El paquete tidyr es parte del núcleo de una de las bibliotecas más populares en el lenguaje R: tidyverse .
El objetivo principal del paquete es llevar los datos a una apariencia ordenada.
En Habré ya hay una publicación dedicada a este paquete, pero data de 2015. Y quiero contarles sobre los cambios más relevantes anunciados hace unos días por su autor Hadley Wickham.
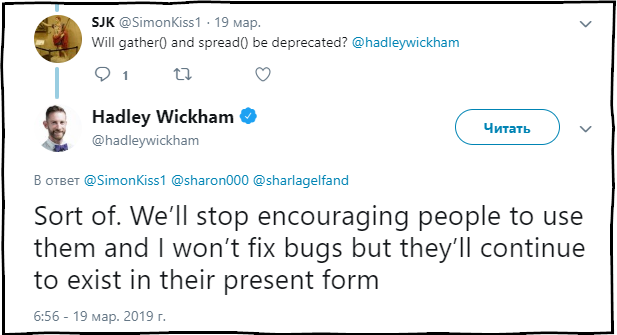
SJK : ¿Las funciones de recopilación () y difusión () quedarán en desuso?
Hadley Wickham : Hasta cierto punto. Dejaremos de recomendar el uso de estas funciones y de corregir errores en ellas, pero continuarán estando presentes en el paquete en el estado actual.
Contenido
Concepto TidyData
El propósito de tidyr es ayudarlo a llevar los datos a una apariencia aparentemente ordenada. Los datos precisos son datos donde:
- Cada variable está en una columna.
- Cada observación es una línea.
- Cada valor es una celda.
Los datos que se dan a los datos ordenados son mucho más simples y convenientes para trabajar durante el análisis.
Las principales funciones incluidas en el paquete tidyr
tidyr contiene un conjunto de funciones para transformar tablas:
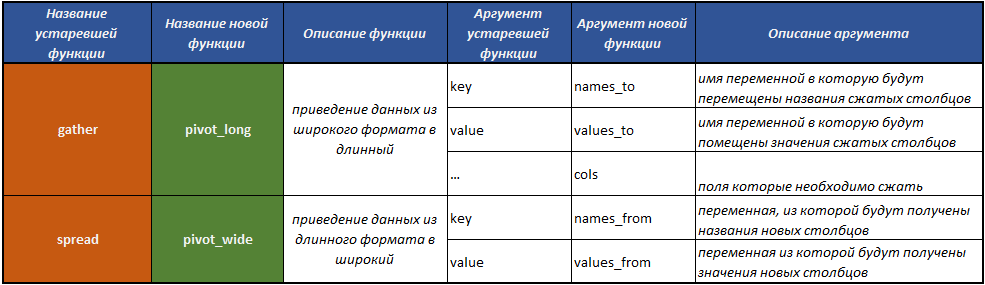
fill() - rellenando los valores faltantes en la columna con los valores anteriores;separate() : divide un campo en varios a través de un separador;unite() : realiza la operación de combinar varios campos en uno, el inverso de la función separate() ;pivot_longer() - una función que convierte datos de un formato ancho a uno largo;pivot_wider() - una función que convierte datos de un formato largo a uno ancho. La operación es la opuesta a la realizada por la función pivot_longer() .gather() desuso : una función que convierte los datos de un formato ancho a uno largo;spread() desuso - una función que convierte los datos de un formato largo a uno ancho. La operación es la opuesta a la que realiza la función gather() .
Anteriormente, las funciones gather() y spread() usaban para este tipo de transformación. A lo largo de los años de la existencia de estas funciones, se ha vuelto obvio que para la mayoría de los usuarios, incluido el autor del paquete, los nombres de estas funciones y sus argumentos no eran del todo obvios, y causaron dificultades para encontrarlas y comprender cuál de estas funciones lleva el marco de fecha de ancho a largo formato y viceversa.
A este respecto, se agregaron dos nuevas funciones importantes a tidyr , que están diseñadas para transformar marcos de fecha.
Las nuevas funciones pivot_longer() y pivot_wider() se inspiraron en algunas de las funciones del paquete cdata creado por John Mount y Nina Zumel.
