Yandex tiene un servicio de desarrollo de componentes de búsqueda que construye una base de búsqueda en MapReduce, proporciona datos para la composición tipográfica para la representación, genera algoritmos y estructuras de datos, y resuelve tareas de ML de crecimiento de calidad. Alexey Shlyunkin, jefe de uno de los grupos dentro de este servicio, explica en qué consiste el tiempo de ejecución de búsqueda y cómo lo gestionamos.
¿Quieres hurgar en ML? Solo quieres MapReduce - ok. ¿Quieres tiempo de ejecución?
- ¿Qué es una búsqueda hoy? Yandex comenzó haciendo una búsqueda, desarrollándola. Han pasado 20 años. Tenemos una base de búsqueda para cientos de miles de millones de documentos.
Llamamos a un documento cualquier página en Internet, pero, de hecho, no solo eso. Aún así, su contenido, varias estadísticas sobre a qué usuarios les gusta ir, cuántos. Además de los datos que calculamos.
También son decenas de miles de instancias que, en respuesta a cada solicitud, procesan datos, buscan algo, enriquecen la respuesta de búsqueda. Algunas instancias buscan imágenes, algunas para documentos de texto ordinarios, otras para video, etc. Es decir, decenas de miles de máquinas están activadas para cada solicitud. Todos intentan encontrar algo y mejorar el resultado que se les muestra. En consecuencia, decenas de miles de máquinas atienden miles de solicitudes por segundo. Estas decenas de miles de instancias se combinan en cientos de servicios diseñados para resolver un problema.

Hay un núcleo de búsqueda: un servicio de búsqueda web. Y hay un servicio de búsqueda de video, etc. En consecuencia, hay una cosa que combina las respuestas de diferentes búsquedas e intenta elegir qué y en qué orden es mejor mostrar al usuario. Si se trata de algún tipo de solicitud sobre música, entonces probablemente sea mejor mostrar Yandex.Music primero y luego, por ejemplo, una página sobre este grupo de música. Esto se llama licuadora. Ya hay cientos de dichos servicios, y también hacen algo para cada solicitud e intentan ayudar a los usuarios de alguna manera. Y, por supuesto, todo esto utiliza el aprendizaje automático de todo tipo, desde algunas estadísticas simples, modelos lineales, hasta potenciadores de gradiente, redes neuronales, etc.
Hablaré sobre infraestructura y ML ahora mismo.
Mi grupo se llama el nuevo grupo de desarrollo de tiempo de ejecución, es parte del servicio de desarrollo de componentes de búsqueda. Para que tengas una idea, te contaré un poco lo que hace nuestro servicio.

De hecho, para todos. Si envía una búsqueda, entonces lanzamos nuestras manos a casi todo, comenzando por construir una base de búsqueda. Es decir, tenemos MapReduce, recopilamos todos los datos sobre los documentos allí, los hierve, construimos todo tipo de estructuras de datos, de modo que cuando los consultamos, podamos calcular algo de manera eficiente. En consecuencia, trabajamos desde la parte inferior cuando el documento nos llega, desde la primera etapa, cuando estos documentos obtienen algo y lo clasifican, y hasta la parte superior, donde el diseño recibe JSON condicional y lo dibuja con todas las imágenes y cosas hermosas. De abajo hacia arriba, estamos desarrollando algo en toda la pila.
Pero no solo estamos escribiendo código y, en consecuencia, estamos haciendo todo esto en infraestructura. En realidad estamos entrenando redes neuronales, CatBoost. Y otras cosas de ML que puedes imaginar y quemar, también te las enseñamos. Además, dado que tenemos grandes cargas, grandes datos, por supuesto, hurgamos en algoritmos y estructuras de datos y nunca nos limitamos a introducirlos en algún lugar. Por ejemplo, en varios lugares usamos árboles de segmentos. Tenemos nuestra propia compresión de índices que crean boro y, de acuerdo con esto, consideramos la dinámica de la mejor manera de construir diccionarios.
En general, al tratar con un coloso tan grande como una búsqueda, estábamos saturados de tareas tan simples. Por lo tanto, nosotros, por supuesto, adoramos algo complejo, nuevo, algo que nos desafía. Y no solo fuimos y escribimos, como siempre, diez líneas de código. Necesitamos pensar en algunos experimentos. En general, las tareas que nos proponemos a menudo están al borde de la ficción. A veces piensas: probablemente no sea posible. Pero entonces, tal vez, experimentaste de alguna manera, los experimentos pueden tomar todo un año, pero al final algo resulta. Luego comenzamos a presentar, rehacer algo.
