Esta es la segunda parte de una serie de artículos sobre sistemas analíticos (
enlace a la parte 1 ).

Hoy no hay duda de que el procesamiento preciso de datos y la interpretación de los resultados pueden ayudar a casi cualquier tipo de negocio. En este sentido, los sistemas analíticos están cada vez más cargados de parámetros, el número de disparadores y eventos de usuarios en las aplicaciones está creciendo.
Debido a esto, las compañías dan a sus analistas más y más información "en bruto" para su análisis y la convierten en las decisiones correctas. No se debe subestimar la importancia de un sistema de análisis para una empresa, y el sistema en sí debe ser confiable y sostenible.
Analítica de clientes
La analítica del cliente es un servicio que una empresa conecta a su sitio web o aplicación a través del SDK oficial, se integra en su propia base de código y selecciona activadores de eventos. Este enfoque tiene un inconveniente obvio: todos los datos recopilados no se pueden procesar completamente como lo desea, debido a las limitaciones de cualquier servicio seleccionado. Por ejemplo, en un sistema no será fácil ejecutar tareas de MapReduce, en otro no podrá ejecutar su modelo. Otro inconveniente será una factura regular (impresionante) por los servicios.
Existen muchas soluciones de análisis de clientes en el mercado, pero tarde o temprano, los analistas se enfrentan al hecho de que no existe un servicio universal adecuado para cualquier tarea (mientras que los precios de todos estos servicios están en constante crecimiento). En esta situación, las empresas a menudo deciden crear su propio sistema de análisis con todas las configuraciones y capacidades personalizadas necesarias.
Analítica del servidor
La analítica del servidor es un servicio que se puede implementar internamente en una empresa en sus propios servidores y (generalmente) por sus propios esfuerzos. En este modelo, todos los eventos de los usuarios se almacenan en servidores internos, lo que permite a los desarrolladores probar diferentes bases de datos para el almacenamiento y elegir la arquitectura más conveniente. E incluso si todavía desea utilizar análisis de clientes de terceros para algunas tareas, aún será posible.
La analítica del servidor se puede implementar de dos maneras. Primero: seleccione algunas utilidades de código abierto, despliéguelas en sus máquinas y desarrolle la lógica empresarial.
| Pros | Contras |
| Puedes personalizar cualquier cosa | A menudo es muy difícil y se necesitan desarrolladores individuales. |
Segundo: tome los servicios SaaS (Amazon, Google, Azure) en lugar de implementarlo usted mismo. Sobre SaaS con más detalle lo diremos en la tercera parte.
| Pros | Contras |
| Puede ser más barato en volúmenes medianos, pero con un gran crecimiento aún será demasiado caro. | No se pueden controlar todos los parámetros. |
| La administración se transfiere completamente a los hombros del proveedor del servicio. | No siempre se sabe qué hay dentro del servicio (puede que no sea necesario) |
Cómo recopilar análisis del servidor
Si queremos alejarnos del uso de análisis de clientes y armar el nuestro, primero debemos pensar en la arquitectura del nuevo sistema. A continuación, paso a paso, le diré qué considerar, por qué se necesita cada uno de los pasos y qué herramientas puede usar.
1. Adquisición de datos
Al igual que en el caso de la analítica de clientes, en primer lugar, los analistas de la compañía eligen los tipos de eventos que desean estudiar en el futuro y los recopilan en una lista. Por lo general, estos eventos tienen lugar en un cierto orden, que se llama el "patrón de eventos".
Luego, imagine que una aplicación móvil (sitio web) tiene usuarios regulares (dispositivos) y muchos servidores. Para transferir eventos de forma segura desde dispositivos a servidores, se necesita una capa intermedia. Dependiendo de la arquitectura, pueden ocurrir varias colas de eventos diferentes.
Apache Kafka es una
cola de pub / sub que se utiliza como cola para recopilar eventos.
Según una publicación en Kvor en 2014, el creador de Apache Kafka decidió nombrar el software después de Franz Kafka porque "es un sistema optimizado para la grabación" y porque amaba las obras de Kafka. - Wikipedia
En nuestro ejemplo, hay muchos productores de datos y sus consumidores (dispositivos y servidores), y Kafka ayuda a conectarlos entre sí. Los consumidores se describirán con más detalle en los próximos pasos, donde serán los actores principales. Ahora consideraremos solo los productores de datos (eventos).
Kafka encapsula los conceptos de cola y partición; más específicamente, es mejor leer sobre esto en otro lugar (por ejemplo, en la
documentación ). Sin entrar en detalles, imagine que se lanza una aplicación móvil para dos sistemas operativos diferentes. Luego, cada versión crea su propia secuencia de eventos por separado. Los productores envían eventos a Kafka, se graban en una cola adecuada.
