
Esta es la continuación de una larga historia sobre nuestro camino espinoso para crear un sistema potente y altamente cargado que garantice el funcionamiento del intercambio.
La primera parte está aquí .
Error misterioso
Después de numerosas pruebas, se puso en funcionamiento el sistema actualizado de negociación y compensación, y nos encontramos con un error sobre el cual era correcto escribir una historia de detectives mística.
Poco después de comenzar en el servidor principal, una de las transacciones se procesó con un error. Al mismo tiempo, todo estaba en orden en el servidor de respaldo. ¡Resultó que una simple operación matemática de calcular el exponente en el servidor principal dio un resultado negativo de un argumento válido! Las encuestas continuaron, y en el registro SSE2 encontraron una diferencia en un bit, que es responsable del redondeo cuando se trabaja con números de punto flotante.
Escribieron una utilidad de prueba simple para calcular el exponente con el conjunto de bits de redondeo. Resultó que en la versión de RedHat Linux que usamos, había un error al trabajar con una función matemática cuando se insertaba el bit desafortunado. Le informamos esto a RedHat, después de un tiempo recibimos un parche de ellos y lo enrollamos. El error ya no ocurrió, pero no estaba claro de dónde vino este bit. La
fesetround función de C fue responsable de ello. Analizamos cuidadosamente nuestro código en busca del supuesto error: verificamos todas las situaciones posibles; consideró todas las funciones que usaban redondeo; intentó jugar una sesión fallida; usó diferentes compiladores con diferentes opciones; Utilizado análisis estático y dinámico.
No se pudo encontrar la causa del error.
Luego comenzaron a verificar el hardware: llevaron a cabo pruebas de carga de los procesadores; comprobó la RAM; incluso ejecutó pruebas para un escenario muy poco probable de un error de varios bits en una celda. De nada sirvió.
Al final, se decidieron por teorías del mundo de la física de alta energía: algunas partículas de alta energía volaron a nuestro centro de datos, atravesaron la pared de la caja, golpearon el procesador y causaron que el pestillo del gatillo se quedara pegado en el mismo bit. Esta teoría absurda se llamaba "neutrino". Si está lejos de la física de partículas elementales: los neutrinos apenas interactúan con el mundo exterior, y ciertamente no pueden afectar al procesador.
Como no fue posible encontrar la causa de la falla, en caso de que excluyeran al servidor "delincuente" de la operación.
Después de un tiempo, comenzamos a mejorar el sistema de espera activa: presentamos las llamadas "reservas cálidas" (réplicas asíncronas). Recibieron un flujo de transacciones que pueden estar en diferentes centros de datos, pero cálido no admitía la interacción activa con otros servidores.
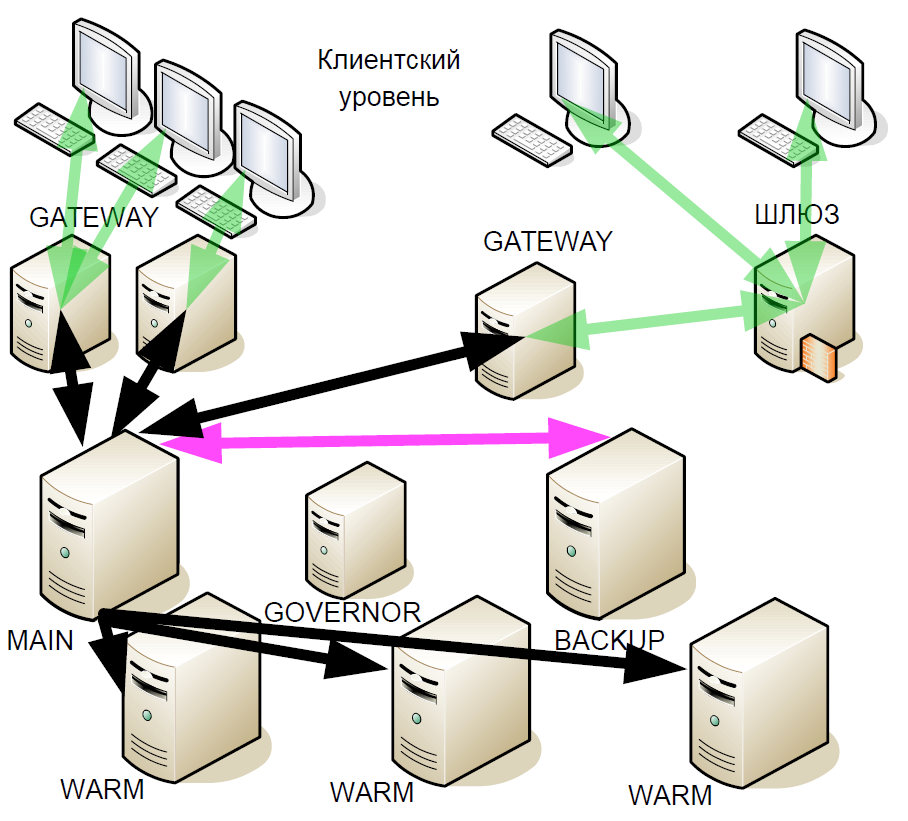
¿Por qué se hizo esto? Si el servidor de respaldo falla, el enlace en caliente con el servidor principal se convierte en el nuevo respaldo. Es decir, después de una falla, el sistema no permanece hasta el final de la sesión de negociación con un servidor principal.
