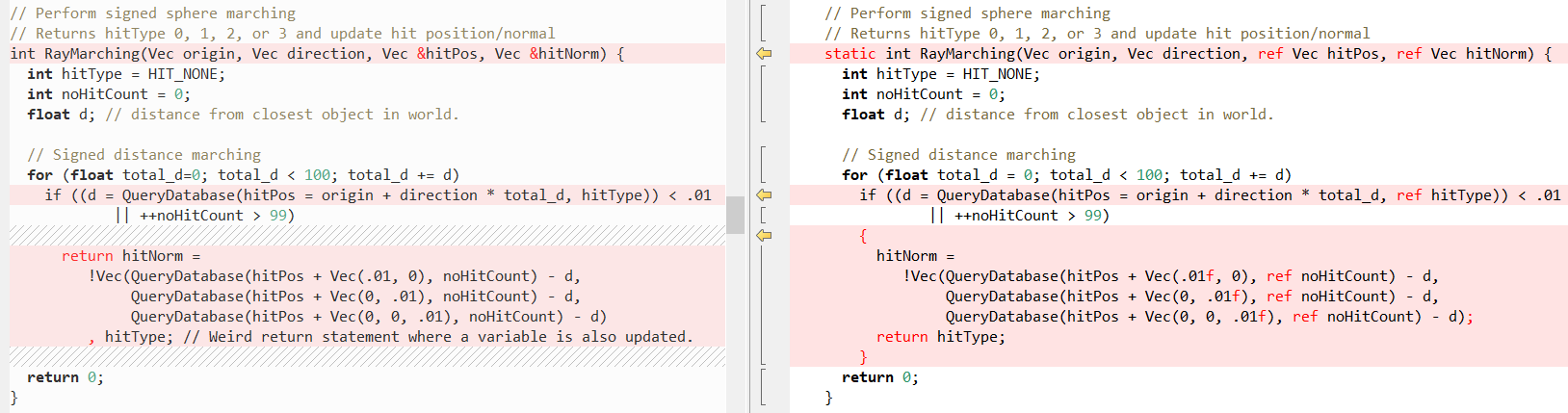
Entonces
QueryDatabase (..) :
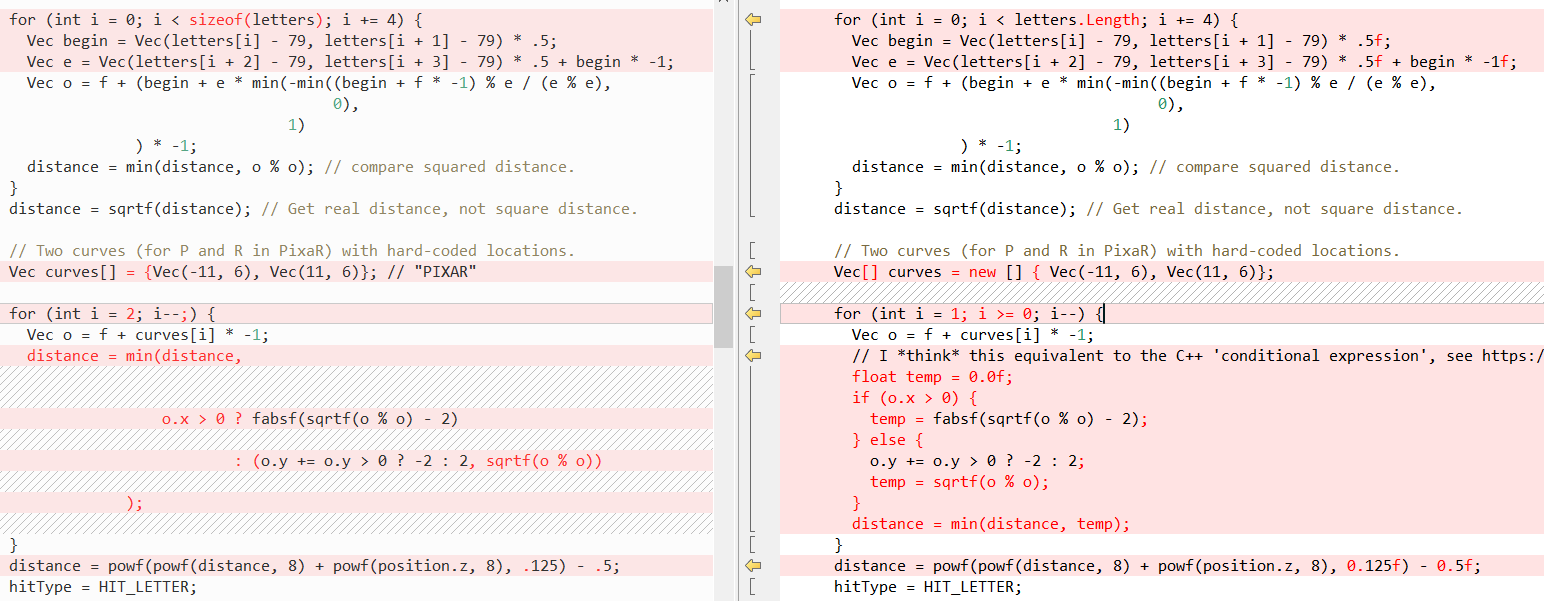
(vea
la publicación de Fabian para obtener una explicación de lo que hacen estas dos funciones)
Pero, de nuevo, el hecho es que C # hace que sea muy fácil escribir código C ++. En este caso, la palabra clave
ref nos ayuda más, lo que nos permite pasar un
valor por referencia . Hemos utilizado las llamadas a métodos de
ref durante bastante tiempo, pero recientemente, se han realizado esfuerzos para resolver la
ref otro lugar:
Ahora, a
veces, usar
ref mejorará el rendimiento, porque entonces la estructura no necesita copiarse, vea los puntos de referencia en la
publicación de Adam Stinix y
"Trampas de rendimiento ref locales y ref retornos en C #" para obtener más información.
Pero lo más importante es que dicho script proporciona a nuestro puerto C # el mismo comportamiento que el código fuente de C ++. Aunque quiero señalar que los llamados "enlaces administrados" no son exactamente lo mismo que los "punteros", en particular, no podrá realizar operaciones aritméticas en ellos, vea más sobre esto aquí:
Rendimiento
Por lo tanto, el código fue bien portado, pero el rendimiento también es importante. Especialmente en el rastreador, que puede calcular el marco durante varios minutos. El código C ++ contiene la variable
