Hola a todos! Mi nombre es Denis Girko, soy el arquitecto de sistemas de la plataforma de comercio electrónico en Lamoda. El año pasado hablé en la conferencia DevConf con un informe que quiero compartir con ustedes.
Este es un informe de revisión sobre las dificultades que encuentra una gran tienda en línea en el proceso de entrega de pedidos y qué soluciones técnicas pueden ayudar a superarlas (utilizando las soluciones que probamos en Lamoda como ejemplo).

¿De qué se tratará? Te diré:
- Sobre el proceso de entrega e identificar problemas;
- cómo almacenar efectivamente territorios de entrega en la base de datos;
- cómo mejorar la calidad de los datos que recibimos del cliente;
- cómo buscar el destinatario en la base de datos de direcciones para encontrar resultados más precisos.
Esquema general de entrega de pedidos de Lamoda
Lamoda es una tienda en línea con cuatro países de entrega: Rusia, Ucrania, Kazajstán, Bielorrusia. Entregamos productos al día siguiente debido a que tenemos nuestro propio servicio de entrega y una docena de socios externos cuyos servicios utilizamos. La entrega es una gran parte de nuestro negocio.
Lamoda acepta el pedido, solicita al cliente la dirección en el momento del registro y la pasa al servicio de mensajería.
¿Qué pasa si no tenemos un servicio de mensajería, sino varios? Luego se agrega el siguiente paso: para determinar qué servicio de entrega tomaremos el pedido.
Puede haber algunos criterios de selección de negocios. Pero lo primero que debe pensar es si este servicio de mensajería tiene entrega a la ciudad seleccionada por el cliente o no. Por lo tanto, el primer paso para integrar cualquier empresa de mensajería en nuestro sistema es averiguar su área de cobertura.
A continuación, debe aprender a verificar si la dirección del cliente se encuentra en este territorio o no.
El esquema general se mejorará y se verá así:
- pedir una dirección;
- averiguar qué servicios de mensajería pueden entregarlo;
- seleccione el que desee de los disponibles.
Ahora un poco más sobre estos pasos.
Le pedimos al cliente la dirección
¿Cómo puedo preguntarle?
- Solicite completar un campo grande. El cliente martilla en su dirección, que además no necesita ninguna manipulación complicada. La dirección puede imprimirse en una hoja de papel, entregada al servicio de mensajería a pie, que luego lo resolverá él mismo.
- La segunda opción es más complicada. Le pedimos al cliente que complete cada componente de la dirección en su campo. Aquí ya puedes hacer algo. Por ejemplo, compare la ciudad de Moscú con una lista dada de ciudades. Pero funcionará mal, porque la ciudad de Moscú se puede escribir de muchas maneras: “g. Moscú "," Ciudad de Moscú "," Ciudad de Moscú "sin espacio, etc.
- Por lo tanto, hay una opción aún más avanzada. Como la lista de ciudades que tenemos es finita, puede precompilar una lista de ciudades y sugerir que el cliente seleccione la que necesita. La ventaja es que a cada elemento de dicha lista ya podemos asociar algún identificador aquí. A los desarrolladores nos encanta trabajar no con cadenas, sino con identificadores que se pueden usar en todos nuestros sistemas como el equivalente de la ciudad seleccionada. Tengo un índice de la oficina central de correos en la diapositiva como identificador.

¿Qué servicio de entrega estamos transportando?
Como tenemos un identificador (índice), dejemos que el territorio almacenado en nuestra base de datos esté representado por una lista de índices. En este caso, el algoritmo para verificar el ingreso de la ciudad al territorio es muy simple. Así que hagámoslo: colocaremos los territorios de entrega recibidos de los servicios de mensajería en la base de datos en forma de índices.
Los índices tienen sus pros y sus contras. Diré de antemano que al principio Lamoda hizo exactamente eso: el resultado de elegir un cliente de la ciudad fue un índice, y nuestros índices se almacenaron en la base de datos. ¿Por qué un plus? Como dije, un índice es algo que todos entienden. Cualquier gerente que acaba de llegar a trabajar sabe qué es un índice. Puede recibir de la empresa de mensajería de la ciudad, de alguna manera convertirlos en índices y usarlos. La desventaja es que el índice es el identificador de la oficina de correos del correo ruso. Y los asentamientos cercanos pueden compartir el mismo índice.
¿Por qué faltan los índices?
Un ejemplo simple: Lyubertsy. Muy cerca se encuentra el pueblo de Marusino. Marusino no tiene una oficina de correos; su correspondencia llega a una de las oficinas de correos de Lyubertsy. Si quisiéramos agregar la entrega a Lyubertsy, pero no la entrega a Marusino, ya que puede que no sea rentable para nosotros, no podríamos hacerlo solo por índice.