Y cuando la nueva versión del sistema se probó y se puso en funcionamiento, nuevamente se produjo un error con un bit de redondeo. Además, con el aumento en el número de servidores en caliente, el error comenzó a aparecer con más frecuencia. En este caso, el vendedor no tenía nada que presentar, ya que no hay evidencia concreta.
Durante el siguiente análisis de la situación, surgió la teoría de que el problema podría estar relacionado con el sistema operativo. Escribimos un programa simple que llama a la función
fesetround en un bucle sin fin, recuerda el estado actual y lo verifica durante el sueño, y esto se hace en muchos hilos competidores. Una vez seleccionados los parámetros de suspensión y la cantidad de subprocesos, comenzamos a reproducir de manera estable el fallo de bits después de aproximadamente 5 minutos de la utilidad. Sin embargo, el soporte de Red Hat no pudo reproducirlo. Las pruebas de nuestros otros servidores mostraron que solo aquellos con ciertos procesadores instalados están afectados por el error. Al mismo tiempo, la transición a un nuevo núcleo resolvió el problema. Al final, simplemente reemplazamos el sistema operativo, y la verdadera causa del error seguía sin estar clara.
Y de repente, el año pasado apareció un artículo sobre Habré "
Cómo encontré un error en los procesadores Intel Skylake ". La situación descrita en ella era muy similar a la nuestra, pero el autor avanzó más en la investigación y adelantó la teoría de que el error estaba en el microcódigo. Y al actualizar los núcleos de Linux, los fabricantes también actualizan el microcódigo.
Desarrollo posterior del sistema.
Aunque nos deshicimos del error, esta historia nos hizo reconsiderar la arquitectura del sistema nuevamente. Después de todo, no estábamos protegidos de la repetición de tales errores.
Los siguientes principios formaron la base para futuras mejoras en el sistema de respaldo:
- No puedes confiar en nadie. Los servidores pueden no funcionar correctamente.
- Redundancia mayoritaria.
- Creación de consenso. Como complemento lógico a la redundancia mayoritaria.
- Las fallas dobles son posibles.
- Vitalidad. El nuevo esquema de repuesto dinámico no debería ser peor que el anterior. El comercio debería ir sin problemas hasta el último servidor.
- Un ligero aumento en el retraso. Cualquier tiempo de inactividad conlleva enormes pérdidas financieras.
- Mínima interacción de red para que el retraso sea lo más bajo posible.
- Seleccione un nuevo servidor maestro en segundos.
Ninguna de las soluciones disponibles en el mercado nos convenía, y el protocolo Raft estaba recién en pañales, así que creamos nuestra propia solución.

Conectividad de red
Además del sistema de respaldo, comenzamos a modernizar la conectividad de la red. El subsistema de E / S era una multitud de procesos que, en la peor forma, afectaban el jitter y el retraso. Teniendo cientos de procesos que procesan conexiones TCP, nos vimos obligados a cambiar constantemente entre ellos, y en una escala de microsegundos, esta es una operación bastante larga. Pero la peor parte es que cuando un proceso recibió un paquete para su procesamiento, lo envió a una cola de SystemV y luego esperó eventos de otra cola de SystemV. Sin embargo, con una gran cantidad de nodos, la llegada de un nuevo paquete TCP en un proceso y la recepción de datos en una cola en otro representan dos eventos competitivos para el sistema operativo. En este caso, si no hay procesadores físicos disponibles para ambas tareas, se procesará uno y el segundo permanecerá en la cola de espera. Es imposible predecir las consecuencias.