Instalar la versión más reciente de tidyr 0.8.3.9000
Para instalar la nueva versión más reciente del paquete tidyr 0.8.3.9000 , en el que hay nuevas funciones disponibles, use el siguiente código.
devtools::install_github("tidyverse/tidyr")
Al momento de escribir, estas funciones solo están disponibles en la versión de desarrollo del paquete en GitHub.
Cambiar a nuevas funciones
De hecho, no es difícil transferir scripts antiguos para trabajar con nuevas funciones, para una mejor comprensión, tomaré un ejemplo de la documentación de funciones antiguas y mostraré cómo se realizan estas mismas operaciones utilizando las nuevas funciones pivot_*() .
Convierta formato ancho a largo.
Código de muestra de la documentación de la función de recopilación # example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
Convirtiendo un formato largo a ancho.
Código de muestra de la documentación de la función de propagación # old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
Porque En los ejemplos anteriores de trabajar con pivot_longer() y pivot_wider() , en las existencias de la tabla de origen no hay columnas enumeradas en los argumentos names_to y values_to, sus nombres deben indicarse entre comillas.
La tabla con la ayuda de la cual descubrirá más fácilmente cómo pasar a trabajar con el nuevo concepto tidyr .
Nota del autor
Todo el texto a continuación es adaptable, incluso diría una traducción gratuita de la viñeta desde el sitio oficial de la biblioteca tidyverse.
pivot_longer () : alarga los conjuntos de datos al disminuir el número de columnas y aumentar el número de filas.

Para ejecutar los ejemplos presentados en el artículo, primero debe conectar los paquetes necesarios:
library(tidyr) library(dplyr) library(readr)
Supongamos que tenemos una tabla con los resultados de una encuesta en la que (entre otras cosas) se les preguntó a las personas sobre su religión e ingresos anuales:
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
Esta tabla contiene datos de religión de encuestados en filas, y los niveles de ingresos están dispersos en los nombres de columna. El número de encuestados de cada categoría se almacena en los valores de las celdas en la intersección de la religión y el nivel de ingresos. Para llevar la tabla a un formato ordenado y correcto, simplemente use pivot_longer() :
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
Argumentos a pivot_longer()
- El primer argumento, cols , describe qué columnas combinar. En este caso, todas las columnas excepto el tiempo .
- El argumento names_to da el nombre de la variable que se creará a partir de los nombres de columna que combinamos.
- values_to proporciona el nombre de la variable que se creará a partir de los datos almacenados en los valores de celda de las columnas unidas.
Especificaciones
Esta es la nueva funcionalidad del paquete tidyr , que anteriormente no estaba disponible cuando se trabajaba con funciones obsoletas.
Una especificación es un marco de datos, cada fila de la cual corresponde a una columna en un nuevo marco de fecha de salida, y dos columnas especiales que comienzan con:
- .name contiene el nombre original de la columna.
- .value contiene el nombre de la columna en la que irán los valores de las celdas.
Las columnas restantes de la especificación reflejan cómo se mostrará el nombre de las columnas compresibles de .name en la nueva columna.
La especificación describe los metadatos almacenados en el nombre de la columna, con una fila para cada columna y una columna para cada variable combinada con el nombre de la columna, probablemente esta definición parece confusa ahora, pero después de considerar algunos ejemplos, todo se volverá mucho más claro.
El significado de la especificación es que puede recuperar, modificar y establecer nuevos metadatos para el marco de datos convertido.
La función pivot_longer_spec() se pivot_longer_spec() para trabajar con especificaciones al convertir una tabla de un formato ancho a uno largo.
Cómo funciona esta función, toma cualquier marco de fecha y genera sus metadatos como se describe anteriormente.