Y además de cualquier proyecto, habilidades, etc., en general, somos uno de los equipos más ambiciosos y de rápido crecimiento en Yandex. Por ejemplo, vine hace dos años, era la novena persona en nuestro servicio. Ahora contamos con un servicio de casi 60 personas. Esto es, de hecho, con los pasantes, pero, en general, cuatro veces hemos crecido exactamente en dos años. Esto es para darle una idea de lo que está haciendo nuestro servicio.
Ahora quiero contarles un poco sobre la parte superior de nuestras tareas y la dirección que, me parece, en el futuro cercano seremos más y más relevantes. Pero para esto, primero debe describir brevemente cómo funciona la capa de búsqueda más básica.
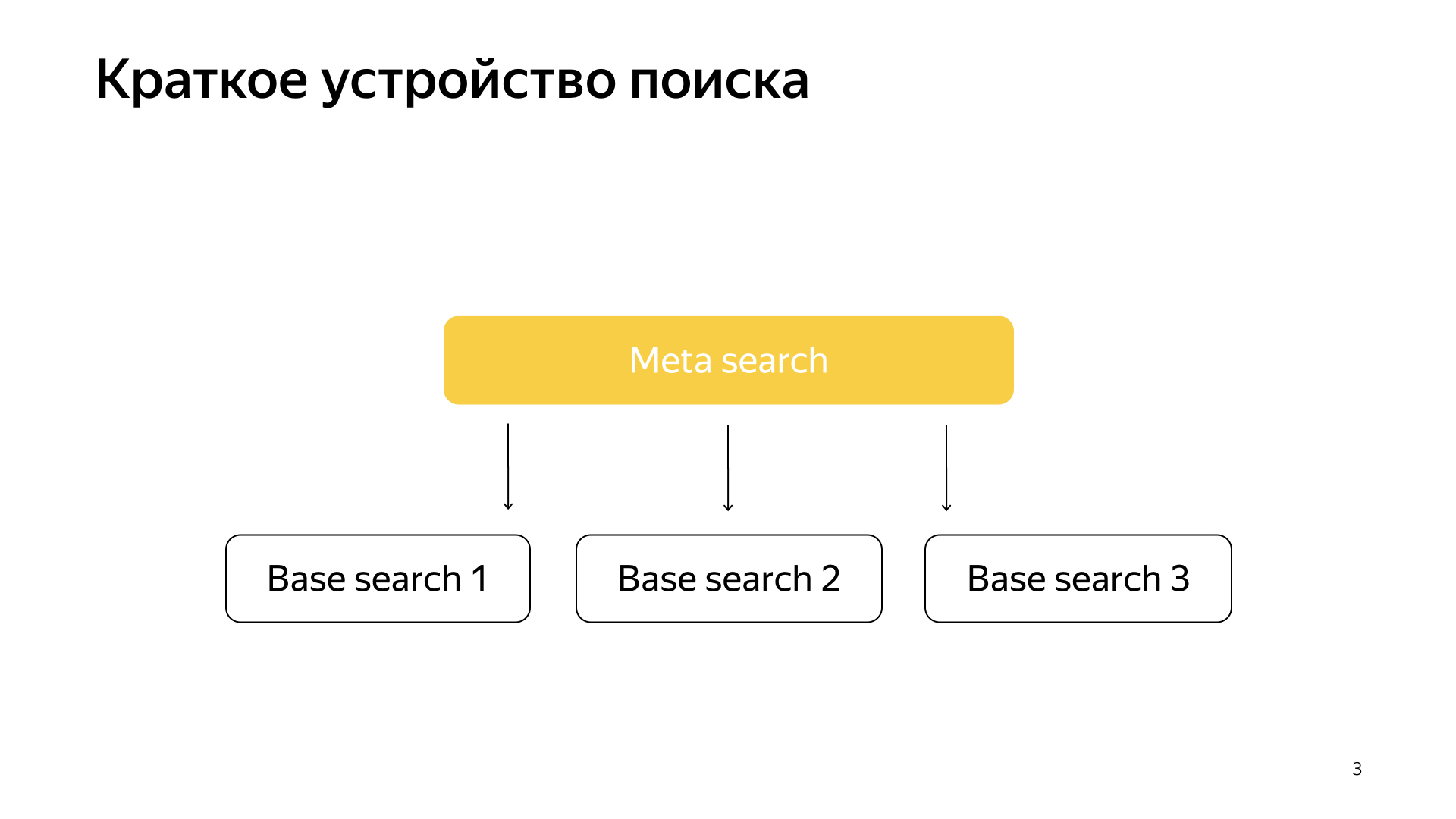
En términos generales, todo funciona de manera muy simple. Tenemos nuestra base de búsqueda, tenemos todos los documentos y dividimos todos estos documentos de manera más o menos uniforme en N piezas. Se llaman fragmentos. Y se lanza un programa llamado "Búsqueda básica" sobre el fragmento. Su tarea es buscar, en consecuencia, en este pedazo de Internet. Es decir, ella sabe cómo buscarlo y no sabe nada más sobre el otro Internet. Y tenemos N fragmentos como ese. Las búsquedas básicas se inician por encima de ellas y, en consecuencia, hay una meta búsqueda sobre esto. La solicitud del usuario cae en él y, en consecuencia, simplemente va a todos los fragmentos, y cada fragmento realiza una búsqueda, luego cada uno devuelve un resultado, y realiza algún tipo de fusión y da una respuesta.