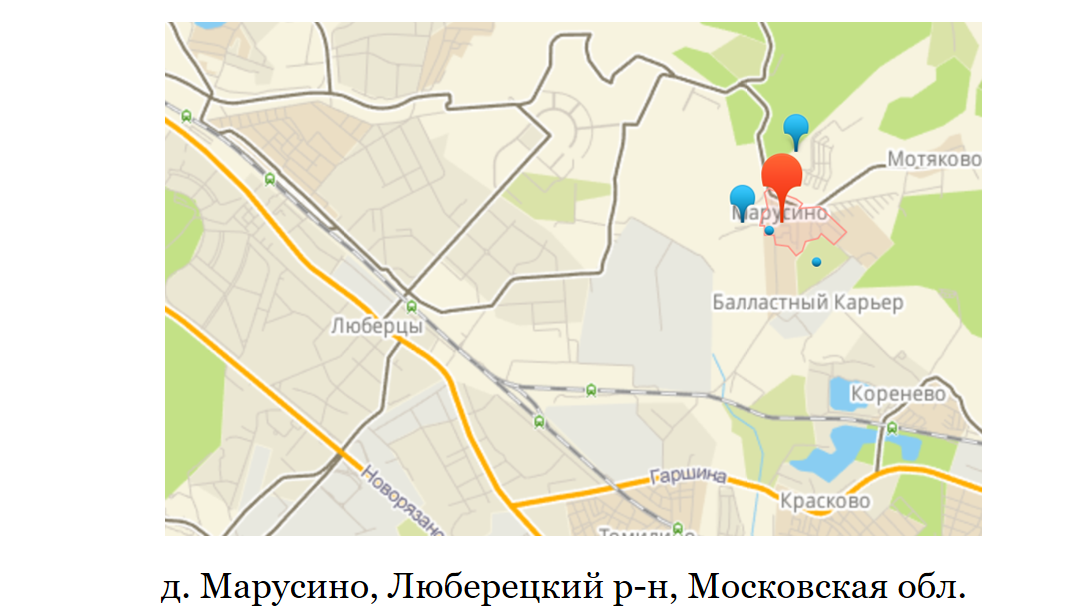
Otro ejemplo es cuando Lamoda se expandió y abrió un segundo almacén de tránsito en Moscú. Era necesario dividir Moscú en las mitades norte y sur. Y ya al momento de realizar el pedido, entienda desde qué almacén de tránsito se realizará la entrega. En este caso, un índice por ciudad no sería suficiente.
Decidimos usar geocoordenadas junto con índices. Tomamos la dirección del cliente, la ejecutamos a través del geocodificador Yandex . En la salida, obtenemos no solo el índice, sino también las coordenadas. Utilizamos índices en los casos en que los detalles no son importantes. Y las coordenadas especifican esos casos cuando necesita hacer una división delgada del territorio.
Proporcionaron una interfaz en su programa de configuración para especialistas en logística, que le permite dibujar un polígono en la parte superior del mapa. Es simple: el punto cae en el vertedero - hay entrega, no cae - no.
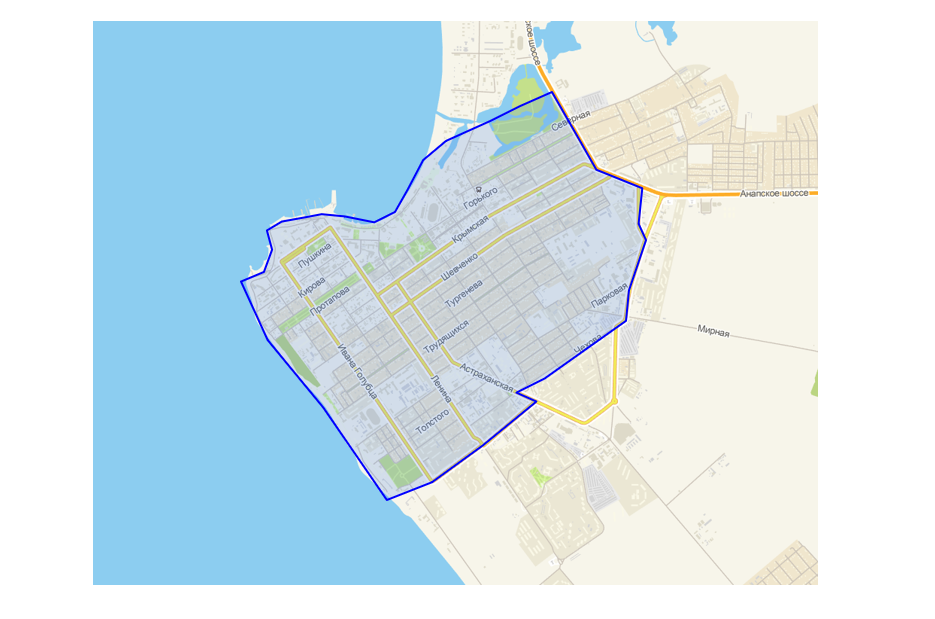
Interfaz de creación de zona poligonal
La ventaja de que tenemos coordenadas geográficas para cada pedido fue la oportunidad de mejorar la interfaz que los especialistas en logística utilizan para hacer rutas para los representantes de ventas. La interfaz muestra un mapa en el que se marcan los pedidos de los clientes. El logístico utiliza la herramienta de lazo, que combina las órdenes adyacentes en una ruta. Además, esta ruta va a un representante de ventas, es decir, una persona no necesita ir de un extremo de la ciudad al otro durante el día para tomar todos sus pedidos, todos están geográficamente cerca.
