Para aquellos que son demasiado flojos para leer todo: se sugiere una refutación de siete mitos populares, que en el campo de la investigación del aprendizaje automático a menudo se considera cierto, a partir de febrero de 2019. Este artículo está disponible en
el sitio web de ArXiv en formato pdf [en inglés].
Mito 1: TensorFlow es una biblioteca tensorial.
Mito 2: Las bases de datos de imágenes reflejan fotos reales encontradas en la naturaleza.
Mito 3: Los investigadores de MO no usan kits de prueba para realizar pruebas.
Mito 4: el entrenamiento de redes neuronales utiliza todos los datos de entrada.
Mito 5: Se requiere la normalización de lotes para entrenar redes residuales muy profundas.
Mito 6: Las redes con atención son mejores que la convolución.
Mito 7: Los mapas de significancia son una forma confiable de interpretar redes neuronales.
Y ahora para los detalles.
Mito 1: TensorFlow es una biblioteca tensorial
De hecho, esta es una biblioteca para trabajar con matrices, y esta diferencia es muy significativa.
En el
cálculo de derivados de orden superior de expresiones de matriz y tensoriales. Laue y col. Los autores de
NeurIPS 2018 demuestran que su biblioteca de diferenciación automática, basada en cálculo de tensor real, tiene árboles de expresión mucho más compactos. El hecho es que el cálculo del tensor utiliza la notación de índice, que le permite trabajar igualmente con los modos directo e inverso.
La numeración matricial oculta los índices por conveniencia de la notación, por lo que los árboles de expresión de diferenciación automática a menudo se vuelven demasiado complejos.
Considere la multiplicación matricial C = AB. Tenemos
para modo directo y
por lo contrario Para realizar correctamente la multiplicación, debe observar estrictamente el orden y el uso de la separación silábica. Desde el punto de vista de la grabación, esto parece confuso para una persona involucrada en MO, pero desde el punto de vista de los cálculos, esta es una carga adicional para el programa.
Otro ejemplo, menos trivial: c = det (A). Tenemos
para modo directo y
por lo contrario En este caso, obviamente es imposible usar el árbol de expresión para ambos modos, dado que consisten en operadores diferentes.
En general, la forma en que TensorFlow y otras bibliotecas (por ejemplo, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) implementaron la diferenciación automática, lo que lleva al hecho de que para directo e inverso Los árboles de expresión diferentes e ineficaces se construyen en el modo. La numeración del tensor evita estos problemas debido a la conmutatividad de la multiplicación debido a la notación de índice. Para detalles sobre cómo funciona esto, vea el artículo científico.
Los autores probaron su método realizando una diferenciación automática del régimen inverso, también conocido como propagación inversa, en tres tareas diferentes, y midieron el tiempo que tomó calcular las Hesse.

En el primer problema, se optimizó la función cuadrática x
T Ax. En el segundo, se calculó la regresión logística, en el tercero - factorización matricial.
En la CPU, su método resultó ser dos órdenes de magnitud más rápido que las bibliotecas populares como TensorFlow, Theano, PyTorch y HIPS autograd.
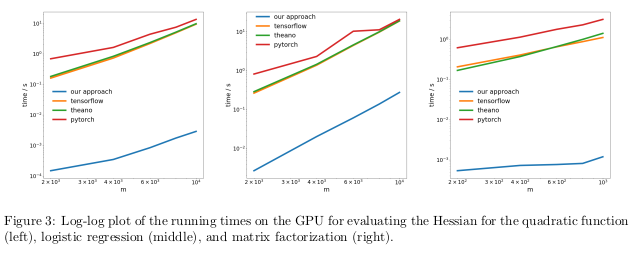
En la GPU, observaron una aceleración aún mayor, de hasta tres órdenes de magnitud.
Las consecuencias:Calcular derivados para funciones de segundo o mayor orden utilizando las bibliotecas actuales de aprendizaje profundo es demasiado costoso desde un punto de vista computacional. Esto incluye el cálculo de los tensores generales de cuarto orden como los Hessianos (por ejemplo, en MAML y la optimización de segundo orden de Newton). Afortunadamente, las fórmulas cuadráticas son raras en el aprendizaje profundo. Sin embargo, a menudo se encuentran en el aprendizaje automático "clásico":
SVM , método de mínimos cuadrados, LASSO, procesos gaussianos, etc.
Mito 2: las bases de datos de imágenes reflejan fotos del mundo real
A muchas personas les gusta pensar que las redes neuronales han aprendido a reconocer objetos mejor que las personas. Esto no es asi. Pueden estar por delante de las personas en las bases de imágenes seleccionadas, por ejemplo, ImageNet, pero en el caso del reconocimiento de objetos de fotos reales de la vida cotidiana, definitivamente no podrán adelantar a un adulto común. Esto se debe a que la selección de imágenes en los conjuntos de datos actuales no coincide con la selección de todas las imágenes posibles que se encuentran naturalmente en la realidad.
En un trabajo bastante antiguo, Un
vistazo imparcial al sesgo del conjunto de datos. Torralba y Efros. CVPR 2011. , Los autores propusieron estudiar las distorsiones asociadas con un conjunto de imágenes en doce bases de datos populares, descubriendo si es posible entrenar al clasificador para determinar el conjunto de datos del que se tomó esta imagen.