Así fue como se organizó la búsqueda durante casi todos los 20 años y, en general, durante mucho tiempo pensaron que esto seguiría siendo así, y que no se podía hacer nada mejor. Pero todo está cambiando, están surgiendo nuevas tecnologías y el aprendizaje automático ahora no solo le permite aumentar la calidad, sino que también le permite resolver algún tipo de problemas de infraestructura. Recientemente, en nuestra búsqueda, los proyectos se han disparado mucho, justo en la unión de la infraestructura y el aprendizaje automático. Cuando dos de estos mastodontes se fusionan, se obtienen resultados muy interesantes.

Recientemente, han aparecido redes neuronales. Tenemos el texto de la solicitud, está el texto del documento. Queremos obtener algunos vectores de números de la solicitud, obtener algunos vectores de números del documento para que el producto escalar prediga el valor que queremos. Por ejemplo, queremos capacitar al producto escalar para predecir la probabilidad de que un usuario haga clic en este documento. Una cosa bastante comprensible.
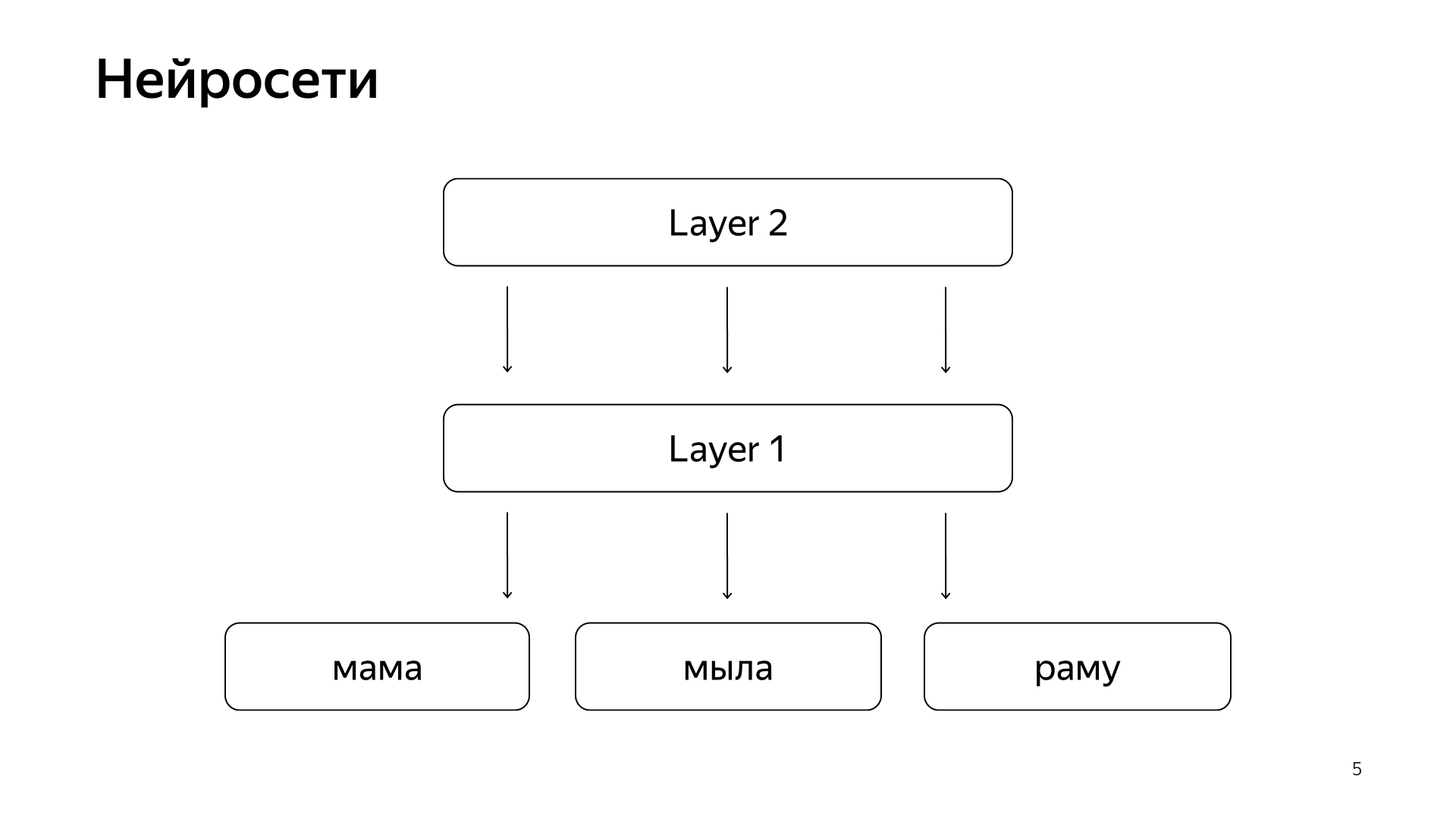
Está organizado aproximadamente de esta manera. Si es muy, muy grosero, entonces tenemos algunas palabras en la capa inferior, y luego hay varias capas de la red. Cada capa, de hecho, toma un vector como entrada. Es decir, la capa inferior es un vector tan escaso, donde