Lo más importante para el servicio Yandex.Zen es desarrollar y mantener una plataforma que conecte audiencias con los autores. Para ser una plataforma atractiva para buenos autores, Zen debe poder encontrar una audiencia relevante para los canales que escriben sobre cualquier tema, incluido el más estrecho. El jefe del grupo de felicidad de los autores, Boris Sharchilev, habló sobre la clasificación autocéntrica, que selecciona a los usuarios más relevantes para los autores. En el informe puede descubrir cómo este enfoque difiere de la selección de elementos relevantes, más populares en los sistemas de recomendación.
Al equilibrar la clasificación centrada en el usuario y la centrada automáticamente, podemos lograr el equilibrio correcto entre la felicidad del usuario y la felicidad de los autores.
- Colegas, hola a todos. Me llamo Borya Trato con la calidad de ranking en Zen. Estoy seguro de que este es uno de los servicios Yandex más interesantes, tenemos un aprendizaje automático muy bueno y en los próximos 17 minutos intentaré convencerlo de esto.
¿Qué es el zen? Si es bastante simple, Zen es un servicio de recomendación personal. Intentamos recomendar a los usuarios contenido relevante en función de lo que sabemos sobre los intereses de estos usuarios. Nuestro objetivo de alto nivel es que los usuarios pasen tiempo en Zen. Y lo que es muy importante es que no se arrepientan esta vez.
Nuestra forma básica de consumo de contenido se parece a esto. Este es un flujo interminable de recomendaciones. Y aquí está claro que, en principio, estamos tratando de recomendar materiales muy diferentes sobre temas muy diferentes. Hay diferentes temas: algo sobre negocios, algo sobre humor, incluso algo sobre fantasía. Es decir, en la cinta puede encontrar artículos educativos y educativos, así como artículos más entretenidos. Y, por supuesto, la personalización. El feed Zen para todos se ve diferente, dependiendo de lo que le interese al usuario. Además, por supuesto, un poco de publicidad.

Un punto muy importante. Al principio, cuando aparecimos, éramos, de hecho, un agregador de contenido de Internet. Es decir, recorrimos los sitios existentes, tomamos contenido de ellos y se lo mostramos al usuario según los intereses. Ahora la situación es diferente. Ahora Zen es una plataforma de blogs completa en la que todos pueden crear su propio canal, ya sea un blogger famoso o un autor novato que tiene algo que contar. Los nuevos autores ven una pantalla de bienvenida tan agradable en la que hablamos sobre el servicio, que el propio Zen seleccionará una audiencia, y solo necesita escribir buenos materiales.
Ahora la plataforma representa más de la mitad del tráfico total en Zen. Y esta cifra solo crecerá. Entendemos que todos pueden clasificar el contenido existente. Por supuesto, lo haremos lo mejor de todo. Pero no todos tienen contenido único, y creemos que esta será nuestra ventaja competitiva.

Es importante entender que el Zen ya es muy grande. Según Yandex.Radar, a fines del año pasado teníamos entre 10 y 12 millones de lectores diarios por día, alrededor de 35 millones de lectores diarios, e incluso según algunos datos de Yandex.Radar, el año pasado Por primera vez recorrieron la audiencia Yandex.News. Esto significa que estamos haciendo Internet con toda seriedad, tenemos tareas muy serias, hay muchas de ellas y realmente esperamos su ayuda.
Hablemos sobre los detalles de cómo funciona y discutamos qué podemos hacer con un interno, cómo podemos ayudar a nuestro servicio.