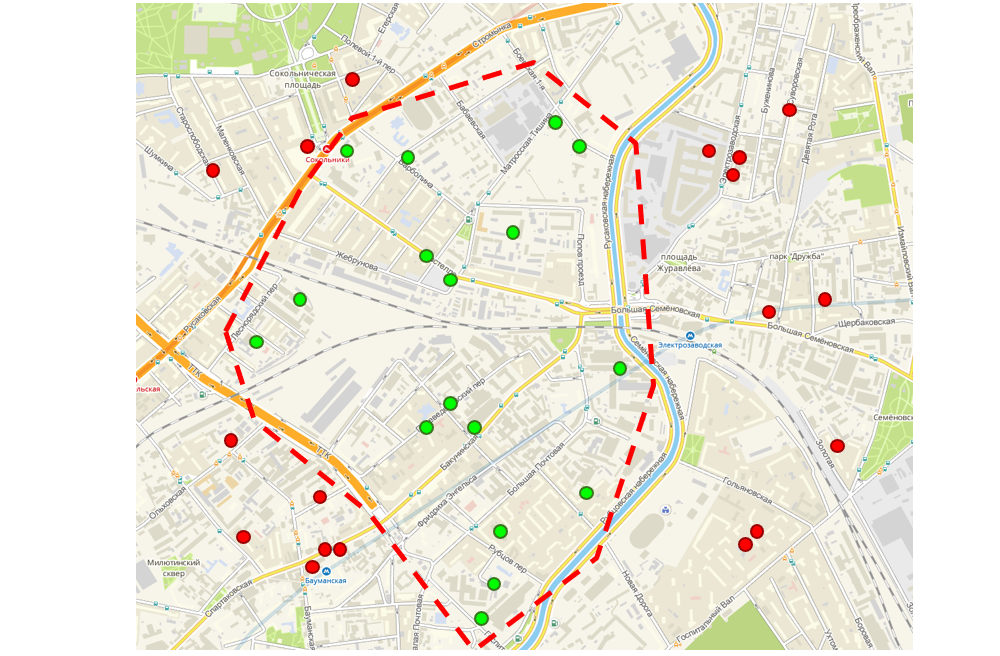
Interfaz de enrutamiento
La dirección ingresada por el cliente se convierte en coordenadas. La probabilidad de que obtengamos las coordenadas de una dirección determinada depende directamente de la calidad de la dirección ingresada por el cliente. Por lo tanto, lo primero que pensamos es cómo aumentar el número de direcciones bien reconocidas. Por lo tanto, debe ayudar al cliente a ingresar la dirección correcta.
El hecho es que los clientes a menudo no siguen los escenarios que les proporcionamos, por lo que adquirimos bases de datos de direcciones para cada uno de los 4 países a los que entregamos pedidos. E hicieron una fiesta no solo por la ciudad, sino también por la calle, e incluso por el número de la casa. Para hacer una lista de casas, analizamos los datos abiertos de openstreetmap.org .
El formulario de pago ofrece consejos para formalizar datos de direcciones
Base de direcciones
Para hacer un sujest en la base de direcciones, debe mantenerlo en casa. ¿Dónde obtuvimos todas las bases de direcciones para nuestros cuatro países? En Rusia, es FIAS , la base de direcciones que compila y mantiene nuestro servicio de impuestos. Es bastante completo, aunque no sin fallas. Nuestros socios de entrega nos han ayudado con otros países.

También tenemos un conjunto de scripts PHP que toman el formato con el que nos llega la base de direcciones, y de la misma manera que lo agrega a PostgreSQL . ¿Por qué en la misma forma? Porque una de las tareas es actualizar periódicamente estas bases de datos de las mismas fuentes. Esto significa que si proporcionáramos la conversión, tendría que repetirse con cada actualización. Por lo tanto, los datos van a PostgreSQL, y desde allí se convierten y almacenan en Apache Solr ; Solr le permite buscarlos rápidamente y hacer lo mejor. Un pequeño servidor web PHP puede crear solicitudes en Solr, de acuerdo con sus resultados, se crea una lista para el cliente en el sitio para el mejor.
