La última vez que hablamos sobre la consistencia de los datos, observamos la diferencia entre los diferentes niveles de aislamiento de transacciones a través de los ojos del usuario, y descubrimos por qué es importante saberlo. Ahora estamos comenzando a aprender cómo PostgreSQL implementa el aislamiento basado en instantáneas y las versiones múltiples.
En este artículo, veremos cómo se ubican físicamente los datos en archivos y páginas. Esto nos aleja del tema del aislamiento, pero tal digresión es necesaria para comprender más material. Necesitamos entender cómo funciona el almacenamiento de datos de bajo nivel.
Relaciones
Si mira dentro de las tablas e índices, resulta que están organizados de manera similar. Tanto eso como otro: objetos base que contienen algunos datos que consisten en líneas.
El hecho de que la tabla consta de filas está fuera de toda duda; para el índice, esto es menos obvio. Sin embargo, imagine un árbol B: consta de nodos que contienen valores indexados y enlaces a otros nodos o filas de la tabla. Estos nodos pueden considerarse líneas de índice, de hecho, tal como están.
De hecho, todavía hay varios objetos organizados de manera similar: secuencias (esencialmente tablas de una sola fila), vistas materializadas (esencialmente tablas que recuerdan la consulta). Y luego están las vistas habituales, que por sí mismas no almacenan datos, pero en todos los demás sentidos son similares a las tablas.
Todos estos objetos en PostgreSQL se denominan la
relación de palabra común. La palabra es extremadamente desafortunada porque es un término de la teoría relacional. Puede establecer un paralelismo entre la relación y la tabla (vista), pero ciertamente no entre la relación y el índice. Pero sucedió: las raíces académicas de PostgreSQL se hacen sentir. Creo que al principio se llamaba tablas y vistas, y el resto creció con el tiempo.
Además, por simplicidad, solo hablaremos de tablas e índices, pero el resto de las
relaciones están estructuradas exactamente de la misma manera.
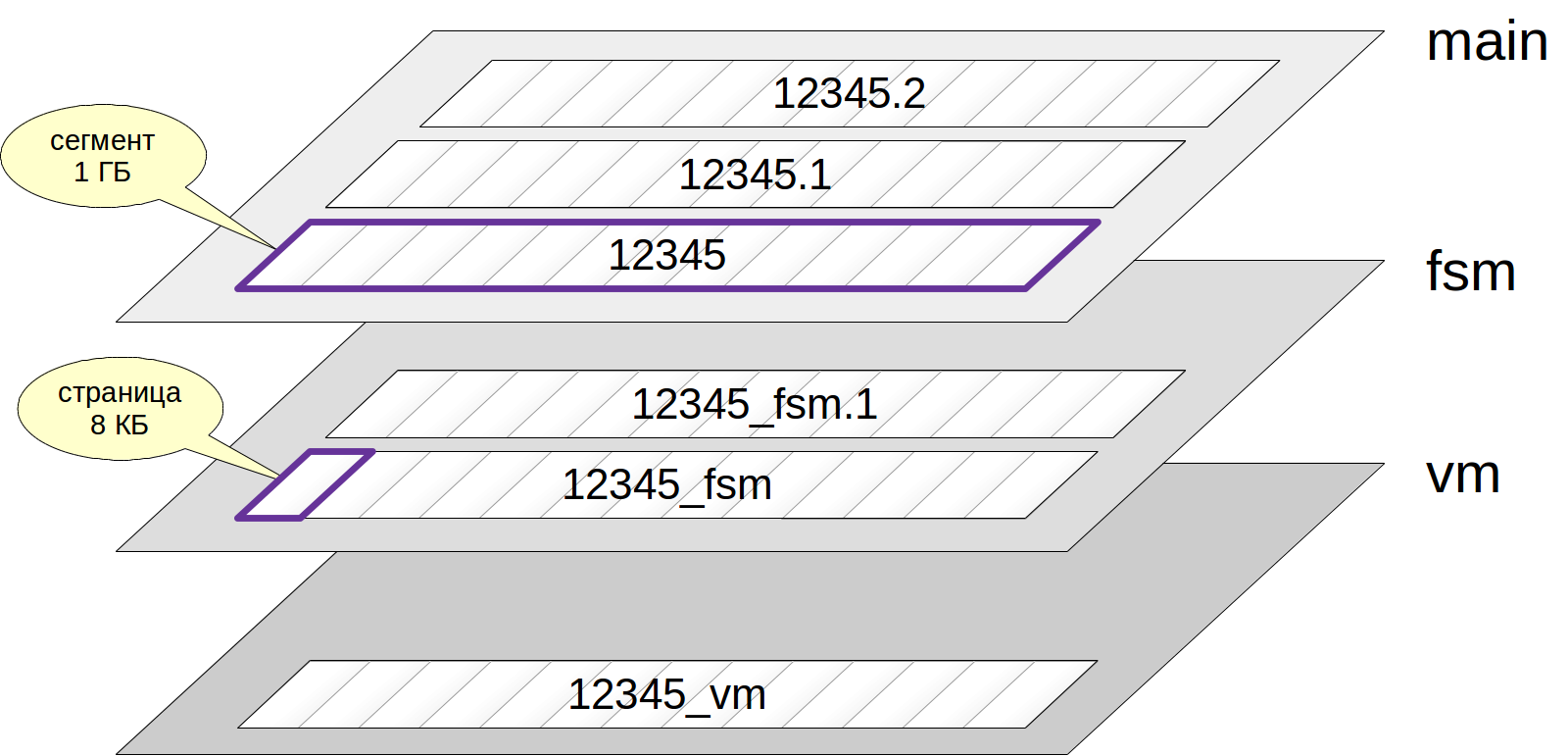
Capas (horquillas) y archivos
Por lo general, cada relación tiene varias
capas (horquillas). Las capas son de varios tipos y cada una de ellas contiene un cierto tipo de datos.
Si hay una capa, al principio está representada por un solo