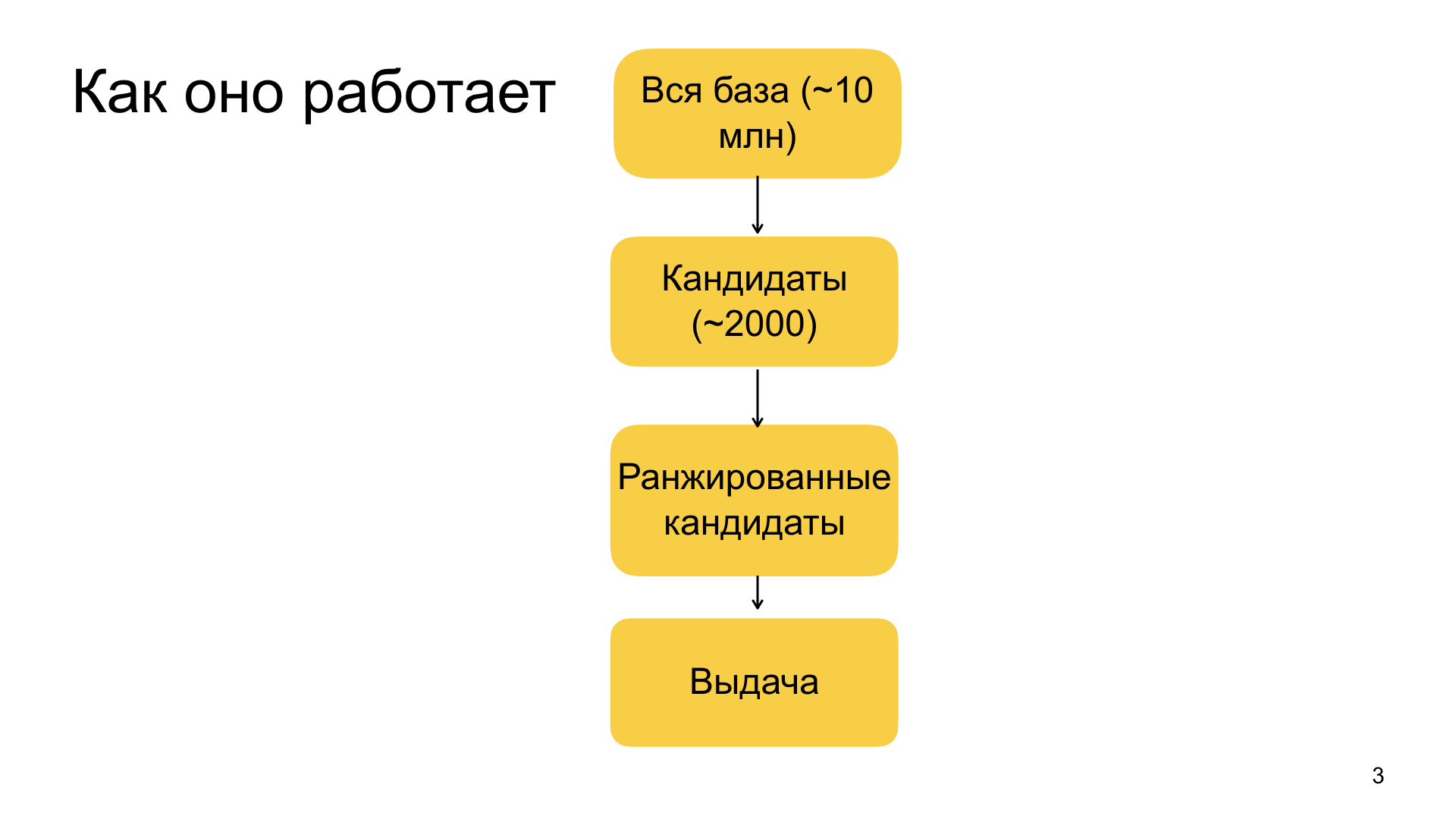
El esquema general de las recomendaciones que tenemos está organizado de esta manera. Todo comienza con nuestra gran base de datos de documentos de los cuales seleccionamos materiales para recomendaciones. Se compone de decenas de millones de documentos. Además, esta base de datos se repone constantemente: cada día llegan aproximadamente un millón de documentos nuevos. Idealmente, nos gustaría aplicar toda nuestra máquina de aprendizaje automático a todas estas decenas de millones de documentos personalmente para cada usuario, y elegir el más relevante para él. Pero, desafortunadamente, esto no funciona en la práctica, porque Zen es un servicio que funciona en tiempo real. Tenemos garantías muy estrictas sobre la rapidez con la que estamos listos para responder, por lo tanto, por razones prácticas, nos vemos obligados a reducir la base de decenas de millones de documentos a miles de recomendaciones potenciales en la primera etapa, que ya podemos clasificar completamente con nuestro modelo y elegir las más relevantes. Esta etapa de reducir la base de decenas de millones a aproximadamente miles se llama selección de candidatos o clasificación fácil.
