
Hola a todos! Mi nombre es Sergey Kostanbaev, en Exchange estoy desarrollando el núcleo del sistema comercial.
Cuando la Bolsa de Nueva York se muestra en las películas de Hollywood, siempre se ve así: multitudes de personas gritando algo, agitando papel, hay un caos total. Nunca tuvimos esto en la Bolsa de Moscú, porque casi desde el principio, el comercio se realizó electrónicamente y se basa en dos plataformas principales: Spectra (mercado de derivados) y ASTS (moneda, acciones y mercados monetarios). Y hoy quiero hablar sobre la evolución de la arquitectura del sistema de comercio y compensación de ASTS, sobre varias soluciones y hallazgos. La historia será larga, así que tuve que dividirla en dos partes.
Somos uno de los pocos intercambios en el mundo que comercializa activos de todas las clases y brinda una gama completa de servicios de intercambio. Por ejemplo, el año pasado tomamos el segundo lugar en el mundo en términos de volumen de negociación de bonos, el puesto 25 entre todas las bolsas de valores, el puesto 13 por capitalización entre las bolsas públicas.
Para los postores profesionales, parámetros como el tiempo de respuesta, la estabilidad de la distribución del tiempo (fluctuación de fase) y la confiabilidad de todo el complejo son críticos. Actualmente, procesamos decenas de millones de transacciones por día. El procesamiento de cada transacción por el núcleo del sistema toma decenas de microsegundos. Por supuesto, con los operadores móviles en Año Nuevo o con motores de búsqueda, la carga en sí es más alta que la nuestra, pero en términos de carga, junto con las características anteriores, pocos pueden compararse con nosotros, como me parece. Al mismo tiempo, es importante para nosotros que el sistema no se ralentice por un segundo, funcione absolutamente estable y todos los usuarios estén en igualdad de condiciones.
Un poco de historia
En 1994, se lanzó el sistema ASTS australiano en el Intercambio de divisas interbancario de Moscú (MICEX), y desde este momento puede contar la historia rusa del comercio electrónico. En 1998, la arquitectura del intercambio se modernizó para la introducción del comercio por Internet. Desde entonces, la velocidad de introducir nuevas soluciones y cambios arquitectónicos en todos los sistemas y subsistemas solo está ganando impulso.
En esos años, el sistema de intercambio funcionaba en hardware de alta gama: los servidores HP Superdome 9000 altamente confiables (construidos en la
arquitectura PA-RISC ), que duplicaban absolutamente todo: los subsistemas de E / S, la red, la RAM (de hecho, había una matriz RAID de RAM ), procesadores (intercambio en caliente compatible). Era posible cambiar cualquier componente del servidor sin detener la máquina. Confiamos en estos dispositivos, los consideramos prácticamente sin problemas. El sistema operativo era similar a Unix HP UX.
Pero desde aproximadamente 2010, ha surgido un fenómeno como el comercio de alta frecuencia (HFT) o el comercio de alta frecuencia, simplemente, intercambie robots. En solo 2.5 años, la carga en nuestros servidores ha aumentado 140 veces.