En tales situaciones, puede aplicar el control dinámico de prioridad del proceso, pero esto requerirá el uso de llamadas al sistema que requieren muchos recursos. Como resultado, cambiamos a un subproceso usando el clásico epoll, esto aumentó enormemente la velocidad y redujo el tiempo de procesamiento de la transacción. También nos deshicimos de ciertos procesos de interacción de red e interacción a través de SystemV, redujimos significativamente el número de llamadas al sistema y comenzamos a controlar las prioridades de las operaciones. Usando solo un subsistema de E / S, fue posible ahorrar aproximadamente 8-17 microsegundos, dependiendo del escenario. Este esquema de un solo subproceso se ha aplicado sin cambios, una secuencia de epoll con un margen es suficiente para dar servicio a todas las conexiones.
Procesamiento de transacciones
La creciente carga en nuestro sistema requirió la modernización de casi todos sus componentes. Pero, desafortunadamente, el estancamiento en el aumento de la velocidad del reloj del procesador en los últimos años ya no nos permitió escalar los procesos "de frente". Por lo tanto, decidimos dividir el proceso del Motor en tres niveles, el más cargado de los cuales es el sistema de verificación de riesgos, que evalúa la disponibilidad de fondos en las cuentas y crea las transacciones. Pero el dinero puede estar en diferentes monedas, y fue necesario descubrir en qué principio dividir el procesamiento de solicitudes.
La solución lógica es dividir por moneda: un servidor cotiza en dólares, otro en libras y un tercer euro. Pero si, con tal esquema, se envían dos transacciones para comprar monedas diferentes, entonces habrá un problema de billeteras no sincronizadas. Y la sincronización es difícil y costosa. Por lo tanto, será correcto fragmentar por separado en las billeteras y por separado en las herramientas. Por cierto, en la mayoría de los intercambios occidentales, la tarea de verificar los riesgos no es tan aguda como la nuestra, por lo que a menudo esto se hace fuera de línea. Necesitábamos implementar un cheque en línea.
Vamos a ilustrar con un ejemplo. El comerciante quiere comprar $ 30, y la solicitud va a validar la transacción: verificamos si este comerciante tiene permiso para este modo de negociación, si tiene los derechos necesarios. Si todo está en orden, la solicitud va al sistema de verificación de riesgos, es decir. verificar la suficiencia de fondos para concluir una transacción. Hay una nota de que la cantidad requerida está actualmente bloqueada. Además, la solicitud se redirige al sistema de negociación, que aprueba o no esta transacción. Digamos que la transacción se aprueba, luego el sistema de verificación de riesgos observa que el dinero se desbloquea y los rublos se convierten en dólares.
En general, el sistema de verificación de riesgos contiene algoritmos complejos y realiza una gran cantidad de cálculos muy intensivos en recursos, y no solo verifica el "saldo de la cuenta", como podría parecer a primera vista.
Cuando comenzamos a dividir el proceso del motor en niveles, nos encontramos con un problema: el código que estaba disponible en ese momento en las etapas de validación y verificación usaba activamente la misma matriz de datos, lo que requería reescribir toda la base del código. Como resultado, tomamos prestada una metodología para procesar instrucciones de los procesadores modernos: cada uno de ellos se divide en pequeñas etapas y varias acciones se realizan en paralelo en un ciclo.
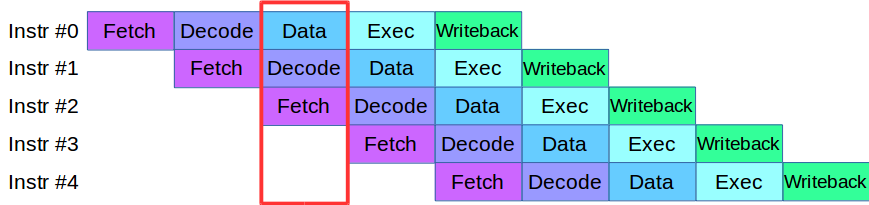
Después de una pequeña adaptación del código, creamos una tubería para el procesamiento paralelo de transacciones, en la cual la transacción se dividió en 4 etapas de la tubería: interacción de red, validación, ejecución y publicación del resultado

Considera un ejemplo. Tenemos dos sistemas de procesamiento, serial y paralelo. Llega la primera transacción, y en ambos sistemas se valida. Luego llega la segunda transacción: en un sistema paralelo, inmediatamente se pone a trabajar, y en un sistema secuencial se pone en cola esperando que la primera transacción pase por la etapa de procesamiento actual. Es decir, la principal ventaja de la canalización es que procesamos la cola de transacciones más rápido.