Cuando tenemos este kit, aplicamos nuestro complejo modelo de aprendizaje automático grande, que en el nivel superior aumenta el gradiente. Todo esto sin sorpresas, pero tenemos factores muy diversos, desde algunos simples que caracterizan, por ejemplo, cuán relevante es el dominio para el usuario, la fuente, con qué frecuencia visita, hace clic, deja comentarios, me gusta y no me gusta. También lo son los factores más complejos que se basan, por ejemplo, en las características de la red neuronal. Procesamos el texto del artículo, procesamos imágenes, otras fuentes de datos y también utilizamos tales características compuestas. Todo este esquema es bastante complicado, no tendré tiempo para contarte en detalle.
Después de clasificar a nuestros 2 mil candidatos, seleccionamos los mejores de ellos. El tamaño de la parte superior depende de cuánto necesitemos recomendar materiales. Siempre se define de manera diferente. Y así formamos el problema final.
Así es como el circuito se ve a un alto nivel. Ahora hablemos sobre qué componentes de todo el proceso estamos interesados en mejorar.

Resulta que estamos interesados en hacer casi todo. Hay muchas tareas. Queremos aumentar la velocidad de entrega de datos para la clasificación: cuanto más recientes tenemos datos, más relevantes hacemos recomendaciones. Quiero acelerar el servicio: cuanto más rápido trabajemos, mejor será la experiencia del usuario. Queremos aumentar la fiabilidad del servicio.
Es importante para nosotros mejorar el ranking. Es decir, necesitamos aplicar nuevos modelos de aprendizaje automático y mejorar nuestros modelos actuales en otros países. Se nos recomienda no solo en Rusia, sino también en muchos otros países del mundo.
También queremos tener en cuenta la regionalidad y recomendar a las personas el contenido que se relaciona con su región.
Y es muy importante: necesitamos desarrollar nuestra plataforma de creación. Este es nuestro futuro, tenemos que invertir en él. También hay muchas tareas. En particular, necesitamos poder encontrar y lanzar contenido de calidad. Es importante para nosotros mostrar buenos materiales, no basura. Necesitamos poder clasificar nuevos formatos de contenido. No solo tenemos artículos, sino también videos cortos y publicaciones que los usuarios ven directamente en el feed. Todos estos formatos deben poder clasificarse.