Las posibilidades de adivinar accidentalmente el conjunto de datos correcto son 1/12 ≈ 8%, mientras que los propios científicos hicieron frente a la tarea con una tasa de éxito de> 75%.
Entrenaron SVM en un
histograma de gradiente direccional (HOG) y descubrieron que el clasificador completó la tarea en el 39% de los casos, lo que excede significativamente los golpes aleatorios. Si repetimos este experimento hoy, con las redes neuronales más avanzadas, seguramente veríamos un aumento en la precisión del clasificador.
Si las bases de datos de imágenes muestran correctamente las imágenes verdaderas del mundo real, no tendríamos que poder determinar de qué conjunto de datos proviene una imagen en particular.

Sin embargo, hay rasgos en los datos que hacen que cada conjunto de imágenes sea diferente de las demás. ImageNet tiene muchos autos de carrera que es poco probable que describan el auto promedio "teórico" en su conjunto.

Los autores también determinaron el valor de cada conjunto de datos midiendo qué tan bien funciona un clasificador entrenado en un conjunto con imágenes de otros conjuntos. De acuerdo con esta métrica, las bases de datos LabelMe e ImageNet resultaron ser las menos sesgadas, habiendo recibido una calificación de 0.58 utilizando el método de "canasta de divisas". Todos los valores resultaron ser inferiores a la unidad, lo que significa que la capacitación en un conjunto de datos diferente siempre conduce a un bajo rendimiento. En un mundo ideal sin conjuntos sesgados, algunos números deberían haber excedido uno.
Los autores concluyeron pesimistamente:
Entonces, ¿cuál es el valor de los conjuntos de datos existentes para algoritmos de entrenamiento diseñados para el mundo real? La respuesta resultante se puede describir como "mejor que nada pero no mucho".
Mito 3: los investigadores de MO no usan kits de prueba para las pruebas
En el libro de texto sobre aprendizaje automático, se nos enseña a dividir el conjunto de datos en capacitación, evaluación y verificación. La efectividad del modelo, entrenado en el conjunto de entrenamiento y evaluado en la evaluación, ayuda a la persona involucrada en el MO a ajustar el modelo para maximizar la eficiencia en su uso real. No es necesario tocar el conjunto de prueba hasta que la persona termine de ajustarse para proporcionar una evaluación imparcial de la efectividad real del modelo en el mundo real. Si una persona hace trampa usando un conjunto de pruebas en las etapas de capacitación o evaluación, el modelo corre el riesgo de adaptarse demasiado a un conjunto de datos en particular.
En el mundo hipercompetitivo de la investigación de MO, los nuevos algoritmos y modelos a menudo se juzgan por la efectividad de su trabajo con los datos de verificación. Por lo tanto, no tiene sentido que los investigadores escriban o publiquen documentos que describan métodos que funcionan mal con los conjuntos de datos de prueba. Y esto, en esencia, significa que la comunidad de la Región de Moscú en su conjunto utiliza un conjunto de pruebas para la evaluación.
¿Cuáles son las consecuencias de esta estafa?

Autores de
¿Los clasificadores CIFAR-10 se generalizan a CIFAR-10? Recht y col. ArXiv 2018 investigó este problema creando un nuevo conjunto de pruebas para CIFAR-10. Para hacer esto, hicieron una selección de imágenes de Tiny Images.
Eligieron CIFAR-10 porque es uno de los conjuntos de datos más utilizados en el MO, el segundo conjunto más popular en NeurIPS 2017 (después de MNIST). El proceso de creación de un conjunto de datos para CIFAR-10 también está bien descrito y es transparente, en la gran base de datos de Tiny Images hay muchas etiquetas detalladas, por lo que puede reproducir un nuevo conjunto de prueba, minimizando el cambio de distribución.