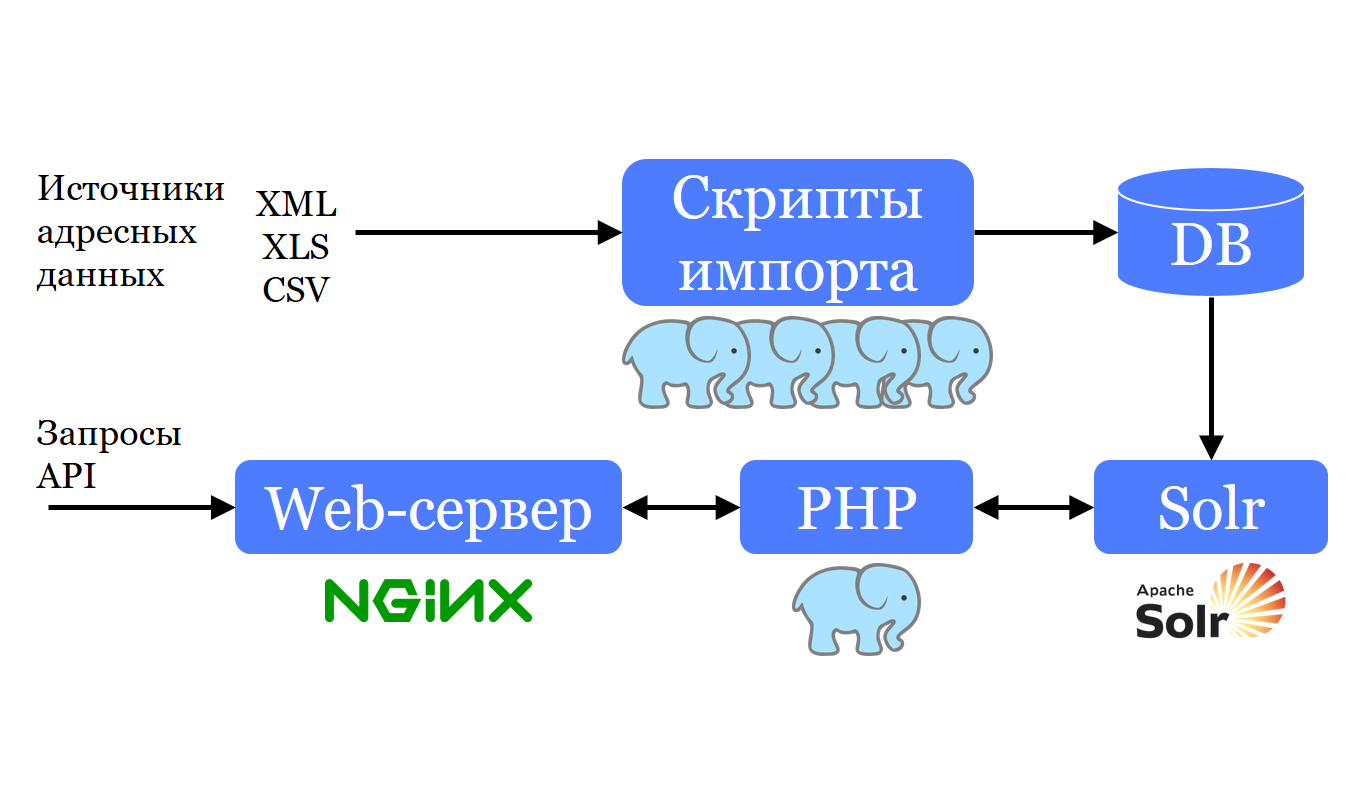
Descargamos datos de la fuente en aproximadamente la misma forma en que nos llegaron. Es decir, con el mismo conjunto de campos, con los mismos tipos de columnas, etc. Agréguelos como están. Intentamos usar los datos de esta forma desde el principio, y para transformarlos en aquellas estructuras con las que podemos trabajar, escribimos varias vistas. Como tenemos 4 países, todo esto se multiplicó por 4, y fue muy difícil y costoso apoyarlo. Por lo tanto, era necesario hacer algo al respecto.
Lo primero que eliminamos es la estructura no estructurada, o más bien específica , en una etapa temprana. Es decir, tan pronto como se cargan los datos sin procesar, con la ayuda de las vistas, los transformamos en un formato unificado, con el cual todas nuestras otras transformaciones se configuran más. Esto nos salvó de multiplicar por 4. Y es en este momento que nos olvidamos de la estructura en la que nos llegaron los datos, y trabajamos solo con lo que hemos inventado para nosotros mismos.
