Solo en los Estados Unidos, hay 3 millones de personas con discapacidad que no pueden abandonar sus hogares. Los robots auxiliares que pueden navegar automáticamente largas distancias pueden hacer que estas personas sean más independientes al llevarles alimentos, medicinas y paquetes. Los estudios muestran que el aprendizaje profundo con refuerzo (OP) es muy adecuado para comparar datos de entrada sin procesar y acciones, por ejemplo, para aprender a
capturar objetos o
mover robots , pero generalmente los
agentes OP carecen de la comprensión de los grandes espacios físicos necesarios para una orientación segura a larga distancia distancias sin ayuda humana y adaptación a un nuevo entorno.
En tres trabajos recientes, "
Entrenamiento de orientación desde cero con AOP ", "
PRM-RL: Implementación de orientación robótica a largas distancias utilizando una combinación de aprendizaje por refuerzo y planificación basada en patrones " y "
Orientación a largo alcance con PRM-RL ", Estudiamos robots autónomos que se adaptan fácilmente a un nuevo entorno, combinando OP profundo con planificación a largo plazo. Enseñamos a los agentes de planificación locales cómo realizar las acciones básicas necesarias para la orientación y cómo moverse distancias cortas sin colisiones con objetos en movimiento. Los planificadores locales realizan observaciones ambientales ruidosas utilizando sensores como lidares unidimensionales que proporcionan distancia a un obstáculo y proporcionan velocidades lineales y angulares para controlar el robot. Capacitamos al planificador local en simulaciones utilizando el aprendizaje de refuerzo automático (AOP), un método que automatiza la búsqueda de recompensas para el OP y la arquitectura de la red neuronal. A pesar del alcance limitado de 10-15 m, los planificadores locales se adaptan bien tanto para su uso en robots reales como para entornos nuevos y previamente desconocidos. Esto le permite usarlos como bloques de construcción para orientarse en espacios grandes. Luego construimos una hoja de ruta, un gráfico donde los nodos son secciones separadas, y los bordes conectan los nodos solo si los planificadores locales, imitando bien a los robots reales que usan sensores y controles ruidosos, pueden moverse entre ellos.
Aprendizaje automático de refuerzo (AOP)
En
nuestro primer trabajo, capacitamos a un planificador local en un pequeño entorno estático. Sin embargo, cuando se aprende con el algoritmo estándar de OP profunda, por ejemplo, el gradiente determinista profundo (
DDPG ), existen varios obstáculos. Por ejemplo, el objetivo real de los planificadores locales es lograr un objetivo determinado, por lo que reciben recompensas poco frecuentes. En la práctica, esto requiere que los investigadores pasen un tiempo considerable en la implementación paso a paso del algoritmo y el ajuste manual de los premios. Los investigadores también tienen que tomar decisiones sobre la arquitectura de las redes neuronales sin tener recetas claras y exitosas. Finalmente, los algoritmos como DDPG aprenden de manera inestable y a menudo exhiben
olvidos catastróficos .
Para superar estos obstáculos, automatizamos el aprendizaje profundo con refuerzo. AOP es un envoltorio automático evolutivo alrededor de un OP profundo, que busca recompensas y arquitectura de red neuronal a través
de la optimización de hiperparámetros a gran escala . Funciona en dos etapas, la búsqueda de recompensas y la búsqueda de arquitectura. Durante la búsqueda de recompensas, AOP entrena simultáneamente a la población de agentes DDPG durante varias generaciones, y cada uno tiene su propia función de recompensa ligeramente modificada, optimizada para la verdadera tarea del planificador local: llegar al punto final del camino. Al final de la fase de búsqueda de recompensas, seleccionamos uno que con mayor frecuencia lleva a los agentes a la meta. En la fase de búsqueda de la arquitectura de la red neuronal, repetimos este proceso, utilizando el premio seleccionado para esta carrera y ajustando las capas de la red, optimizando el premio acumulativo.
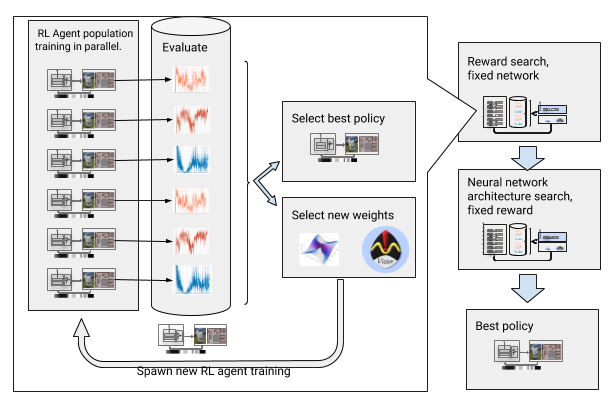 AOP con la búsqueda de premios y arquitectura de la red neuronal
AOP con la búsqueda de premios y arquitectura de la red neuronalSin embargo, este proceso paso a paso hace que AOP sea ineficaz en términos del número de muestras. ¡El entrenamiento AOP con 10 generaciones de 100 agentes requiere 5 mil millones de muestras, lo que equivale a 32 años de estudio! La ventaja es que después del AOP, el proceso de aprendizaje manual está automatizado y DDPG no tiene olvidos catastróficos. Lo que es más importante, la calidad de las políticas finales es mayor: son resistentes al ruido del sensor, la unidad y la localización, y están bien generalizadas a nuevos entornos. Nuestra mejor política es un 26% más exitosa que otros métodos de orientación en nuestros sitios de prueba.