Descubrieron que una gran cantidad de modelos diferentes de redes neuronales en el nuevo conjunto de prueba mostraron una caída significativa en la precisión (4% - 15%). Sin embargo, el rango de rendimiento relativo de cada modelo se mantuvo bastante estable.
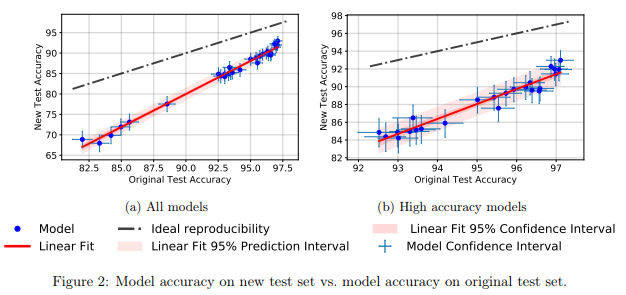
En general, los modelos con mejor rendimiento mostraron una menor caída de precisión en comparación con los de peor rendimiento. Esto es bueno porque se deduce que la pérdida de generalización del modelo debido al engaño, al menos en el caso de CIFAR-10, disminuye a medida que la comunidad inventa métodos y modelos de MO mejorados.
Mito 4: el entrenamiento de la red neuronal utiliza todas las entradas
En general, se acepta que los
datos son un nuevo petróleo y que cuantos más datos tengamos, mejor podremos capacitar modelos de aprendizaje profundo que ahora son ineficientes en la muestra y están sobrepatrizados.
En
un estudio empírico de ejemplos de olvido durante el aprendizaje de redes neuronales profundas. Toneva y col. Los autores de
ICLR 2019 demuestran una redundancia significativa en varios conjuntos comunes de imágenes pequeñas. Sorprendentemente, el 30% de los datos de CIFAR-10 simplemente se pueden eliminar sin cambiar la precisión del cheque en una cantidad significativa.
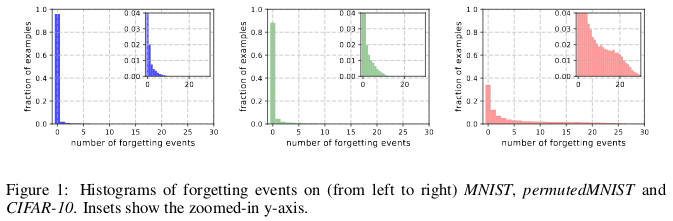 Historias de olvido de (izquierda a derecha) MNIST, permutedMNIST y CIFAR-10.
Historias de olvido de (izquierda a derecha) MNIST, permutedMNIST y CIFAR-10.El olvido ocurre cuando una red neuronal clasifica incorrectamente una imagen en el tiempo t + 1, mientras que en el tiempo t pudo clasificar correctamente una imagen. El flujo de tiempo se mide mediante actualizaciones SGD. Para rastrear el olvido, los autores lanzaron su red neuronal en un pequeño conjunto de datos después de cada actualización de SGD, y no en todos los ejemplos disponibles en la base de datos. Los ejemplos que no están sujetos al olvido se llaman ejemplos inolvidables.
Descubrieron que 91.7% MNIST, 75.3% permutedMNIST, 31.3% CIFAR-10 y 7.62% CIFAR-100 son ejemplos inolvidables. Esto es intuitivamente comprensible, ya que aumentar la diversidad y la complejidad del conjunto de datos debería hacer que la red neuronal olvide más ejemplos.