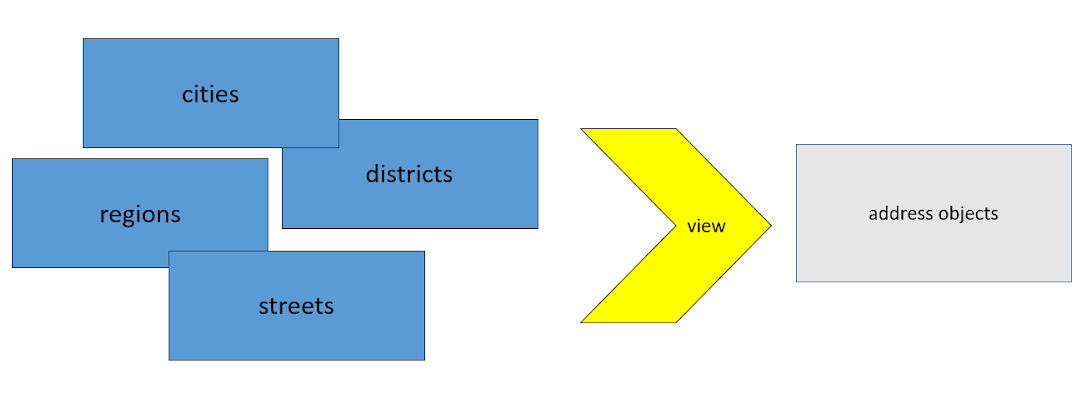
Si necesita dos fuentes, descárguelo. Lo principal es que el formato de esta salida de datos después de la conversión a vistas es el mismo.
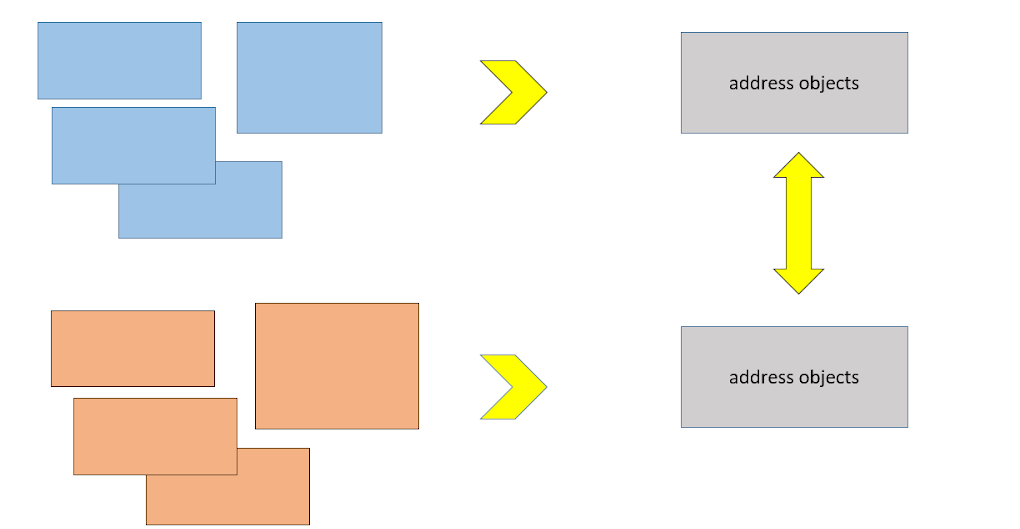
Otro requisito para las bases de datos de direcciones cargadas era que era necesario hacer correcciones de puntos. Un ejemplo simple: en FIAS, la República de Chuvash se llama "Representante de Chuvash. "Chuvasia". Bueno, queremos solo la República Chuvash. ¿Por qué necesitamos este guión? Y al mismo tiempo, aún no podemos evitar actualizaciones periódicas de las fuentes.
Aquí están las siguientes capas que tenemos en PostgreSQL.

Las tablas de la izquierda son datos sin procesar descargados de la fuente.
Detrás de ellos hay vistas que convierten los datos a un formato estándar.
Las anulaciones locales son nuestro conjunto de tablas que puntualmente redefinen algunos atributos de los datos de dirección cargados. Hemos incluido aquí, por ejemplo, que un registro con dicho identificador debería recibir en lugar de "Chuvash rep. - Chuvasia ”es nuestro nombre elegido.
La tabla de mapeo es nuestro repositorio de identificadores, que nosotros mismos asignamos a los objetos de dirección que descargamos; esto nos permitió abstraer nuestros sistemas de la fuente, de esos identificadores que se usan en la fuente, y también para ocultar no una fuente, sino incluso varias, bajo una ID Lo contaré un poco más tarde. Todo esto junto se combina y se fija en una vista materializada. Por lo tanto, obtenemos casi el equivalente de la tabla final, que puede actualizarse ejecutando un comando SQL REFRESH MATERIALIZED VIEW .
