En esta publicación, hablaremos sobre un estudio piloto de ML para el hipermercado en línea de Utkonos, donde predijimos la recompra de productos perecederos. Al mismo tiempo, tomamos en cuenta los datos no solo sobre saldos de existencias, sino también el calendario de producción con fines de semana y días festivos, e incluso el clima (calor, nieve, lluvia y granizo no son más que Taft Three Weathers, pero no clientes). Ahora sabemos, por ejemplo, que el "misterioso alma rusa" está especialmente hambriento de carne los sábados y aprecia los huevos blancos por encima de los marrones. Pero lo primero es lo primero.

Piloto minorista más que piloto
En el comercio minorista, el aprendizaje automático está en una posición dual. Por un lado, los minoristas han acumulado cantidades impresionantes de datos durante períodos de tiempo muy impresionantes: recibos de compras individuales, datos de tarjetas de fidelización ... Por otro lado, los minoristas han existido durante tanto tiempo que el problema de pronóstico de la demanda comenzó a resolverse mucho antes de que apareciera la moda de la ciencia de datos y hoy está a su disposición. herramientas de BI necesarias.
Resulta que el comercio minorista es uno de los campos más prometedores para los experimentos de científicos de datos y la introducción del aprendizaje automático, pero las empresas miran todo esto con escepticismo: ¿es realmente bueno para mí? Después de todo, ya hay soluciones de trabajo probadas por muchos años de experiencia.
¡Y entonces es hora de acordar un estudio piloto!
Los propios pilotos, en comparación con un proyecto ML completo, tienen limitaciones y detalles entendibles.
- Se dedica suficiente tiempo a un estudio piloto para mostrar a los clientes las posibilidades de aprendizaje automático sobre sus datos, pero no tanto como para perder dinero.
- Además, como regla general, los especialistas en datos ya no tendrán una segunda oportunidad: si los primeros resultados del negocio no parecen interesantes, entonces se mantendrán escépticos y fieles a los viejos métodos de pronóstico. Por lo tanto, debe apuntar con precisión.
- Durante el proyecto piloto, no puede surgir una relación de confianza entre el cliente y el centro de datos. Y es probable que las unidades y especialistas que poseen los datos importantes para la interpretación no estén disponibles durante la prueba piloto, así como las ideas comercialmente importantes.
Por supuesto, estas características no se manifiestan en cada proyecto piloto, pero constituyen una parte importante de sus riesgos.
Un poco sobre la tarea
Mucho antes de familiarizarse con el aprendizaje automático, Utkonos ya utilizaba su propio sistema analítico, que predecía el reembolso de los bienes durante una semana con una precisión muy alta. Sin embargo, el minorista está interesado en la posibilidad de aumentar la efectividad de la planificación. Esto se refería principalmente a productos perecederos, muchos de los cuales también son muy caros. Tenedor tradicional: si compra mucho, habrá pérdidas, si no compra lo suficiente, el comprador irá al competidor por su amado lomo de ternera cosechado con luna llena y lluvia ligeramente llovizna. Para un pronóstico suficientemente preciso para pasado mañana, las soluciones basadas en el aprendizaje automático son más adecuadas, lo que permite tener en cuenta más factores que las herramientas de BI clásicas. Utkonos acordó actuar como nuestro socio para un experimento destinado a probar las hipótesis de la aplicabilidad de Machine Learning al comercio electrónico.