Y un punto muy importante, del que quiero hablar con un poco más de detalle con más detalles técnicos: es importante para nosotros poder que cada autor encuentre una audiencia que sea relevante para él, incluso si se trata de autores y temas muy especializados. Hablemos con más detalle cuál es el problema aquí y cómo lo resolvemos.
Veamos un ejemplo.
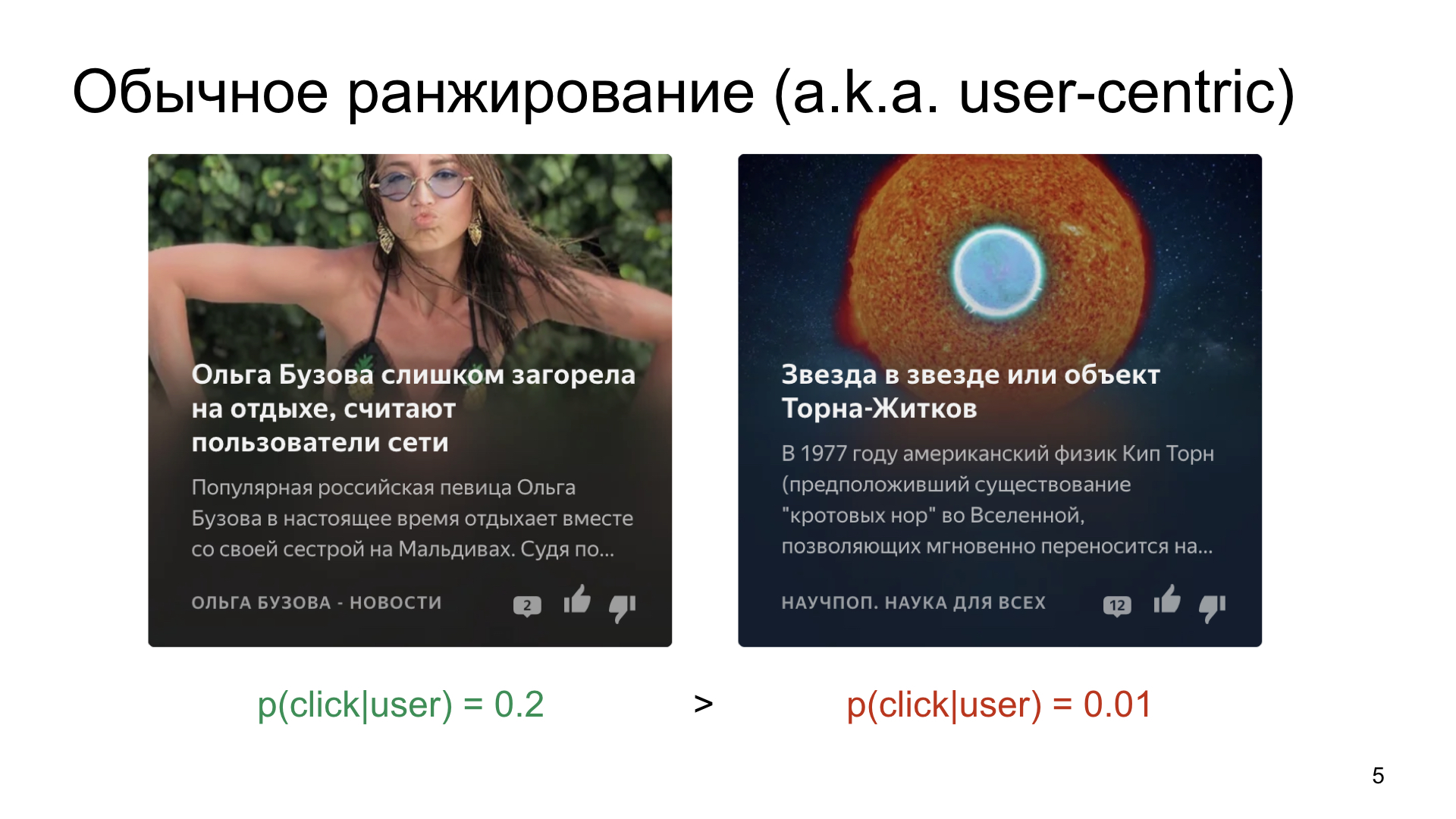
Seleccionamos, supongamos, de dos tarjetas que queremos mostrar al usuario.
Así es como funciona el mundo y la forma en que las personas trabajan, que hay algo más promedio, donde la probabilidad de un clic es en promedio 20 por ciento, y hay algo más específico, por ejemplo, artículos sobre ciencia o sobre espacio.
Si simplemente clasificamos las tarjetas de acuerdo con la probabilidad de un clic, entonces, por supuesto, un contenido más simple y cliqueable recogerá una gran cantidad de impresiones, e incluso un muy buen artículo sobre ciencia no lo hará. Por supuesto, no queremos esto. Queremos encontrar audiencias interesadas incluso para canales especializados.

¿Por qué quieres hacer esto? De hecho, hay dos razones. El primero es el supermercado. Es decir, queremos que el Zen sea una especie de corte de Internet. Para que todo lo que el usuario pueda encontrar y lo que le interesa en la gran Internet se presente en Zen. Y para que reciba lo que le interesa.
Los canales científicos tienen su propia audiencia. Pero hay tal matiz. Si los amantes de la ciencia muestran ciencia y contenido popular, es más probable que hagan clic en él que en ciencia. Pero si les muestras solo ciencia, también harán clic en ciencia, y ni siquiera se arrepentirán. La pregunta es cómo encontrar a esas personas y cómo mostrar contenido, centrándose no en el usuario, sino en el autor.

Como hacerlo La fórmula de clasificación habitual, que predice la probabilidad de clics, no nos ayudará aquí, porque en promedio se perderán más artículos de nicho. Pero puede ir hacia otro lado: asignar una determinada cuota y, en ella, dar impresiones a los autores de manera más o menos uniforme, darles una especie de garantía mínima. Esto se puede hacer, y esto hará que los autores estén un poco más felices, pero, desafortunadamente, esto hará que nuestros usuarios estén menos felices. Los usuarios harán clic menos, se enojarán más y se irán. Por supuesto, no queremos esto.
¿Cómo estar aquí?
Pensamos durante mucho tiempo y se nos ocurrió un nuevo concepto. Lo llamamos clasificaciones o impresiones autocéntricas para el autor.