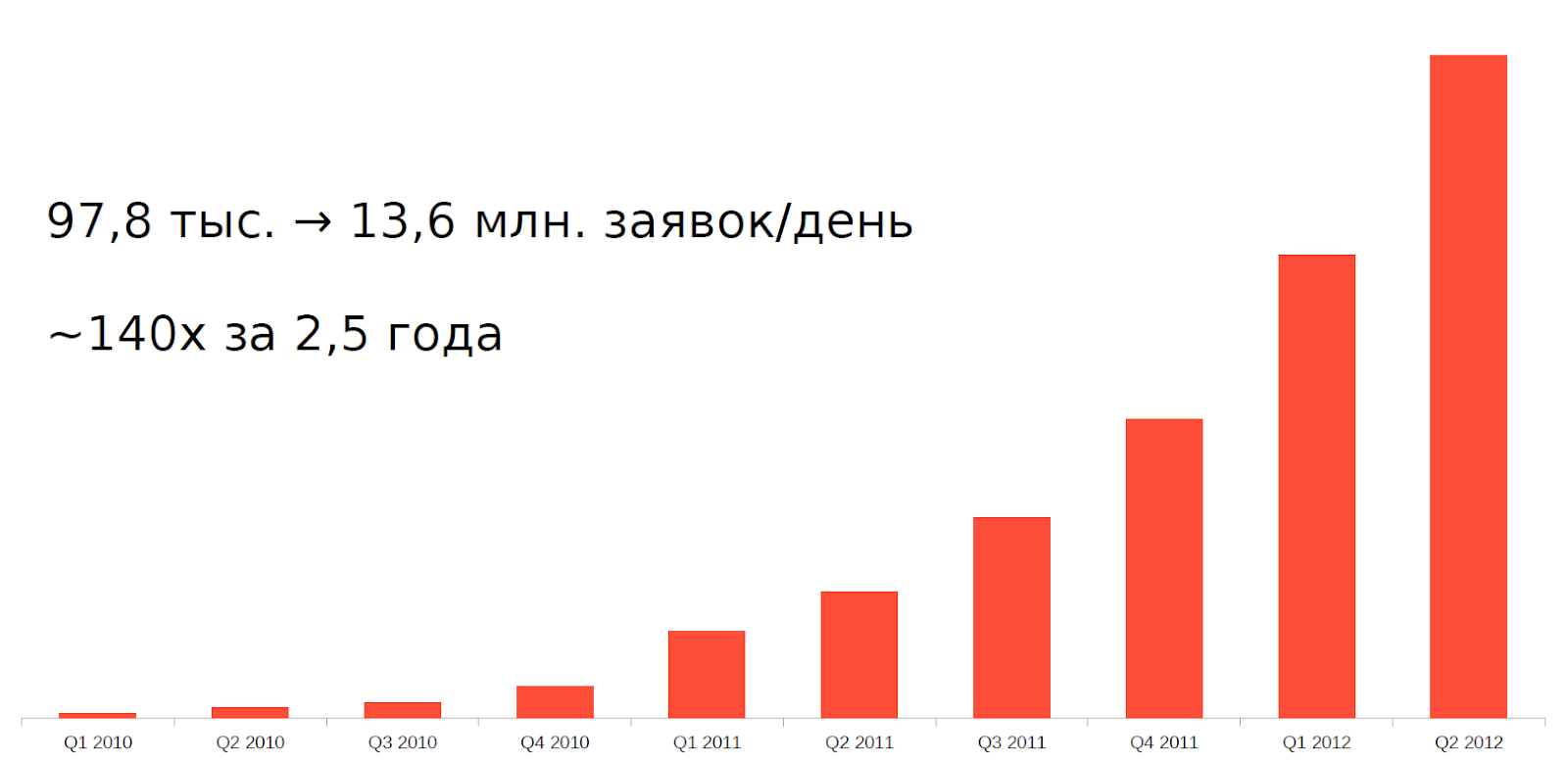
Resistir tal carga con la arquitectura y los equipos antiguos era imposible. Era necesario adaptarse de alguna manera.
Inicio
Las solicitudes al sistema de intercambio se pueden dividir en dos tipos:
- Transacciones Si desea comprar dólares, acciones u otra cosa, envíe una transacción al sistema de negociación y obtenga una respuesta sobre el éxito.
- Solicitudes de información. Si desea conocer el precio actual, consulte el libro de pedidos o los índices y luego envíe solicitudes de información.