cada palabra es una solicitud. Lo multiplica por una matriz, obtiene algún tipo de vector y luego, en consecuencia, aplica cierta no linealidad a cada componente, y lo hace varias veces. Y la última capa, esto se llama solo el vector que acabamos de tomar la solicitud, aplicamos tales capas, y aquí la última capa es el vector de solicitud.
En consecuencia, estas redes neuronales se han introducido activamente en la búsqueda en los últimos años, trajeron muchos beneficios para la calidad. Pero tienen un problema porque todas las cantidades que queremos predecir son buenas, pero lo suficientemente aproximadas, porque para entrenar una red neuronal así, la capa inferior es muy grande: todas las palabras provienen de decenas de millones de palabras, por lo que debe poder escribir su entrada varios miles de millones de datos.
Por ejemplo, podemos entrenarnos en algunos clics de usuarios, y así sucesivamente. Pero la señal principal que se considera la más importante en nuestra búsqueda es el marcado manual por parte de personas especiales. Toman la solicitud, toman el documento, lo leen, entienden lo bueno que es y ponen una marca, es decir, cuánto se ajusta este documento a esta solicitud. Durante mucho tiempo, no pudimos predecir tal magnitud por las redes neuronales, porque todavía tenemos millones de estimaciones, porque contratar todo el planeta para marcarlo todo constantemente es muy costoso. Por lo tanto, hicimos un truco.