Entonces tenemos el sistema ASTS +.
Es cierto, también con los transportadores, no todo es tan suave. Supongamos que tenemos una transacción que afecta las matrices de datos en una transacción vecina, esta es una situación típica para el intercambio. Dicha transacción no se puede ejecutar en la tubería, porque puede afectar a otros. Esta situación se denomina riesgo de datos, y tales transacciones simplemente se procesan por separado: cuando finalizan las transacciones "rápidas" en la cola, la tubería se detiene, el sistema procesa la transacción "lenta" y luego comienza la tubería nuevamente. Afortunadamente, la proporción de tales transacciones en el flujo total es muy pequeña, por lo que la tubería se detiene tan raramente que no afecta el rendimiento general.

Luego comenzamos a resolver el problema de sincronizar tres hilos de ejecución. Como resultado, nació un sistema basado en un búfer circular con celdas de tamaño fijo. En este sistema, todo está sujeto a la velocidad de procesamiento, los datos no se copian.
- Todos los paquetes de red entrantes entran en la etapa de asignación.
- Los colocamos en una matriz y marcamos que están disponibles para la etapa No. 1.
- Llegó la segunda transacción, nuevamente está disponible para la etapa No. 1.
- El primer flujo de procesamiento ve las transacciones disponibles, las procesa y las transfiere a la siguiente etapa del segundo flujo de procesamiento.
- Luego procesa la primera transacción y marca la celda correspondiente con la bandera
deleted ; ahora está disponible para un nuevo uso.
Por lo tanto, se procesa toda la cola.
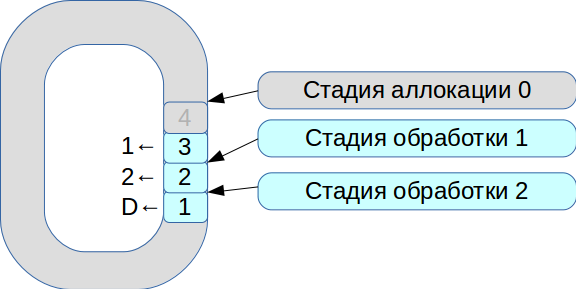
El procesamiento de cada etapa requiere unidades o decenas de microsegundos. Y si utiliza esquemas estándar de sincronización del sistema operativo, perderemos más tiempo en la sincronización misma. Por lo tanto, comenzamos a usar spinlock. Sin embargo, este es un tono muy malo en un sistema de tiempo real, y RedHat recomienda encarecidamente no hacerlo, por lo que usamos spinlock durante 100 ms y luego entramos en modo semáforo para excluir la posibilidad de un punto muerto.
Como resultado, logramos un rendimiento de aproximadamente 8 millones de transacciones por segundo. Y solo dos meses después, en un
artículo sobre LMAX Disruptor, vieron una descripción de un circuito con la misma funcionalidad.
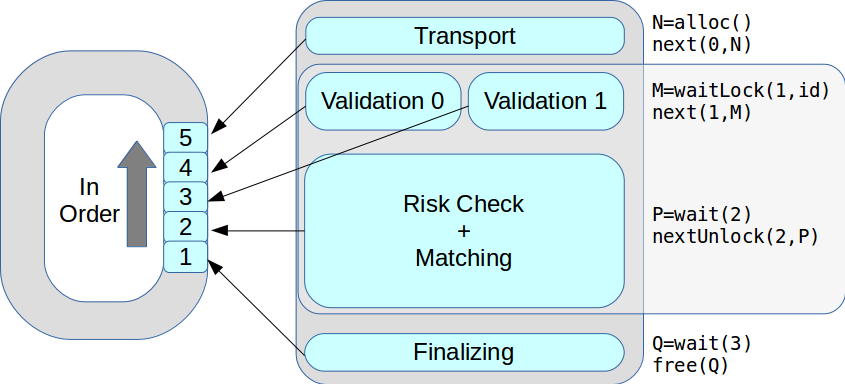
Ahora en una etapa podría haber varios hilos de ejecución. Todas las transacciones se procesaron a su vez, en el orden recibido. Como resultado, el rendimiento máximo aumentó de 18 mil a 50 mil transacciones por segundo.