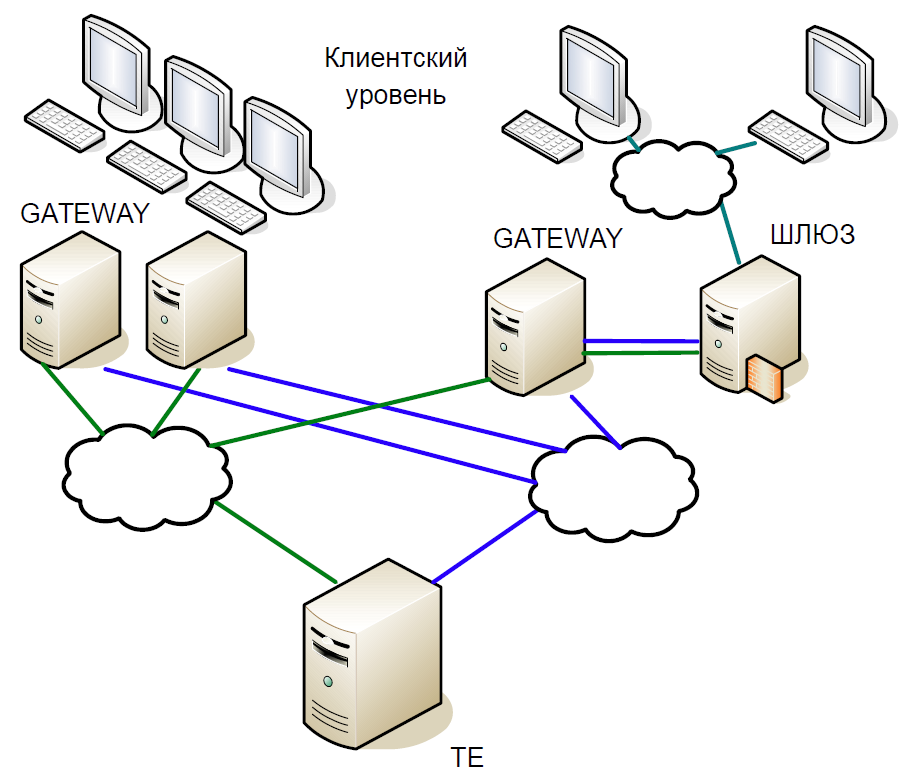
Esquemáticamente, el núcleo del sistema se puede dividir en tres niveles:
- El nivel de cliente en el que trabajan los corredores y clientes. Todos ellos interactúan con servidores de acceso.
- Los servidores de acceso (Gateways) son servidores de caché que procesan localmente todas las solicitudes de información. ¿Quiere saber a qué precio se negocian ahora las acciones de Sberbank? La solicitud va al servidor de acceso.
- Pero si desea comprar acciones, la solicitud ya está en el servidor central (Trade Engine). Hay un servidor de este tipo para cada tipo de mercado, juegan un papel crucial, y fue por su bien que creamos este sistema.
El núcleo del sistema comercial es una base de datos difícil en memoria en la que todas las transacciones son transacciones de intercambio. La base estaba escrita en C, de las dependencias externas solo existía la biblioteca libc y no había ninguna asignación dinámica de memoria. Para reducir el tiempo de procesamiento, el sistema comienza con un conjunto estático de matrices y con una reubicación estática de datos: primero, todos los datos del día actual se cargan en la memoria, y luego no hay acceso al disco, todo el trabajo se realiza solo en la memoria. Cuando se inicia el sistema, todos los datos de referencia ya están ordenados, por lo que la búsqueda funciona de manera muy eficiente y toma poco tiempo en tiempo de ejecución. Todas las tablas están hechas con listas intrusivas y árboles para estructuras de datos dinámicas de modo que no requieren asignación de memoria en tiempo de ejecución.
Repasemos brevemente la historia del desarrollo de nuestro sistema de negociación y compensación.
La primera versión de la arquitectura del sistema de negociación y compensación se creó sobre la llamada interacción Unix: se utilizaron memoria compartida, semáforos y colas, y cada proceso consistió en un hilo. Este enfoque fue generalizado a principios de la década de 1990.
La primera versión del sistema contenía dos niveles de Gateway y un servidor central del sistema de comercio. El esquema de trabajo fue el siguiente:
- El cliente envía una solicitud que llega a la puerta de enlace. Comprueba la validez del formato (pero no los datos en sí) y rechaza la transacción incorrecta.
- Si se ha enviado una solicitud de información, se ejecuta localmente; Si se trata de una transacción, se redirige al servidor central.
- Luego, el motor comercial procesa la transacción, cambia la memoria local y envía una respuesta a la transacción, y esta misma, a la replicación utilizando un mecanismo de replicación separado.