Los ejemplos olvidables parecen exhibir características más raras y extrañas en comparación con las inolvidables. Los autores los comparan con los vectores de soporte en SVM, ya que parecen dibujar el contorno de los límites de decisión.
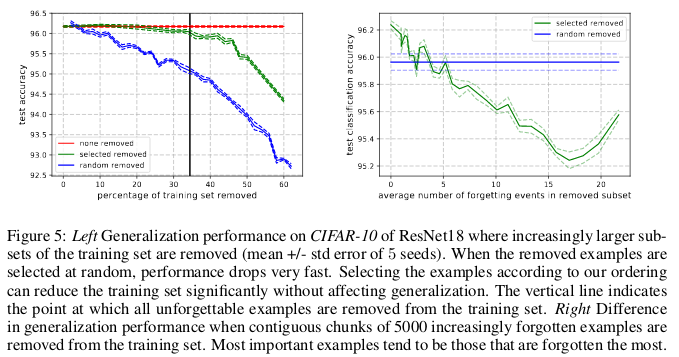
Ejemplos inolvidables, a su vez, codifican principalmente información redundante. Si clasificamos los ejemplos por el grado de inolvidabilidad, podemos comprimir el conjunto de datos eliminando los más inolvidables.
El 30% de los datos de CIFAR-10 se pueden eliminar sin afectar la precisión de las verificaciones, y la eliminación del 35% de los datos conduce a una ligera caída en la precisión de las verificaciones en un 0.2%. Si selecciona el 30% de los datos al azar, eliminarlos conducirá a una pérdida significativa en la precisión de la verificación del 1%.
Del mismo modo, el 8% de los datos se pueden eliminar del CIFAR-100 sin disminuir la precisión de la validación.
Estos resultados muestran que existe una redundancia significativa en los datos para el entrenamiento de redes neuronales, similar al entrenamiento SVM, donde los vectores no compatibles pueden eliminarse sin afectar la decisión del modelo.
Las consecuencias:Si podemos determinar cuál de los datos es inolvidable antes de comenzar el entrenamiento, entonces podemos ahorrar espacio eliminándolos y tiempo sin usarlos al entrenar una red neuronal.
Mito 5: Se requiere la normalización de lotes para entrenar redes residuales muy profundas.
Durante mucho tiempo se creyó que "entrenar una red neuronal profunda para la optimización directa solo para un propósito controlado (por ejemplo, la probabilidad logarítmica de una clasificación correcta) usando el descenso de gradiente, comenzando con parámetros aleatorios, no funciona bien".
El montón de métodos ingeniosos de inicialización aleatoria, funciones de activación, técnicas de optimización y otras innovaciones, como las conexiones residuales, que han aparecido desde entonces, facilitaron el entrenamiento de redes neuronales profundas utilizando el método de descenso de gradiente.
Pero se produjo un avance real después de la introducción de la normalización por lotes (y otras técnicas de normalización secuencial), limitando el tamaño de las activaciones para cada capa de la red a fin de eliminar el problema de la desaparición y los gradientes explosivos.
En un trabajo reciente,
Arreglo de inicialización: aprendizaje residual sin normalización. Zhang y col. ICLR 2019 ha demostrado que es posible entrenar una red con 10,000 capas usando SGD puro sin aplicar ninguna normalización.

Los autores compararon el entrenamiento residual de la red neuronal para diferentes profundidades en CIFAR-10 y descubrieron que si bien los métodos de inicialización estándar no funcionaban para 100 capas, los métodos de reparación y normalización por lotes tuvieron éxito con 10,000 capas.

Llevaron a cabo un análisis teórico y mostraron que "la normalización del gradiente de ciertas capas está limitada por el número que aumenta infinitamente desde una red profunda", que es un problema de gradientes explosivos. Para evitar esto, se usa Foxup, cuya idea clave es escalar los pesos en m capas para cada una de las ramas residuales L por el número de veces dependiendo de my L.

La reparación ayudó a entrenar una red residual profunda con 110 capas en el CIFAR-10 con una alta velocidad de aprendizaje comparable al comportamiento de una red de arquitectura similar entrenada usando la normalización por lotes.
Los autores mostraron resultados de prueba similares utilizando Fixup en la red sin ninguna normalización, trabajando con la base de datos ImageNet y con traducciones del inglés al alemán.
Mito 6: Las redes con atención son mejores que las convolucionales.
La idea de que los mecanismos de "atención" son superiores a las redes neuronales convolucionales está ganando popularidad en la comunidad de investigadores de MO. En el trabajo de
Vaswani y sus colegas , se observó que "el costo computacional de las convoluciones desmontables es igual a la combinación de una capa de auto atención y una capa de retroalimentación puntual".
Incluso las redes competitivas generativas avanzadas muestran la ventaja de la auto-atención sobre la convolución estándar al modelar dependencias de largo alcance.
Los contribuyentes
prestan menos atención con convoluciones ligeras y dinámicas. Wu y col. ICLR 2019 arroja dudas sobre la eficiencia paramétrica y la efectividad de la auto atención al modelar dependencias de largo alcance, y ofrece nuevas opciones de convolución, parcialmente inspiradas en la auto atención, más efectivas en términos de parámetros.
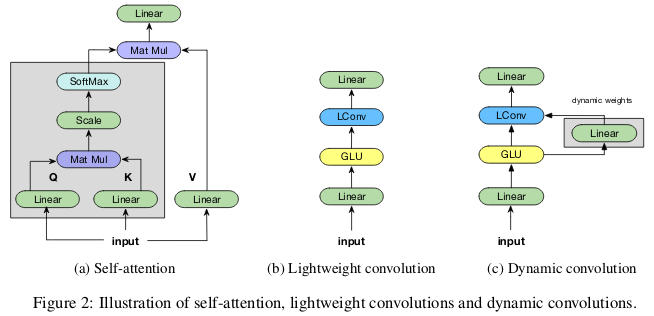
Las circunvoluciones "ligeras" son separables en profundidad, softmax normalizadas en dimensión de tiempo, separadas por peso en dimensión de canal y reutilizan los mismos pesos en cada paso de tiempo (como redes neuronales recurrentes). Las convoluciones dinámicas son ligeras que usan pesos diferentes en cada paso de tiempo.
Tales trucos hacen que las convoluciones ligeras y dinámicas sean varias veces más efectivas que las convoluciones indivisibles estándar.