Para mostrar las posibilidades del aprendizaje automático para resolver este problema, de acuerdo con el negocio, se seleccionaron varios nombres comerciales:
- dos productos de la categoría "Carne refrigerada" - como productos perecederos, cuya información es más importante para actualizar rápidamente;
- y dos productos de la categoría "Huevo de gallina" - como productos con una demanda estacional específica, que no se puede predecir simplemente como "el jueves todos compran X, y el viernes - X se multiplica por un coeficiente". Aunque los huevos de gallina no son difíciles de predecir ejecuciones hipotecarias y solo para ellos el horizonte de planificación semanal es bastante aceptable, fue en estos productos que fue necesario demostrar que el aprendizaje automático realmente ve relaciones complejas y construye un pronóstico no trivial.
Hemos elegido productos específicos a nuestro gusto, confiando en la integridad de los datos históricos. Algunos productos se introdujeron recientemente en la línea, otros, por el contrario, se vendieron una vez, pero en este momento ya se habían retirado del surtido, por lo que el valor de los datos sobre ellos era solo histórico.
Los datos proporcionados por Utkonos contenían información sobre las ventas de cuatro nombres de productos para los 2 años anteriores y sobre la disponibilidad de estos productos en stock en los períodos relevantes. Desde el conjunto de datos generales, inmediatamente "cortamos" los últimos seis meses, desde principios de noviembre hasta finales de abril, este será nuestro conjunto de pruebas. Incluía meses de otoño relativamente tranquilos y una serie de vacaciones de invierno y vacaciones de primavera.
Nos esperaba una corta pero emocionante aventura.
Datos de almacenes: misteriosos y necesarios
Al trabajar con datos históricos, la primera pregunta que surgió ante nosotros fue cómo separar las ventas reales de las "ventas máximas disponibles" (es decir, los casos en que los bienes que terminan en el almacén se canjearon al 100%, pero si están disponibles, el volumen de ventas podría ser más alto)? Dichos deseos incumplidos de los compradores, después de todo, no se muestran en los datos de ninguna manera.
Disponibilidad de bienes en stock. Por cierto, a partir de la experiencia de proyectos anteriores en el comercio minorista, esperábamos que estos fueran saldos expresados en unidades de medida. Sin embargo, en este caso, estábamos tratando con el indicador relativo "accesibilidad", que se midió en porcentaje durante el día. En cuanto a la disponibilidad de bienes en el almacén, este indicador es muy relativo: el hecho de que no hubiera ningún producto en ningún momento no significaba que quisieran comprarlo.
Después de experimentar con diferentes opciones (reconstrucción de la "demanda real" basada en coeficientes calculados de manera diferente y filtrar el conjunto de datos de ventas con diferentes umbrales de accesibilidad), finalmente seleccionamos el umbral óptimo que no redujo demasiado el conjunto de datos. El ideal, la disponibilidad de productos durante todo el día, redujo significativamente los datos incluso para los productos más vendidos.
Artículo 1: carne refrigerada (aves de corral inusuales)
Comenzamos a trabajar con carne refrigerada, ya que no dudamos de la capacidad predictiva del modelo, tan pronto como estuvo listo en forma de borrador. (Spoiler: pero en vano, en el conjunto de datos con ventas de huevos nos esperaba una sorpresa interesante, pero más sobre eso más adelante).
Para ahorrar tiempo "fuera de la caja", tenemos una biblioteca lista para usar que funciona bien con series de tiempo: Prophet de Facebook .