- Gateway recibe una respuesta del nodo central y lo redirige al cliente.
- Después de un tiempo, el Gateway recibe la transacción usando el mecanismo de replicación, y esta vez la ejecuta localmente, cambiando sus estructuras de datos para que las siguientes solicitudes de información muestren los datos reales.
De hecho, el modelo de replicación se describe aquí, en el cual Gateway repitió completamente las acciones realizadas en el sistema de negociación. Un canal de replicación separado proporcionó el mismo orden de ejecución de transacción en múltiples nodos de acceso.
Como el código era de un solo subproceso, se utilizó un esquema clásico con procesos bifurcados para servir a muchos clientes. Sin embargo, hacer una bifurcación para toda la base de datos fue muy costoso, por lo tanto, se utilizaron procesos de servicio livianos que recopilaron paquetes de sesiones TCP y los transfirieron a una cola (cola de mensajes SystemV). Gateway y Trade Engine trabajaron solo con esta cola, tomando transacciones para su ejecución desde allí. Ya era imposible enviarle una respuesta, porque no está claro qué proceso de servicio debería leerlo. Entonces recurrimos a un truco: cada proceso bifurcado creaba una cola de respuesta para sí mismo, y cuando llegaba una solicitud en la cola entrante, se le agregaba inmediatamente una etiqueta para la cola de respuesta.
La copia constante de la cola a la cola de grandes cantidades de datos creó problemas, especialmente característicos de las solicitudes de información. Por lo tanto, aprovechamos otro truco: además de la cola de respuesta, cada proceso también creó memoria compartida (Memoria compartida de SystemV). Los paquetes se colocaron en él, y solo la etiqueta se guardó en la cola, lo que le permite encontrar el paquete fuente. Esto ayudó a almacenar datos en el caché del procesador.
SystemV IPC incluye utilidades para ver el estado de los objetos de cola, memoria y semáforo. Usamos esto activamente para comprender lo que está sucediendo en el sistema en un momento particular, donde los paquetes se acumulan, lo que está bloqueado, etc.
Primera modernización
En primer lugar, nos deshicimos de la puerta de enlace de un solo proceso. Su inconveniente importante era que podía procesar una transacción de replicación o una solicitud de información de un cliente. Y con el aumento de la carga, el Gateway procesará las solicitudes por más tiempo y no podrá procesar el flujo de replicación. Además, si el cliente envió una transacción, solo necesita verificar su validez y reenviarla aún más. Por lo tanto, reemplazamos un proceso de Gateway con muchos componentes que pueden funcionar en paralelo: información multiproceso y procesos transaccionales que funcionan de forma independiente entre sí con un área de memoria común mediante RW-lock. Y al mismo tiempo, introdujimos procesos de programación y replicación.
El impacto del comercio de alta frecuencia
La versión anterior de la arquitectura duró hasta 2010. Mientras tanto, ya no estábamos satisfechos con el rendimiento de los servidores HP Superdome. Además, la arquitectura PA-RISC en realidad murió; el proveedor no ofreció ninguna actualización significativa. Como resultado, comenzamos a cambiar de HP UX / PA RISC a Linux / x86. La transición comenzó con la adaptación de los servidores de acceso.
¿Por qué tuvimos que cambiar la arquitectura nuevamente? El hecho es que el comercio de alta frecuencia ha cambiado significativamente el perfil de carga del núcleo del sistema.
Supongamos que tenemos una pequeña transacción que causó un cambio significativo en el precio: alguien compró medio billón de dólares. Después de un par de milisegundos, todos los participantes del mercado lo notan y comienzan a corregirlo. Naturalmente, las solicitudes se alinean en una cola enorme, que el sistema acumulará durante mucho tiempo.

En este intervalo de 50 ms, la velocidad promedio es de aproximadamente 16 mil transacciones por segundo. Si reduce la ventana a 20 ms, obtenemos una velocidad promedio de 90 mil transacciones por segundo, y en el pico habrá 200 mil transacciones. En otras palabras, la carga es inestable, con explosiones bruscas. Y la cola de solicitudes siempre debe procesarse rápidamente.