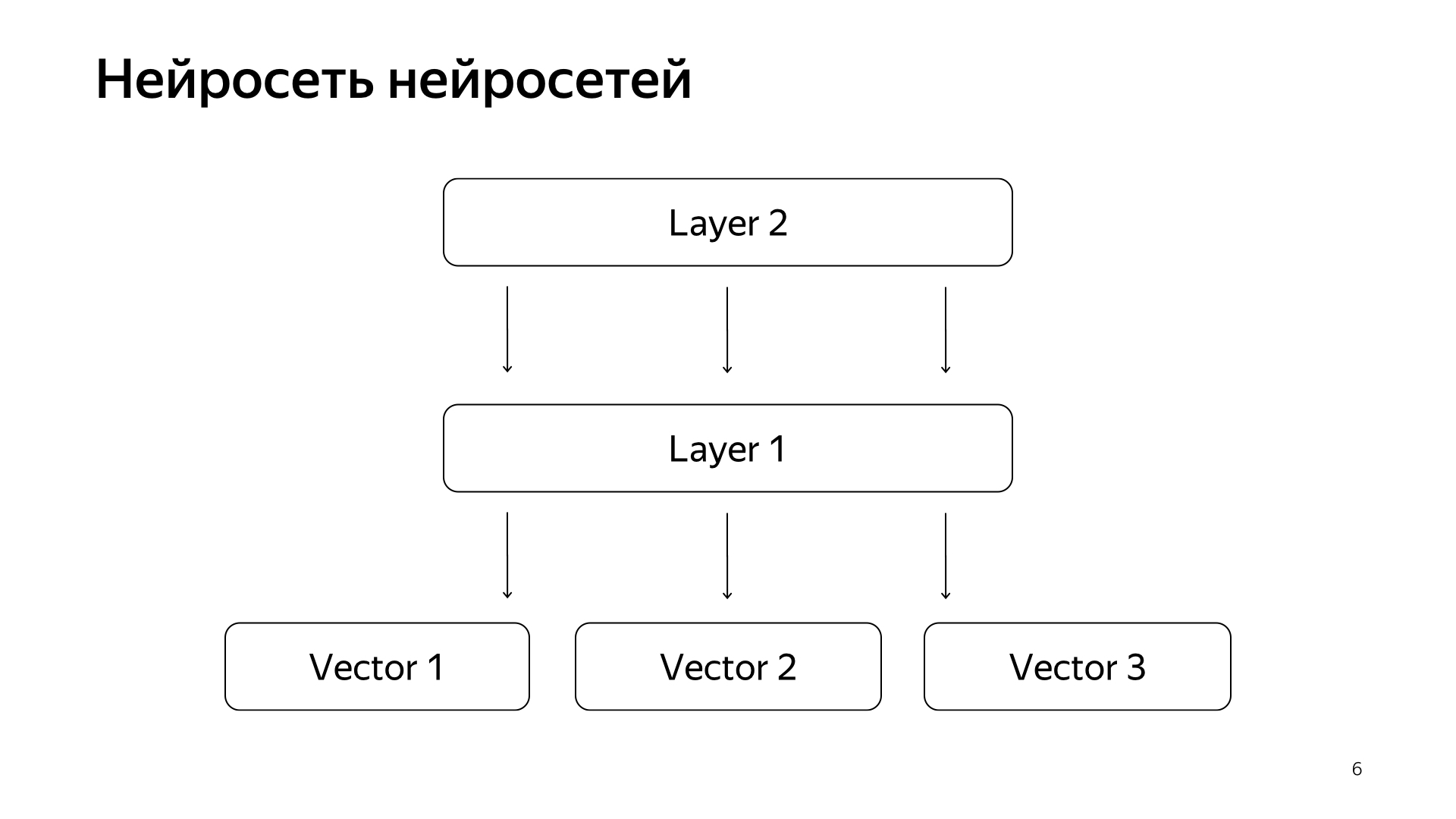
Red neuronal de redes neuronales. En los últimos años, hemos acumulado muchas redes neuronales que predicen buenas señales, pero un poco más ásperas que la evaluación de personas especiales. Por consiguiente, decidimos que enviaríamos los vectores ya preparados de estas redes a la capa inferior, y luego entrenaremos a la red neuronal para predecir nuestra relevancia de búsqueda en la red de datos más pequeña.
El resultado fue un muy buen modelo. Ella trae las solicitudes de documentos a un vector, y su producto escalar predice directamente la relevancia real que siempre hemos querido predecir.
Además, teníamos una idea de cómo rehacer un poco la búsqueda. El proyecto se llama una base KNN (inglés k-vecinos más cercanos, método k-vecinos más cercanos).

La idea básica es esta. Tenemos un vector de consulta y un vector de documento. Necesitamos encontrar el más cercano. Tenemos cada documento representado por un vector. Destaquemos N grupos, aquellos que caracterizan todo el espacio del documento. Hablando más o menos. Fuertemente más pequeño que el número de documentos, pero por ejemplo, caracterizan los temas. En términos simples, hay un grupo de gatos, un grupo de comestibles, un grupo de programación, etc.