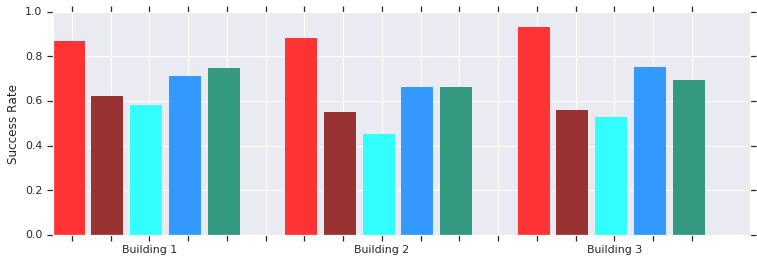 Rojo - AOP tiene éxito a distancias cortas (hasta 10 m) en varios edificios previamente desconocidos. Comparación con DDPG entrenado manualmente (rojo oscuro), campos de potencial artificial (azul), ventana dinámica (azul) y clonación de comportamiento (verde).La política del planificador de AOP local funciona bien con robots en entornos reales no estructurados
Rojo - AOP tiene éxito a distancias cortas (hasta 10 m) en varios edificios previamente desconocidos. Comparación con DDPG entrenado manualmente (rojo oscuro), campos de potencial artificial (azul), ventana dinámica (azul) y clonación de comportamiento (verde).La política del planificador de AOP local funciona bien con robots en entornos reales no estructuradosY aunque estos políticos solo son capaces de orientación local, son resistentes a obstáculos en movimiento y son bien tolerados por robots reales en entornos no estructurados. Y aunque fueron entrenados en simulaciones con objetos estáticos, efectivamente hacen frente a los que se mueven. El siguiente paso es combinar las políticas de AOP con la planificación basada en muestras para expandir su área de trabajo y enseñarles a navegar largas distancias.
Orientación a larga distancia con PRM-RL
Los planificadores basados en patrones trabajan con orientación de largo alcance, aproximando los movimientos del robot. Por ejemplo, un robot construye
hojas de ruta probabilísticas (PRM) al dibujar rutas de transición entre secciones. En nuestro
segundo trabajo , que ganó el premio en la conferencia
ICRA 2018 , combinamos PRM con programadores OP locales sintonizados manualmente (sin AOP) para entrenar robots localmente y luego adaptarlos a otros entornos.
Primero, para cada robot, entrenamos la política del planificador local en una simulación generalizada. Luego creamos un PRM teniendo en cuenta esta política, el llamado PRM-RL, basado en un mapa del entorno donde se utilizará. La misma tarjeta se puede usar para cualquier robot que deseamos usar en el edificio.
Para crear un PRM-RL, combinamos nodos de muestras solo si el programador de OP local puede moverse de manera confiable y repetida entre ellos. Esto se hace en una simulación de Monte Carlo. El mapa resultante se adapta a las capacidades y la geometría de un robot en particular. Las tarjetas para robots con la misma geometría, pero con diferentes sensores y unidades, tendrán una conectividad diferente. Dado que el agente puede girar alrededor de la esquina, los nodos que no están en línea directa también pueden activarse. Sin embargo, los nodos adyacentes a las paredes y los obstáculos tendrán menos probabilidades de ser incluidos en el mapa debido al ruido del sensor. En tiempo de ejecución, el agente de OP se mueve por el mapa de una sección a otra.