archivo . El nombre del archivo consta de un identificador numérico al que se puede agregar el final correspondiente al nombre de la capa.
El archivo crece gradualmente y cuando su tamaño alcanza 1 GB, se crea el siguiente archivo de la misma capa (a veces, estos archivos se denominan
segmentos ). El número de segmento se agrega al final del nombre del archivo.
La limitación de tamaño de archivo de 1 GB ha surgido históricamente para admitir varios sistemas de archivos, algunos de los cuales no pueden funcionar con archivos grandes. La restricción se puede cambiar al construir PostgreSQL (
./configure --with-segsize ).
Por lo tanto, varios archivos pueden corresponder a una relación en un disco. Por ejemplo, para una mesa pequeña habrá 3 de ellos.
Todos los archivos de objetos que pertenecen a un espacio de tabla y una base de datos se colocarán en un directorio. Esto debe tenerse en cuenta porque los sistemas de archivos generalmente no funcionan muy bien con una gran cantidad de archivos en un directorio.
Solo tenga en cuenta que los archivos, a su vez, se dividen en
páginas (o
bloques ), generalmente de 8 KB. Hablaremos sobre la estructura interna de las páginas a continuación.
Ahora veamos los tipos de capas.
La capa principal son los datos en sí: la misma tabla o filas de índice. La capa principal existe para cualquier relación (excepto para las representaciones que no contienen datos).
Los nombres de los archivos en la capa principal consisten solo en un identificador numérico. Aquí hay una ruta de ejemplo al archivo de tabla que creamos la última vez:
=> SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41496 (1 row)
¿De dónde vienen estos identificadores? El directorio base corresponde al espacio de tabla pg_default, el siguiente subdirectorio corresponde a la base de datos y el archivo que nos interesa ya está en él:
=> SELECT oid FROM pg_database WHERE datname = 'test';
oid ------- 41493 (1 row)
=> SELECT relfilenode FROM pg_class WHERE relname = 'accounts';
relfilenode ------------- 41496 (1 row)
La ruta es relativa, se cuenta desde el directorio de datos (PGDATA). Además, casi todas las rutas en PostgreSQL se cuentan desde PGDATA. Gracias a esto, puede transferir PGDATA de forma segura a otro lugar: no contiene nada (a menos que necesite configurar la ruta a las bibliotecas en LD_LIBRARY_PATH).