Sistema de gestión de riesgos cambiarios
La perfección no tiene límites, y pronto comenzamos a modernizarnos nuevamente: en el marco de ASTS +, comenzamos a transferir sistemas de gestión de riesgos y operaciones de liquidación a componentes autónomos. Desarrollamos una arquitectura moderna flexible y un nuevo modelo de riesgo jerárquico, probamos siempre que fue posible usar la clase
fixed_point lugar de
double .
Pero inmediatamente surgió el problema: ¿cómo sincronizar toda la lógica de negocios que ha estado funcionando durante muchos años y transferirla al nuevo sistema? Como resultado, la primera versión del prototipo del nuevo sistema tuvo que ser abandonada. La segunda versión, que actualmente está trabajando en producción, se basa en el mismo código que funciona tanto en la parte comercial como en la de riesgo. Durante el desarrollo, lo más difícil fue hacer que git se fusionara entre las dos versiones. Nuestro colega Evgeny Mazurenok realizó esta operación todas las semanas y maldijo durante mucho tiempo cada vez.
Al seleccionar un nuevo sistema, inmediatamente tuvimos que resolver el problema de interacción. Al elegir un bus de datos, era necesario garantizar una fluctuación estable y un retraso mínimo. Para esto, la red InfiniBand RDMA es la más adecuada: el tiempo de procesamiento promedio es 4 veces menor que en las redes Ethernet de 10 G. Pero la verdadera diferencia estaba en los percentiles: 99 y 99.9.
Por supuesto, InfiniBand tiene sus propias dificultades. Primero, otra API es ibverbs en lugar de sockets. En segundo lugar, casi no hay soluciones de mensajería de código abierto ampliamente disponibles. Intentamos hacer nuestro prototipo, pero resultó ser muy difícil, por lo que elegimos una solución comercial: Confinity Low Latency Messaging (anteriormente IBM MQ LLM).
Entonces surgió el problema de la separación correcta del sistema de riesgo. Si solo elimina el motor de riesgos y no crea un nodo intermedio, las transacciones de dos fuentes pueden mezclarse.
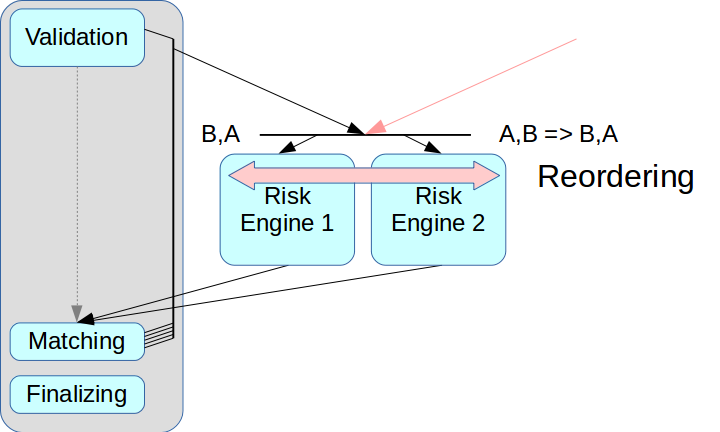
Las llamadas soluciones de ultra baja latencia tienen un modo de reordenamiento: las transacciones de dos fuentes se pueden organizar en el orden correcto al recibirlas, esto se realiza utilizando un canal separado para intercambiar información sobre la secuencia. Pero todavía no aplicamos este modo: complica todo el proceso y, en algunas soluciones, no es compatible en absoluto. Además, cada transacción debería tener asignadas las marcas de tiempo apropiadas, y en nuestro esquema este mecanismo es muy difícil de implementar correctamente. Por lo tanto, utilizamos el esquema clásico con el intermediario de mensajes, es decir, con un despachador que distribuye mensajes entre Risk Engine.
El segundo problema estaba relacionado con el acceso del cliente: si hay varias puertas de enlace de riesgo, el cliente debe conectarse a cada una de ellas, y para ello deberá realizar cambios en la capa del cliente. Queríamos alejarnos de esto en esta etapa, por lo que en el esquema actual de Risk Gateway procesan todo el flujo de datos. Esto limita severamente el rendimiento máximo, pero simplifica enormemente la integración del sistema.
Duplicación
Nuestro sistema no debe tener un solo punto de falla, es decir, todos los componentes deben estar duplicados, incluido un intermediario de mensajes. Resolvimos este problema utilizando el sistema CLLM: contiene un clúster RCMS en el que dos despachadores pueden trabajar en modo maestro-esclavo, y cuando uno falla, el sistema cambia automáticamente al otro.