Pero, ¿por qué hay una cola? Entonces, en nuestro ejemplo, muchos usuarios notaron un cambio de precio y enviaron las transacciones correspondientes. Esos vienen a Gateway, los serializa, establece un cierto orden y los envía a la red. Los enrutadores mezclan paquetes y los reenvían. Cuyo paquete llegó antes, esa transacción "ganó". Como resultado, los clientes de intercambio comenzaron a notar que si se enviaba la misma transacción desde varios Gateways, entonces las posibilidades de un procesamiento rápido aumentan. Pronto, los robots de intercambio comenzaron a bombardear Gateway con solicitudes, y surgió una avalancha de transacciones.

Una nueva ronda de evolución.
Después de extensas pruebas e investigaciones, cambiamos al núcleo en tiempo real del sistema operativo. Para hacer esto, eligieron RedHat Enterprise MRG Linux, donde MRG representa la cuadrícula de mensajes en tiempo real. La ventaja de los parches en tiempo real es que optimizan el sistema para la ejecución más rápida posible: todos los procesos están organizados en una cola FIFO, puede aislar los núcleos, sin caídas, todas las transacciones se procesan en secuencia estricta.
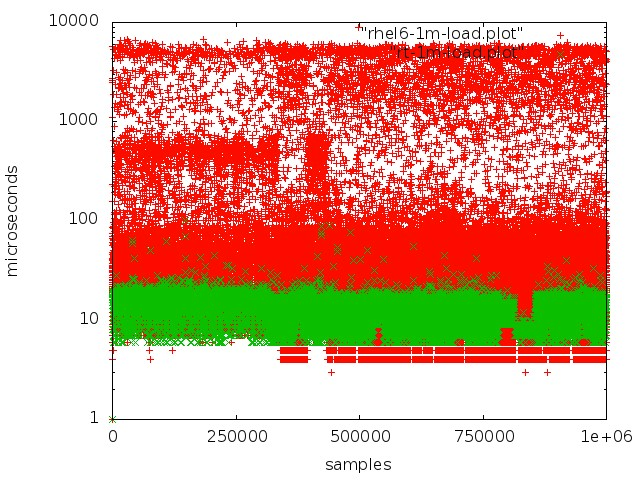 Rojo: trabajar con una cola en un núcleo normal, verde: trabajar en un núcleo en tiempo real.
Rojo: trabajar con una cola en un núcleo normal, verde: trabajar en un núcleo en tiempo real.Pero lograr una baja latencia en los servidores normales no es tan simple:
- El modo SMI, que en la arquitectura x86 se encuentra en el corazón del trabajo con periféricos importantes, interfiere enormemente. El procesamiento de varios eventos de hardware y la gestión de componentes y dispositivos se realiza mediante firmware en el denominado modo SMI transparente, en el que el sistema operativo no ve lo que está haciendo el firmware. Como regla general, todos los principales proveedores ofrecen extensiones especiales para servidores de firmware, lo que permite reducir la cantidad de procesamiento SMI.
- No debe haber control dinámico de la frecuencia del procesador, esto lleva a un tiempo de inactividad adicional.
- Cuando se restablece el registro del sistema de archivos, se producen ciertos procesos en el núcleo que conducen a retrasos impredecibles.
- Debe prestar atención a cosas como afinidad de CPU, afinidad de interrupción, NUMA.
Debo decir que el tema de la configuración del hardware y kernel de Linux para el procesamiento en tiempo real merece un artículo aparte. Pasamos mucho tiempo en experimentos e investigaciones antes de lograr un buen resultado.
Al cambiar de servidores PA-RISC a x86, prácticamente no tuvimos que cambiar mucho el código del sistema, solo lo adaptamos y lo reconfiguramos. Al mismo tiempo, se corrigieron varios errores. Por ejemplo, las consecuencias surgieron rápidamente de que PA RISC era un sistema Big endian y x86 un sistema Little endian: por ejemplo, los datos no se leían correctamente. Un error más complicado fue que PA RISC usa el acceso
secuencial a memoria
constante , mientras que x86 puede reordenar las operaciones de lectura, por lo que el código que es absolutamente válido en una plataforma deja de funcionar en otra.