sampleCount , que controla la calidad de imagen final, con
sampleCount = 2 siguiente manera:

¡Obviamente no es muy realista!
Pero cuando llegas a
sampleCount = 2048 , todo se ve
mucho mejor:

Pero comenzar con
sampleCount = 2048 lleva
mucho tiempo, por lo que todas las demás ejecuciones se realizan con un valor de
2 para cumplir al menos un minuto. Cambiar
sampleCount solo afecta el número de iteraciones del bucle de código más externo, consulte
esta explicación para obtener una explicación.
Resultados después de un puerto de línea "ingenuo"
Para comparar sustancialmente C ++ y C #, utilicé la herramienta
time-windows , este es el puerto del comando
time unix. Los resultados iniciales se veían así:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| Tiempo (seg) | 47,40 | 80,14 | 78,02 |
| En el núcleo (seg.) | 0,14 (0,3%) | 0,72 (0,9%) | 0.63 (0.8%) |
| En espacio de usuario (seg.) | 43,86 (92,5%) | 73,06 (91,2%) | 70,66 (90,6%) |
| Número de errores de falla de página | 1143 | 4818 | 5945 |
| Conjunto de trabajo (KB) | 4232 | 13 624 | 17 052 |
| Memoria Extruida (KB) | 95 | 172 | 154 |
| Memoria no preventiva | 7 7 | 14 | 16 |
| Archivo de intercambio (KB) | 1460 | 10 936 | 11 024 |
Inicialmente, vemos que el código C # es un poco más lento que la versión C ++, pero está mejorando (ver más abajo).