Buscamos más en el sistema de archivos:
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41496
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41496
Existe una capa de inicialización solo para tablas no registradas (creadas con UNLOGGED) y sus índices. Dichos objetos no son diferentes de los ordinarios, excepto que las acciones con ellos no se registran en el registro de pregrabación. Debido a esto, trabajar con ellos es más rápido, pero en caso de falla es imposible restaurar los datos en un estado consistente. Por lo tanto, al restaurar PostgreSQL simplemente elimina todas las capas de dichos objetos y escribe la capa de inicialización en el lugar de la capa principal. El resultado es un "maniquí". Hablaremos sobre el diario en detalle, pero en un ciclo diferente.
La tabla de cuentas se registra en diario, por lo que no hay una capa de inicialización para ella. Pero para el experimento, puede deshabilitar el registro:
=> ALTER TABLE accounts SET UNLOGGED; => SELECT pg_relation_filepath('accounts');
pg_relation_filepath ---------------------- base/41493/41507 (1 row)
La capacidad de habilitar y deshabilitar el diario sobre la marcha, como se puede ver en el ejemplo, implica sobrescribir datos en archivos con diferentes nombres.
La capa de inicialización tiene el mismo nombre que la capa principal, pero con el sufijo "_init":
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_init
-rw------- 1 postgres postgres 0 /var/lib/postgresql/11/main/base/41493/41507_init
Mapa del espacio libre (mapa del espacio libre): una capa en la que hay un espacio vacío dentro de las páginas. Este lugar cambia constantemente: cuando se agregan nuevas versiones de cadenas, disminuye, mientras que la limpieza aumenta. El mapa de espacio libre se utiliza al insertar nuevas versiones de filas para encontrar rápidamente una página adecuada en la que se ajusten los datos que se agregarán.
El mapa de espacio libre tiene el sufijo "_fsm". Pero el archivo no aparece de inmediato, sino solo si es necesario. La forma más fácil de lograr esto es limpiar la mesa (por qué, hablemos a su debido tiempo):
=> VACUUM accounts;
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_fsm
-rw------- 1 postgres postgres 24576 /var/lib/postgresql/11/main/base/41493/41507_fsm
Un mapa de visibilidad es una capa en la que las páginas que contienen solo versiones actuales de cadenas están marcadas con un bit. En términos generales, esto significa que cuando una transacción intenta leer una línea de dicha página, la línea se puede mostrar sin verificar su visibilidad. Examinaremos en detalle cómo sucede esto en los siguientes artículos.
postgres$ ls -l --time-style=+ /var/lib/postgresql/11/main/base/41493/41507_vm
-rw------- 1 postgres postgres 8192 /var/lib/postgresql/11/main/base/41493/41507_vm
Páginas
Como ya dijimos, los archivos se dividen lógicamente en páginas.
Por lo general, una página tiene un tamaño de 8 KB. El tamaño dentro de algunos límites se puede cambiar (16 KB o 32 KB), pero solo durante el ensamblaje (
./configure --with-blocksize ). La instancia ensamblada y en ejecución puede funcionar con páginas de un solo tamaño.
Independientemente de a qué capa pertenecen los archivos, el servidor los utiliza aproximadamente de la misma manera. Las páginas se leen primero en la memoria caché del búfer, donde los procesos pueden leerlas y modificarlas; luego, si es necesario, las páginas se devuelven al disco.
