ASN.1 es un estándar (ISO, ITU-T, GOST) de un lenguaje que describe información estructurada, así como reglas de codificación para esta información. Para mí, como programador, este es solo otro formato para serializar y presentar datos, junto con JSON, XML, XDR y otros. Es extremadamente común en nuestra vida cotidiana, y muchas personas lo encuentran: en comunicaciones celulares, telefónicas, VoIP (UMTS, LTE, WiMAX, SS7, H.323), en protocolos de red (LDAP, SNMP, Kerberos), en todo En cuanto a la criptografía (X.509, CMS, estándares PKCS), en tarjetas bancarias y pasaportes biométricos, y mucho más.
Este artículo analiza
PyDERASN : la biblioteca Python ASN.1 utilizada activamente en proyectos relacionados con la criptografía en
Atlas .
De hecho, no vale la pena recomendar ASN.1 para tareas criptográficas: ASN.1 y sus códecs son complejos. Esto significa que el código no será simple, pero siempre es un vector de ataque adicional. Solo mire
la lista de vulnerabilidades en las bibliotecas ASN.1. Bruce Schneier, en su
ingeniería de criptografía, tampoco recomienda usar este estándar debido a su complejidad: "La codificación TLV más conocida es ASN.1, pero es increíblemente compleja y nos alejamos de ella". Pero, desafortunadamente, hoy tenemos
infraestructuras de clave pública en las que se utilizan activamente
certificados X.509 , mensajes CRL, OCSP, TSP, CMP,
CMC ,
CMS y muchos estándares
PKCS . Por lo tanto, debe poder trabajar con ASN.1 si está haciendo algo relacionado con la criptografía.
ASN.1 se puede codificar de varias formas / códecs:
- BER (Reglas básicas de codificación)
- CER (Reglas de codificación canónica)
- DER (Reglas de codificación distinguidas)
- GSER (Reglas de codificación de cadenas genéricas)
- JER (Reglas de codificación JSON)
- LWER (reglas de codificación de peso ligero)
- REA (reglas de codificación de octeto)
- PER (Reglas de codificación empaquetadas)
- SER (Reglas de codificación específicas de señalización)
- XER (Reglas de codificación XML)
y varios otros. Pero en las tareas criptográficas en la práctica, se utilizan dos: BER y DER. Incluso en documentos XML firmados (
XMLDSig ,
XAdES ) todavía habrá objetos ASN.1 DER codificados en Base64, así como en el protocolo
ACME basado en JSON de Let's Encrypt. Puede comprender mejor todos estos códecs y los principios de codificación BER / CER / DER en artículos y libros:
ASN.1 en palabras simples ,
ASN.1 - Comunicación entre sistemas heterogéneos por Olivier Dubuisson ,
ASN.1 Completo por el profesor John Larmouth .
BER es un formato TLV binario orientado a bytes (por ejemplo, PER, popular en comunicaciones móviles - orientado a bits). Cada elemento se codifica en forma de: una etiqueta (
T ag) que identifica el tipo de elemento que se codifica (entero, cadena, fecha, etc.), la longitud (
L ength) del contenido y el contenido en sí (
V alue). BER opcionalmente le permite no especificar un valor de longitud estableciendo un valor de longitud indefinido especial y terminando con un mensaje de Fin de Octetos. Además de la codificación de longitud, BER tiene mucha variabilidad en el método de codificación de tipos de datos, como:
- INTEGER, IDENTIFICADOR DE OBJETO, BIT STRING y la longitud del elemento pueden no normalizarse (no codificarse en forma mínima);
- BOOLEAN es verdadero para cualquier contenido que no sea cero;
- BIT STRING puede contener cero bits "extra";
- BIT STRING, OCTET STRING y todos sus tipos de cadenas derivados, incluida la fecha / hora, se pueden dividir en partes (trozos) de longitud variable, cuya longitud durante la (des) codificación no se conoce de antemano;
- UTCTime / GeneralizedTime puede tener diferentes métodos para configurar el desplazamiento de zona horaria y las fracciones de cero "extra" de segundos;
- Los valores de SECUENCIA PREDETERMINADA pueden o no estar codificados;
- Los valores nombrados de los últimos bits en BIT STRING pueden codificarse opcionalmente;
- SECUENCIA (OF) / SET (OF) puede tener un orden arbitrario de elementos.