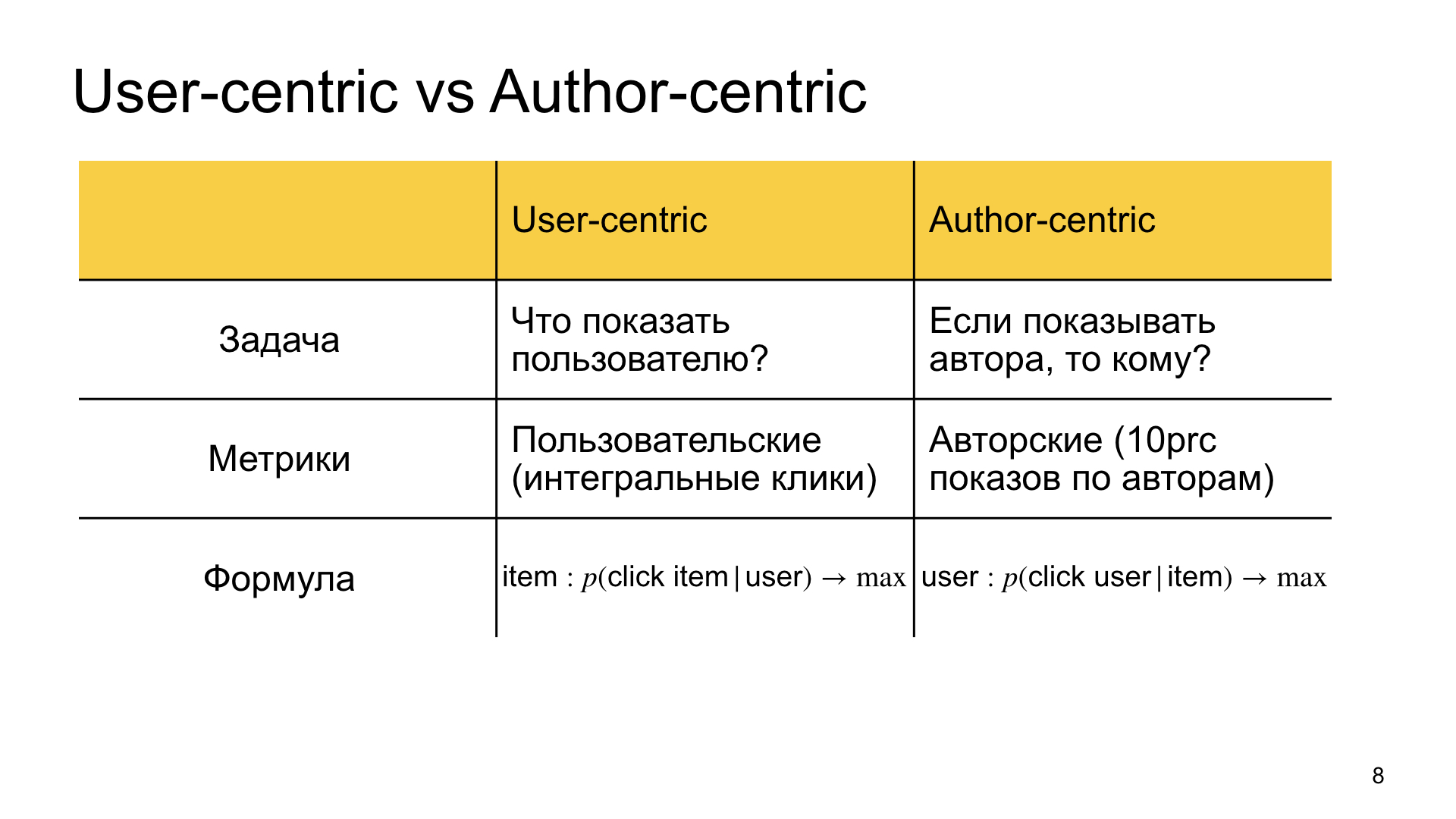
¿Cuál es nuestro objetivo en la clasificación regular, que llamamos centrado en el usuario? Encuentre el material que sea más relevante para el usuario. Respondemos la pregunta de qué mostrarle al usuario.
En la clasificación autocéntrica, volcamos el enunciado del problema y decimos que queremos mostrarle a este autor, y la pregunta es a quién mostrarle, a quién es más relevante. De ahí la diferencia en las métricas. En el primer caso, estamos más interesados en métricas personalizadas, es decir, clics integrales, tiempo integral en Zen, etc. En el segundo caso, estamos interesados en las llamadas métricas de autor. Por ejemplo, medimos qué tan bien vive el Zen, por ejemplo, el 10% inferior de los autores. Si viven lo suficientemente bien, entonces todos los demás también son felices.