Cada página tiene un marcado interno y generalmente contiene las siguientes secciones:
0 + ----------------------------------- +
El | rumbo |
24 + ----------------------------------- +
El | matriz de punteros a cadenas de versión |
inferior + ----------------------------------- +
El | espacio libre |
superior + ----------------------------------- +
El | versiones de fila |
especial + ----------------------------------- +
El | área especial |
tamaño de página + ----------------------------------- +
El tamaño de estas secciones es fácil de descubrir con la extensión de inspección de la página de "investigación":
=> CREATE EXTENSION pageinspect; => SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('accounts',0));
lower | upper | special | pagesize -------+-------+---------+---------- 40 | 8016 | 8192 | 8192 (1 row)
Aquí miramos el
título de la primera página (cero) de la tabla. Además del tamaño de las áreas restantes, el encabezado contiene otra información sobre la página, pero aún no nos interesa.
Al final de la página hay un
área especial , en nuestro caso, vacía. Se usa solo para índices, y luego no para todos. El "fondo" aquí corresponde a la imagen; quizás sería más correcto decir "en direcciones altas".
A continuación del área especial están
las versiones de fila : los mismos datos que almacenamos en la tabla, más información general.
En la parte superior de la página, inmediatamente después del encabezado, se encuentra la tabla de contenido: una
matriz de punteros a la versión de las líneas disponibles en la página.
Entre las versiones de líneas y punteros puede haber
espacio libre (que está marcado en el mapa de espacio libre). Tenga en cuenta que no hay fragmentación dentro de la página, todo el espacio libre siempre está representado por un fragmento.
Punteros
¿Por qué son necesarios los punteros a las versiones de cadena? El hecho es que las filas de índice deben referirse de alguna manera a la versión de las filas en la tabla. Está claro que el enlace debe contener el número de archivo, el número de página en el archivo y alguna indicación de la versión de la línea. Un desplazamiento desde el comienzo de la página podría usarse como una indicación, pero esto es inconveniente. No podríamos mover la versión de la línea dentro de la página porque rompería los enlaces existentes. Y esto conduciría a la fragmentación del espacio dentro de las páginas y otras consecuencias desagradables. Por lo tanto, el índice se refiere al número de índice y el puntero se refiere a la posición actual de la versión de fila en la página. Resulta el direccionamiento indirecto.
Cada puntero ocupa exactamente 4 bytes y contiene:
- enlace a la versión de la cadena;
- la longitud de esta versión de la cadena;
- varios bits que determinan el estado de la versión de una cadena.
Formato de datos
El formato de datos en el disco coincide completamente con la representación de los datos en la RAM. La página se lee en la memoria caché del búfer "tal cual", sin ninguna transformación. Por lo tanto, los archivos de datos de una plataforma son incompatibles con otras plataformas.
Por ejemplo, en la arquitectura x86, el orden de bytes se adopta del menos significativo al más alto (little-endian), z / Architecture usa el orden inverso (big-endian), y en ARM el orden de cambio.
Muchas arquitecturas proporcionan alineación de datos a través de los límites de palabras de máquina. Por ejemplo, en un sistema x86 de 32 bits, los enteros (tipo entero, ocupa 4 bytes) se alinearán en el borde de las palabras de 4 bytes, así como los números de coma flotante de precisión doble (tipo de precisión doble, 8 bytes). Y en un sistema de 64 bits, los valores dobles se alinearán en el borde de las palabras de 8 bytes. Esta es otra razón de incompatibilidad.
Debido a la alineación, el tamaño de la fila de la tabla depende del orden de los campos. Por lo general, este efecto no es muy notable, pero en algunos casos puede conducir a un aumento significativo de tamaño. Por ejemplo, si coloca los campos char (1) y entero mezclados, generalmente se perderán 3 bytes entre ellos. Puede ver más sobre esto en la presentación de Nikolai Shaplov "
What's Inside It ".
Versiones de cadenas y tostadas
Acerca de cómo se organizan las versiones de cadenas desde adentro, hablaremos en detalle la próxima vez. Hasta ahora, lo único importante para nosotros es que cada versión debe caber completamente en una página: PostgreSQL no proporciona una forma de "continuar" la línea en la página siguiente. En cambio, se utiliza una tecnología llamada TOAST (Técnica de almacenamiento de atributos de gran tamaño). El nombre en sí sugiere que la cadena se puede cortar en tostadas.