En consecuencia, no dispersaremos los documentos aleatoriamente en fragmentos, como antes, pero colocaremos el documento en ese fragmento, es decir, el centroide que está más cerca del documento. En consecuencia, tendremos dichos documentos agrupados por tema en fragmento.
Y además, solo por una solicitud, ahora no podemos ir a todos los fragmentos, sino solo ir a un pequeño subconjunto de aquellos que están más cerca de esta solicitud.
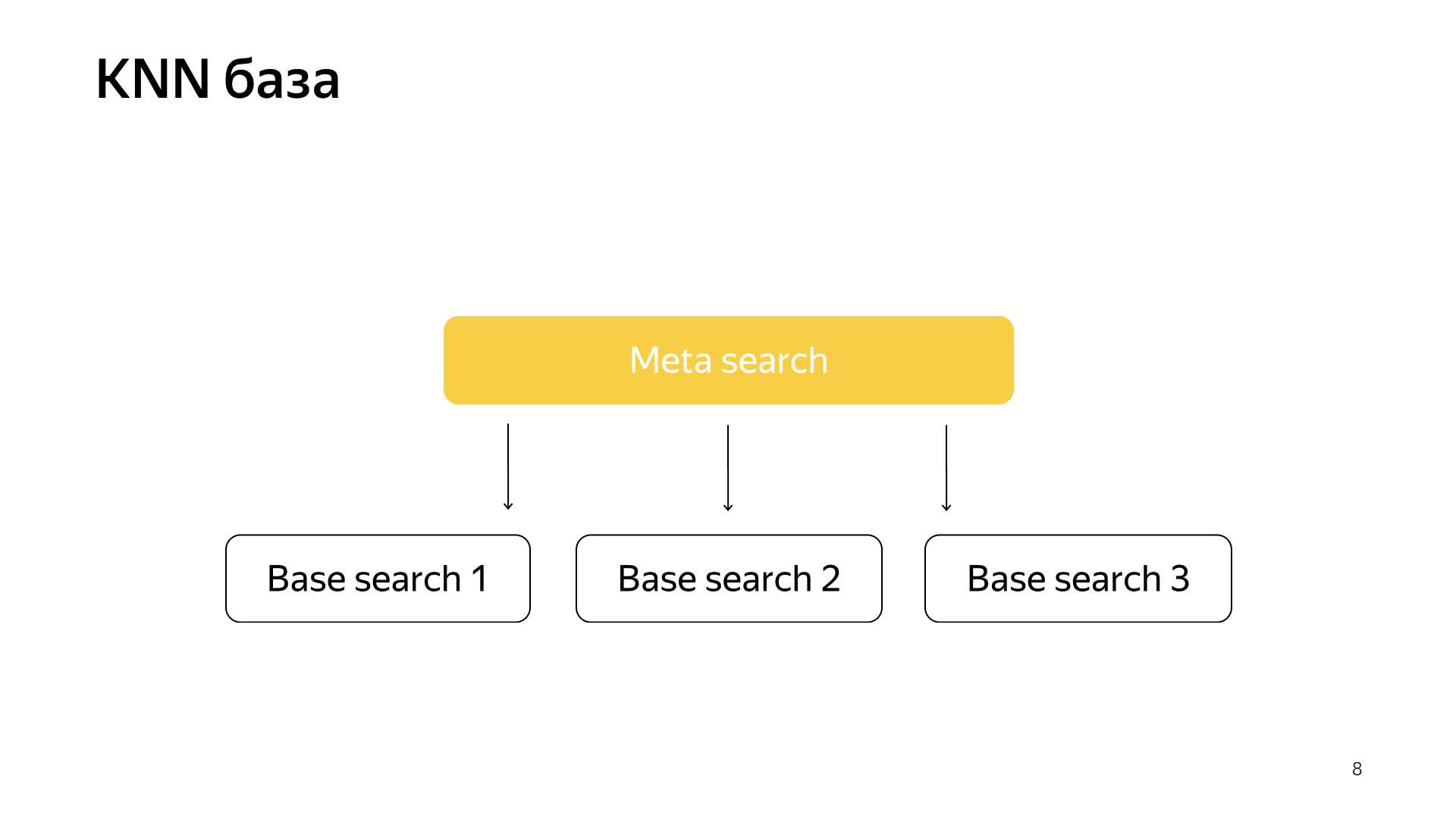
En consecuencia, teníamos un esquema de este tipo, la metabúsqueda está incluida en todos los fragmentos. Y ahora necesita ir a un número mucho menor, y al mismo tiempo seguiremos buscando los documentos más cercanos.