Objetos de dirección: base de direcciones formada con todas las correcciones y adiciones.
Entonces, en la salida ya hemos corregido los objetos de dirección, ya con nuevos nombres y nuestros identificadores. Todo esto se transforma y desnormaliza, como conveniente para la búsqueda, y se suma en Solr.
Dado que ahora tenemos bases de datos de direcciones, sería genial usarlas no solo para hacer un ajuste para el formulario de pedido, sino también para hacer una búsqueda. ¿Dónde puede ser útil una búsqueda? Resulta mucho dónde. Las mismas áreas de entrega que recibimos de los servicios de mensajería a menudo están representadas simplemente por una lista de ciudades. Y la lista de ciudades está plagada de los mismos problemas que con la entrada del usuario: las ciudades pueden tener diferentes interpretaciones, diferentes nombres y más.
Tengo una diapositiva especial aquí, una historia de horror: ¿qué tendríamos que hacer si tomáramos todo manualmente para convertirlo a PHP?

Adición: en la pantalla, una pieza de código real del servicio, que se volvió innecesaria solo por las soluciones descritas.
Hemos clasificado estos problemas.
1) Nombres equivalentes de los mismos objetos. Por ejemplo, sinónimos comunes como Chuvasia y la República de Chuvasia.
2) Ciudades renombradas. Ucrania se encuentra ahora en la fase activa de deshacerse del pasado comunista, por lo que literalmente todos los días hacen cambios en los nombres de sus asentamientos. Por esta razón, puede resultar que en una base de datos tengamos nombres antiguos y en otra, nuevos.
3) Muchos errores. A menudo se equivoca en el estado de los asentamientos. Hay un pueblo, aquí hay un pueblo o aquí hay un pueblo, hay una granja.