Hablando en serio, TOAST involucra varias estrategias. Los valores de los atributos "largos" se pueden enviar a una tabla de servicio separada, previamente cortada en pequeñas tostadas. Otra opción es comprimir el valor para que la versión de la fila todavía se ajuste a una página de tabla normal. Y es posible tanto eso como otro: al principio comprimir, y solo luego cortar y enviar.
Para cada tabla principal, si es necesario, se crea una tabla TOAST separada (pero una para todos los atributos). La necesidad está determinada por la presencia de atributos potencialmente largos en la tabla. Por ejemplo, si una tabla tiene una columna de tipo numérico o texto, se creará una tabla TOAST de inmediato, incluso si no se utilizan valores largos.
Dado que la tabla TOAST es esencialmente una tabla normal, todavía tiene el mismo conjunto de capas. Y esto duplica la cantidad de archivos que "sirven" la tabla.
Inicialmente, las estrategias están determinadas por los tipos de datos de columna. Puede verlos con el comando
\d+ en psql, pero como también muestra mucha otra información, utilizaremos la solicitud en el directorio del sistema:
=> SELECT attname, atttypid::regtype, CASE attstorage WHEN 'p' THEN 'plain' WHEN 'e' THEN 'external' WHEN 'm' THEN 'main' WHEN 'x' THEN 'extended' END AS storage FROM pg_attribute WHERE attrelid = 'accounts'::regclass AND attnum > 0;
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | extended client | text | extended amount | numeric | main (4 rows)
Los nombres de las estrategias tienen los siguientes significados:
- plain - TOAST no se usa (se usa para tipos de datos obviamente "cortos", como el entero);
- extendido: tanto la compresión como el almacenamiento en una tabla TOAST separada están permitidos;
- externo: los valores largos se almacenan en la tabla TOAST sin comprimir;
- main - los valores largos se comprimen primero y solo en la tabla TOAST si la compresión no ayudó.
En términos generales, el algoritmo es el siguiente. PostgreSQL quiere que al menos 4 líneas quepan en una página. Por lo tanto, si el tamaño de la línea excede la cuarta parte de la página, teniendo en cuenta el encabezado (con una página normal de 8K, esto es 2040 bytes), se debe aplicar TOAST a parte de los valores. Actuamos en el orden descrito a continuación y nos detenemos tan pronto como la línea deja de exceder el umbral:
- Primero, clasificamos los atributos con estrategias externas y extendidas, pasando del más largo al más corto. Los atributos extendidos se comprimen (si esto tiene un efecto) y, si el valor en sí excede un cuarto de la página, se envía inmediatamente a la tabla TOAST. Los atributos externos se manejan de la misma manera, pero no se comprimen.
- Si después de la primera pasada la versión de la fila aún no se ajusta, enviamos los atributos restantes con las estrategias externas y extendidas a la tabla TOAST.
- Si esto tampoco ayuda, intente comprimir los atributos con la estrategia principal, mientras los deja en la página de la tabla.
- Y solo si después de eso la fila aún no es lo suficientemente corta, los atributos principales se envían a la tabla TOAST.
