
Las mejoras en la velocidad de la CPU están disminuyendo, y estamos viendo que la industria de semiconductores cambia a tarjetas aceleradoras para que los resultados continúen mejorando notablemente. Nvidia se ha beneficiado más de esta transición, sin embargo, es parte de la misma tendencia, impulsando la investigación de aceleradores de redes neuronales, FPGA y productos como los TPU de Google. Estos aceleradores han aumentado increíblemente la velocidad de la electrónica en los últimos años, y muchos comenzaron a esperar que representaran un nuevo camino de desarrollo, en relación con la desaceleración de la ley de Moore. Pero un nuevo trabajo científico sugiere que, de hecho, no todo es tan color de rosa como a algunos les gustaría.
Las arquitecturas especiales como GPU, TPU, FPGA y ASIC, incluso si funcionan de manera bastante diferente a las CPU de uso general, todavía usan los mismos nodos funcionales que los procesadores x86, ARM o POWER. Y esto significa que el aumento de la velocidad de estos aceleradores también depende en cierta medida de las mejoras asociadas con la escala de los transistores. Pero, ¿qué proporción de estas mejoras dependía de la mejora de las tecnologías de producción y un aumento en la densidad asociada con la ley de Moore, y qué de las mejoras en las áreas objetivo para las cuales están destinados estos procesadores? ¿Qué porcentaje de mejoras solo está relacionado con los transistores?
El profesor asociado de ingeniería eléctrica de la Universidad de Princeton, David Wenzlaf, y su estudiante graduado Adi Fuchs han creado un modelo que les permite medir la velocidad de mejora. Su modelo utiliza las características de 1612 CPU y 1001 GPU de diversas capacidades, realizadas sobre la base de varias unidades funcionales, para evaluar numéricamente los beneficios asociados con las mejoras en las unidades. Wenzlaf y Fuchs han creado una
métrica para mejorar el rendimiento relacionado con el progreso de CMOS (CMOS-Driven return, CDR), que se puede comparar con las mejoras adquiridas a través de la especialización de chip (CSR).
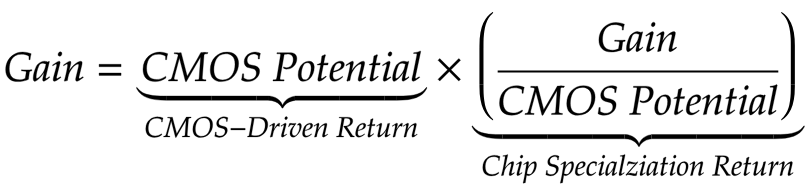
El equipo llegó a una conclusión desalentadora. Las ventajas obtenidas debido a la especialización de los chips están fundamentalmente relacionadas con el número de transistores colocados en un milímetro de silicio a largo plazo, así como con las mejoras de estos transistores asociados con cada nueva unidad funcional. Peor aún, existen limitaciones fundamentales sobre cuánta velocidad podemos extraer al mejorar el circuito del acelerador sin mejorar la escala CMOS.
Es importante que todo lo anterior se aplique a largo plazo. Un estudio realizado por Wenzlaf y Fuchs muestra que la velocidad a menudo aumenta dramáticamente cuando los aceleradores se ponen en servicio por primera vez. Con el tiempo, cuando se estudian los métodos de aceleración óptimos y se describen las mejores prácticas, los investigadores adoptan el enfoque más óptimo. Además, en los aceleradores, las tareas bien definidas de un área bien estudiada que se pueden paralelizar (GPU) están bien resueltas. Sin embargo, esto también significa que las mismas propiedades, debido a las cuales la tarea puede adaptarse para los aceleradores, limitan la ventaja obtenida de esta aceleración a largo plazo. El equipo llamó a este problema "aceleradores de punto muerto".
Y el mercado informático de alto rendimiento probablemente lo haya sentido por algún tiempo. En 2013, escribimos sobre el
difícil camino hacia las supercomputadoras a gran escala. E incluso entonces, Top500 predijo que los aceleradores darían un salto único en las calificaciones de rendimiento, pero no aumentarían la velocidad del aumento de velocidad.

Sin embargo, las consecuencias de estos descubrimientos van más allá del mercado informático de alto rendimiento. Por ejemplo, después de estudiar la GPU, Wenzlaf y Fuchs descubrieron que los beneficios que no podían atribuirse a CMOS mejorados eran muy pequeños.