Trabajar con un centro de datos de respaldo
InfiniBand está optimizado para funcionar como una red local, es decir, para conectar equipos montados en bastidor, y no hay forma de establecer una red InfiniBand entre dos centros de datos distribuidos geográficamente. Por lo tanto, implementamos un puente / despachador que se conecta al almacén de mensajes a través de redes Ethernet regulares y retransmite todas las transacciones a la segunda red IB. Cuando necesite migrar desde el centro de datos, podemos elegir con qué centro de datos trabajar ahora.
Resumen
Todo lo anterior no se hizo a la vez, tomó varias iteraciones del desarrollo de una nueva arquitectura. Creamos el prototipo en un mes, pero tardó más de dos años en finalizar las condiciones de trabajo. Intentamos lograr el mejor compromiso entre aumentar la duración del procesamiento de la transacción y aumentar la confiabilidad del sistema.
Como el sistema se actualizó en gran medida, implementamos la recuperación de datos de dos fuentes independientes. Si por algún motivo el almacén de mensajes no funciona correctamente, puede tomar el registro de transacciones de una segunda fuente: Risk Engine. Este principio se respeta en todo el sistema.
Entre otras cosas, logramos mantener la API del cliente para que ni los corredores ni nadie más requirieran una alteración significativa para la nueva arquitectura. Tuve que cambiar algunas interfaces, pero no tuve que hacer cambios significativos en el modelo de trabajo.
Llamamos a la versión actual de nuestra plataforma Rebus, como abreviatura de las dos innovaciones más notables en arquitectura, Risk Engine y BUS.
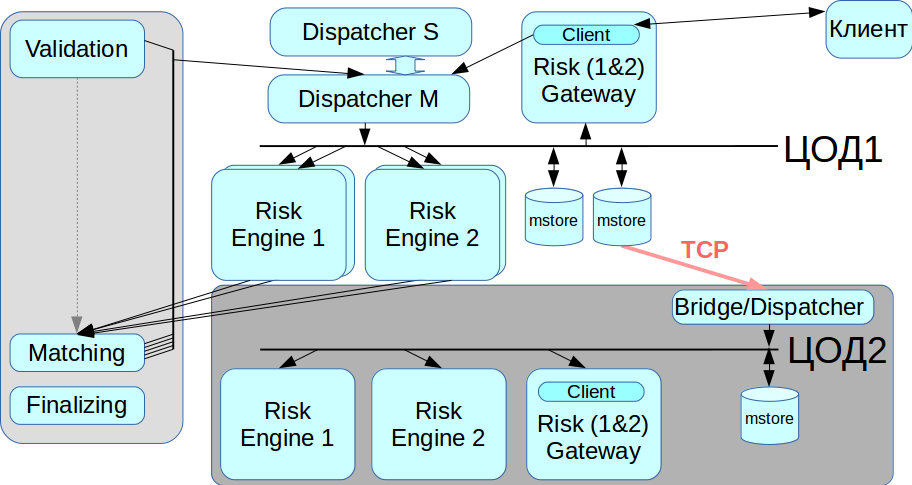
Inicialmente, queríamos resaltar solo la parte de compensación, pero el resultado fue un gran sistema distribuido. Ahora los clientes pueden interactuar con Trading Gateway, con la compensación o con ambos a la vez.
Lo que finalmente logramos:

Reducido el nivel de retraso. Con un pequeño volumen de transacciones, el sistema funciona igual que la versión anterior, pero al mismo tiempo soporta una carga mucho mayor.
La productividad máxima aumentó de 50 mil a 180 mil transacciones por segundo. Una nueva corriente de información está obstaculizando un mayor crecimiento.
Hay dos formas de mejorar aún más: la coincidencia de paralelización y el cambio del esquema de trabajo con Gateway. Ahora todas las puertas de enlace funcionan de acuerdo con el esquema de replicación, que a esta carga deja de funcionar normalmente.Al final, puedo dar algunos consejos a aquellos que están desarrollando sistemas empresariales:- Prepárate para lo peor todo el tiempo. Los problemas siempre surgen inesperadamente.
- Por lo general, es imposible rehacer la arquitectura rápidamente. Especialmente si necesita lograr la máxima confiabilidad en una variedad de indicadores. Cuantos más nodos, más recursos se necesitan para el soporte.
- Todas las soluciones especiales y patentadas requerirán además recursos para investigación, soporte y soporte.
- , .