A veces, para resolver un problema, solo necesita mirarlo desde un ángulo diferente. Incluso si en los últimos 10 años tales problemas se han resuelto de la misma manera con diferentes efectos, no es un hecho que este método sea el único.
Existe un tema como la pérdida de clientes. La cosa es inevitable, porque los clientes de cualquier compañía pueden tomar y dejar de usar sus productos o servicios por muchas razones. Por supuesto, para la empresa, el flujo de salida es una acción natural, pero no la más deseable, por lo que todos están tratando de minimizar este flujo de salida. Y aún mejor: para predecir la probabilidad de una salida de una categoría particular de usuarios, o un usuario específico, y ofrecer algunos pasos de retención.
Analice e intente mantener al cliente, si es posible, al menos por las siguientes razones:
- atraer nuevos clientes es más costoso que los procedimientos de retención . Para atraer nuevos clientes, por regla general, debe gastar algo de dinero (publicidad), mientras que los clientes existentes pueden activarse con una oferta especial con condiciones especiales;
- Comprender por qué los clientes se van es la clave para mejorar los productos y servicios .
Existen enfoques estándar para pronosticar los flujos de salida. Pero en uno de los campeonatos de IA, decidimos tomar y probar la distribución de Weibull para esto. La mayoría de las veces se usa para análisis de supervivencia, pronóstico del tiempo, análisis de desastres naturales, ingeniería industrial y similares. La distribución de Weibull es una función de distribución especial parametrizada por dos parámetros.
y
.
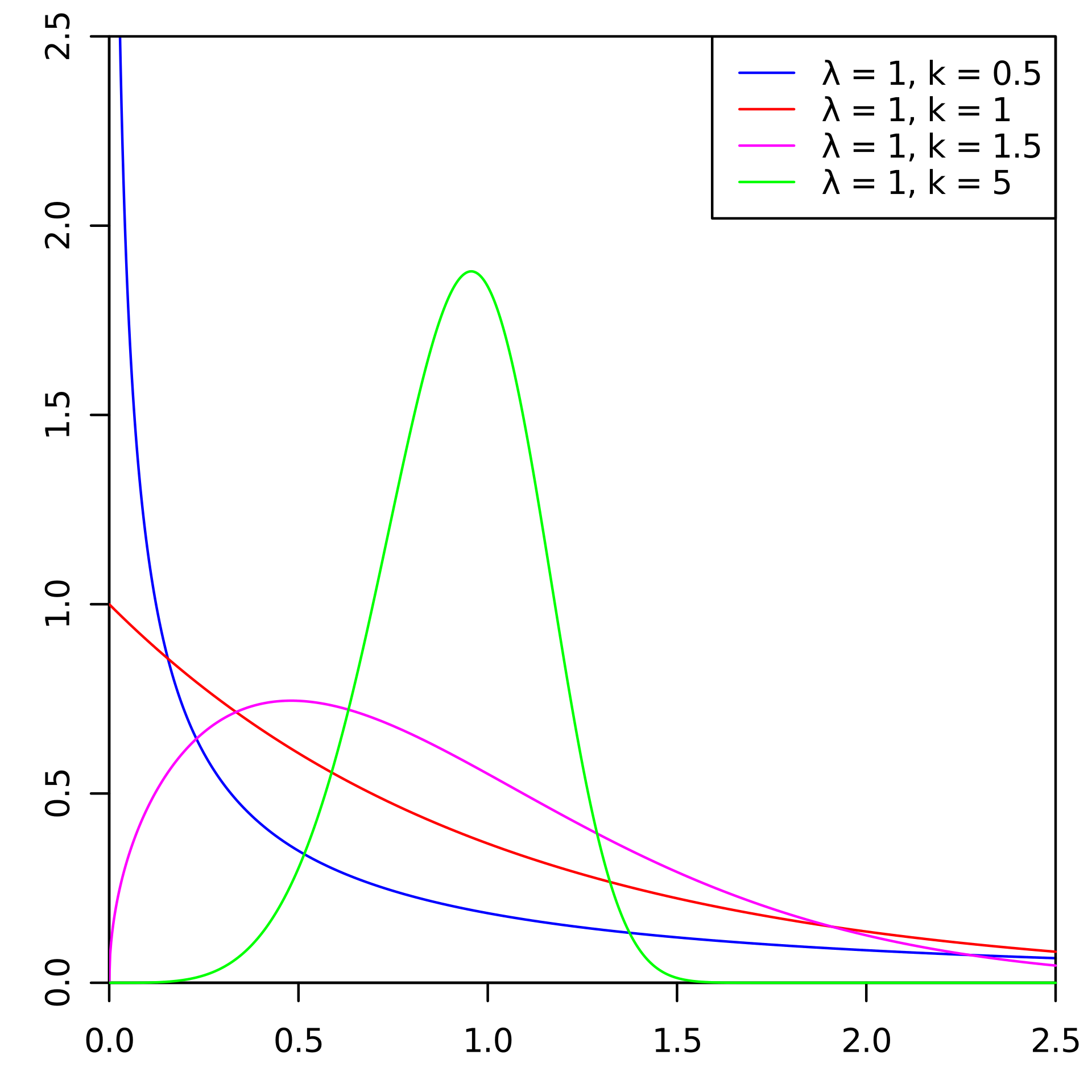 Wikipedia
WikipediaEn general, la cosa es entretenida, pero para predecir el flujo de salida, y de hecho en fintech, no se usa con tanta frecuencia. Debajo del corte, le diremos cómo nosotros (el Laboratorio de Minería de Datos) lo hicimos al ganar oro en el Campeonato AI en la nominación de "AI en los Bancos".