Para todo lo anterior, no siempre es posible codificar datos para que sean idénticos al formulario original. Por lo tanto, se inventó un subconjunto de las reglas: DER es una regulación estricta de un solo método de codificación válido, que es fundamental para las tareas criptográficas, donde, por ejemplo, cambiar un bit invalidará la firma o la suma de verificación. DER tiene un inconveniente significativo: las longitudes de todos los elementos deben conocerse de antemano durante la codificación, lo que no permite la serialización de datos. El códec CER no tiene este inconveniente, lo que garantiza una presentación inequívoca de los datos. Desafortunadamente (o afortunadamente, ¿no tenemos decodificadores aún más complejos?), No se hizo popular. Por lo tanto, en la práctica, encontramos un uso "mixto" de datos codificados BER y DER. Dado que tanto CER como DER son un subconjunto de BER, cualquier decodificador BER es capaz de procesarlos.
Problemas con pyasn1
En el trabajo, escribimos muchos programas de Python relacionados con la criptografía. Y hace unos años, prácticamente no había elección de bibliotecas gratuitas: estas son bibliotecas de muy bajo nivel que le permiten simplemente codificar / decodificar, por ejemplo, un entero y un encabezado de estructura, o esta es la biblioteca
pyasn1 . Vivimos en él durante varios años y al principio estábamos muy satisfechos, ya que le permite trabajar con estructuras ASN.1 como objetos de alto nivel: por ejemplo, un objeto de certificado X.509 decodificado le permite acceder a sus campos a través de la interfaz del diccionario: cert ["tbsCertificate"] ["SerialNumber"] nos mostrará el número de serie de este certificado. Del mismo modo, puede "recopilar" objetos complejos trabajando con ellos como con listas, diccionarios, y luego simplemente llamar a la función pyasn1.codec.der.encoder.encode y obtener una representación serializada del documento.
Sin embargo, se revelaron debilidades, problemas y limitaciones. Hubo, y desafortunadamente aún persiste, errores en pyasn1: al momento de escribir, en pyasn1, uno de los tipos básicos, GeneralizedTime, está decodificado y codificado
incorrectamente .
En nuestros proyectos, para ahorrar espacio, a menudo almacenamos solo la ruta al archivo, el desplazamiento y la longitud en bytes del objeto al que queremos referirnos. Por ejemplo, un archivo firmado arbitrariamente se ubicará en la estructura ASN.1 SignedData de CMS:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL 751 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9
y podemos obtener el archivo original firmado con un desplazamiento de 65 bytes, 751 bytes de longitud. pyasn1 no almacena esta información en sus objetos decodificados. El llamado TLVSeeker fue escrito: una pequeña biblioteca que le permite decodificar las etiquetas y las longitudes de los objetos, en cuya interfaz le ordenamos "ir a la siguiente etiqueta", "ir dentro de la etiqueta" (ir dentro de la SECUENCIA del objeto), "ir a la siguiente etiqueta", "decirle a su desplazamiento y la longitud del objeto donde estamos ". Fue una caminata "manual" sobre los datos serializados DER de ASN.1. Pero no era posible trabajar con datos serializados BER de esta manera, porque, por ejemplo, la cadena de bytes OCTET STRING podría codificarse como varios fragmentos.