4) Palabras extranjeras transliteradas al ruso, a menudo el mismo nombre se transcribe de diferentes maneras.
5) Hay muchos errores en la jerarquía: Zelenograd, por costumbre, pertenece a la región de Moscú, aunque formalmente también figura en Moscú como FIAS. Escriba correctamente "Ciudad de Moscú, Zelenograd".
¿Cómo se nos ocurrió esto?
Lo primero que hacemos es separar todos los componentes insignificantes de la dirección de los nombres. No los tiramos a la basura, participan en la búsqueda, sino por separado de las partes importantes.
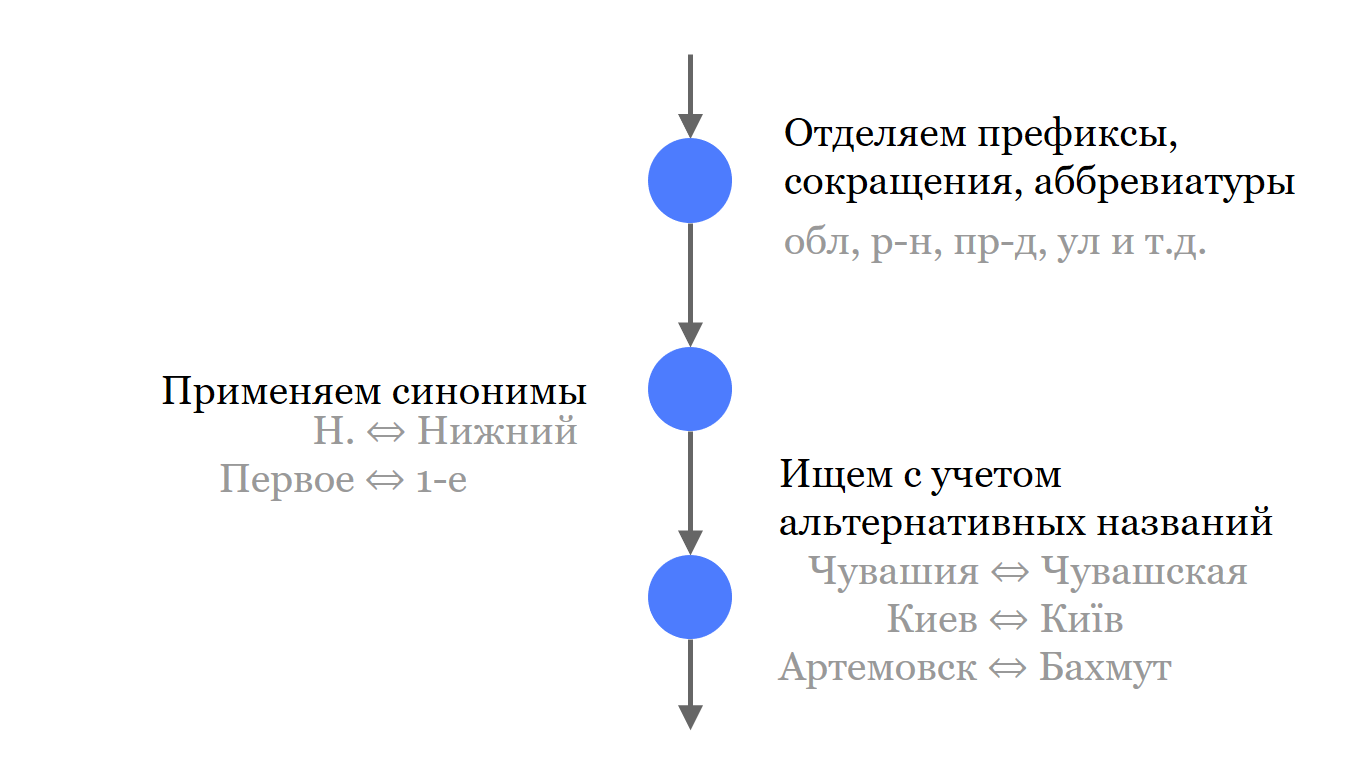
Luego, hicimos una breve lista de sinónimos y abreviaturas comunes que se usan en los nombres. Donde la fuente lo permitió, cargamos y pusimos todos los nombres en Solr. No solo los sinónimos y nombres históricos más relevantes, sino también posibles.
Para una mejor búsqueda, descartamos todas las letras que pueden presentar discrepancias. Esto se aplica al idioma ruso y aquellos idiomas con los que todavía tenemos que lidiar.
Corregimos errores tipográficos y arreglamos el diseño.
Finalmente, se nos ocurrieron padres fantasmas: estos son padres asignados a objetos. Son relevantes en la búsqueda, pero no participan en el resultado de la búsqueda. Por ejemplo, para Zelenograd, agregamos la región de Moscú. Ahora puede buscar "Región de Moscú, Zelenograd" y encontrar el objeto que necesitamos, pero en los resultados de búsqueda seguirá siendo el correcto "Moscú, Zelenograd".
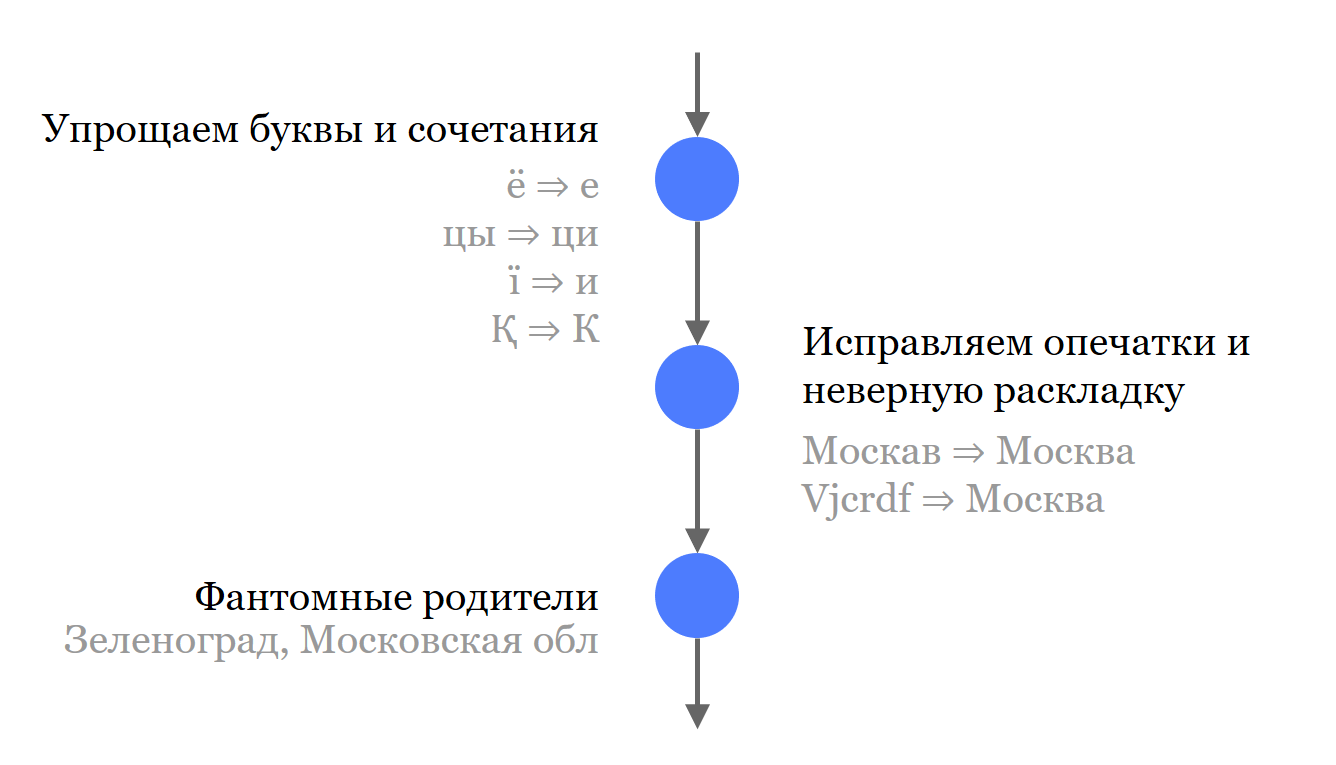
Dependiendo de los requisitos comerciales, se necesita una gradación diferente de la precisión de búsqueda. Por lo tanto, tenemos 4 grados, cada uno de ellos da un resultado con una probabilidad más alta, pero con una probabilidad más baja será exactamente el resultado que se busca.