Sobre el flujo de salida en general
Veamos un poco qué es la salida del cliente y por qué es tan importante. Para los negocios, la base de clientes es importante. Los nuevos clientes acuden a esta base de datos, por ejemplo, después de enterarse de un producto o servicio de la publicidad, viven un tiempo (usan los productos activamente) y después de un tiempo dejan de usarlo. Este período se denomina "Ciclo de vida del cliente" (es decir, Ciclo de vida del cliente), un término que describe los pasos que sigue el cliente cuando se entera de un producto, toma una decisión de compra, paga, usa y se convierte en un cliente fiel, y finalmente deja de usar por una razón u otros productos. En consecuencia, el flujo de salida es la etapa final del ciclo de vida del cliente cuando el cliente deja de usar los servicios, y para los negocios esto significa que el cliente ha dejado de ser rentable y en general cualquier beneficio.
Cada cliente del banco es una persona específica que selecciona una tarjeta bancaria específica específicamente para sus necesidades. A menudo viaja: un mapa con millas es útil. Él compra mucho: hola, tarjeta con devolución de dinero. Él compra mucho en tiendas específicas, y para esto ya hay un plástico afiliado especial. Por supuesto, a veces también se selecciona una tarjeta de acuerdo con el criterio de "Servicio más barato". En general, hay suficientes variables aquí.
Y otra persona elige el banco en sí mismo: ¿vale la pena elegir una tarjeta bancaria, cuyas sucursales solo se encuentran en Moscú y en la región cuando eres de Khabarovsk? Si la tarjeta de dicho banco es al menos 2 veces más rentable, la presencia de sucursales bancarias cercanas sigue siendo un criterio importante. Sí, 2019 ya está aquí y lo digital es nuestro todo, pero una serie de problemas para algunos bancos solo se pueden resolver en la sucursal. Además, una vez más, una parte de la población confía en un banco físico mucho más que una aplicación en un teléfono inteligente, esto también debe tenerse en cuenta.
Como resultado, una persona puede tener muchas razones para rechazar los productos del banco (o del banco mismo). Él cambió su trabajo, y la tarifa de la tarjeta cambió de un salario a "Para simples mortales", que es menos rentable. Se mudó a otra ciudad donde no hay sucursales bancarias. No me gustaba hablar con un operador no calificado en el departamento. Es decir, puede haber incluso más razones para cerrar una cuenta que para usar un producto.
Y el cliente no solo puede expresar explícitamente su intención: ir al banco y escribir una declaración, sino simplemente dejar de usar los productos sin romper el contrato. Aquí, para comprender tales problemas, se decidió utilizar el aprendizaje automático y la inteligencia artificial.
Además, la salida de clientes puede ocurrir en cualquier industria (telecomunicaciones, proveedores de Internet, compañías de seguros, en general, donde haya una base de clientes y transacciones periódicas).
Que hemos hecho
En primer lugar, era necesario describir un límite claro, desde cuándo comenzamos a considerar que el cliente se había ido. Desde el punto de vista del banco que nos proporcionó los datos para el trabajo, el estado de actividad del cliente era binario: está activo o no. Había un indicador ACTIVE_FLAG en la tabla "Actividad", cuyo valor podría ser "0" o "1" (respectivamente, "Inactivo" y "Activo"). Y todo estaría bien, pero la persona es tal que puede usarlo activamente por un tiempo, y luego dejar de estar activo durante un mes: se enferma, se va a otro país a descansar o incluso va a probar la tarjeta de otro banco. O tal vez después de un largo período de inactividad, nuevamente comience a usar los servicios del banco
Por lo tanto, decidimos llamar al período de inactividad un cierto período continuo de tiempo durante el cual el indicador se estableció como "0".
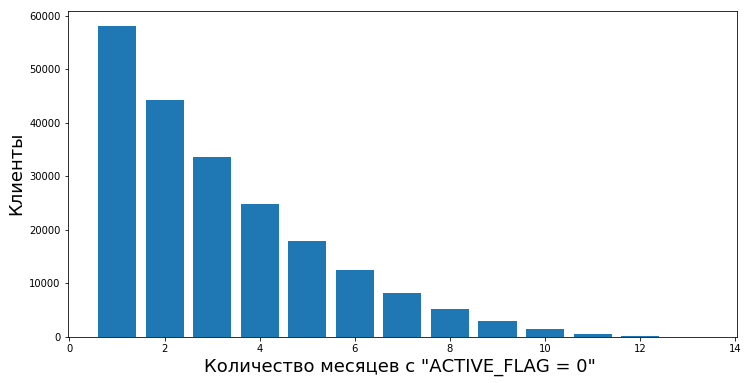
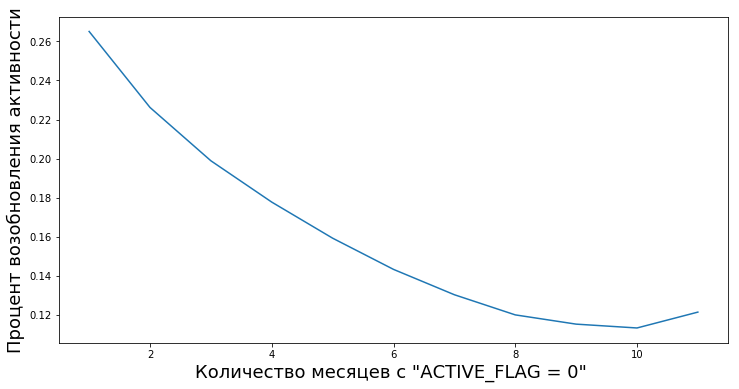
Los clientes pasan de inactivos a activos después de períodos de inactividad de varias longitudes. Tenemos la oportunidad de calcular el grado de valor empírico "confiabilidad de los períodos de inactividad", es decir, la probabilidad de que una persona vuelva a comenzar a usar los productos del banco después de una inactividad temporal.
Por ejemplo, este gráfico muestra la reanudación de la actividad (ACTIVE_FLAG = 1) de los clientes después de varios meses de inactividad (ACTIVE_FLAG = 0).
Aquí aclararemos un poco el conjunto de datos con el que comenzamos a trabajar. Entonces, el banco proporcionó información agregada durante 19 meses en las siguientes tablas:
- “Actividad”: transacciones mensuales de clientes (con tarjeta, en la banca por Internet y en la banca móvil), incluida la información de nómina y facturación.
- "Tarjetas": datos de todas las tarjetas que tiene un cliente, con un programa detallado de tarifas.
- “Contratos”: información sobre los contratos de los clientes (tanto abiertos como cerrados): préstamos, depósitos, etc., indicando los parámetros de cada uno.
- “Clientes”: un conjunto de datos demográficos (género y edad) y la disponibilidad de datos de contacto.
Para el trabajo, necesitábamos todas las tablas excepto el "Mapa".
La dificultad aquí era otra cosa: en estos datos, el banco no indicó qué tipo de actividad tuvo lugar en las tarjetas. Es decir, podríamos entender si hubo transacciones o no, pero ya no pudimos determinar su tipo. Por lo tanto, no estaba claro si el cliente retiraba efectivo, si recibía un salario o si gastaba dinero en compras. Y no teníamos datos sobre saldos de cuentas, lo que sería útil.
La muestra en sí era imparcial: para esta sección durante 19 meses, el banco no hizo ningún intento por retener a los clientes y minimizar el flujo de salida.
Entonces, sobre los períodos de inactividad.
Para formular la definición de flujo de salida, debe elegir un período de inactividad. Para crear un pronóstico de salida a la vez
, debe tener un historial de clientes de al menos 3 meses en el intervalo
. Nuestra historia se limitó a 19 meses, por lo que decidimos tomar un período de inactividad de 6 meses, si corresponde. Y durante el período mínimo para un pronóstico cualitativo tomaron 3 meses. Cifras a los 3 y 6 meses que tomamos empíricamente en base a un análisis del comportamiento de los datos del cliente.
La definición de flujo de salida que formulamos de la siguiente manera: flujo de salida mensual del cliente
este es el primer mes con ACTIVE_FLAG = 0, donde al menos seis ceros seguidos en el campo ACTIVE_FLAG se han estado ejecutando desde este mes, en otras palabras, el mes desde el cual el cliente ha estado inactivo durante 6 meses.
 Numero de clientes difuntos
Numero de clientes difuntos Cantidad de clientes restantes
Cantidad de clientes restantesComo se considera salida
En tales competiciones, y de hecho en la práctica, los flujos de salida a menudo se predicen de esta manera. El cliente utiliza productos y servicios a diferentes intervalos de tiempo; los datos sobre la interacción con él se presentan en forma de un vector de características de longitud fija n. La mayoría de las veces esta información incluye:
- Datos específicos del usuario (datos demográficos, segmento de marketing).
- La historia del uso de productos y servicios bancarios (estas son acciones del cliente que siempre están vinculadas a un tiempo o período específico del intervalo que necesitamos).
- Datos externos, si pueden obtenerlos, por ejemplo, revisiones de redes sociales.
Y después de eso derivan la definición de flujo de salida, propia para cada tarea. Luego usan el algoritmo de aprendizaje automático, que predice la probabilidad de que el cliente se vaya
basado en el vector de factores
. Para aprender el algoritmo, se utiliza uno de los marcos conocidos para construir conjuntos de árboles de decisión,
XGBoost ,
LightGBM ,
CatBoost o sus modificaciones.
El algoritmo en sí no es malo, pero en términos de pronóstico de flujo de salida, tiene varias desventajas serias.
- No tiene la llamada "memoria" . La entrada del modelo recibe un número dado de características que corresponden al momento actual en el tiempo. Para establecer información sobre el historial de cambios en los parámetros, es necesario calcular características especiales que caracterizan los cambios en los parámetros a lo largo del tiempo, por ejemplo, el número o la cantidad de transacciones bancarias en los últimos 1.2.3 meses. Tal enfoque solo puede reflejar parcialmente la naturaleza de los cambios temporales.
- Horizonte de pronóstico fijo. El modelo puede predecir el flujo de salida de los clientes solo durante un período predeterminado, por ejemplo, un pronóstico con un mes de anticipación. Si necesita un pronóstico para otro período de tiempo, por ejemplo, durante tres meses, debe reconstruir el conjunto de entrenamiento y volver a capacitar al nuevo modelo.
Nuestro enfoque
Decidimos de inmediato que no usaríamos enfoques estándar. Además de nosotros, 497 personas se registraron en el campeonato, cada una de las cuales tuvo una buena experiencia. Por lo tanto, tratar de hacer algo de manera estándar en tales condiciones no es una buena idea.
Y comenzamos a resolver los problemas que enfrenta el modelo de clasificación binaria prediciendo la distribución probabilística de los tiempos de salida del cliente.
Aquí se puede ver un enfoque similar; permite una predicción más flexible del flujo de salida y probar hipótesis más complejas que en el enfoque clásico. Como una familia de distribuciones que simula el tiempo de salida, elegimos la
distribución de Weibull para su uso generalizado en el análisis de supervivencia. El comportamiento del cliente puede verse como una especie de supervivencia.
Aquí hay ejemplos de distribuciones de densidad de probabilidad de Weibull que dependen de parámetros
y
:
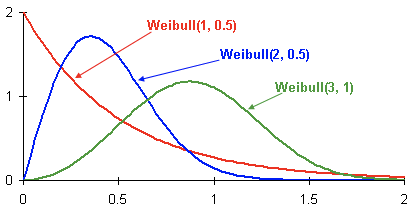
Esta es la distribución de densidad de probabilidad de la rotación de clientes de tres clientes diferentes a lo largo del tiempo. El tiempo se presenta en meses. En otras palabras, este gráfico muestra cuándo es más probable que el cliente salga en los próximos dos meses. Como puede ver, un cliente con una distribución tiene un gran potencial para irse antes que los clientes con una distribución Weibull (2, 0.5) y Weibull (3.1).
El resultado es un modelo que para cada cliente para cualquier
del mes predice los parámetros de distribución de Weibull, que mejor reflejan el inicio de la probabilidad de salida a lo largo del tiempo. Si más detalles:
- Características objetivo en la muestra de capacitación: el tiempo restante antes de la salida en un mes en particular para un cliente en particular.
- Si no hay un indicador de flujo de salida para el cliente, asumimos que el tiempo de flujo de salida es mayor que la cantidad de meses, comenzando desde el actual y hasta el final de nuestro historial.
- El modelo utilizado: una red neuronal recurrente con una capa LSTM.
- Como función de pérdida, utilizamos la función de probabilidad logarítmica negativa para la distribución de Weibull.
Estas son las ventajas de este método:
- La distribución probabilística, además de la posibilidad obvia de clasificación binaria, le permite predecir de manera flexible varios eventos, por ejemplo, si el cliente deja de usar los servicios del banco dentro de los 3 meses. Además, si es necesario, se pueden promediar varias métricas sobre esta distribución.
- La red neuronal recurrente LSTM tiene memoria y usa eficientemente todo el historial. Con la expansión o el refinamiento de la historia, la precisión crece.
- El enfoque se puede ampliar sin problemas al dividir los intervalos de tiempo en otros más pequeños (por ejemplo, al dividir meses en semanas).
Pero no es suficiente crear un buen modelo, también debe evaluar adecuadamente su calidad.
¿Cómo evaluar la calidad?
Como métrica, elegimos Lift Curve. Se utiliza en los negocios para tales casos debido a una interpretación comprensible; se describe bien
aquí y
aquí . Si describe el significado de esta métrica en una oración, obtiene "¿Cuántas veces el algoritmo hace la mejor predicción en la primera
% que al azar ".
Entrenamos modelos
Las condiciones de competencia no establecieron una métrica de calidad específica por la cual se puedan comparar varios modelos y enfoques. Además, la definición del concepto de flujo de salida puede ser diferente y puede depender de la declaración del problema, que, a su vez, está determinada por los objetivos comerciales. Por lo tanto, para entender qué método es mejor, entrenamos dos modelos:
- Un enfoque de clasificación binaria de uso frecuente que utiliza el algoritmo de aprendizaje automático de un conjunto de árbol de decisión ( LightGBM );
- Modelo Weibull-LSTM
La muestra de prueba consistió en 500 clientes preseleccionados que no estaban en la muestra de capacitación. Para el modelo, los hiperparámetros se seleccionaron mediante validación cruzada por parte del cliente. Para entrenar cada modelo, se utilizaron los mismos conjuntos de atributos.
Debido al hecho de que el modelo no tiene memoria, se tomaron signos especiales, que muestran la proporción de cambios en los parámetros de un mes al valor promedio de los parámetros en los últimos tres meses. Lo que caracterizó la tasa de cambio de valores en el último período de tres meses. Sin esto, un modelo basado en Random Forest estaría en una posición previamente perdedora en relación con Weibull-LSTM.
¿Por qué LSTM con distribución Weibull es mejor que el enfoque basado en el conjunto de árboles de decisión?
Aquí, todo es, literalmente, literalmente un par de imágenes.
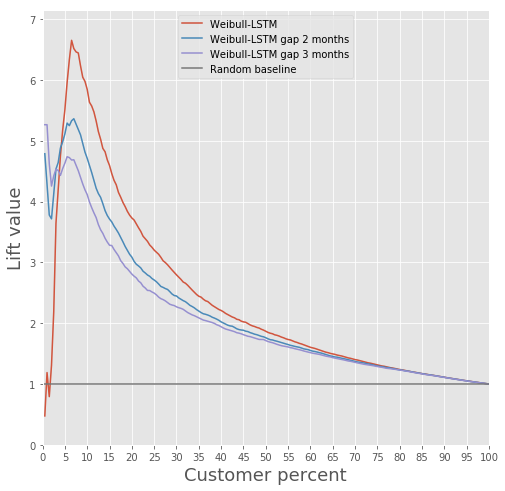 Comparación de la curva de elevación para el algoritmo clásico y Weibull-LSTM
Comparación de la curva de elevación para el algoritmo clásico y Weibull-LSTM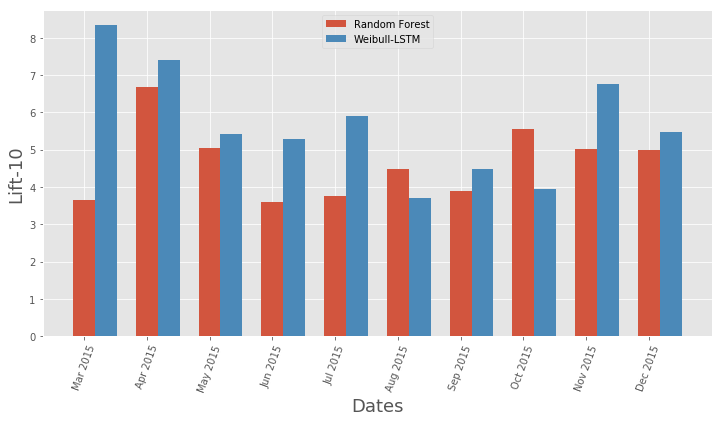 Comparación métrica de la curva de elevación mensual para el algoritmo clásico y Weibull-LSTM
Comparación métrica de la curva de elevación mensual para el algoritmo clásico y Weibull-LSTMEn general, LSTM hace el algoritmo clásico en casi todos los casos.
Predicción de salida
Un modelo basado en una red neuronal recurrente con células LSTM con una distribución Weibull puede predecir el flujo de salida de antemano, por ejemplo, predecir la salida de un cliente en los próximos n meses. Considere el caso para n = 3. En este caso, para cada mes, la red neuronal debe determinar correctamente si el cliente se irá desde el próximo mes hasta el enésimo mes. En otras palabras, debe determinar correctamente si el cliente permanecerá después de n meses. Esto puede considerarse una predicción por adelantado: predecir el momento en que el cliente comenzó a pensar en cómo irse.
Compare la curva de elevación para Weibull-LSTM 1, 2 y 3 meses antes del flujo de salida:
Ya escribimos anteriormente que los pronósticos que se hacen para los clientes que no están activos durante algún tiempo también son importantes. Por lo tanto, aquí agregaremos a la muestra los casos en los que el cliente fallecido ya ha estado inactivo durante uno o dos meses, y verificaremos que Weibull-LSTM clasifique correctamente tales casos como flujo de salida. Dado que tales casos estaban presentes en la muestra, esperamos que la red los maneje bien:
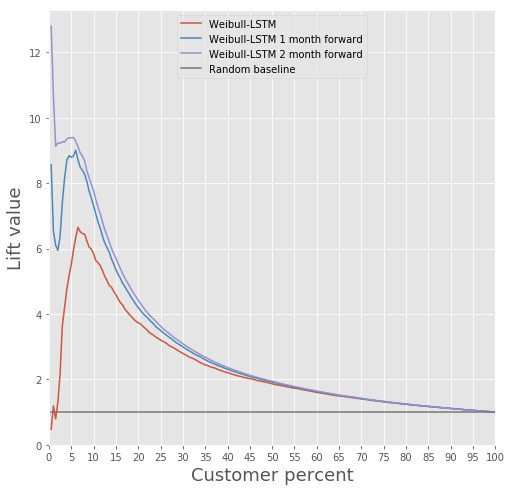
Retención de clientes
En realidad, esto es lo principal que se puede hacer con la información disponible que tal o cual cliente se está preparando para dejar de usar el producto. Hablando sobre la construcción de un modelo que pueda ofrecer algo útil a los clientes para mantenerlos, esto no funcionará si no tiene un historial de tales intentos que terminaría bien.
No teníamos una historia así, así que lo decidimos así.
- Estamos construyendo un modelo que define productos interesantes para cada cliente.
- En cada mes, ejecutamos un clasificador e identificamos posibles clientes salientes.
- Algunos clientes ofrecen un producto, de acuerdo con el modelo del párrafo 1, recuerdan sus acciones.
- Después de unos meses, miramos cuáles de estos clientes potencialmente salientes se fueron y cuáles se quedaron. Por lo tanto, formamos una muestra de entrenamiento.
- Entrenamos al modelo en la historia obtenida en el párrafo 4.
- Opcionalmente, repita el procedimiento, reemplazando el modelo del párrafo 1 con el modelo obtenido en el párrafo 5.
Las pruebas habituales A / B pueden servir como un control de la calidad de dicha retención: dividimos a los clientes que potencialmente se van en dos grupos. Ofrecemos productos basados en nuestro modelo de retención a uno, y no ofrecemos nada al segundo. Decidimos entrenar un modelo que ya podría beneficiarse en el punto 1 de nuestro ejemplo.
Queríamos hacer la segmentación lo más interpretable posible. Para hacer esto, elegimos varios signos que podrían interpretarse fácilmente: el número total de transacciones, el salario, la rotación total de la cuenta, la edad, el género. Los signos de la tabla "Tarjetas" no se tuvieron en cuenta como poco informativos, y los signos de la tabla 3 "Contratos", debido a la complejidad del procesamiento para evitar fugas de datos entre el conjunto de validación y el conjunto de capacitación.
La agrupación se realizó utilizando modelos de mezcla gaussiana.
El criterio de información de Akaike hizo posible determinar 2 óptimos. El primer óptimo corresponde a 1 grupo. El segundo óptimo, menos pronunciado, corresponde a 80 grupos. De este resultado se puede sacar la siguiente conclusión: es extremadamente difícil dividir los datos en grupos sin información dada a priori. Para una mejor agrupación, necesita datos que describan a cada cliente en detalle.Por lo tanto, se consideró la tarea de capacitación con un maestro para ofrecer a cada cliente individual un producto. Se consideraron los siguientes productos: “depósito a plazo”, “tarjeta de crédito”, “sobregiro”, “préstamo al consumidor”, “préstamo para automóvil”, “hipoteca”.Otro tipo de producto estaba presente en los datos: "Cuenta corriente". Pero no lo consideramos debido al bajo contenido de información. Por usuarios que son clientes del banco, es decir No dejaron de usar sus productos, se construyó un modelo que predecía qué producto podría ser de su interés. Se eligió la regresión logística como modelo, y se usó el valor de elevación para los primeros 10 percentiles como la métrica de evaluación de calidad.La calidad del modelo se puede estimar en la figura.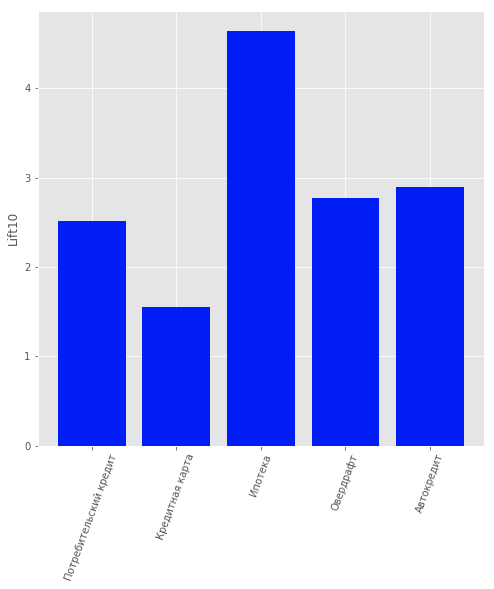 Resultados del modelo de recomendación del cliente
Resultados del modelo de recomendación del clienteResumen
Este enfoque nos trajo el primer lugar en la nominación de "IA en los bancos" en el Campeonato de IA RAIF-Challenge 2017. Aparentemente, lo principal era abordar el problema desde un lado inusual y usar un método que se usa comúnmente para otras situaciones.Aunque la salida masiva de usuarios puede ser un desastre natural para los servicios.Este método también se puede observar para cualquier otra área donde es importante considerar la salida, no por los bancos en su conjunto. Por ejemplo, lo usamos para calcular nuestro propio flujo de salida, en las sucursales siberianas y de San Petersburgo de Rostelecom.Empresa "Laboratorio de minería de datos" "Portal de búsqueda" Sputnik "
Aparentemente, lo principal era abordar el problema desde un lado inusual y usar un método que se usa comúnmente para otras situaciones.Aunque la salida masiva de usuarios puede ser un desastre natural para los servicios.Este método también se puede observar para cualquier otra área donde es importante considerar la salida, no por los bancos en su conjunto. Por ejemplo, lo usamos para calcular nuestro propio flujo de salida, en las sucursales siberianas y de San Petersburgo de Rostelecom.Empresa "Laboratorio de minería de datos" "Portal de búsqueda" Sputnik "