Otro inconveniente para nuestras tareas pyasn1 es la incapacidad de comprender a partir de objetos decodificados si un campo dado estaba presente en SECUENCIA o no. Por ejemplo, si la estructura contiene el campo OPCIONAL SECUENCIA DE CAMPO, podría estar completamente ausente de los datos recibidos (OPCIONAL), pero podría estar presente, pero podría ser de longitud cero (lista vacía). En el caso general, esto no pudo aclararse. Y esto es necesario para una verificación rigurosa de la validez de los datos recibidos. ¡Imagínese que alguna autoridad de certificación emitiría un certificado con datos "no enteramente" válidos desde el punto de vista de los esquemas ASN.1! Por ejemplo, la autoridad de certificación TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı en su certificado raíz superó los límites permisibles de
RFC 5280 para la longitud del componente sujeto; no se puede decodificar honestamente de acuerdo con el esquema. El códec DER requiere que un campo cuyo valor sea DEFAULT no se codifique durante la transmisión; tales documentos se encuentran en la vida, y la primera versión de PyDERASN incluso permitió conscientemente ese comportamiento no válido (desde el punto de vista de DER) en aras de la compatibilidad con versiones anteriores.
Otra limitación es la incapacidad de descubrir fácilmente en qué forma (BER / DER) se codificó uno u otro objeto en la estructura. Por ejemplo, el estándar CMS dice que el mensaje está codificado con BER, pero el campo firmadoAttrs, sobre el cual se forma la firma criptográfica, debe estar en DER. Si decodificamos con el DER, entonces recaeremos en el procesamiento del CMS en sí, si decodificamos con el BER, no sabremos en qué forma se firmó el atributo. Como resultado, será necesario que TLVSeeker (el análogo de los cuales no está en pyasn1) busque la ubicación de cada uno de los campos firmadosAttrs, y DER debe decodificarlo por separado desde la vista serializada.
La posibilidad de procesamiento automático de los campos DEFINED BY, que son muy comunes, fue muy deseable para nosotros. Después de decodificar la estructura ASN.1, es posible que nos queden muchos CUALQUIER campo, que deben procesarse más de acuerdo con el esquema seleccionado en función del IDENTIFICADOR DE OBJETO especificado en el campo de estructura. En el código Python, esto significa escribir un if y luego llamar al decodificador para CUALQUIER campo.
El advenimiento de PyDERASN
En Atlas, regularmente, después de encontrar problemas o modificar los programas gratuitos utilizados, enviamos parches a la parte superior. En pyasn1, enviamos mejoras varias veces, pero el código pyasn1 no es el más fácil de entender, y a veces se produjeron cambios de API incompatibles, lo que nos golpeó en las manos. Además, estamos acostumbrados a escribir pruebas con pruebas generativas, que no era el caso en pyasn1.
¡Un buen día, decidí que tenía que soportar esto y era hora de intentar escribir mi propia biblioteca con __slot __s, offset y blobs bellamente exhibidos! Simplemente crear un códec ASN.1 no sería suficiente: debe transferirle todos nuestros proyectos dependientes, y esto es cientos de miles de líneas de código en las que hay mucho trabajo con estructuras ASN.1. Ese es uno de los requisitos para ello: facilidad de traducción del código pyasn1 actual. Después de pasar todas mis vacaciones, escribí esta biblioteca, le transferí todos los proyectos. Dado que tienen una cobertura de pruebas de casi el 100%, esto también significaba que la biblioteca estaba en pleno funcionamiento.
PyDERASN, del mismo modo, tiene casi el 100% de cobertura de prueba. Las pruebas generativas se utilizan con la maravillosa biblioteca de
hipótesis . También se llevó a cabo un
fuzzing pypy en 32 máquinas nucleares. A pesar de que casi no nos queda ningún código Python2, PyDERASN aún mantiene la compatibilidad con él y, debido a esto, tiene una sola dependencia de
seis . Además, se
prueba con el conjunto de pruebas de cumplimiento ASN.1: 2008 .
El principio de trabajar con él es similar a pyasn1: trabajar con objetos Python de alto nivel. La descripción de los circuitos ASN.1 es similar.