Pero primero veamos qué nos hace el .NET JIT incluso con este puerto "ingenuo" línea por línea. Primero, hace un buen trabajo al incorporar métodos de ayuda más pequeños. Esto se puede ver en el resultado de la excelente
herramienta Inlining Analyzer (verde = incorporado):
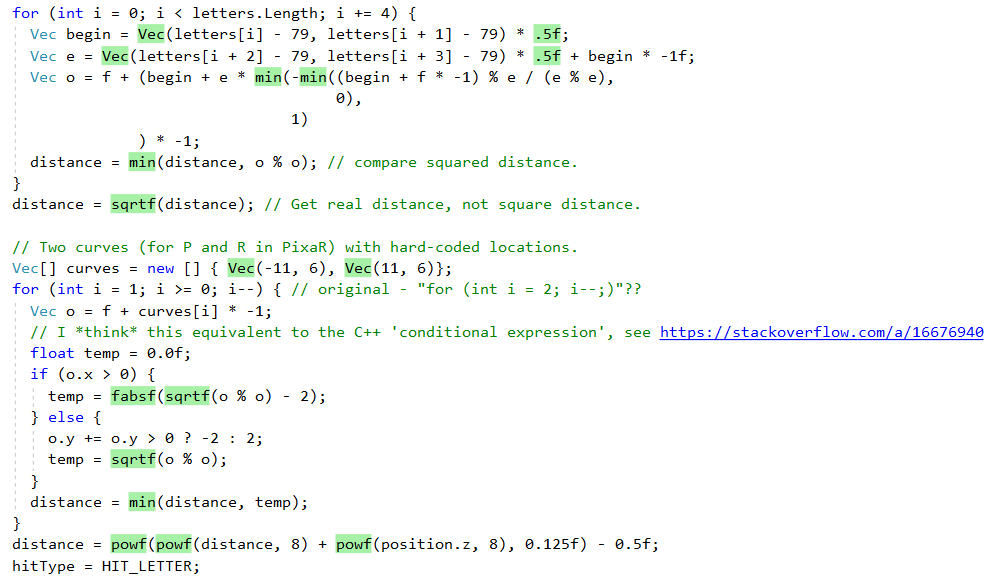
Sin embargo, no incorpora todos los métodos, por ejemplo, debido a la complejidad,
QueryDatabase(..) omite
QueryDatabase(..) :
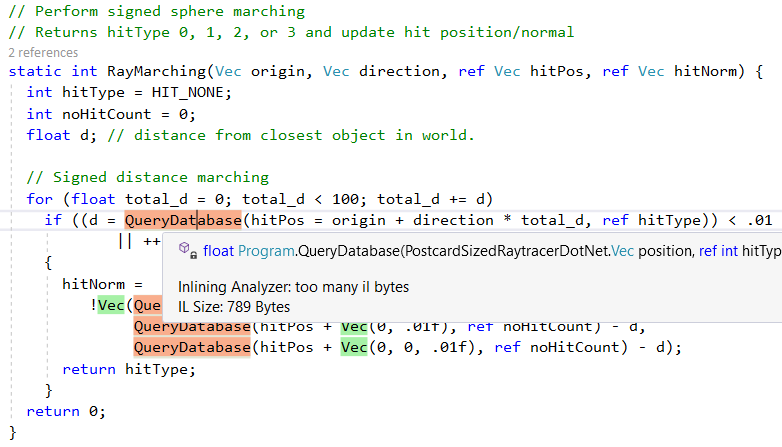
Otra característica del compilador .NET Just-In-Time (JIT) es la conversión de llamadas a métodos específicos a las instrucciones correspondientes de la CPU. Podemos ver esto en acción con la función de shell
sqrt , aquí está el código fuente de C # (tenga en cuenta la llamada a
Math.Sqrt ):
Y aquí está el código de ensamblador que genera .NET JIT: no hay llamada a
Math.Sqrt y se
Math.Sqrt la instrucción de procesador
vsqrtsd :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(para obtener este problema, siga
estas instrucciones , use el
complemento VS2019 "Disasmo" o mire
SharpLab.io )
Estos reemplazos también se conocen como
intrínsecos , y en el siguiente código podemos ver cómo los genera el JIT. Este fragmento muestra la asignación solo para
AMD64 , pero el JIT también apunta a
X86 ,
ARM y
ARM64 , el método completo
aquí .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
Como puede ver, algunos métodos se implementan como
Sqrt y
Abs , mientras que otros utilizan funciones de tiempo de ejecución de C ++, por ejemplo,
powf .