¿Cómo hacemos esto? Supongamos que tenemos la fórmula de clasificación habitual. Para simplificar, suponga que predice la probabilidad de que un usuario haga clic en un elemento determinado, en una tarjeta determinada. Que haremos Ahora reparémoslo para cada artículo y apliquemos nuestro modelo para este artículo, idealmente, a todos los usuarios, en la práctica, a algún tipo de muestra de usuario. Y construiremos una distribución de nuestras puntuaciones, es decir, estimaciones de la probabilidad de que los usuarios hagan clic en un artículo para cada artículo. Ahora para cada artículo tenemos una distribución tal como en el gráfico (diapositiva arriba - aprox. Ed.). Después de eso, clasificaremos los artículos para el usuario y seleccionaremos la parte superior no solo por la probabilidad de un clic, sino por el percentil en el que este usuario cae para este artículo. Es decir, estimamos la probabilidad de un clic, vemos dónde cae el usuario en esta distribución y organizamos por este valor.

Aquí tenemos las mismas dos cartas, una de ellas es más clicable, 20%, la otra, menos del 1%. Ahora, si toma un usuario específico, tal situación es posible que tenga la posibilidad de hacer clic en una tarjeta más popular que en una menos popular, digamos, 10% versus 3%. Pero como la probabilidad promedio de hacer clic en una tarjeta popular es del 20%, y el usuario tiene el 10%, en promedio es menos relevante para esta publicación que el usuario Zen promedio. Y en otra situación, lo contrario: tiene un 3% de posibilidades de hacer clic, pero el artículo promedio tiene un 1%. Por lo tanto, es una audiencia promedio más relevante para el artículo que otros usuarios de Zen. Por lo tanto, la idea clave aquí es que incluso si la probabilidad de hacer clic en un artículo es menor, con la ayuda de dicho marco tenemos la oportunidad de mostrar un artículo menos popular si el usuario es el núcleo más confiable para esta publicación.

