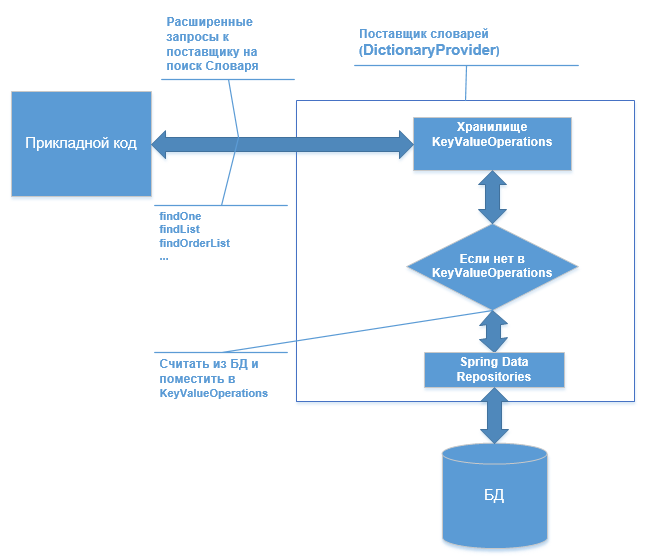
Los sistemas interactivos usan muchos directorios diferentes, diccionarios de datos, estos son varios estados, códigos, nombres, etc., por regla general, hay muchos de ellos y cada uno de ellos no es grande. En la estructura a menudo tienen atributos comunes: Código, ID, Nombre, etc. En el código de la aplicación hay muchas búsquedas diferentes, comparaciones por Código, por ID de referencia. Las búsquedas se pueden extender, por ejemplo: buscar por ID, por Código, obtener una lista por criterio, ordenar, etc. ... Y como resultado, los directorios se almacenan en caché, lo que reduce el acceso frecuente a la base de datos. Aquí quiero mostrar un ejemplo de cómo los repositorios clave-valor de Spring Data pueden ser útiles para estos fines. La idea principal es esta: una búsqueda avanzada en los repositorios de valores clave y, en ausencia de un objeto, hacer una búsqueda a través de los repositorios de datos de Spring en la base de datos y luego colocarlos en los repositorios de valores clave.
Y así, en Spring hay KeyValueOperations, que es similar al repositorio Spring Data, pero funciona con el concepto de Key-Value y coloca los datos en una estructura HashMap (
escribí sobre los repositorios Spring Data aquí ). Los objetos pueden ser de cualquier tipo, lo principal es que se especifica la clave.
public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; ....
Aquí la clave es statusId, y la ruta completa de la anotación se indica específicamente, en el futuro usaré JPA Entity, y también hay un Id allí, pero ya relacionado con la base de datos.
KeyValueOperations tiene métodos similares a los de los repositorios de Spring Data.
interface KeyValueOperations { <T> T insert(T objectToInsert); void update(Object objectToUpdate); void delete(Class<?> type); <T> T findById(Object id, Class<T> type); <T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type); .... .
Por lo tanto, puede especificar la configuración de Java KeyValueOperations para Spring Bean
@SpringBootApplication public class DemoSpringDataApplication { @Bean public KeyValueOperations keyValueTemplate() { return new KeyValueTemplate(keyValueAdapter()); } @Bean public KeyValueAdapter keyValueAdapter() { return new MapKeyValueAdapter(ConcurrentHashMap.class); }
La clase de almacenamiento del diccionario se enumera aquí: ConcurrentHashMap
Y dado que trabajaré con los diccionarios de entidades JPA, conectaré dos de ellos a este proyecto.
Este es un diccionario de "Estado" y "Tarjeta"
@Entity public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; @Id @Column(name = "STATUS_ID") public long getStatusId() { return statusId; } .... @Entity public class Card { @org.springframework.data.annotation.Id private long cardId; private String code; private String name; @Id @Column(name = "CARD_ID") public long getCardId() { return cardId; } ...
