Prólogo
Hay una utilidad tan simple y muy útil en el mundo:
BDelta , y sucedió que se arraigó en nuestro proceso de producción durante mucho tiempo (aunque su versión no se pudo instalar, pero ciertamente no fue la última disponible). Lo usamos para su propósito previsto: la construcción de parches binarios. Si nos fijamos en lo que hay en el repositorio, se pone un poco triste: de hecho, fue abandonado hace mucho tiempo y estaba muy desactualizado allí (una vez que mi antiguo colega hizo varias correcciones allí, pero fue hace mucho tiempo). En general, decidí resucitar este negocio: bifurqué, arrojé lo que no planeaba usar,
adelanté el proyecto en
cmake ,
alineé las microfunciones "calientes", quité grandes matrices de la pila (y matrices de longitud variable, que francamente "bombardeé") , una vez más condujo el perfilador - y descubrió que aproximadamente el 40% del tiempo se gasta en
fwrite ...
Entonces, ¿qué pasa con fwrite?
En este código, fwrite (en mi caso de prueba particular: creando un parche entre archivos cercanos de 300 MB, los datos de entrada están completamente en la memoria) se llama millones de veces con un pequeño búfer. Obviamente, esto se ralentizará y, por lo tanto, me gustaría influir de alguna manera en esta desgracia. No deseo implementar varios tipos de fuentes de datos, entrada-salida asíncrona, quería encontrar una solución más fácil. Lo primero que se me ocurrió fue aumentar el tamaño del búfer
setvbuf(file, nullptr, _IOFBF, 64* 1024)
pero no obtuve una mejora significativa en el resultado (ahora fwrite representó aproximadamente el 37% del tiempo), significa que el problema aún no está en la grabación frecuente de datos en el disco. Mirando fwrite "debajo del capó", puede ver que la estructura de ARCHIVO de bloqueo / desbloqueo está sucediendo en el interior de esta manera (pseudocódigo, todo el análisis se realizó en Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); } return retval; }
Según el generador de perfiles, _fwrite_nolock representa solo el 6% del tiempo, el resto es sobrecarga. En mi caso particular, la seguridad de los hilos es un exceso obvio, lo sacrificaré reemplazando la llamada fwrite con
_fwrite_nolock , incluso con argumentos que no necesito ser
inteligentes . Total: esta simple manipulación a veces redujo el costo de registrar el resultado, que en la versión original representaba casi la mitad del costo del tiempo. Por cierto, en el mundo POSIX hay una función similar:
fwrite_unlocked . En términos generales, lo mismo ocurre con Fread. Por lo tanto, con la ayuda del par #define, puede obtener una solución multiplataforma sin bloqueos innecesarios si no son necesarios (y esto sucede con bastante frecuencia).
fwrite, _fwrite_nolock, setvbuf
Hagamos un resumen del proyecto original y comencemos a probar un caso específico: grabar un archivo grande (512 MB) en porciones extremadamente pequeñas: 1 byte. Sistema de prueba: AMD Ryzen 7 1700, 16 GB de RAM, HDD 3.5 "7200 rpm 64 MB de caché, Windows 10 1809, el binario fue construido de 32 bits, se incluyen optimizaciones, la biblioteca está estáticamente vinculada.
Muestra para el experimento:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
Las variables serán TEST_BUFFER_SIZE, y en algunos casos reemplazaremos fwrite_unlocked con fwrite. Comencemos con el caso de fwrite sin establecer explícitamente el tamaño del búfer (comente setvbuf y el código asociado): tiempo 27048906 μs, velocidad de escritura - 18.93 Mb / s. Ahora configure el tamaño del búfer en 64 Kb: tiempo - 25037111 μs, velocidad - 20.44 Mb / s. Ahora probamos el funcionamiento de _fwrite_nolock sin llamar a setvbuf: 7262221 ms, ¡la velocidad es de 70.5 Mb / s!
A continuación, experimente con el tamaño del búfer (setvbuf):
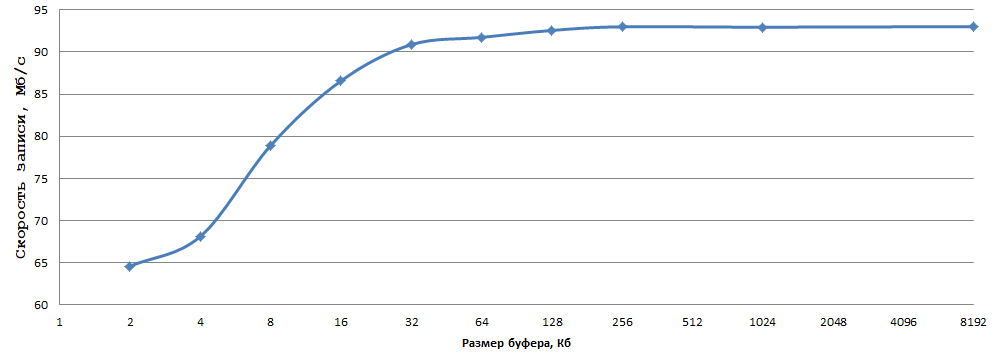
Los datos se obtuvieron promediando 5 experimentos; era demasiado vago para considerar los errores. En cuanto a mí, 93 MB / s al escribir 1 byte en un HDD normal es un muy buen resultado, solo seleccione el tamaño de búfer óptimo (en mi caso 256 KB, justo) y reemplace fwrite con _fwrite_nolock / fwrite_unlocked (en si la seguridad del hilo no es necesaria, por supuesto).
Del mismo modo con fread en condiciones similares. Ahora veamos cómo están las cosas en Linux, la configuración de prueba es la siguiente: AMD Ryzen 7 1700X, 16 GB de RAM, HDD 3.5 "7200 rpm 64 MB de caché, OpenSUSE 15 OS, GCC 8.3.1, probaremos x86-64 binar, sistema de archivos en sección de prueba ext4 El resultado de fwrite sin establecer explícitamente el tamaño del búfer en esta prueba es 67.6 Mb / s, al configurar el búfer en 256 Kb la velocidad aumentó a 69.7 Mb / s. Ahora realizaremos mediciones similares para fwrite_unlocked - los resultados son 93.5 y 94.6 Mb / s, respectivamente. Variar el tamaño del búfer de 1 KB a 8 MB me llevó a las siguientes conclusiones: aumentar el búfer aumenta la velocidad de escritura, pero la diferencia en mi caso fue de solo 3 Mb / s, no noté ninguna diferencia de velocidad entre el búfer de 64 Kb y 8 Mb. De los datos recibidos en esta máquina Linux, podemos sacar las siguientes conclusiones:
- fwrite_unlocked es más rápido que fwrite, pero la diferencia en la velocidad de escritura no es tan grande como en Windows
- El tamaño del búfer en Linux no tiene un efecto tan significativo en la velocidad de escritura a través de fwrite / fwrite_unlocked como en Windows
En total, el método propuesto es efectivo tanto en Windows como en Linux (aunque en menor medida).
Epílogo
El propósito de este artículo era describir una técnica simple y efectiva en muchos casos (no encontré las funciones _fwrite_nolock / fwrite_unlocked anteriormente, no son muy populares, pero en vano). No pretendo ser nuevo en el material, pero espero que el artículo sea útil para la comunidad.