¿Qué obtenemos realmente de este diseño? Reduce significativamente el consumo de recursos informáticos, simplemente porque vamos a menos grupos. Esto, como ya he dicho, considero uno de los aspectos más destacados de nuestro servicio, esta es la aleación de infraestructura y aprendizaje automático que ofrece resultados que nadie podía pensar antes.

Y, al final, es algo bastante divertido, porque obtuviste los modelos aquí, y luego fuiste, rehiciste toda la búsqueda, apagaste los petabytes de datos y tu búsqueda funciona, quema diez veces menos recursos. Usted ahorró mil millones de dólares para la compañía, todos están felices.

Hablé sobre uno de los proyectos que aparece en nuestra búsqueda y que se está implementando y haciendo junto con todos los experimentos durante un año suspendido. Nuestras otras tareas típicas son duplicar la base de búsqueda, porque Internet está en constante crecimiento y queremos ponernos al día y buscar en todas las páginas de Internet. Y, por supuesto, esta es la aceleración de la capa base, en la que hay más casos, más hierro. Por ejemplo, acelerar su búsqueda base en un uno por ciento significa ahorrar aproximadamente un millón de dólares.
También participamos en la búsqueda como incubadora de inicio. Te lo explicaré. La búsqueda se ha realizado durante 20 años. Ya ha hecho muchas cosas, muchas veces nos topamos con un callejón sin salida y pensamos que no se podía hacer nada más. Luego hubo una larga serie de experimentos. Nuevamente atravesamos este callejón sin salida. Y durante este tiempo hemos acumulado mucha experiencia sobre cómo hacer cosas grandes y geniales. En consecuencia, ahora la mayoría de las nuevas direcciones en Yandex se realizan en la búsqueda, porque las personas en la búsqueda ya saben cómo hacer todo esto, y es lógico pedirles que al menos diseñen algún sistema nuevo. Y como máximo, ve y hazlo tú mismo.
Ahora, espero que tengas una pequeña idea de nuestro trabajo. Contaré rápidamente la parte temática de mi historia sobre pasantes en nuestro servicio. Los amamos mucho. Tenemos muchos, el verano pasado solo en mi grupo había 20 aprendices, y creo que esto es bueno. Cuando llevas a uno o tres pasantes, se sienten un poco solos, a veces tienen miedo de preguntar a los camaradas mayores. Y cuando hay muchos de ellos, se comunican entre sí como compañeros en la desgracia. Si tienen miedo de preguntarle algo a los desarrolladores, irán, susurrarán en la esquina. Tal ambiente ayuda a hacer todo de manera eficiente.
Tenemos un millón de tareas, el equipo no es muy grande, por lo que nuestros pasantes están completamente cargados. No le pedimos al alumno que se siente en el registrador todo el tiempo, escriba pruebas, refactorice el código, pero inmediatamente le damos algún tipo de tarea de producción complicada: acelerar la búsqueda, mejorar la compresión del índice. Por supuesto que te ayudamos. Sabemos que todo esto vale la pena, por lo que nos complace compartir nuestra experiencia. Dado que nuestro campo de actividad es bastante extenso, cada uno de nosotros encontrará una tarea para él a su gusto. ¿Quieres hurgar en ML? Solo quieres MapReduce - ok. ¿Quieres tiempo de ejecución? Hay de todo.
¿Qué necesitas para llegar a nosotros? Hacemos todo principalmente en C ++ y Python. No es necesario saber ambos, uno puede saber una cosa. Agradecemos el conocimiento de algoritmos. Forma un cierto estilo de pensamiento y ayuda mucho. Pero esto tampoco es necesario: nuevamente, estamos listos para enseñar todo, estamos listos para invertir nuestro tiempo, porque sabemos que vale la pena. El requisito más importante que hacemos, nuestro lema, es no tener miedo a nada ni a muchas figuras. No tenga miedo de abandonar la producción, no tenga miedo de comenzar a hacer algo complicado. Por lo tanto, necesitamos personas que tampoco tengan miedo a nada y que también estén listas para convertir montañas. Muchas gracias