¿Y dónde encontramos esa aplicación de búsqueda?
- Una vez más, ejecutamos la dirección ingresada por el cliente a través de dicha búsqueda. Si no utilizó nuestros consejos en la página de pago, entonces tenemos una oportunidad más de convertir las líneas que ingresó en identificadores. Obtenemos una dirección formal.
- Revisamos esta búsqueda todo lo que nos envían los servicios de mensajería: reconocemos las ciudades que nos transmiten. Esto nos permitió lanzar solo 10 piezas al día, esto es relevante para B2B: Lamoda proporciona su entrega a empresas de terceros, por lo que hay muchos servicios de mensajería nuevos conectados por unidad de tiempo.
- Esto nos permitió "encadenar" información útil en nuestros identificadores en bases de datos de direcciones. Por ejemplo, descargamos zonas horarias, direcciones IP, para buscar ciudades por direcciones IP de clientes.
- Ahora tenemos la oportunidad de ocultar la base de direcciones combinada de dos fuentes con uno de nuestros identificadores. Es decir, permitió evitar duplicados y hacer coincidir los mismos objetos de dirección en ambas bases.
No nos detenemos Este es un proceso que aún podemos mejorar.
En primer lugar, Lamoda trabaja en índices. Es decir, nuestros identificadores son índices, de los cuales conocemos las desventajas. Casi todos nuestros sistemas han cambiado a la nueva API; operan no con índices, sino con los mismos identificadores que nosotros mismos asignamos a nuestros objetos de dirección. La ventaja es que verificar una ciudad en el territorio es tan simple como con índices. Sin embargo, no hay ningún inconveniente en el hecho de que varios asentamientos pueden esconderse detrás de una identificación.
Adición: ha pasado el tiempo desde el momento de mi discurso, y ahora me complace corregirme: nuestros índices ahora solo permanecen en el caso, cuando el servicio de mensajería nos da su territorio en forma de una lista de ellos, por ejemplo, Russian Post. En otros casos, los índices fueron suplantados por nuestros identificadores de dirección internos.
En la diapositiva hay una parte de la interfaz que le permite configurar manualmente el territorio, pero, de hecho, todo se configura a partir de listas cargadas por lotes de objetos de dirección en forma de cadenas.

Descargamos coordenadas geográficas de openstreetmap.org para hogares. Ahora, en un gran porcentaje de casos, no necesitamos ir a un servicio externo para averiguar la ubicación. Esto nos redujo 10 veces los viajes a Yandex, lo que naturalmente ahorró dinero.
Nos deshacemos de PHP en la cadena de búsqueda de datos de dirección. Reescribimos el código que accedió a Solr en Lua. Reemplazado nginx con Openresty , ahora todo es muy rápido y puede soportar cargas pesadas. El 95% de las respuestas de nuestro servicio de búsqueda caben en 10 milisegundos, lo cual es más que suficiente para nosotros.

Adición: el uso de Openresty y Lua, que atrajo su desempeño, fue una especie de experimento que valió la pena: el servicio funciona rápidamente, es estable bajo carga y se mantiene fácilmente. Pero desde entonces, Lamoda ha adoptado Golang, que tiene las mismas cualidades, como uno de los lenguajes de programación para el backend cargado. Si la decisión de desarrollar el servicio se tomara ahora, lo preferiríamos.
Conclusión
Mi moralidad personal de todo el trabajo realizado es que los datos de dirección son un área donde no se puede esperar una calidad de datos ideal. Esto nunca sucederá. Nunca recibiremos datos perfectos de un cliente o de fuentes externas. Por lo tanto, tienes que exprimir al máximo lo que es.