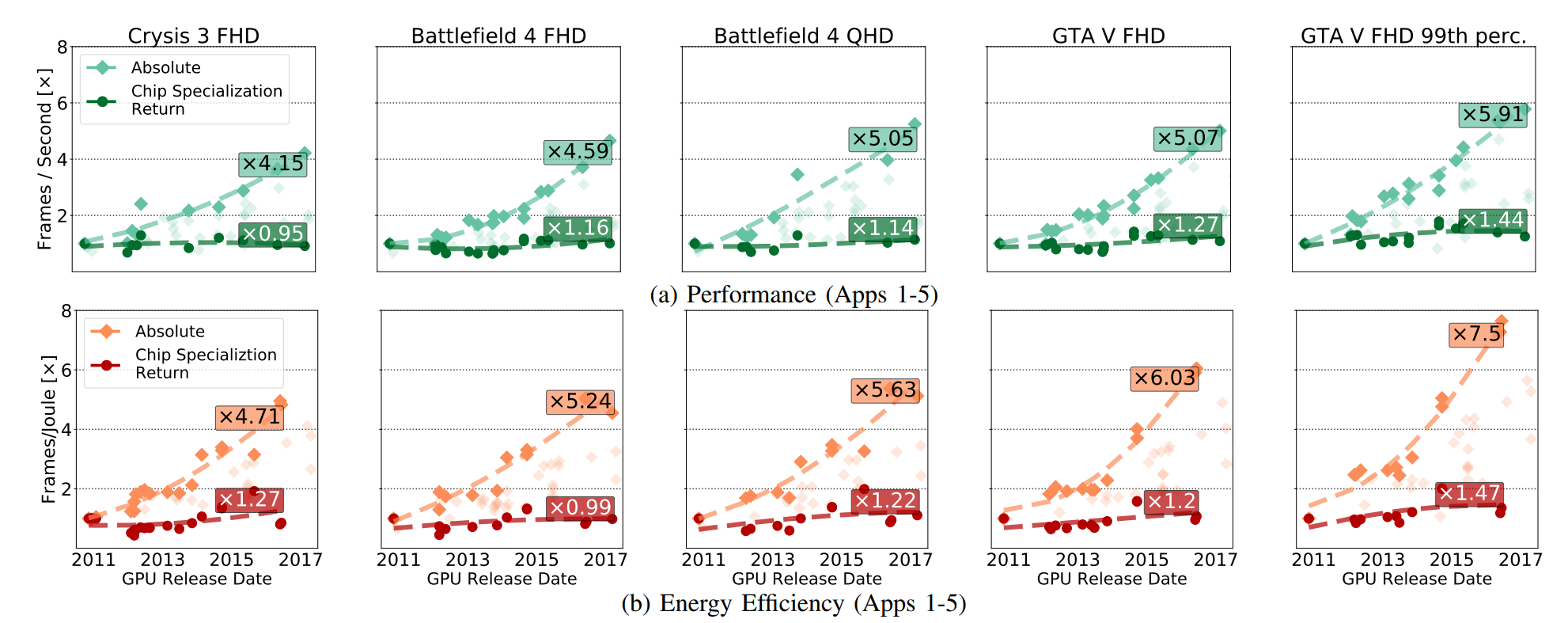
En la fig. Se ha demostrado un crecimiento absoluto del rendimiento de la GPU (incluidos los beneficios obtenidos del desarrollo de CMOS), y estos beneficios han surgido únicamente del desarrollo de la RSE. Las CSR tratan sobre las mejoras que quedan si elimina todos los avances en la tecnología CMOS del circuito de la GPU.
La siguiente figura aclara la relación de cantidades:
Disminuir la CSR no significa ralentizar la GPU en números absolutos. Como escribió Fuchs:
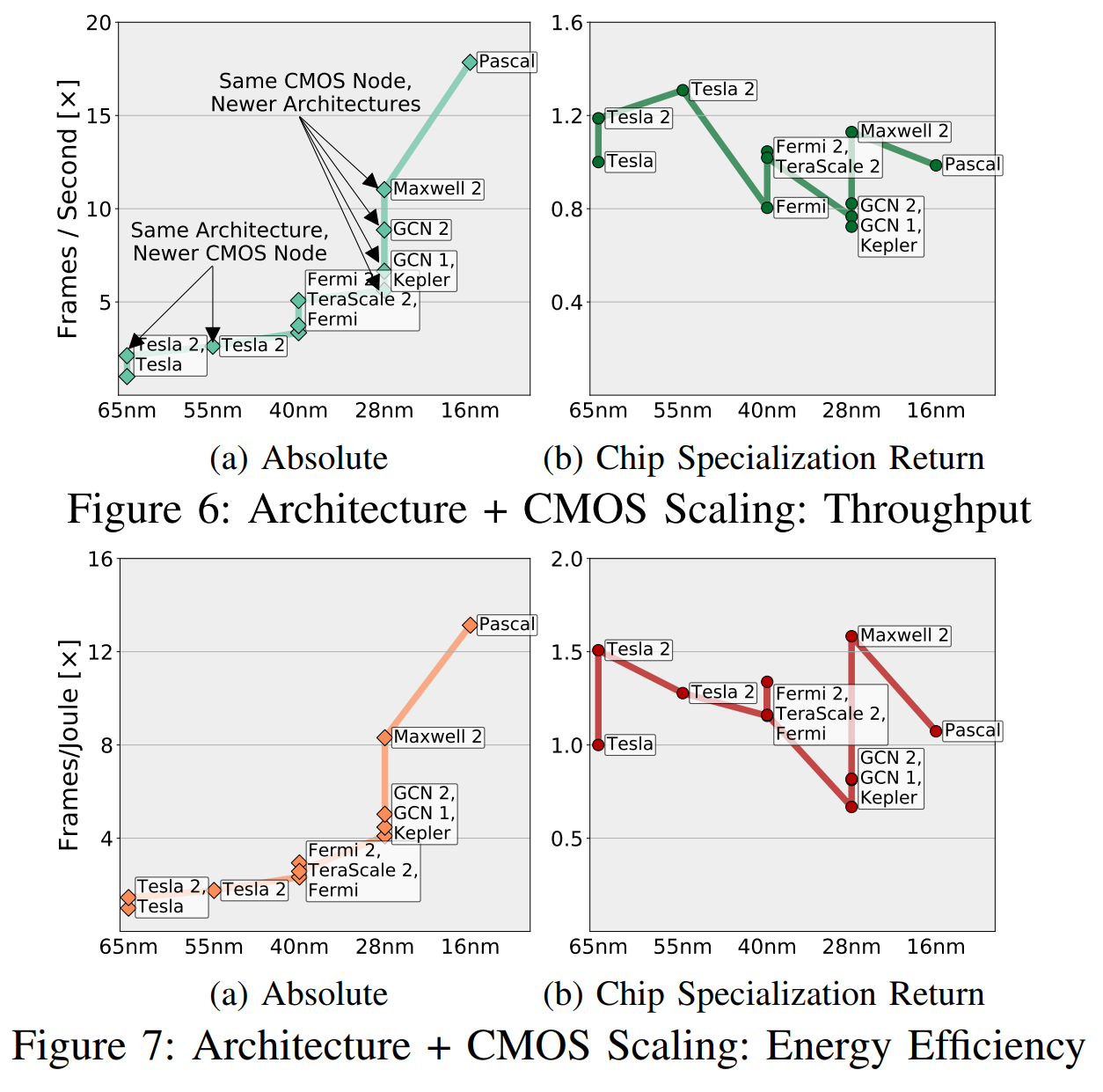
La RSE normaliza el beneficio "en función del potencial de CMOS", y este "potencial" tiene en cuenta la cantidad de transistores y la diferencia en velocidad, eficiencia en el uso de energía, área, etc. (en diferentes generaciones de CMOS). En la fig. 6, proporcionamos una comparación aproximada de las combinaciones de "arquitectura + nodos CMOS", triangulando las velocidades medidas de todas las aplicaciones en diferentes combinaciones, y usando relaciones transitivas entre aquellas combinaciones que no tienen suficientes aplicaciones comunes (menos de cinco).
Intuitivamente, estos gráficos se pueden entender como en la Fig. 6a muestra lo que "los ingenieros y gerentes ven", y la fig. 6b es "lo que vemos, excluyendo el potencial de CMOS". Me aventuraré a sugerir que le preocupa más si su nuevo chip está por delante del anterior que si lo hace debido a mejores transistores o debido a una mejor especialización.
El mercado de GPU está bien definido, diseñado y especializado, y tanto AMD como Nvidia tienen todas las razones para adelantarse, mejorando los circuitos. Pero, a pesar de esto, vemos que en su mayor parte, las aceleraciones se deben a factores relacionados con CMOS y no a CSR.