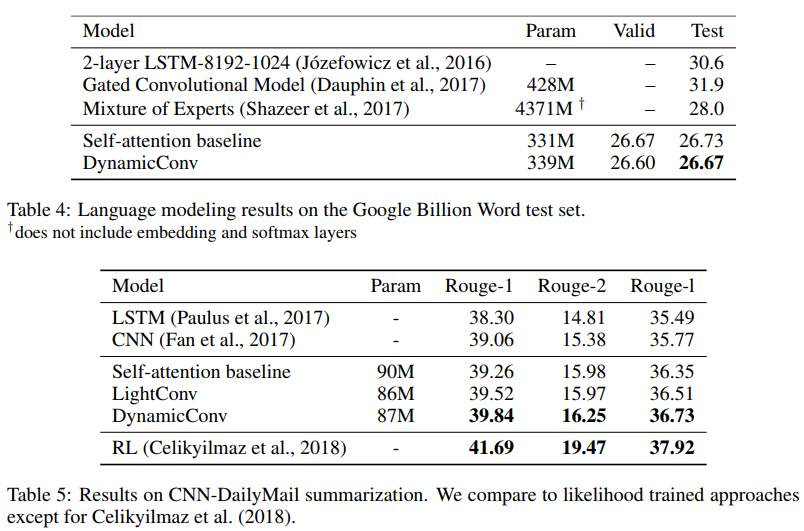
Los autores muestran que estas nuevas convoluciones corresponden o exceden las redes autoabsorbentes en la traducción automática, el modelado del lenguaje, los problemas de suma abstracta, utilizando los mismos o menos parámetros.
Mito 7: Tarjetas de importancia: una forma confiable de interpretar redes neuronales
Aunque existe la opinión de que las redes neuronales son cajas negras, ha habido muchos intentos de interpretarlas. Los más populares son los mapas de significancia u otros métodos similares que asignan evaluaciones de importancia a características o ejemplos de capacitación.
Es tentador poder concluir que una imagen dada ha sido clasificada de cierta manera debido a ciertas partes de la imagen que son significativas para la red neuronal. Para calcular los mapas de significancia, existen varios métodos que a menudo utilizan la activación de redes neuronales en una imagen determinada y los gradientes que pasan por la red.
En la
interpretación de las redes neuronales es frágil. Ghorbani y col. Los autores de
AAAI 2019 muestran que pueden introducir un cambio escurridizo en la imagen, que, sin embargo, distorsionará su mapa de importancia.

La red neuronal determina la mariposa monarca no por el patrón en sus alas, sino por la presencia de hojas verdes sin importancia en el fondo de la foto.

Las imágenes multidimensionales a menudo están más cerca de los límites de decisión establecidos por las redes neuronales profundas, de ahí su sensibilidad a los ataques adversos. Y si los ataques competitivos mueven las imágenes más allá de los límites de la solución, los ataques interpretativos competitivos los desplazan a lo largo del límite de la solución sin abandonar el territorio de la misma solución.
El método básico desarrollado por los autores es una modificación del método Goodfello de marcado rápido de gradiente, que fue uno de los primeros métodos exitosos de ataques competitivos. Se puede suponer que otros ataques más nuevos y más complejos también se pueden usar para ataques a la interpretación de redes neuronales.
Las consecuencias:Debido a la creciente difusión del aprendizaje profundo en áreas críticas de aplicación como la imagen médica, es importante abordar cuidadosamente la interpretación de las decisiones tomadas por las redes neuronales. Por ejemplo, aunque sería genial si la red neuronal convolucional pudiera reconocer la mancha en la imagen de MRI como un tumor maligno, no se debe confiar en estos resultados si se basan en métodos de interpretación poco confiables.