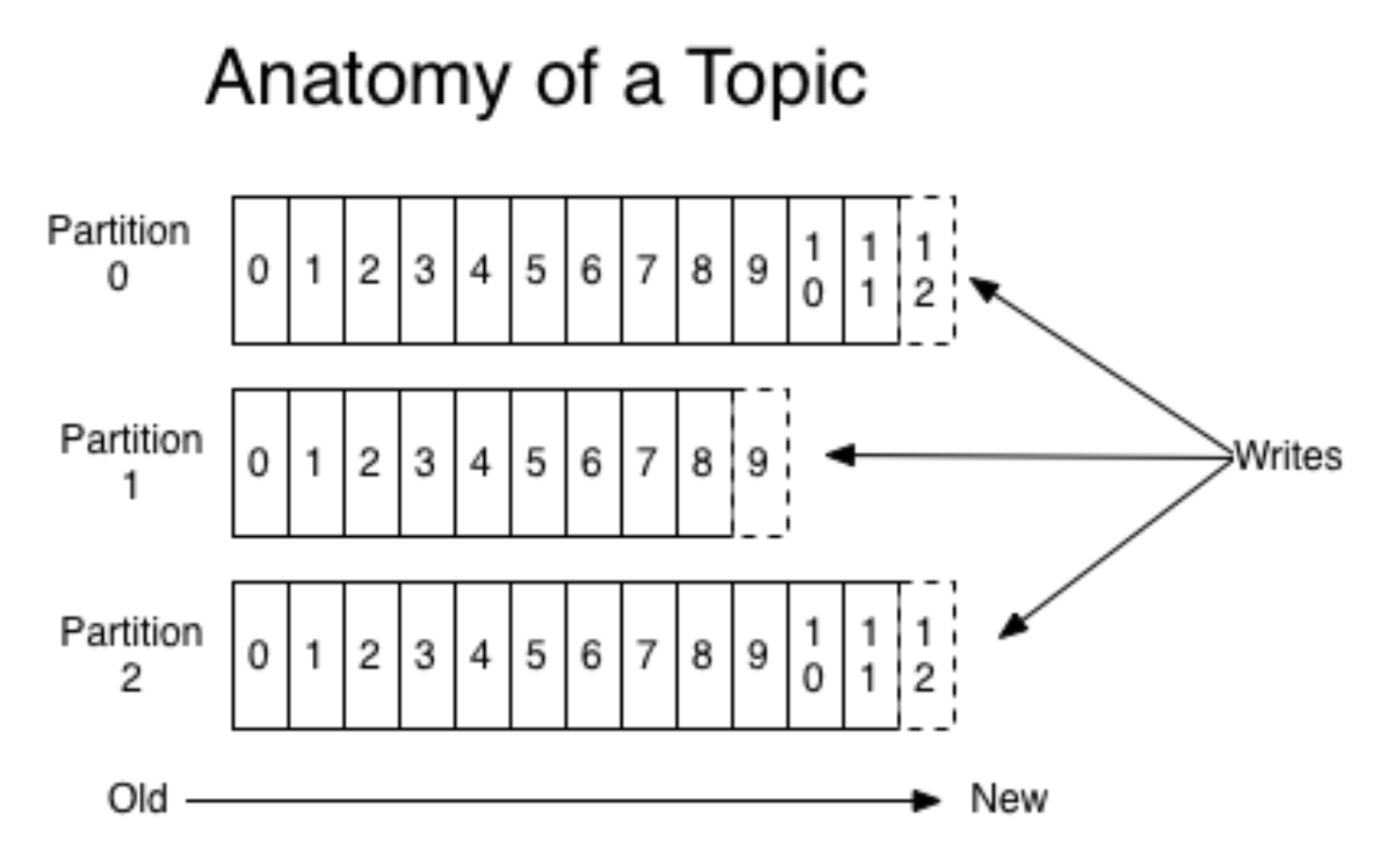
(foto
de aquí )
Al mismo tiempo, Kafka te permite leer en pedazos y procesar el flujo de eventos con mini-murciélagos. Kafka es una herramienta muy conveniente que se adapta bien a las necesidades crecientes (por ejemplo, por geolocalización de eventos).
Por lo general, un fragmento es suficiente, pero las cosas se vuelven más difíciles debido a la escala (como siempre). Probablemente nadie querrá usar solo un fragmento físico en la producción, ya que la arquitectura debe ser tolerante a fallas. Además de Kafka, hay otra solución bien conocida: RabbitMQ. No lo usamos en producción como una cola para el análisis de eventos (si tienes esa experiencia, ¡cuéntanoslo en los comentarios!). Sin embargo, utilizaron AWS Kinesis.