Los FPGA y tableros especiales para procesar códecs de video, estudiados por científicos, también se encuentran bajo tales características, incluso si la mejora relativa con el tiempo se volvió más o menos debido al creciente mercado. Las mismas características que le permiten responder activamente a la aceleración, en última instancia, limitan la capacidad de los aceleradores para mejorar su eficiencia. Fuchs y Wenzlaf escriben sobre la GPU: "Aunque la velocidad de fotogramas de los gráficos de la GPU se ha incrementado en 16 veces, suponemos que las mejoras adicionales en la velocidad y la eficiencia energética seguirán 1.4–2.4 veces y 1.4–1.7 veces, respectivamente" . AMD y Nvidia no tienen un espacio especial para maniobrar en el que pueda aumentar la velocidad mejorando CMOS.
Las implicaciones de este trabajo son importantes. Ella dice que lo específico de sus áreas de arquitectura ya no dará mejoras significativas en la velocidad cuando la ley de Moore deje de funcionar. E incluso si los diseñadores de chips pueden concentrarse en mejorar el rendimiento en un número fijo de transistores, estas mejoras estarán limitadas por el hecho de que los procesos bien estudiados no tienen casi nada que mejorar.
El trabajo indica la necesidad de desarrollar un enfoque fundamentalmente nuevo para la informática. Una alternativa potencial es la
arquitectura Intel Meso . Fuchs y Wenzlaf también
sugirieron el uso de materiales alternativos y otras soluciones que van más allá del alcance de CMOS, incluida la investigación sobre la posibilidad de usar memoria no volátil como aceleradores.