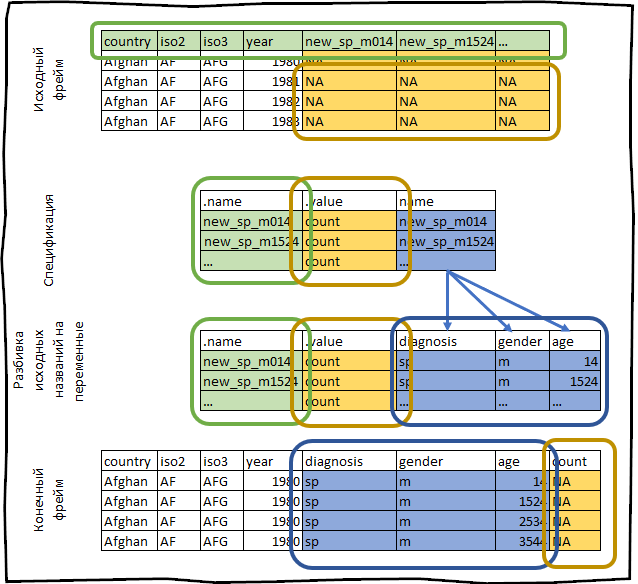
Por ejemplo, tomemos el conjunto de datos who que viene con el paquete tidyr . Este conjunto de datos contiene información proporcionada por la organización internacional de salud sobre la incidencia de tuberculosis.
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
Construimos su especificación.
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
Los campos país , iso2 , iso3 ya son variables. Nuestra tarea es voltear las columnas de new_sp_m014 a newrel_f65 .
Los nombres de estas columnas almacenan la siguiente información:
- El prefijo
new_ indica que la columna contiene datos sobre nuevos casos de tuberculosis, el marco de fecha actual contiene información solo sobre nuevas enfermedades, por lo tanto, este prefijo en el contexto actual no tiene ningún significado. sp / rel / sp / ep describe un método para diagnosticar una enfermedad.m / f género del paciente.014 rango de edad del paciente.
Podemos separar estas columnas usando la función extract() usando una expresión regular.
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
Tenga en cuenta que la columna .name debe permanecer sin cambios, ya que este es nuestro índice en los nombres de columna del conjunto de datos de origen.
El género y la edad (columnas de género y edad ) tienen valores fijos y conocidos, por lo tanto, se recomienda convertir estas columnas en factores:
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
Finalmente, para aplicar la especificación que creamos a la fecha original del marco who , necesitamos usar el argumento spec en la función pivot_longer() .
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
Todo lo que acabamos de hacer puede representarse esquemáticamente de la siguiente manera:
Especificación utilizando múltiples valores (.value)
En el ejemplo anterior, la columna de especificación .value contenía solo un valor, en la mayoría de los casos esto sucede.
Pero ocasionalmente puede surgir una situación en la que necesita recopilar datos de columnas con diferentes tipos de datos en los valores. Usando la función spread() desuso, esto sería bastante difícil.
El siguiente ejemplo está tomado de la viñeta para el paquete data.table .
Creemos un marco de datos de entrenamiento.
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
El marco de fecha creado en cada fila contiene datos sobre los hijos de una familia. Las familias pueden tener uno o dos hijos. Para cada niño, se proporcionan datos sobre la fecha de nacimiento y el sexo, y los datos para cada niño están en columnas separadas, nuestra tarea es llevar estos datos al formato correcto para el análisis.
Tenga en cuenta que tenemos dos variables con información sobre cada niño: su género y fecha de nacimiento (las columnas con el prefijo dop contienen la fecha de nacimiento, las columnas con el prefijo género contienen el género del niño). En el resultado esperado, deben ir en columnas separadas. Podemos hacer esto generando una especificación en la que la columna .value tendrá dos valores diferentes.
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
Entonces, veamos los pasos que realiza el código anterior.
pivot_longer_spec(-family) : crea una especificación que comprime todas las columnas disponibles, excepto la columna de la familia.separate(col = name, into = c(".value", "child")) : separa la columna .name , que contiene los nombres de los campos de origen, subrayados y coloca los valores en las columnas .value y child .mutate(child = parse_number(child)) : convierte los valores del campo hijo de texto a tipo de datos numéricos.
Ahora podemos aplicar la especificación recibida al marco de datos inicial y llevar la tabla a la forma deseada.
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
Usamos el argumento na.rm = TRUE , porque el formulario de datos actual nos obliga a crear filas adicionales para observaciones inexistentes. Porque la familia 2 solo tiene un hijo, na.rm = TRUE asegura que la familia 2 tendrá una línea en la salida.
pivot_wider() : es la transformación inversa, y viceversa, aumenta el número de columnas en la fecha del cuadro al reducir el número de filas.