Todo este proceso está muy bien explicado en el artículo
"¿Cómo se implementa Math.Pow () en .NET Framework?" , también se puede ver en la fuente CoreCLR:
Resultados después de simples mejoras de rendimiento
Me pregunto si puede mejorar de inmediato el ingenuo puerto de línea por puerto. Después de algunos perfiles, hice dos cambios principales:
- Eliminar la inicialización de matriz en línea
- Reemplazar las funciones de
Math.XXX(..) con análogos de MathF.()
Estos cambios se explican con más detalle a continuación.
Eliminar la inicialización de matriz en línea
Para obtener más información sobre por qué esto es necesario, consulte
esta excelente respuesta de desbordamiento de pila de
Andrei Akinshin , junto con puntos de referencia y código de ensamblador. Llega a la siguiente conclusión:
Conclusión
- ¿.NET almacena en caché las matrices locales codificadas? Como los que ponen el compilador de Roslyn en metadatos.
- En este caso, habrá gastos generales? Desafortunadamente, sí: para cada llamada, JIT copiará el contenido de la matriz de los metadatos, lo que lleva más tiempo en comparación con una matriz estática. El tiempo de ejecución también selecciona objetos y crea tráfico en la memoria.
- ¿Hay alguna necesidad de preocuparse por esto? Posiblemente Si este es un método activo y desea alcanzar un buen nivel de rendimiento, debe usar una matriz estática. Si este es un método frío que no afecta el rendimiento de la aplicación, probablemente necesite escribir un código fuente "bueno" y colocar la matriz en el área del método.
Puede ver los cambios realizados en
esta diferencia .
Uso de funciones MathF en lugar de Math
En segundo lugar, y lo más importante, mejoré significativamente el rendimiento al hacer los siguientes cambios:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
Comenzando con .NET Standard 2.1, existen implementaciones concretas de funciones matemáticas comunes
float . Están ubicados en la clase
System.MathF . Para obtener más información sobre esta API y su implementación, consulte aquí:
Después de estos cambios, la diferencia en el rendimiento del código C # y C ++ se redujo a aproximadamente un 10%:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| Tiempo (seg) | 41,38 | 58,89 | 46.04 | 44,33 |
| En el núcleo (seg.) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0.13 (0.3%) |
| En espacio de usuario (seg.) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44.03 (99.3%) |
| Número de errores de falla de página | 1119 | 4749 | 5776 | 5661 |
| Conjunto de trabajo (KB) | 4136 | 13,440 | 16,788 | 16,652 |
| Memoria Extruida (KB) | 89 | 172 | 150 | 150 |
| Memoria no preventiva | 7 7 | 13 | 16 | 16 |
| Archivo de intercambio (KB) | 1428 | 10 904 | 10 960 | 11 044 |
TC: compilación multinivel, compilación
escalonada (
supongo que se habilitará de forma predeterminada en .NET Core 3.0)
Para completar, aquí están los resultados de varias ejecuciones:
| Correr | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | .NET Core (2.2) TC OFF | .NET Core (2.2) TC ON |
|---|
| TestRun-01 | 41,38 | 58,89 | 46.04 | 44,33 |
| TestRun-02 | 41,19 | 57,65 | 46,23 | 45,96 |
| TestRun-03 | 42,17 | 62,64 | 46,22 | 48,73 |
Nota : la diferencia entre .NET Core y .NET Framework se debe a la falta de la API de MathF en .NET Framework 4.7.2, para obtener más información, consulte
el ticket de soporte .Net Framework (4.8?) Para netstandard 2.1 .