Después de cambiar a x86, la productividad aumentó casi tres veces, el tiempo promedio de procesamiento de transacciones disminuyó a 60 μs.
Ahora echemos un vistazo más de cerca a los cambios clave que se han realizado en la arquitectura del sistema.
Epic espera caliente
En cuanto a los servidores básicos, sabíamos que son menos confiables. Por lo tanto, al crear una nueva arquitectura, a priori asumimos la posibilidad de falla de uno o más nodos. Por lo tanto, necesitábamos un sistema de reserva activa capaz de cambiar muy rápidamente a máquinas de respaldo.
Además, había otros requisitos:
- En ningún caso debe perder las transacciones procesadas.
- El sistema debe ser absolutamente transparente para nuestra infraestructura.
- Los clientes no deberían ver interrupciones de conexión.
- La reserva no debería introducir un retraso significativo, ya que este es un factor crítico para el intercambio.
Al crear un sistema de espera activa, no consideramos escenarios como fallas dobles (por ejemplo, la red en un servidor dejó de funcionar y el servidor principal se colgó); no consideró la posibilidad de errores en el software, porque se detectan durante las pruebas; y no consideró el mal funcionamiento del hierro.
Como resultado, llegamos al siguiente esquema:
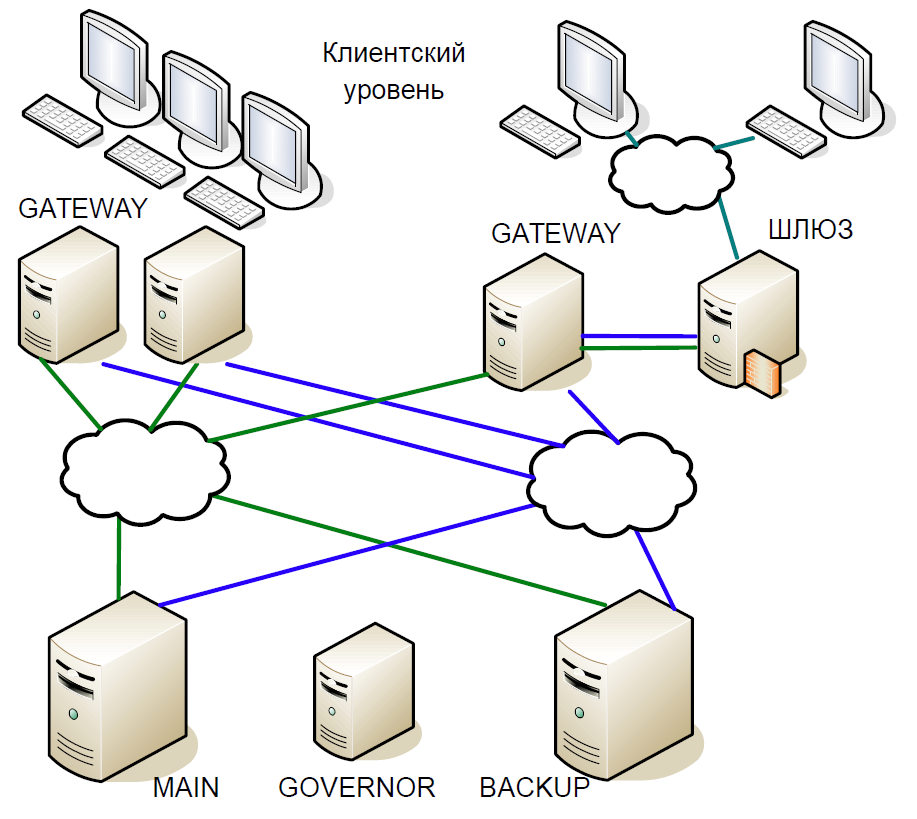
- El servidor principal interactuó directamente con los servidores de Gateway.
- Todas las transacciones recibidas en el servidor principal se replicaron instantáneamente en el servidor de respaldo a través de un canal separado. El Árbitro (Gobernador) coordinó el cambio cuando se produjo algún problema.