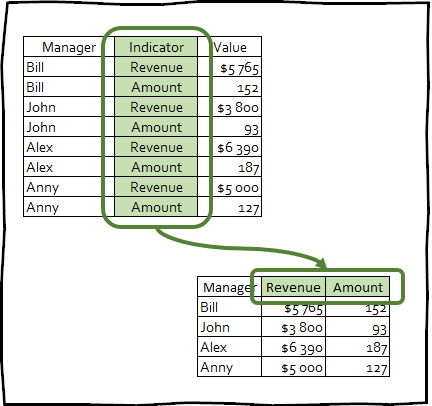
Este tipo de transformación rara vez se usa para llevar los datos a una apariencia ordenada, sin embargo, esta técnica puede ser útil para crear tablas dinámicas utilizadas en presentaciones o para integrarse con cualquier otra herramienta.
De hecho, las funciones pivot_longer() y pivot_wider() son simétricas y realizan acciones opuestas, es decir: df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec) y df %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec) devolverá el df original.
Para demostrar el funcionamiento de la función pivot_wider() , utilizaremos el conjunto de datos fish_encounters , que almacena información sobre cómo varias estaciones registran el movimiento de los peces a lo largo del río.
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
En la mayoría de los casos, esta tabla será más informativa y conveniente de usar si proporciona información para cada estación en una columna separada.
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
Este conjunto de datos registra información solo cuando la estación detectó el pescado, es decir Si algún pez no fue reparado por alguna estación, entonces estos datos no estarán en la tabla. Esto significa que la salida será poblada por NA.
Sin embargo, en este caso, sabemos que la ausencia de un registro significa que el pez no se notó, por lo que podemos usar el argumento values_fill en la función pivot_wider() y completar estos valores faltantes con ceros:
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
Generando un nombre de columna a partir de múltiples variables de origen
Imagine que tenemos una tabla que contiene una combinación de producto, país y año. Para generar una fecha de marco de prueba, puede ejecutar el siguiente código:
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
Nuestra tarea es expandir el marco de fecha para que una columna contenga datos para cada combinación de producto y país. Para hacer esto, simplemente pase el vector que contiene los nombres de los campos que se unirán al argumento names_from .
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
También puede aplicar especificaciones a la función pivot_wider() . Pero cuando se alimenta a pivot_wider() especificación hace lo contrario de pivot_longer() : las columnas especificadas en .name se crean utilizando valores de .value y otras columnas.
Para este conjunto de datos, puede generar una especificación de usuario si desea que cada combinación posible de país y producto tenga su propia columna, y no solo las que están presentes en los datos:
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
Algunos ejemplos avanzados de trabajo con el nuevo concepto tidyr
Traer datos a una apariencia ordenada usando el conjunto de datos del censo de ingresos y alquiler de EE. UU. Como ejemplo
El conjunto de datos us_rent_income contiene información sobre el ingreso promedio y el alquiler de cada estado en los EE. UU. Para 2017 (el conjunto de datos está disponible en el paquete tidycensus ).
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
Es extremadamente inconveniente trabajar con ellos en la forma en que se almacenan los datos en el conjunto de datos us_rent_income, por lo que nos gustaría crear un conjunto de datos con columnas: rent , rent_moe , come , ingreso_moe . Hay muchas formas de crear esta especificación, pero lo principal es que necesitamos generar cada combinación de los valores de las variables y estimar / moe , y luego generar el nombre de la columna.
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
Proporcionar esta especificación a pivot_wider() nos da el resultado que estamos buscando:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
Banco Mundial
A veces, llevar el conjunto de datos al formulario correcto requiere varios pasos.
El conjunto de datos world_bank_pop contiene datos del Banco Mundial sobre la población de cada país desde 2000 hasta 2018.
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
Nuestro objetivo es crear un conjunto de datos ordenado donde cada variable esté en una columna separada. Todavía no está claro qué pasos son necesarios, pero comenzaremos con el problema más obvio: el año se distribuye en varias columnas.
Para solucionar esto, debe usar la función pivot_longer() .
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
Conclusión
, tidyr , spread() gather() . pivot_longer() pivot_wider() .