Antes de pasar al siguiente paso, debemos mencionar una capa adicional del sistema: el almacenamiento de registros sin procesar. Esta no es una capa requerida, pero será útil si algo sale mal y las colas de eventos en Kafka se restablecen. El almacenamiento de registros sin procesar no requiere una solución complicada y costosa; simplemente puede grabarlos en algún lugar en el orden correcto (incluso en un disco duro).

2. Procesamiento de flujos de eventos
Después de preparar todos los eventos y colocarlos en colas adecuadas, procedemos al paso de procesamiento. Aquí hablaré sobre las dos opciones de procesamiento más comunes.
La primera opción es habilitar Spark Streaming en un sistema Apache. Todos los productos de Apache viven en HDFS, un sistema seguro de réplica de archivos. Spark Streaming es una herramienta fácil de usar que procesa la transmisión de datos y escala bien. Sin embargo, puede ser un poco difícil de mantener.
Otra opción es crear su propio controlador de eventos. Para hacer esto, por ejemplo, debe escribir una aplicación Python, compilarla en la ventana acoplable y suscribirse a la cola Kafka. Cuando los disparadores llegan a los controladores en la ventana acoplable, se iniciará el procesamiento. Con este método, debe seguir ejecutando aplicaciones constantemente.
Supongamos que hemos elegido una de las opciones descritas anteriormente y procedemos al procesamiento en sí. Los procesadores deben comenzar verificando la validez de los datos, filtrando basura y eventos "rotos". Para la validación usualmente usamos
Cerberus . Después de eso, puede hacer un mapeo de datos: los datos de diferentes fuentes se normalizan y estandarizan para agregarse a la etiqueta general.
3. Base de datos
El tercer paso es mantener los eventos normalizados. Cuando trabajemos con un sistema analítico listo, a menudo tendremos que contactarlos, por lo que es importante elegir una base de datos conveniente.
Si los datos se ajustan bien a un esquema fijo, puede elegir
Clickhouse o alguna otra base de datos de columnas. Entonces las agregaciones funcionarán muy rápidamente. La desventaja es que el esquema está rígidamente fijo y, por lo tanto, el plegado de objetos arbitrarios sin refinamiento fallará (por ejemplo, cuando ocurre un evento no estándar). Pero puedes contar muy rápido.
Para datos no estructurados, puede tomar NoSQL, por ejemplo,
Apache Cassandra . Funciona en HDFS, está bien replicado, puede generar muchas instancias, tolerante a fallas.
Puede elegir algo más simple, por ejemplo,
MongoDB . Es bastante lento y para pequeños volúmenes. Pero la ventaja es que es muy simple y, por lo tanto, adecuado para comenzar.
4. Agregaciones
Habiendo guardado cuidadosamente todos los eventos, queremos recopilar toda la información importante del lote que vino y actualizar la base de datos. A nivel mundial, queremos obtener cuadros de mando y métricas relevantes. Por ejemplo, desde eventos para recopilar un perfil de usuario y de alguna manera medir el comportamiento. Los eventos se agregan, recopilan y guardan nuevamente (ya en las tablas de usuario). Al mismo tiempo, puede construir el sistema para que también conecte un filtro al agregador-coordinador: recopile usuarios solo de un cierto tipo de eventos.
Después de eso, si alguien en el equipo necesita solo análisis de alto nivel, puede conectar sistemas de análisis externos. Puede tomar Mixpanel nuevamente. pero como es bastante costoso, no se envían todos los eventos del usuario allí, sino solo lo que se necesita. Para hacer esto, debe crear un coordinador que transmitirá algunos eventos sin procesar o algo que nosotros mismos agregamos anteriormente a sistemas externos, API o plataformas publicitarias.
5. Frontend
Necesita conectar la interfaz al sistema creado. Un buen ejemplo es el servicio
redash , una GUI para bases de datos que ayuda a construir paneles. Cómo funciona la interacción:
- El usuario realiza una consulta SQL.
- En respuesta, recibe una tableta.
- Para ella, crea una 'nueva visualización' y obtiene un hermoso calendario que ya puede guardarse para ella.
Las visualizaciones en el servicio se actualizan automáticamente, puede configurar y rastrear su monitoreo. Redash es gratis, en caso de autohospedaje, y cómo SaaS costará $ 50 por mes.

Conclusión
Después de completar todos los pasos anteriores, creará el análisis de su servidor. Tenga en cuenta que esta no es una manera tan fácil como simplemente conectar el análisis del cliente, porque todo debe configurarse de forma independiente. Por lo tanto, antes de crear su propio sistema, vale la pena comparar la necesidad de un sistema de análisis serio con los recursos que está listo para dedicarle.
Si calculó todo y obtuvo que los costos son demasiado altos, en la siguiente parte hablaré sobre cómo hacer una versión más barata de análisis de servidor.
Gracias por leer! Estaré encantado de hacer preguntas en los comentarios.