Incrementar aún más la productividad
¡Estoy seguro de que el código aún se puede mejorar!
Si está interesado en resolver la diferencia de rendimiento,
aquí está el código C # . A modo de comparación, puede ver el código de ensamblador de C ++ desde el excelente servicio
Compiler Explorer .
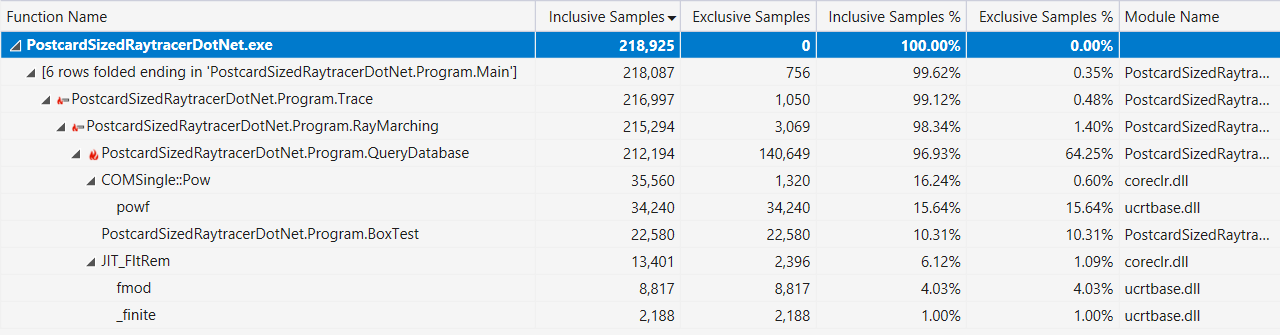
Finalmente, si eso ayuda, aquí está la salida del generador de perfiles de Visual Studio con una pantalla de "ruta caliente" (después de las mejoras de rendimiento descritas anteriormente):
¿C # es un lenguaje de bajo nivel?
O más específicamente:
¿Qué características del lenguaje de la funcionalidad C # / F # / VB.NET o BCL / Runtime significan programación de "bajo nivel" *?
* Sí, entiendo que "bajo nivel" es un término subjetivo.
Nota: cada desarrollador de C # tiene su propia idea de cuál es el "nivel bajo", los programadores de C ++ o Rust darán por sentado estas funciones.
Aquí está la lista que hice:
- ref devoluciones y ref locales
- “Pasar y regresar por referencia para evitar copiar grandes estructuras. ¡Los tipos y la memoria seguros pueden ser incluso más rápidos que los inseguros!
- Código inseguro en .NET
- “El lenguaje central de C #, como se definió en capítulos anteriores, es muy diferente de C y C ++ en que carece de punteros como tipo de datos. En cambio, C # proporciona enlaces y la capacidad de crear objetos gobernados por el recolector de basura. Este diseño, combinado con otras características, hace que C # sea un lenguaje mucho más seguro que C o C ++ ".
- Punteros gestionados en .NET
- “Hay otro tipo de puntero en el CLR: un puntero administrado. Se puede definir como un tipo más general de enlace que puede apuntar a otras ubicaciones, y no solo al comienzo del objeto ".
- C # 7 Series, Parte 10: Span <T> y Universal Memory Management
- "System.Span <T> es solo un tipo de pila (
ref struct ) que envuelve todos los patrones de acceso a la memoria; es un tipo de acceso universal y continuo a la memoria. Podemos imaginar una implementación de Span con una referencia ficticia y una longitud que acepte los tres tipos de acceso a memoria ".
- Compatibilidad ("Guía de programación de C #")
- ".NET Framework proporciona interoperabilidad con código no administrado a través de servicios de invocación de plataforma, el
System.Runtime.InteropServices , compatibilidad C ++ y compatibilidad COM (interoperabilidad COM)".