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), )
Sin embargo, PyDERASN tiene una apariencia de tipeo fuerte. En pyasn1, si el campo era de tipo CMSVersion (INTEGER), se le podría asignar un int o INTEGER. PyDERASN requiere estrictamente que el objeto asignado sea exactamente CMSVersion. Además de escribir código Python3, utilizamos
anotaciones de tipeo , por lo que nuestras funciones no tendrán argumentos incomprensibles como def func (serial, contenido), pero def func (serial: CertificateSerialNumber, contenido: EncapsulatedContentInfo), y PyDERASN ayuda a realizar un seguimiento de tales código
Al mismo tiempo, PyDERASN tiene concesiones extremadamente convenientes para este tipo de escritura. pyasn1 no permitió que SubjectKeyIdentifier (). subtype (impllicitTag = Tag (...)) asignara un objeto SubjectKeyIdentifier () (sin la ETIQUETA IMPLICIT requerida) y a menudo tuvo que copiar y recrear objetos solo debido a las etiquetas IMPLICIT / EXPLICIT cambiadas. PyDERASN observa estrictamente solo el tipo básico: sustituirá automáticamente las etiquetas de una estructura ASN.1 existente. Esto simplifica enormemente el código de la aplicación.
Si se produce un error durante la decodificación, en pyasn1 no es fácil entender exactamente dónde ocurrió. Por ejemplo, en el certificado turco ya mencionado obtenemos este error: UTF8String (tbsCertificate: issuer: rdnSequence: 3: 0: value: DEFINED BY 2.5.4.10:utf8String) (at 138) límites insatisfechos: 1 ⇐ 77 ⇐ 64 Al escribir ASN .1 las estructuras de las personas pueden cometer errores, y es más fácil depurar aplicaciones o descubrir problemas de documentos codificados del lado opuesto.
La primera versión de PyDERASN no era compatible con la codificación BER. Apareció mucho más tarde y el procesamiento UTCTime / GeneralizedTime con zonas horarias aún no es compatible. Esto vendrá en el futuro, porque el proyecto está escrito principalmente en el tiempo libre.
También en la primera versión no hubo trabajo con los campos DEFINED BY. Unos meses más tarde,
apareció esta
oportunidad y comenzó a utilizarse activamente, lo que redujo significativamente el código de la aplicación: en una operación de decodificación, fue posible desmontar toda la estructura a la profundidad misma. Para hacer esto, en el esquema, qué campos están definidos que "determinan". Por ejemplo, una descripción de un esquema CMS:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), )
dice que si contentType contiene un OID con id_signedData, entonces el campo de contenido (ubicado en la misma SECUENCIA) debe decodificarse utilizando el esquema SignedData. ¿Por qué hay tantos corchetes? Un campo puede "definir" varios campos al mismo tiempo, como es el caso en las estructuras de EnvelopedData. Los campos definidos se identifican mediante la llamada ruta de decodificación: establece la ubicación exacta de cualquier elemento en todas las estructuras.
No siempre es deseable o no siempre es posible introducir inmediatamente estas definiciones en el circuito. Puede haber casos específicos de aplicaciones en los que los OID y las estructuras solo se conocen en un proyecto de terceros. PyDERASN proporciona la capacidad de especificar estas definiciones justo en el momento de decodificar la estructura:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)})
Aquí decimos que en CMS SignedData para todos los certificados adjuntos, decodifica todas sus extensiones (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, etc.). A través de la ruta de decodificación, indicamos qué elemento "sustituir" define, como si estuviera definido en el circuito.