Si los usuarios se acercan a nosotros de manera más o menos uniforme, entonces la puntuación dada por la que clasificamos, es decir, el percentil en el que aterriza cada usuario, se distribuirá de manera uniforme entre los usuarios. Esto significa que si todos los artículos se clasifican de esta manera, todos recogerán más o menos la misma cantidad de impresiones. No habrá emisiones de decenas de millones de impresiones en comparación con 10 impresiones de algunas tarjetas menos relevantes. Por lo tanto, al equilibrar la clasificación centrada en el usuario y la centrada automáticamente, podemos lograr la proporción de felicidad del usuario y felicidad de los autores que consideramos correcta.
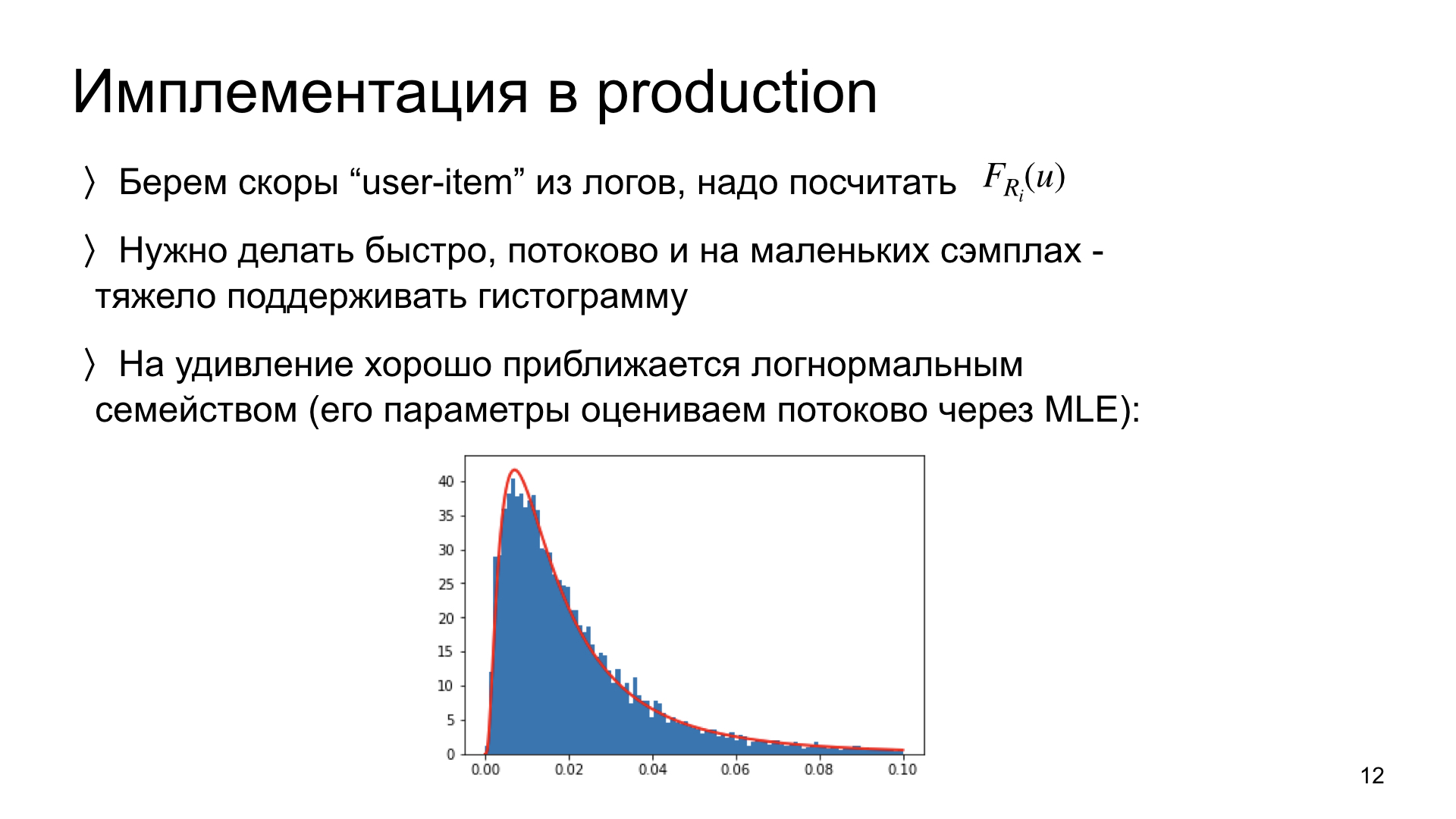
Algunas palabras sobre cómo implementamos esto en la producción. Necesitamos mirar nuestros registros y calcular la distribución de cada artículo a partir de ellos. Una limitación importante: necesitamos poder hacer esto, primero, rápido y segundo, en modo de transmisión. Es decir, idealmente, para actualizar la estimación de distribución de nuevos datos, necesitamos tener en memoria no todos los datos anteriores, sino solo la estimación actual. Tal sistema es escalable, tal esquema funciona. Idealmente, necesitamos poder hacer esto con datos pequeños. Si algún artículo tiene solo 300 impresiones, entonces debemos poder estimar adecuadamente la distribución para tal cantidad de observaciones.
Realizamos experimentos y descubrimos que tales distribuciones de puntajes son sorprendentemente cercanas a las distribuciones logarítmicas normales. Es decir, esta es una observación empírica. Y si es así, entonces, en lugar de estimar el histograma completo de la distribución de forma no paramétrica, podemos evaluar solo dos parámetros de esta distribución. Y podemos hacer esto en la secuencia, utilizando solo la estimación del parámetro actual y nuevas observaciones. Tal esquema es muy rápido y funciona muy bien. Ahora ella está en producción con nosotros.