También lancé un grito en Twitter y obtuve muchas más opciones para su inclusión en la lista:
- Ben Adams : "Herramientas integradas para plataformas (Instrucciones de CPU)"
- Mark Gravell : “SIMD via Vector (que va bien con Span) es * bastante * bajo; .NET Core debería (¿pronto?) Ofrecer herramientas integradas de CPU directas para un uso más explícito de instrucciones específicas de CPU "
- Mark Gravell : "JIT de gran alcance: cosas como elisión de rango en matrices / intervalos, así como el uso de reglas por estructura T para eliminar grandes fragmentos de código que JIT sabe con certeza que no están disponibles para esa T o en su CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated, etc.) "
- Kevin Jones : "Mencionaría especialmente las clases
MemoryMarshal e Unsafe , y tal vez algunas otras cosas en los System.Runtime.CompilerServices "
- Theodoros Chatsigiannakis : "También puedes incluir
__makeref y el resto"
- damageboy : "¿La capacidad de generar dinámicamente código que coincida exactamente con la entrada esperada, dado que este último solo se conocerá en tiempo de ejecución y puede cambiar periódicamente?"
- Robert Hacken : "Emisión dinámica de IL"
- Victor Baybekov : “Stackalloc no fue mencionado. También es posible escribir IL puro (no dinámico, por lo tanto, se guarda en una llamada de función), por ejemplo, use
ldftn caché y llame a través de calli . Hay una plantilla de proyecto en VS2017 que hace que esto sea trivial al sobrescribir los métodos extern + MethodImplOptions.ForwardRef + ilasm.ex »
- Victor Baybekov : "MethodImplOptions.AggressiveInlining también" activa la programación de bajo nivel "en el sentido de que le permite escribir código de alto nivel con muchos métodos pequeños y aún controlar el comportamiento de JIT para obtener un resultado optimizado. De lo contrario, copie y pegue cientos de métodos LOC ... "
- Ben Adams : "¿Usa las mismas convenciones de llamadas (ABI) que en la plataforma base y p / invoca para la interacción?"
- Victor Baibekov : “Además, como mencionó #fsharp, tiene una
inline que funciona desde el nivel IL hasta el JIT, por lo tanto, se consideró importante a nivel del idioma. C # esto no es suficiente (hasta ahora) para lambdas, que siempre son llamadas virtuales, y las soluciones son a menudo extrañas (genéricos limitados) "
- Alexandre Mutel : “Nuevo SIMD integrado, postprocesamiento de Unsafe Utility class / IL (por ejemplo, personalizado, Fody, etc.). Para C # 8.0, punteros de función próximos ... "
- Alexandre Mutel : "Con respecto a IL, F # admite directamente IL en un idioma, por ejemplo"
- OmariO : “ BinaryPrimitives . Nivel bajo, pero seguro "
- Koji Matsui : “¿Qué tal tu propio ensamblador incorporado? Es difícil tanto para el kit de herramientas como para el tiempo de ejecución, pero puede reemplazar la solución p / invoke actual e implementar el código incrustado, si lo hay "
- Frank A. Kruger : "Ldobj, stobj, initobj, initblk, cpyblk"
- Conrad Coconut : “¿Quizás transmitir el almacenamiento local? Tampones de tamaño fijo? Probablemente deberías mencionar las restricciones no administradas y los tipos blittable :) "
- Sebastiano Mandala : “Solo una pequeña adición a todo lo que se dijo: ¿qué tal algo simple, como organizar estructuras y cómo llenar y alinear la memoria y ordenar campos puede afectar el rendimiento de la caché? Esto es algo que yo mismo debo explorar ".
- Nino Floris : "Las constantes integradas a través de readonlyspan, stackalloc, finalizadores, WeakReference, delegados abiertos, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, pueden establecer los tipos de estructuras exactamente de acuerdo con el diseño (utilizado para TaskAwaiter y su versión)"
Entonces, al final, diría que C # ciertamente le permite escribir código que se parece a C ++, y en combinación con las bibliotecas de tiempo de ejecución y de clase base proporciona muchas funciones de bajo nivel.Lectura adicional
Unity Burst Compiler: