El proceso de pensamiento de cualquier persona es difícil de matematizar. Cualquier tarea comercial genera un conjunto de documentos formales e informales, cuya información se refleja en el repositorio corporativo. Cada tarea que genera cualquier proceso de información crea a su alrededor un conjunto de documentos y la lógica de su procesamiento, que está poco formalizada en el entorno de almacenamiento corporativo. Debe haber estructuras dentro del almacén de datos para borrar el flujo de información. El producto Oracle Enterprise Data Quality, que está diseñado para resolver las tareas de limpieza de datos "sucios", puede ayudar. Pero esto no se limita a su uso.
1. El concepto de una base de datos aleatoria.Las primeras conexiones comerciales de una persona se describen mediante documentos formales e informales, como una declaración, declaración, contrato de trabajo, solicitud de colocación, solicitud de un recurso. Estos documentos crean conexiones lógicas entre los procesos comerciales, pero, como regla, son producto del pensamiento de los gerentes de oficina y están poco formalizados.
La tarea de cualquier optimización al menos complicada es no solo comprender las reglas formales e informales, sino, a menudo, aportar conocimientos dispares a una base de información común.
Definición Una base de datos aleatoria es un conjunto de hechos, documentos, notas manuales, documentos formales que son procesados por una persona para un proceso comercial específico, pero que no pueden procesarse de manera totalmente automática debido a la fuerte influencia del factor humano.Un ejemplo El secretario recibe formalmente la llamada. La persona que llama está interesada en un producto o servicio. La persona que llama no es conocida por CRM. Pregunta: ¿qué debe decir la persona que llama para que un especialista la escuche?
Para ser más precisos: ¿en qué medida las instrucciones comerciales de la secretaria permiten un diálogo formal sobre el negocio si el especialista responsable no está listo para este tipo de actividad?
Resulta que nuevamente llegamos a la definición de una base de datos aleatoria.
Tal vez contiene más hechos de los que la secretaria puede saber. Pero la información recibida en ella no puede ser superflua. En general, cuando los hechos aleatorios de una base de datos aleatoria llegan a la entrada de un sistema formalizado, surge una sobrecarga de información, y toda sobrecarga de información puede afectar el desempeño no solo del secretario, sino de toda la empresa.
Si se utiliza con fines de procesamiento, una máquina que lee los estados de esta información se basa en conclusiones lógicas sobre el estado opuesto a la persona: sobrecarga de información. La lógica humana es más flexible.
2. Aplicación de la definición a tareas reales.Imagine una tienda en la que las etiquetas de precio para productos aleatorios son notablemente altas o bajas. Cuando salga de esta tienda, en la cabeza de un cliente inexperto con una lista de compras estará el precio de 5-7 (o incluso 3) de los productos más populares, cuyo precio puede afectar el tamaño del cheque total. Resulta que si fuera posible conocer la lista de productos, cuyo precio los compradores recuerdan con mayor frecuencia, el resto de los precios podría variar en un rango relativamente amplio.
¿Alguna vez te has preguntado por qué, antes de la Cuaresma, la carne al principio se vuelve mucho más barata, y luego puede aumentar considerablemente su precio y luego desaparecer? El precio de un producto, cuya demanda puede caer a cero, primero se calienta artificialmente, luego, pasando un cierto nivel de demanda, comienza a fijarse y, después de un tiempo, aumenta con fuerza, ya que la codicia no permite regalar productos no líquidos a un precio justo.
Una situación casi similar existe en el mercado de datos. La información más útil casi siempre está oculta por hipótesis secundarias sobre su aplicabilidad y capacidad de extracción.
Es suficiente presentar cualquier información que sea interesante para 5000-7000 personas en cualquier recurso relativamente desprotegido, seguramente hay sitios de copiar y pegar.
O el famoso juego con códigos telefónicos "¿Quién me llamó?". Alrededor de mil sitios en Runet consisten solo en los números de teléfono de varios operadores para ser un poco más altos en los resultados de búsqueda, tratando de vender de alguna manera el nombre de dominio y anunciando más caro.
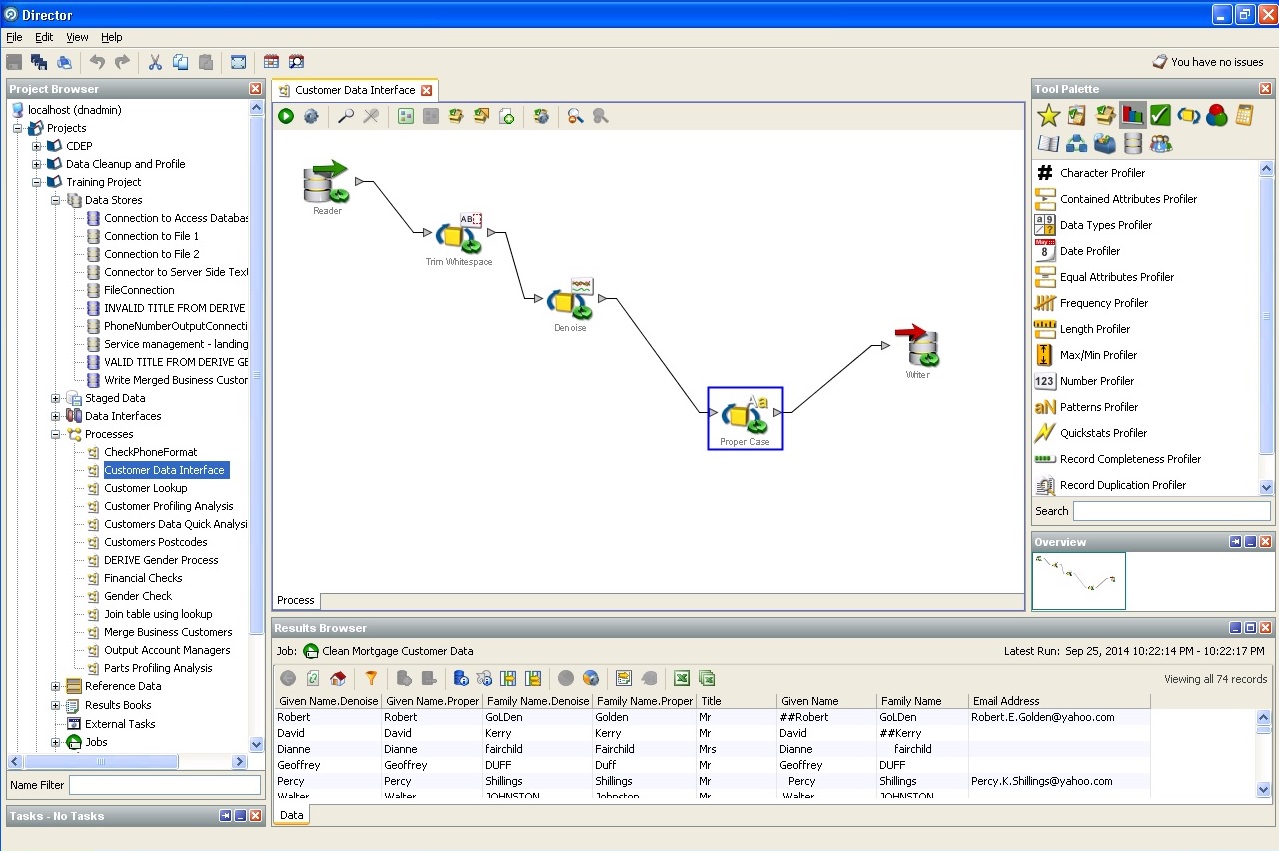
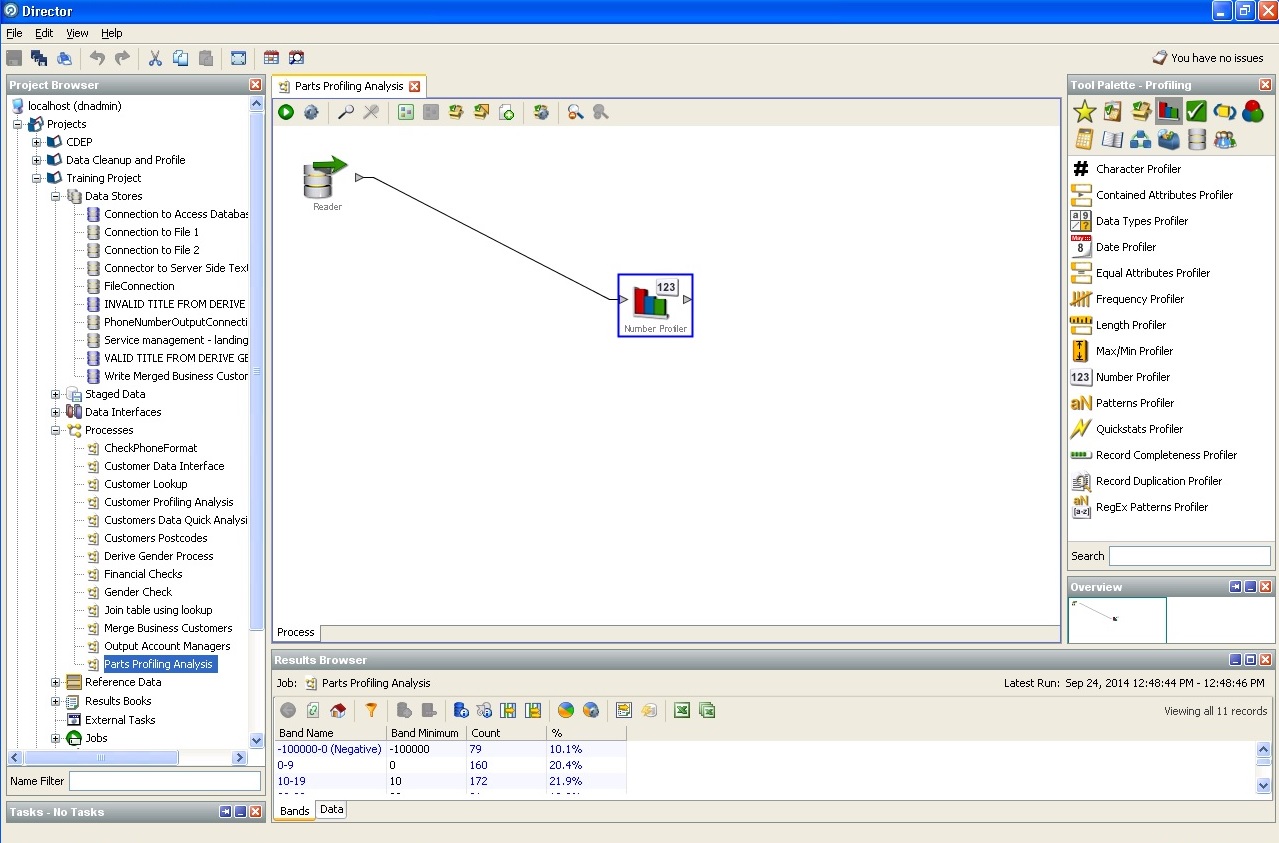
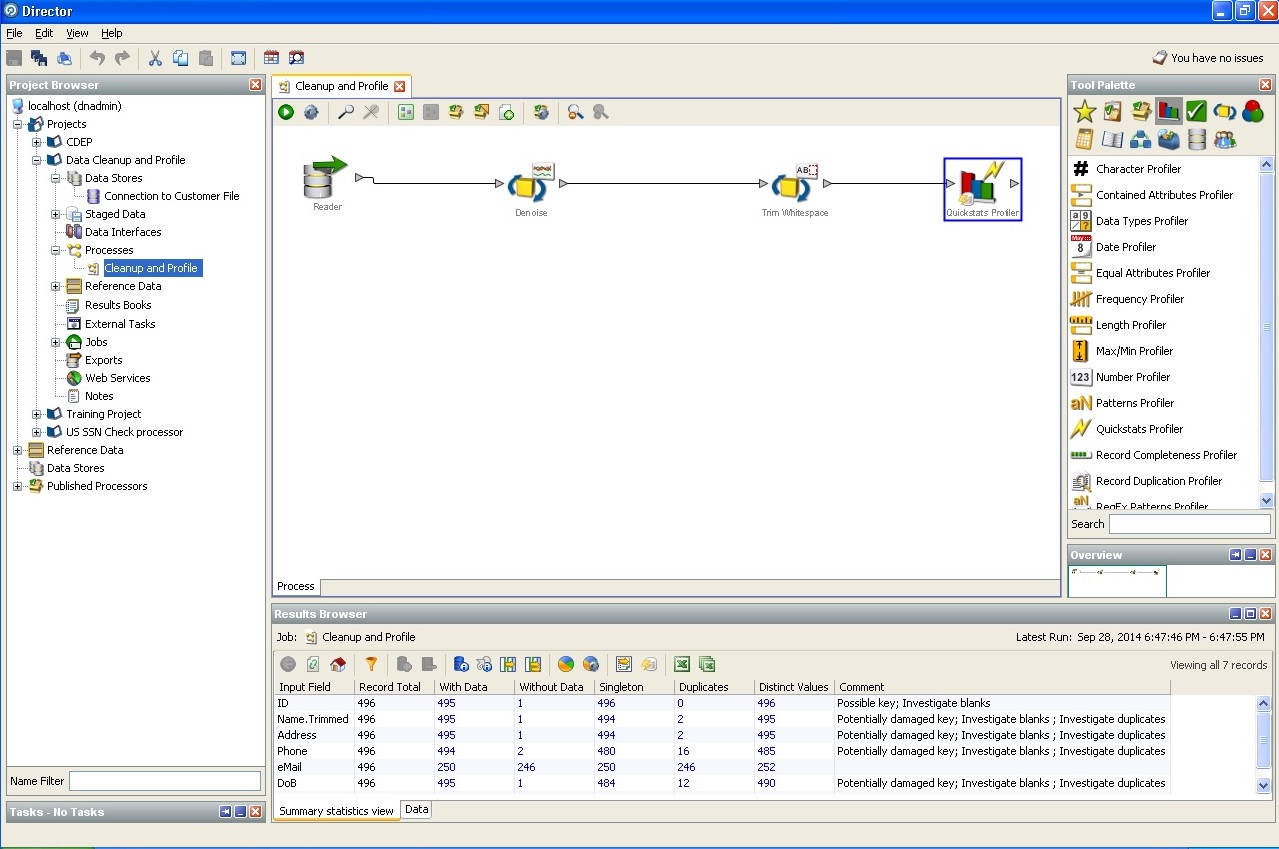
3. El precio del problema cuando se trabaja con datos "sucios".Según la investigación del autor del artículo, hasta el 10% de los recursos laborales de cada proyecto se desvían a la escritura de ciertos procedimientos de limpieza de datos. Si no se detiene en un tipo y una longitud completamente banales, es decir, identificadores únicos, reglas de integridad de la base de datos y reglas de integridad comercial, escalas de unidades cuantitativas y cualitativas, sistemas de unidades laborales y cualquier otro estado, influencias, transiciones, cuya preparación requiere como estadística habitual Análisis comercial lógico y serio. La formalización de los requisitos surge de la necesidad de formalizar la relación de dimensión de hechos, tanto para construir repositorios como para resolver problemas en el front-end.
De acuerdo, si los procesos de ETL ocupan el 70% del tiempo de trabajo de cualquier almacenamiento, ¿ahorrar un 5-7% de los recursos en la limpieza correcta de los datos en un almacenamiento condicional de 200,000 clientes ya es una buena ventaja?
Cubriremos un poco los problemas de datos "sucios" en sistemas listos para usar. Supongamos que envía una felicitación por un feriado nacional a 10,000 clientes por correo. ¿Cuántas personas tirarán su carta con la mejor postal en el buzón, si comete un error en el nombre, apellido o rellena el formulario incorrectamente? ¡El precio de sus esfuerzos puede reducir el estado de ánimo de cualquier usuario a cero!
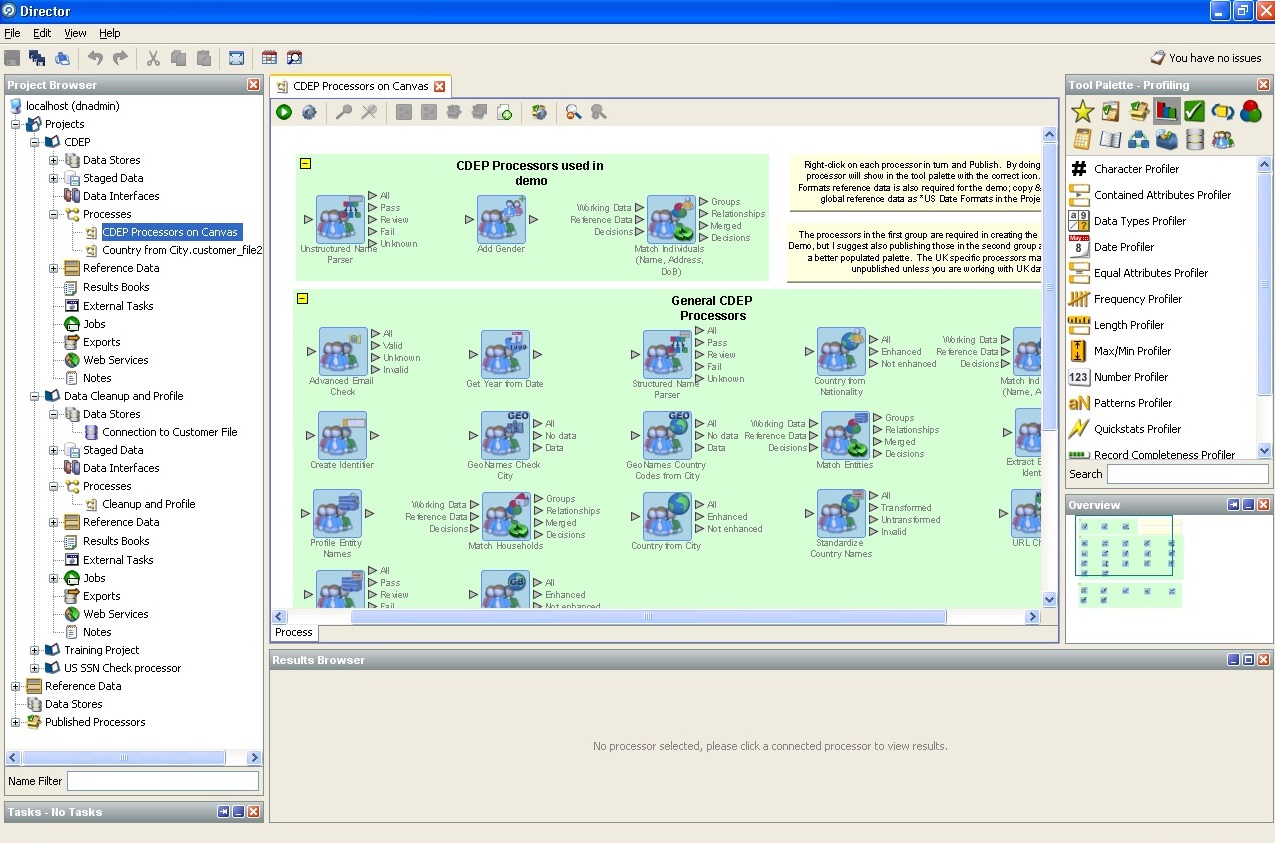
4. Oracle Enterprise Data Quality: escudo y espada del almacenamiento corporativo.Las capturas de pantalla que proporcionamos describen las capacidades de Oracle Enterprise Data Quality.
Entonces, deje que alguien derrame agua sobre su base de datos o documento de texto.
Aquí hay una lista de procesadores estándar (unidades lógicas que le permiten usar
a los datos de una u otra hipótesis, o busque la requerida):
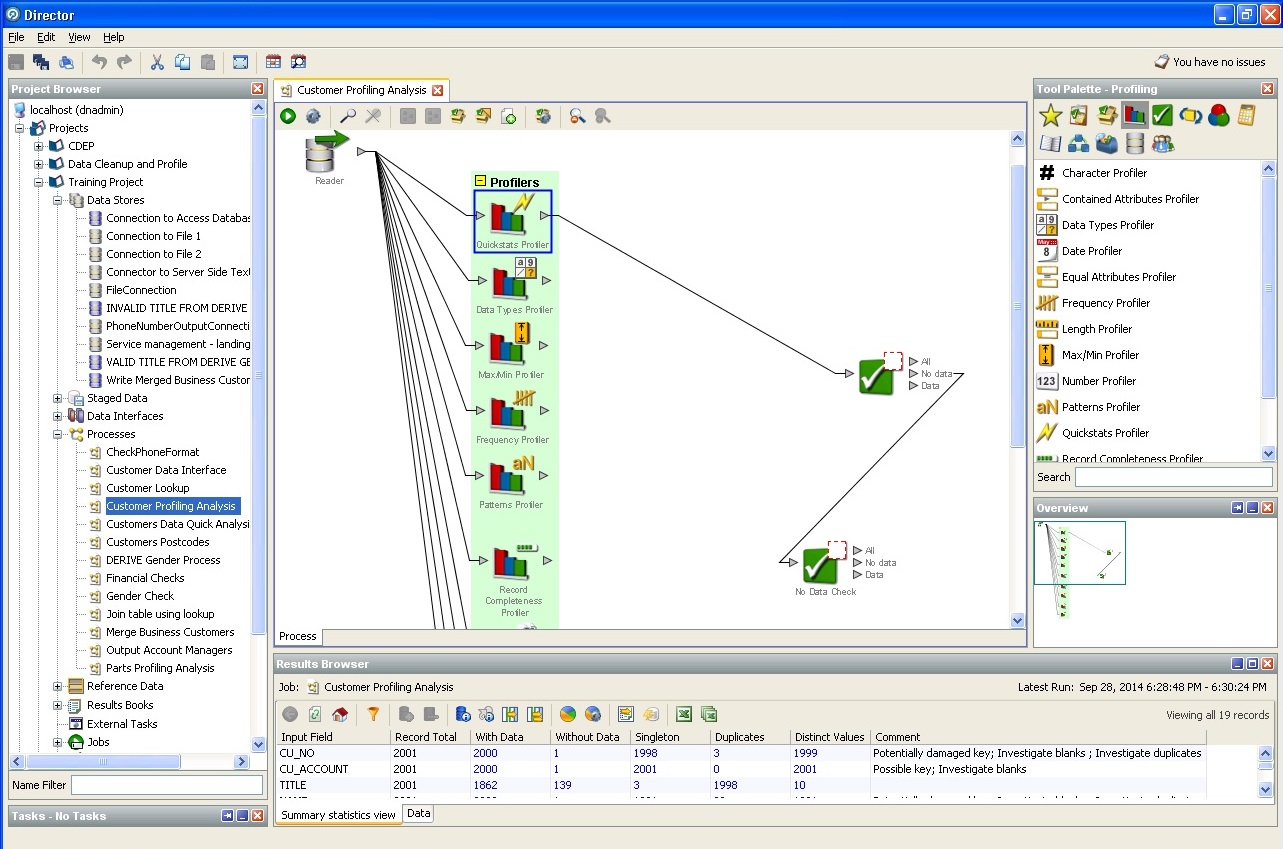
Acción de perfil de base de datos aleatoria:
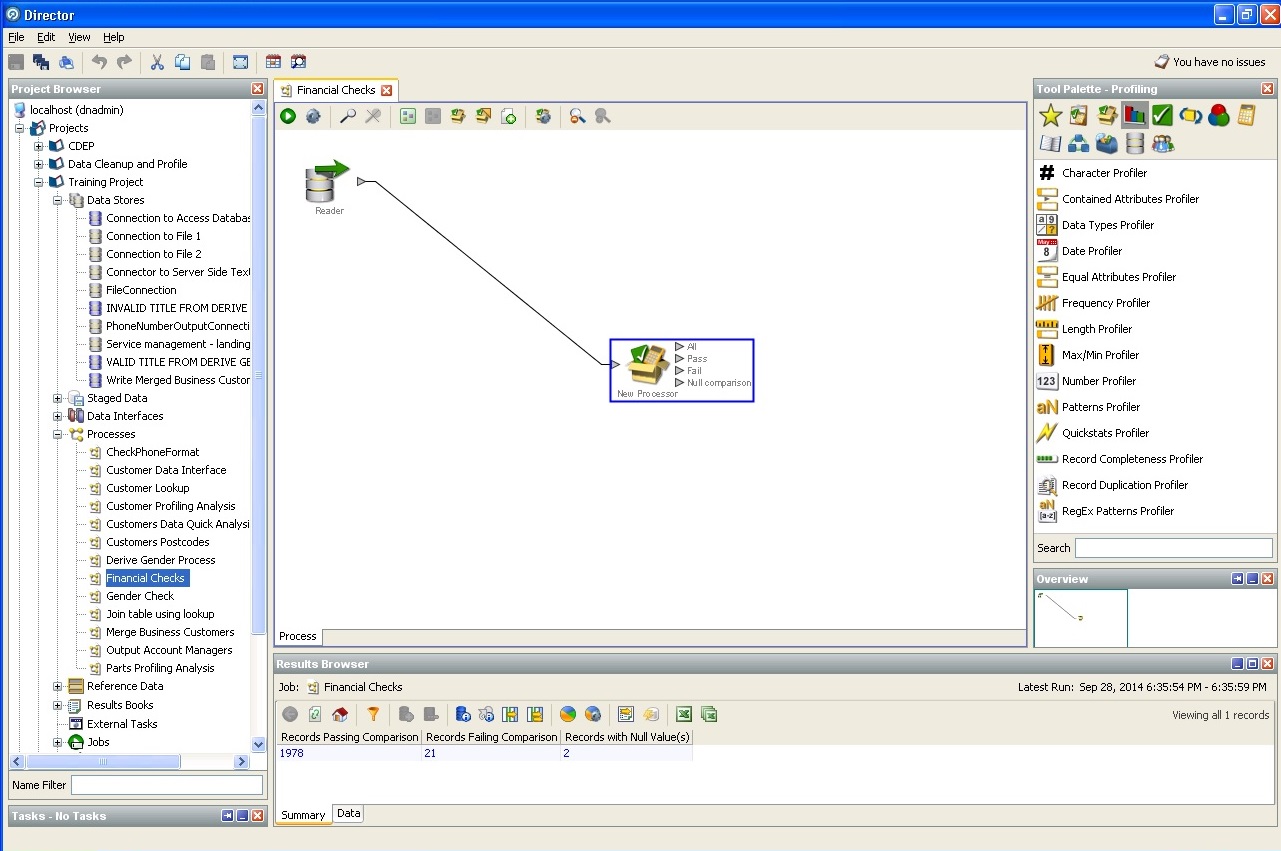
Auditoría elemental de solvencia financiera:
Trabajar con un código postal:
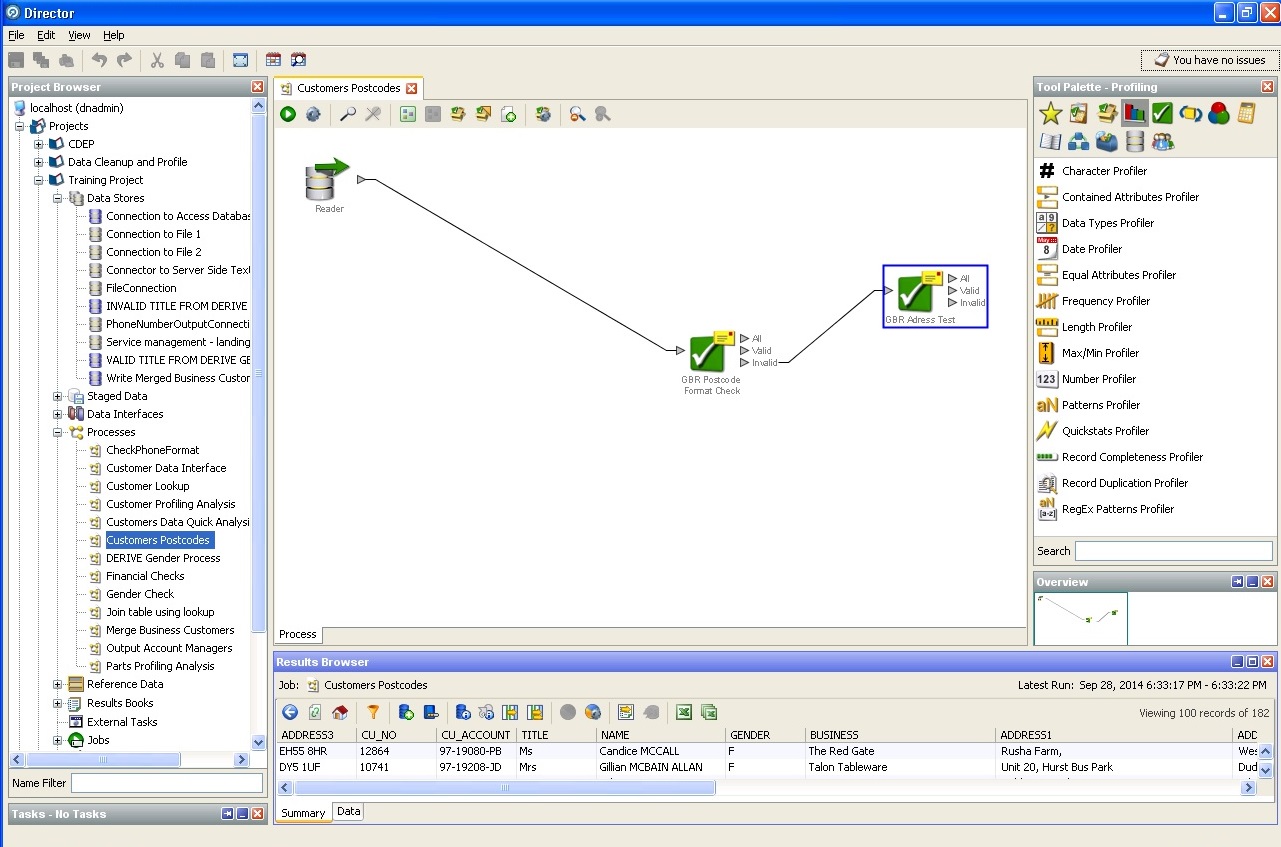
Limpieza de la dirección postal:
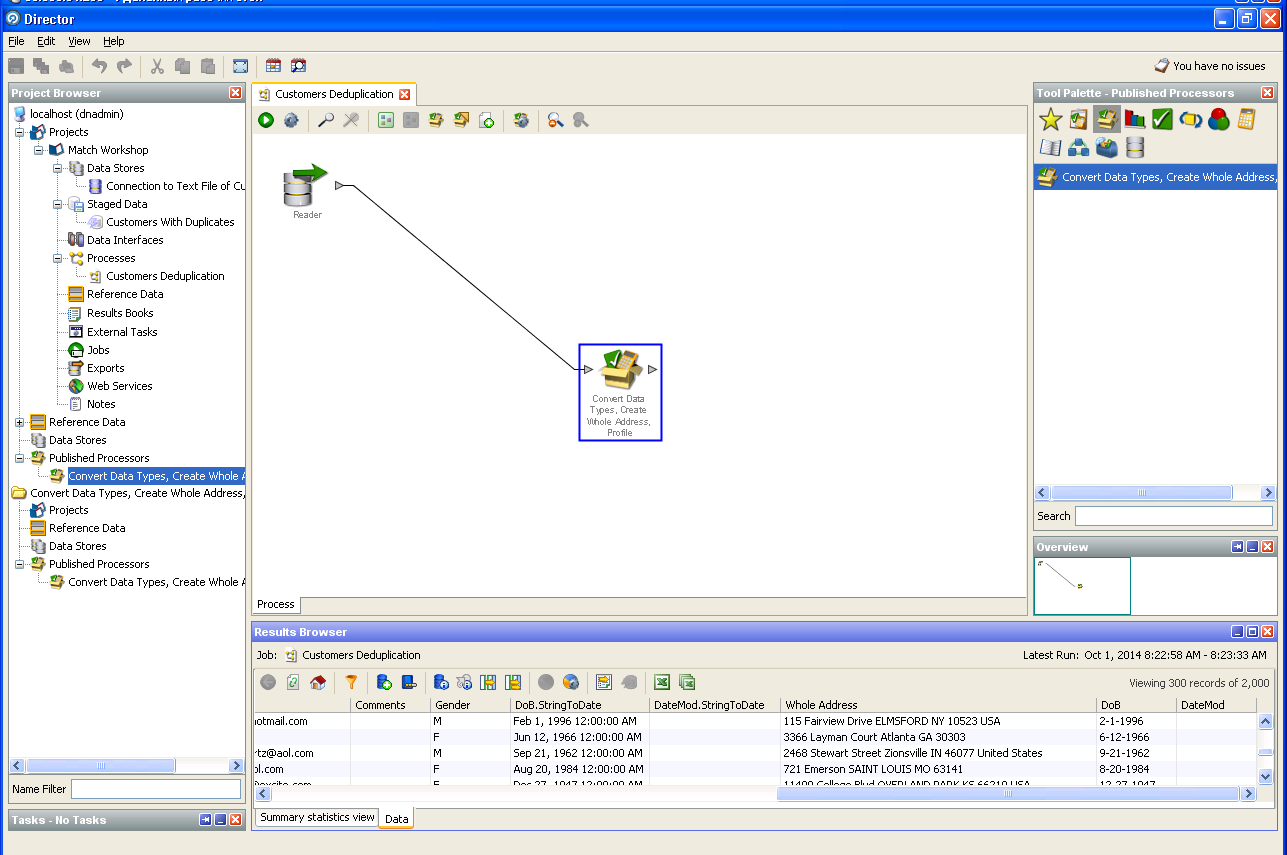
Borrar datos del usuario:
Asignación de un registro a uno u otro intervalo de confianza:
Determinación del género del usuario a partir de datos indirectos:
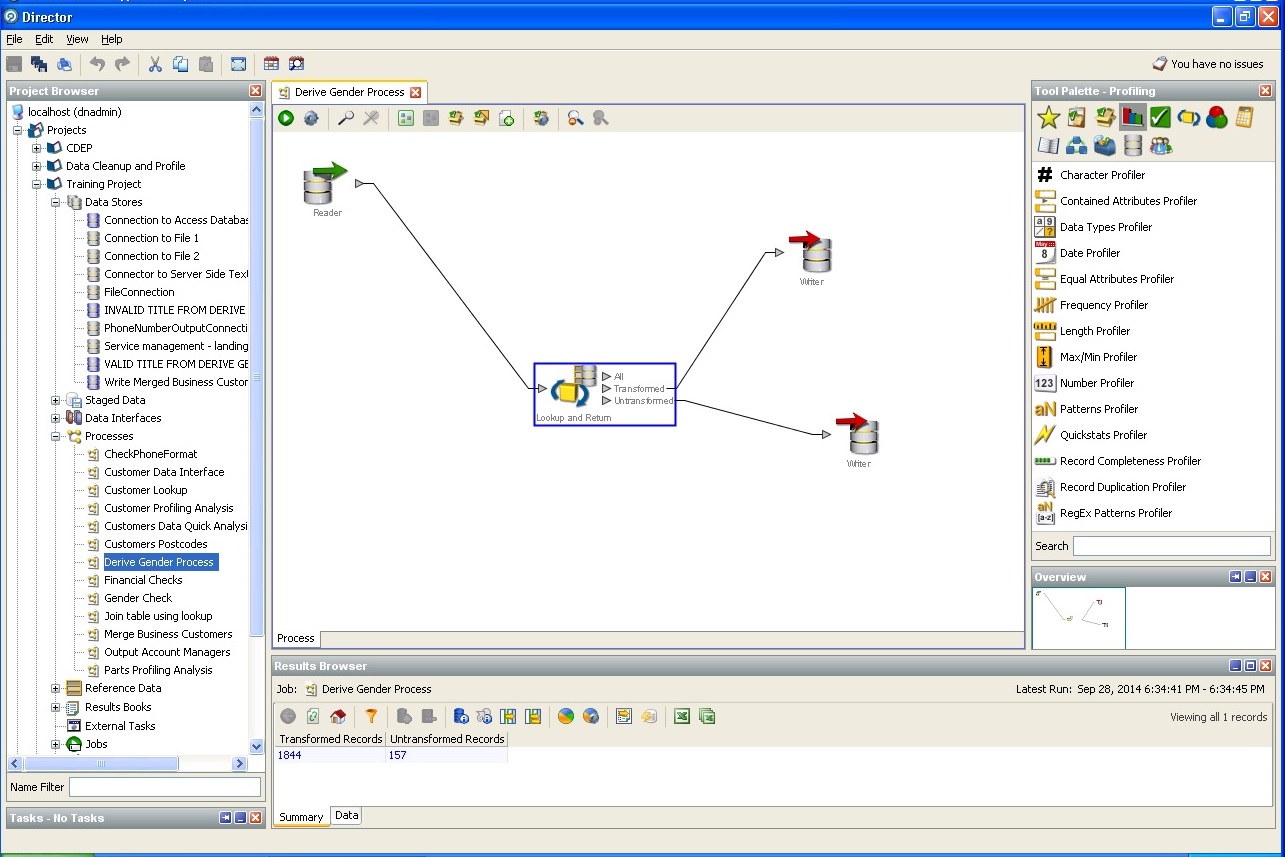
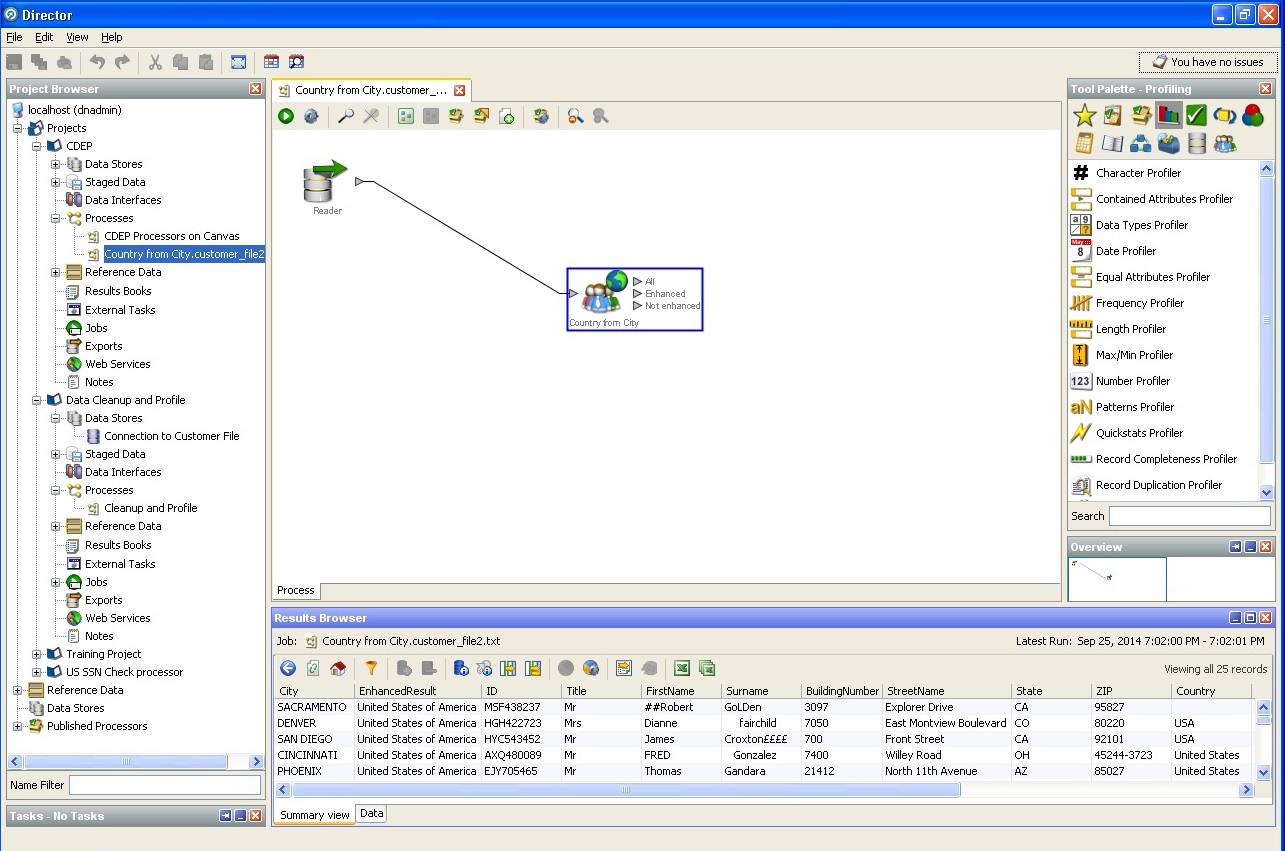
Definición de ciudad y país, estado:
La búsqueda de claves más simple en una base de datos aleatoria:
Desduplicación de los datos del usuario:
 5. Observaciones divertidas hechas sobre los resultados del trabajo en Oracle EDQ.
5. Observaciones divertidas hechas sobre los resultados del trabajo en Oracle EDQ.Uno de los principios para comparar las contribuciones de escritores y poetas a la literatura es comparar sus diccionarios poéticos y literarios. Brindamos una serie de diccionarios compilados en tiempo libre para pruebas de soluciones listas para Oracle EDQ, Python, Java. Estaremos agradecidos si los filólogos en los comentarios publican sus resultados.
Número p.p.
| La palabra
| Frecuencia de ocurrencia
|
León
Tolstoi, guerra y paz. Fragmento de la tabla de frecuencias.
Diccionario de derechos de autor.
| Yo
Brodsky, Urania.
| Yo
Brodsky Complete works, un fragmento del diccionario de frecuencias
el autor
| N.
Nekrasov, un fragmento del diccionario de frecuencias para la colección completa
ensayos
|
1)
| y
| 10351
| en
1037
| en
5745
| y
3420
|
3)
| en
| 5185
| y
647
| y
4500
| en
2108
|
4)
| no
| 4292
| no
391
| no
3022
| no
1726
|
5)
| que
| 3845
| en
341
| en
2239
| yo
1040
|
6)
| el es
| 3730
| como
329
| como
1758
| con
883
|
7)
| en
| 3305
| con
237
| con
1674
| en
854
|
8)
| con
| 3030
| que
168
| que
1531
| como
763
|
9)
| como
| 2097
| a
148
| Y
1200
| que
693
|
10)
| yo
| 1896
| de
147
| yo
1040
| el es
644
|
11)
| su
| 1882
| de
104
| a
922
| tu
475
|
12)
| a
| 1771
| yo
90
| de
810
| pero
472
|
13)
| entonces
| 1600
| donde
88
| todos
748
| pero
449
|
14)
| ella es
| 1564
| que
88
| por
744
| entonces
383
|
15)
| pero
| 1234
| para
76
| tu
721
| a
367
|
16)
| es
| 1208
| por
74
| En
713
| todos
344
|
17)
| dijo
| 1135
| Pero
72
| para
687
| para
313
|
18)
| fue
| 1125
| ninguno
70
| de
635
| para mi
309
|
19)
| entonces
| 1032
| lo haría
69
| pero
617
| si
294
|
20)
| el principe
| 1012
| entonces
67
| el es
592
| su
275
|
21)
| para
| 985
| tu
67
| Pero
584
| entonces
232
|
22)
| pero
| 962
| acerca de
66
| entonces
540
| fue
229
|
23)
| a el
| 918
| pero
63
| acerca de
538
| por
224
|
24)
| todos
| 908
| esta ahi
61
| es
524
| no
223
|
25)
| por
| 895
| Yo soy
61
| Yo soy
489
| ninguno
222
|
26)
| ella
| 885
|
| pero
463
| acerca de
213
|
27)
| de
| 845
|
| donde
449
| su
212
|
28)
|
|
|
| que
443
| de
209
|
29)
|
|
|
| Un
428
| de
207
|
30)
|
|
|
| lo mismo
422
| nosotros somos
206
|
Conclusión: las estadísticas de la lengua rusa en los últimos cien años en términos de la frecuencia de las palabras individuales no ha cambiado mucho entre los poetas: las palabras son más "melodiosas". Por cierto, las estadísticas de Daria Dontsova coinciden en muchos aspectos con Leo Tolstoi en el campo del diccionario de frecuencias de las obras completas.
6. Varios cálculos formales como conclusión.Alrededor de 60 mil Ivanov Ivanov Ivanovich viven en nuestro país. Suponiendo que hipotéticamente, en algún lugar, se almacenan 100 tablas en la base de datos promedio, 10 campos clave en cada tabla y cada clave puede tomar 60 mil valores, obtenemos que el número total de estados clave únicos dentro de la base de datos es de aproximadamente 60 millones. Incluso si dos claves se mezclan en una tabla, pueden generar hasta 20 estados únicos en una tabla. En total, hasta varios miles pueden encontrarse con la base de estados únicos. ¿Está de acuerdo en que pasar el 10% del tiempo de desarrollo y el 5-7% del tiempo de ejecución de ETL para atrapar esas pequeñeces es un lujo inadmisible?
UPD1 Si está cansado de arrastrar el sistema de control para cada directorio más o menos importante en su trabajo, los sistemas MDM (Master Data Management) lo ayudarán. Por supuesto, entregamos dichos sistemas al mercado, incluida una versión en software libre.
UPD2 Muy a menudo en las conferencias se hace la pregunta: "Cómo crear un sistema de gestión de calidad de datos más barato". Le pido que considere este artículo como una pequeña introducción a este problema, con alguna simplificación de la funcionalidad EDQ. Sí, y sin embargo, puede tomar un montón de ODI + EDQ y hacerlo muy bien, pero este es el tema de una mayor narración.