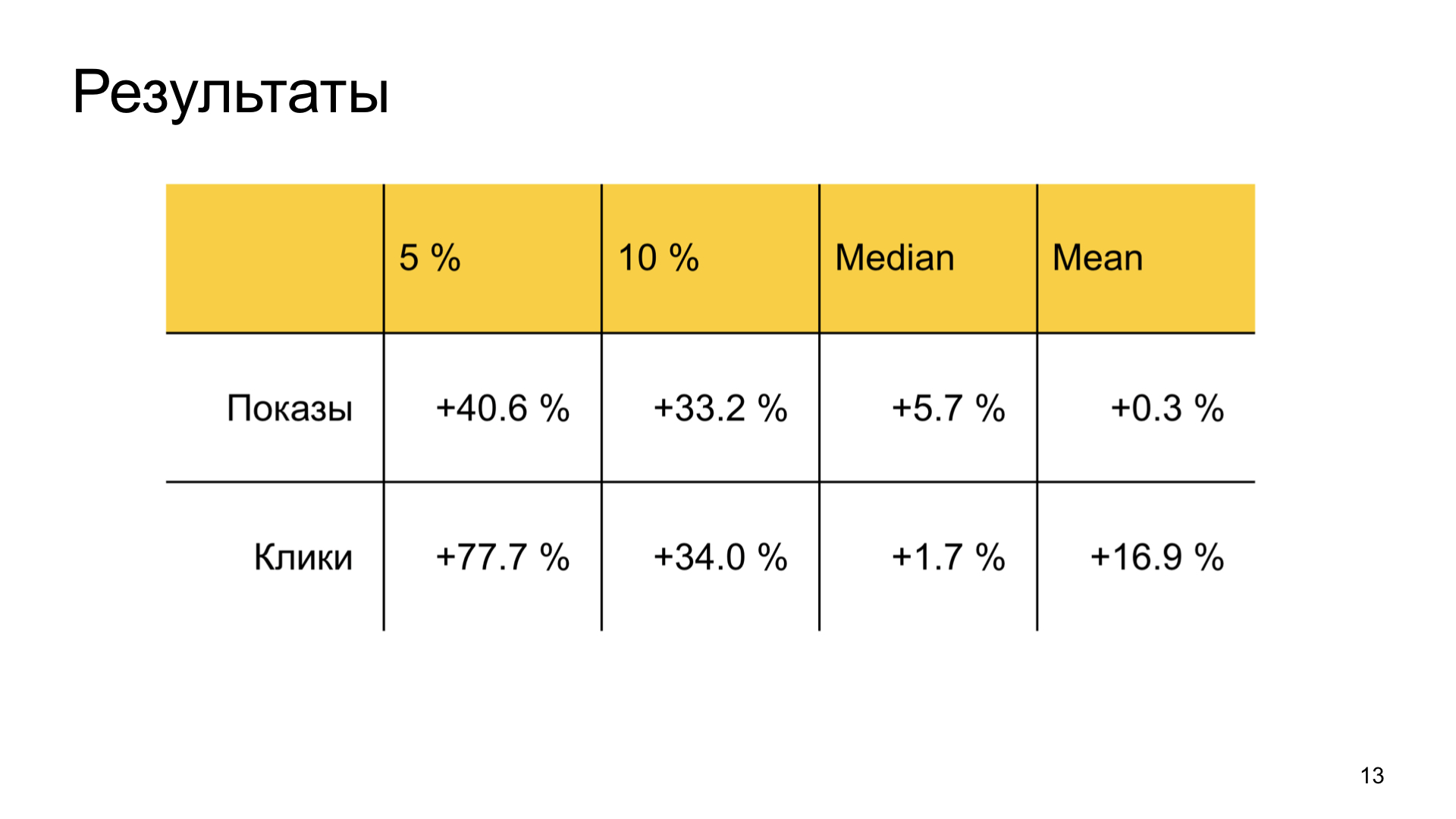
Los resultados también son buenos. Aumentamos enormemente la felicidad de los buenos autores descuidados en Zen y no desperdiciamos las métricas comunes de los usuarios. Es decir, la tarea empresarial se logra por completo.
Ahora he mostrado uno de los ejemplos de tareas con las que podemos lidiar. Por supuesto, hay muchas de estas tareas, y con cada una de ellas necesitamos su ayuda. Realmente esperamos que quieras
trabajar con nosotros . Al final, diré algunas palabras sobre lo que esperamos de los pasantes y lo que no esperamos de ellos. Del aprendiz, esperamos lo más importante: la capacidad de escribir código. No tenemos científicos puros en el servicio. Todos somos ingenieros de ML, deben poder realizar el ciclo completo de tareas. Deben ser capaces e implementar su solución en producción, y aplicar ML. Es decir, esperamos que pueda escribir código a un nivel básico, comprender los enfoques, conocer los algoritmos, las estructuras de datos, los conceptos básicos del aprendizaje automático.
¿Qué no esperamos de los pasantes? En primer lugar, no esperamos un conocimiento profundo de ningún idioma o marco. Es decir, si no sabe cómo funcionan las corutinas en Python, está bien, le enseñaremos todo. Y no esperamos mucha experiencia de usted. Esperamos conocimiento de usted, un deseo de trabajar. Si no hay experiencia, está bien. Enseñaremos todo, y todo estará bien. Gracias