Finalmente, PyDERASN tiene la capacidad de trabajar desde la
línea de comandos para decodificar archivos ASN.1 y tiene
una impresión bastante rica. Puede decodificar un ASN.1 arbitrario, o puede especificar un esquema claramente definido y ver algo como esto:
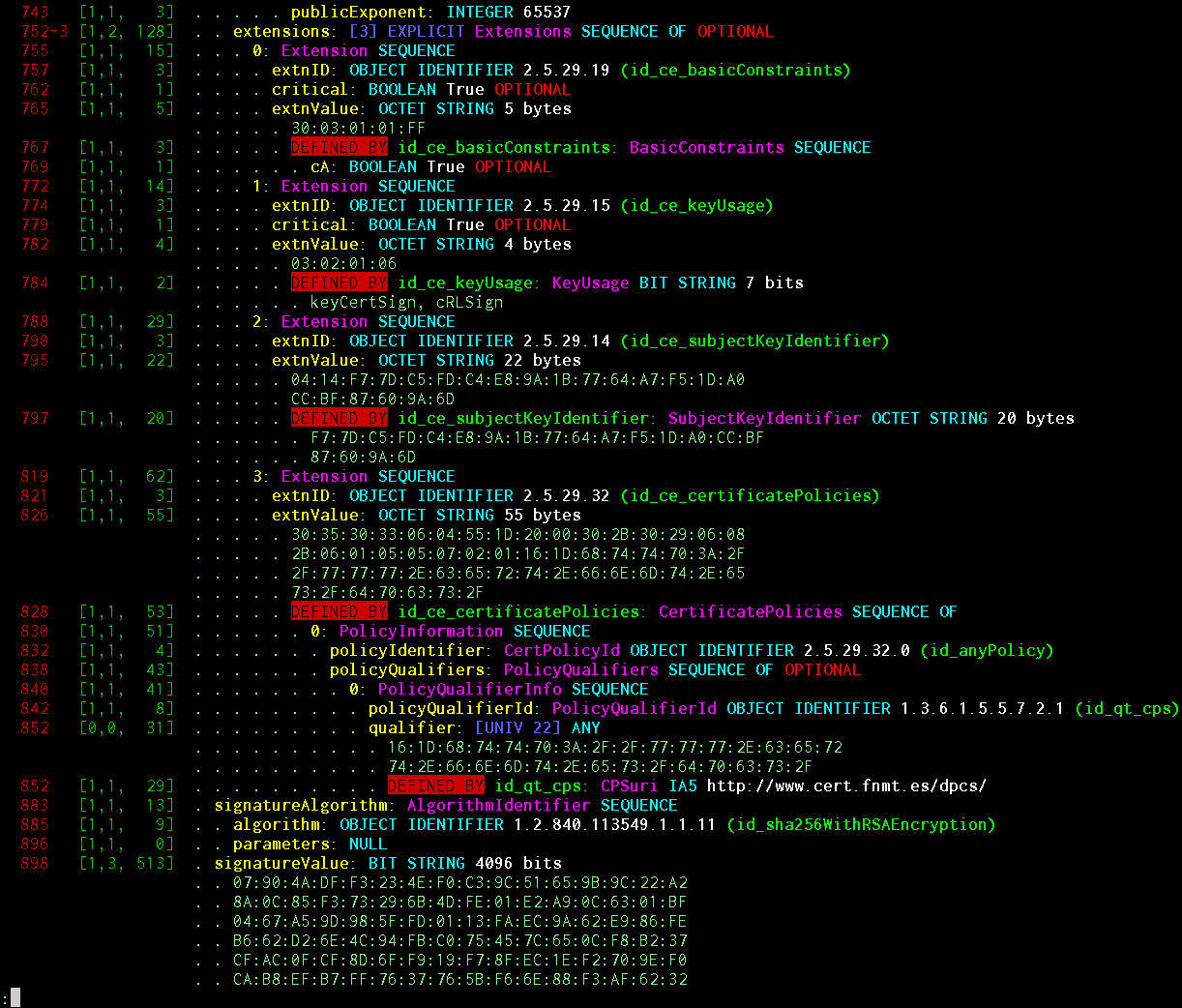
Información mostrada: desplazamiento de objeto, longitud de etiqueta, longitud de longitud, longitud de contenido, presencia de EOC (fin de octetos), bandera de codificación BER, bandera de codificación de longitud indefinida, longitud de etiqueta EXPLICIT y compensación (si existe), profundidad de anidamiento de objeto en estructuras, valor de etiqueta IMPLICIT / EXPLICIT, nombre de objeto de acuerdo con el esquema, su tipo ASN.1 básico, número de serie dentro de SECUENCIA / CONJUNTO, valor CHOICE (si lo hay), nombre legible para humanos INTEGER / ENUMERATED / BIT STRING de acuerdo con el esquema, valor de cualquier tipo básico , Indicador POR DEFECTO / OPCIONAL del circuito, una señal de que el objeto fue decodificado automáticamente como DEFINIDO POR y después gm de OID-y sucedió, OID chelovekochitaemy.