A veces puede ser útil cambiar la estrategia para algunas columnas. Por ejemplo, si se sabe de antemano que los datos de la columna no están comprimidos, puede establecer una estrategia externa para ello; esto ahorrará en intentos de compresión inútiles. Esto se hace de la siguiente manera:
=> ALTER TABLE accounts ALTER COLUMN number SET STORAGE external;
Repitiendo la solicitud, obtenemos:
attname | atttypid | storage ---------+----------+---------- id | integer | plain number | text | external client | text | extended amount | numeric | main
Las tablas e índices TOAST se encuentran en un esquema pg_toast separado y, por lo tanto, generalmente no son visibles. Para las tablas temporales, se utiliza el esquema pg_toast_temp_
N , similar al pg_temp_
N. habitual
.Por supuesto, si lo desea, nadie se molesta en echar un vistazo a la mecánica interna del proceso. Digamos que hay tres atributos potencialmente largos en la tabla de cuentas, por lo que debe ser una tabla TOAST. Aquí esta:
=> SELECT relnamespace::regnamespace, relname FROM pg_class WHERE oid = ( SELECT reltoastrelid FROM pg_class WHERE relname = 'accounts' );
relnamespace | relname --------------+---------------- pg_toast | pg_toast_33953 (1 row)
=> \d+ pg_toast.pg_toast_33953
TOAST table "pg_toast.pg_toast_33953" Column | Type | Storage ------------+---------+--------- chunk_id | oid | plain chunk_seq | integer | plain chunk_data | bytea | plain
Es lógico que para las "tostadas" en las que se corta la línea, se aplica la estrategia simple: la TOSTADA del segundo nivel no existe.
El índice PostgreSQL se oculta con más cuidado, pero también es fácil de encontrar:
=> SELECT indexrelid::regclass FROM pg_index WHERE indrelid = ( SELECT oid FROM pg_class WHERE relname = 'pg_toast_33953' );
indexrelid ------------------------------- pg_toast.pg_toast_33953_index (1 row)
=> \d pg_toast.pg_toast_33953_index
Unlogged index "pg_toast.pg_toast_33953_index" Column | Type | Key? | Definition -----------+---------+------+------------ chunk_id | oid | yes | chunk_id chunk_seq | integer | yes | chunk_seq primary key, btree, for table "pg_toast.pg_toast_33953"
La columna del cliente utiliza la estrategia extendida: los valores en ella se comprimirán. Comprobar:
=> UPDATE accounts SET client = repeat('A',3000) WHERE id = 1; => SELECT * FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | chunk_data ----------+-----------+------------ (0 rows)
No hay nada en la tabla TOAST: los caracteres que se repiten se comprimen perfectamente y luego el valor cabe en una página de tabla normal.
Ahora deje que el nombre del cliente consista en caracteres aleatorios:
=> UPDATE accounts SET client = ( SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000) ) WHERE id = 1 RETURNING left(client,10) || '...' || right(client,10);
?column? ------------------------- TCKGKZZSLI...RHQIOLWRRX (1 row)
Esta secuencia no se puede comprimir y cae en la tabla TOAST:
=> SELECT chunk_id, chunk_seq, length(chunk_data), left(encode(chunk_data,'escape')::text, 10) || '...' || right(encode(chunk_data,'escape')::text, 10) FROM pg_toast.pg_toast_33953;
chunk_id | chunk_seq | length | ?column? ----------+-----------+--------+------------------------- 34000 | 0 | 2000 | TCKGKZZSLI...ZIPFLOXDIW 34000 | 1 | 1000 | DDXNNBQQYH...RHQIOLWRRX (2 rows)
Como puede ver, los datos se cortan en fragmentos de 2000 bytes.
Al acceder a un valor "largo", PostgreSQL automáticamente, transparente para la aplicación, restaura el valor original y lo devuelve al cliente.
Por supuesto, se gastan muchos recursos en compresión en rodajas y recuperación posterior. Por lo tanto, almacenar datos voluminosos en PostgreSQL no es una buena idea, especialmente si se usa activamente y no se requiere lógica transaccional para ellos (como un ejemplo: originales escaneados de documentos contables). Una alternativa más rentable podría ser almacenar dichos datos en el sistema de archivos y, en el DBMS, los nombres de los archivos correspondientes.
Una tabla TOAST se usa solo cuando se refiere a un valor "largo". Además, la tabla de tostado tiene su propio control de versiones: si la actualización de datos no afecta el valor "largo", la nueva versión de la fila se referirá al mismo valor en la tabla de TOAST; esto ahorra espacio.
Tenga en cuenta que TOAST solo funciona para tablas, pero no para índices. Esto impone un límite en el tamaño de las claves indexadas.
Puede leer más sobre la organización interna de datos en la documentación .
Continuará