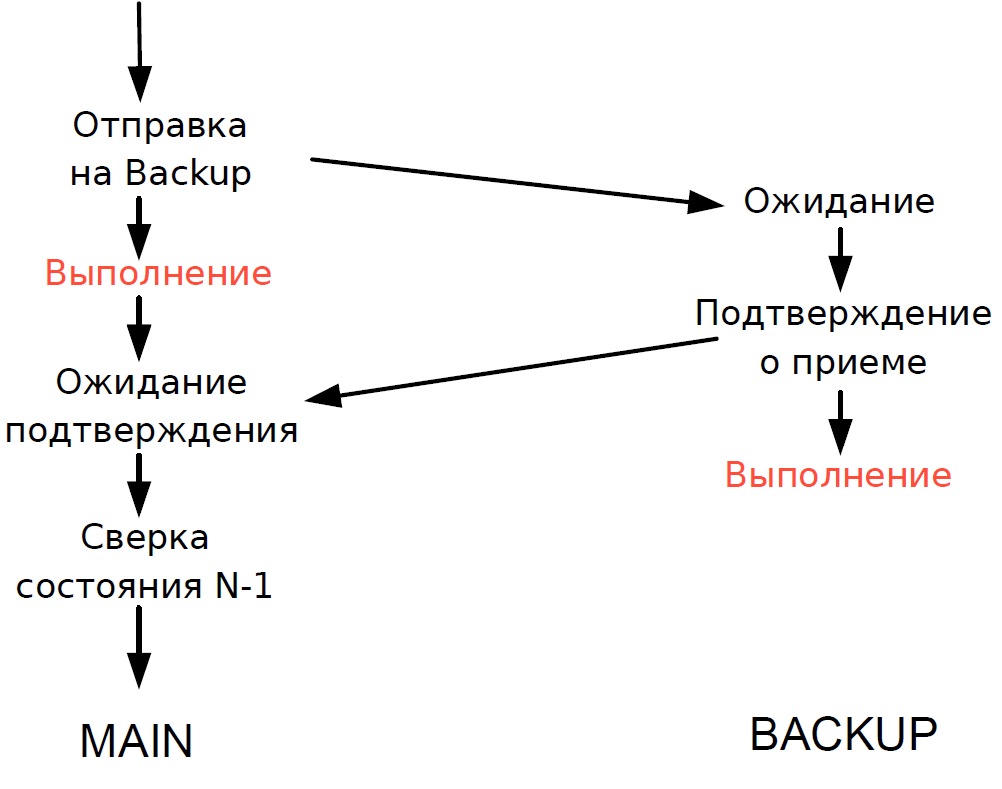
- El servidor principal procesó cada transacción y esperó la confirmación del servidor de respaldo. Para minimizar el retraso, nos negamos a esperar a que se complete la transacción en el servidor de respaldo. Como la duración de la transacción a través de la red fue comparable a la duración de la transacción, no se agregó ningún retraso adicional.
- Podríamos verificar el estado de procesamiento del servidor principal y de respaldo solo para la transacción anterior, y el estado de procesamiento de la transacción actual era desconocido. Dado que los procesos de subproceso único todavía se usaban aquí, esperar una respuesta de Copia de seguridad ralentizaría todo el flujo de procesamiento y, por lo tanto, hicimos un compromiso razonable: verificamos el resultado de la transacción anterior.

El esquema funcionó de la siguiente manera.
Supongamos que el servidor principal deja de responder, pero la puerta de enlace continúa comunicándose. En el servidor de respaldo, se activa un tiempo de espera, se convierte en Gobernador y él le asigna el rol del servidor principal, y todos los Gateways cambian al nuevo servidor principal.
Si el servidor principal vuelve a funcionar, también se activa un tiempo de espera interno, ya que durante algún tiempo no ha habido llamadas al servidor desde Gateway. Luego también recurre al gobernador, y lo excluye del plan. Como resultado, el intercambio funciona con un servidor hasta el final del período de negociación. Dado que la probabilidad de que un servidor falle es bastante baja, dicho esquema se consideró bastante aceptable, no contenía una lógica compleja y se probó fácilmente.
Continuará