El bonito sistema de impresión está hecho especialmente para generar una secuencia de objetos PP que ya se visualizan por medios separados. La captura de pantalla muestra el renderizador en texto plano. Hay renderizadores en formato JSON / HTML para que esto se pueda ver resaltado en el navegador ASN.1 como en el proyecto
asn1js .
Otras bibliotecas
Este no era el objetivo, pero PyDERASN fue significativamente
más rápido que pyasn1. Por ejemplo, decodificar archivos CRL de megabytes puede llevar tanto tiempo que tenga que pensar en formatos intermedios para almacenar datos (rápido) y cambiar la arquitectura de las aplicaciones. pyasn1 decodifica CRL
CACert.org en mi computadora portátil durante más de 20 minutos, ¡mientras que PyDERASN en solo 28 segundos! Hay un proyecto
asn1crypto destinado a trabajar rápidamente con estructuras criptográficas: decodifica (completamente, no perezosamente) la misma CRL en 29 segundos, pero consume casi el doble de RAM cuando se ejecuta en Python3 (983 MiB versus 498), y 3.5 veces con Python2 (1677 contra 488), mientras que pyasn1 consume hasta 4.3 veces más (2093 contra 488).
asn1crypto, que mencioné, no lo consideramos, porque el proyecto estaba recién en pañales y no habíamos oído hablar de él. Ahora tampoco comenzarían a mirar en su dirección, ya que descubrí de inmediato que el mismo GeneralizedTime no tiene un aspecto arbitrario, y al serializar, elimina silenciosamente fracciones de un segundo. Esto es aceptable para trabajar con certificados X.509, pero en general no funcionará.
Por el momento, PyDERASN es el decodificador Py DER / Go DER más estricto que conozco. En la biblioteca de codificación / asn1 de mi Go favorito, no
hay una verificación estricta de las cadenas IDENTIFICADOR DE OBJETO y UTCTime / GeneralizedTime. A veces, la rigidez puede interferir (principalmente debido a la compatibilidad con aplicaciones anteriores que nadie solucionará), por lo que en PyDERASN durante la decodificación puede pasar
varias configuraciones que debilitan las verificaciones.
El código del proyecto intenta ser lo más simple posible. Toda la biblioteca es un solo archivo. El código está escrito con énfasis en la facilidad de comprensión, sin rendimiento innecesario y optimizaciones de código DRY. Como ya dije, no admite la decodificación BER completa de las cadenas UTCTime / GeneralizedTime, así como los tipos de datos REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING. En todos los demás casos, personalmente, no veo ninguna razón para usar otras bibliotecas en Python.
Al igual que todos mis proyectos, como
PyGOST ,
GoGOST ,
NNCP ,
GoVPN , PyDERASN es
un software completamente
gratuito distribuido bajo los términos de
LGPLv3 + , y está disponible para su descarga gratuita. Ejemplos de uso están
aquí en
las pruebas PyGOST .
Sergey Matveev ,
banco de cifrado , miembro de
la Open Society Foundation Foundation , Python / Go-developer, jefe especialista de
FSUE "STC Atlas" .