Estas son entidades estándar que corresponden a tablas en la base de datos, llamo la atención sobre dos anotaciones de Id para cada entidad, una para JPA, la otra para KeyValueOperations
La estructura de los diccionarios es similar, un ejemplo de uno de ellos.
create table STATUS ( status_id NUMBER not null, code VARCHAR2(20) not null, name VARCHAR2(50) not null );
Repositorios de Spring Data para ellos:
@Repository public interface CardCrudRepository extends CrudRepository<Card, Long> { } @Repository public interface StatusCrudRepository extends CrudRepository<Status, Long> { }
Y aquí está el ejemplo de DictionaryProvider en sí donde conectamos los repositorios de Spring Data y KeyValueOperations
@Service public class DictionaryProvider { private static Logger logger = LoggerFactory.getLogger(DictionaryProvider.class); private Map<Class, CrudRepository> repositoryMap = new HashMap<>(); @Autowired private KeyValueOperations keyValueTemplate; @Autowired private StatusCrudRepository statusRepository; @Autowired private CardCrudRepository cardRepository; @PostConstruct public void post() { repositoryMap.put(Status.class, statusRepository); repositoryMap.put(Card.class, cardRepository); } public <T> Optional<T> dictionaryById(Class<T> clazz, long id) { Optional<T> optDictionary = keyValueTemplate.findById(id, clazz); if (optDictionary.isPresent()) { logger.info("Dictionary {} found in keyValueTemplate", optDictionary.get()); return optDictionary; } CrudRepository crudRepository = repositoryMap.get(clazz); optDictionary = crudRepository.findById(id); keyValueTemplate.insert(optDictionary.get()); logger.info("Dictionary {} insert in keyValueTemplate", optDictionary.get()); return optDictionary; } ....
Las inyecciones automáticas se instalan en él para repositorios y KeyValueOperations, y luego lógica simple (aquí, sin verificar nulo, etc.), buscamos en el diccionario keyValueTemplate, si lo hay, luego regresamos, de lo contrario extraemos de la base de datos a través de crudRepository y lo colocamos en keyValueTemplate, y damos fuera
Pero si todo esto se limitara solo a una búsqueda clave, entonces probablemente no haya nada especial. Y entonces KeyValueOperations tiene una amplia gama de operaciones CRUD y solicitudes. Aquí hay un ejemplo de una búsqueda en el mismo keyValueTemplate, pero ya por Código usando la consulta KeyValueQuery.
public <T> Optional<T> dictionaryByCode(Class<T> clazz, String code) { KeyValueQuery<String> query = new KeyValueQuery<>(String.format("code == '%s'", code)); Iterable<T> iterable = keyValueTemplate.find(query, clazz); Iterator<T> iterator = iterable.iterator(); if (iterator.hasNext()) { return Optional.of(iterator.next()); } return Optional.empty(); }
Y es comprensible, si antes busqué por ID y el objeto ingresó en keyValueTemplate, entonces buscar por el código del mismo objeto lo devolverá ya desde keyValueTemplate, no habrá acceso a la base de datos. Spring Expression Language se utiliza para describir la solicitud.
Ejemplos de prueba:
Búsqueda de ID
private void find() { Optional<Status> status = dictionaryProvider.dictionaryById(Status.class, 1L); Assert.assertTrue(status.isPresent()); Optional<Card> card = dictionaryProvider.dictionaryById(Card.class, 100L); Assert.assertTrue(card.isPresent()); }
Buscar por código
private void findByCode() { Optional<Card> card = dictionaryProvider.dictionaryByCode(Card.class, "VISA"); Assert.assertTrue(card.isPresent()); }
Puede obtener listas de datos a través de
<T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type);
Puede especificar la ordenación en la solicitud
query.setSort(Sort.by(DESC, "name"));
Materiales:
valor clave de spring-dataProyecto Github