 Se crea un mapa con tres simulaciones de Monte Carlo para cada par de nodos seleccionados al azar
Se crea un mapa con tres simulaciones de Monte Carlo para cada par de nodos seleccionados al azar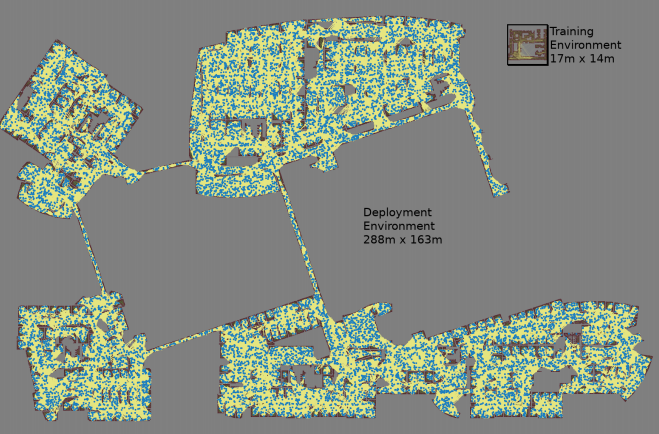 El mapa más grande tenía un tamaño de 288x163 m y contenía casi 700,000 bordes. 300 trabajadores lo recogieron durante 4 días, después de haber realizado 1.100 millones de controles de colisión.El tercer trabajo
El mapa más grande tenía un tamaño de 288x163 m y contenía casi 700,000 bordes. 300 trabajadores lo recogieron durante 4 días, después de haber realizado 1.100 millones de controles de colisión.El tercer trabajo proporciona varias mejoras al PRM-RL original. En primer lugar, estamos reemplazando el DDPG sintonizado manualmente con programadores locales de AOP, lo que mejora la orientación a largas distancias. En segundo lugar, se agregan
mapas de localización y marcado simultáneo (
SLAM ), que los robots usan en tiempo de ejecución como fuente para construir mapas de ruta. Las tarjetas SLAM están sujetas a ruido, y esto cierra la "brecha entre el simulador y la realidad", un problema bien conocido en robótica, debido a que los agentes entrenados en simulaciones se comportan mucho peor en el mundo real. Nuestro nivel de éxito en la simulación coincide con el nivel de éxito de los robots reales. Y finalmente, agregamos mapas de construcción distribuidos, para que podamos crear mapas muy grandes que contengan hasta 700,000 nodos.
Evaluamos este método con la ayuda de nuestro agente de AOP, que creó mapas basados en dibujos de edificios que excedían el entorno de capacitación 200 veces en el área, incluidas solo costillas, que se completaron con éxito en el 90% de los casos en 20 intentos. Comparamos PRM-RL con varios métodos a distancias de hasta 100 m, que excedieron seriamente el alcance del planificador local. PRM-RL logró el éxito 2-3 veces más a menudo que los métodos convencionales debido a la conexión correcta de los nodos, adecuados para las capacidades del robot.
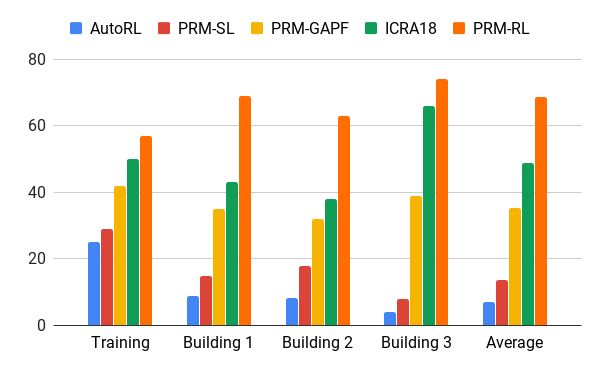 Tasa de éxito en el movimiento de 100 m en diferentes edificios. Azul: planificador local de AOP, primer trabajo; rojo - PRM original; amarillo - campos de potencial artificial; el verde es el segundo trabajo; rojo - el tercer trabajo, PRM con AOP.
Tasa de éxito en el movimiento de 100 m en diferentes edificios. Azul: planificador local de AOP, primer trabajo; rojo - PRM original; amarillo - campos de potencial artificial; el verde es el segundo trabajo; rojo - el tercer trabajo, PRM con AOP.Probamos PRM-RL en muchos robots reales en muchos edificios. A continuación se muestra una de las suites de prueba; el robot se mueve de manera confiable en casi todos lados, excepto en los lugares más desordenados y áreas que van más allá de la tarjeta SLAM.

Conclusión
La orientación de la máquina puede aumentar seriamente la independencia de las personas con discapacidades de movilidad. Esto se puede lograr desarrollando robots autónomos que puedan adaptarse fácilmente al entorno y los métodos disponibles para la implementación en el nuevo entorno basados en la información existente. Esto se puede hacer automatizando el entrenamiento de orientación básica para distancias cortas con AOP, y luego utilizando las habilidades adquiridas junto con las tarjetas SLAM para crear hojas de ruta. Las hojas de ruta consisten en nodos conectados por costillas, sobre los cuales los robots pueden moverse de manera confiable. Como resultado, se desarrolla una política de comportamiento del robot que, después de un entrenamiento, puede usarse en diferentes entornos y emitir hojas de ruta especialmente adaptadas para un robot en particular.