Los resultados del modelo en los datos de entrenamiento muestran inmediatamente ventajas y desventajas. El modelo recoge bien la estacionalidad de la demanda, pero elige mal. También vacaciones conectadas por el Profeta por defecto. La desviación relativa es 31.36%, continuaremos usándola como resultado base.
La herramienta de visualización de estacionalidad incorporada, que Prophet ve, le permite obtener de inmediato una pequeña idea de cómo cambiaron las compras de uno de los productos durante dos años, qué características tienen durante el año y durante la semana:

Nuestra carne refrigerada tiene una clara tendencia al alza en el número total de compras, el número de compras aumenta de lunes a sábado y cae los domingos, en verano las compras notablemente "ceden". Es malo que el verano no entre en nuestro período de prueba; Por otro lado, recuerde que el período de vacaciones y vacaciones es importante para el nivel de ventas, porque las vacaciones de verano están lejos de ser las únicas en Rusia.
La pregunta lógica es: ¿es posible usar este modelo inmediatamente para pronosticar para los próximos seis meses?
Intuitivamente, parece que no. El experimento demostró que sí. El patrón general de estacionalidad durante la semana es correcto. Pero inmediatamente se hizo evidente que hay un millón de desviaciones del patrón estacional general, tanto hacia arriba como hacia abajo, y la desviación promedio de 45.71% es mucho mayor que los resultados en los datos de entrenamiento. Está claro que esto no es bueno.
Para empezar, intentemos entrenar el modelo diariamente, imaginando que todos los días después de la finalización de la tienda, el conjunto de datos se complementa con las ventas de "hoy". Ya sabemos que en las ventas hay una tendencia al alza en general: es posible que el volumen de ventas en nuestros datos de prueba crezca con mayor intensidad debido a una actividad de marketing más activa que en el conjunto de capacitación.
Éxito relativo: con la reentrenamiento diario del modelo, la desviación relativa es del 33,79%. Complementamos los parámetros del modelo con información sobre los fines de semana pospuestos, el ayuno religioso y los días festivos tradicionales de Rusia (como Año Nuevo, Pascua y otros). También se agregaron cambios climáticos repentinos: días en que la temperatura subía o bajaba más de 10 grados o simplemente era notablemente más alta o más baja que otros días de este mes. Ahora, en promedio durante seis meses, nuestro pronóstico se desvió de las ventas reales en un 28.48% y, en general, el modelo comenzó a tener mejor en cuenta los aumentos en la actividad del consumidor. ¡Mejoramos la desviación promedio en un cinco por ciento! A pesar de que el Profeta, en principio, funciona mal y se recomienda eliminar los datos de ellos, fue un notable movimiento hacia adelante.


Antes de mostrar los resultados preliminares, surgió la pregunta: ¿podemos mejorar un poco más el pronóstico? Si observa la correlación de las ventas de productos y su precio promedio por día, está claro que estas son características relacionadas, y el precio no se tiene en cuenta al construir el modelo. Pero a juzgar por el conjunto de datos, podríamos tomar solo un cierto "precio promedio por unidad": en los pedidos a menudo variaba durante el mismo día, es decir se registró con un descuento personal del comprador, y los precios de "escaparate" no se incluyeron en el conjunto de datos.

El coeficiente de correlación entre el precio promedio por unidad por día y el número de volumen vendido de este tipo de carne refrigerada fue de ¬ - 0.61 a p <0.01. Está claro que el "precio unitario promedio" no es un indicador ideal: si durante el día hubo muchas compras de, por ejemplo, socios con un gran descuento constante, el ruido peligroso se introducirá en los datos. Pero queríamos resaltar los días en que hubo impactos de marketing: descuentos generales en un grupo de productos, descuentos para todos los que introducen un código promocional de distribución gratuita, etc.
Sin embargo, incluso después de que los días con el precio promedio en el cuantil del 5% se asignaron como días promocionales, no hubo un aumento en la precisión del modelo. La precisión aumentó en días de ventas extremas, y la desviación relativa promedio durante seis meses se mantuvo igual.
Pero la idea de una relación estadística pronunciada con el precio se ha conservado para el futuro.

Estábamos bastante satisfechos con el resultado preliminar, era hora de pasar a otros productos antes de que terminara el tiempo asignado para el proyecto piloto.
Artículo 2: huevo de gallina
Se nos advirtió de inmediato que los huevos son una de las categorías de productos más indicativas en términos del impacto de eventos externos. En primer lugar, el volumen de compras crece en Semana Santa: los huevos se pintan y se cocinan con huevos. Pero más, por supuesto, está pintado. Esto es fácil de entender al comparar las ventas de huevos blancos y marrones.

En general, nuestro modelo espera que haya un ligero aumento en la demanda en Semana Santa, pero su pronóstico es casi 2 veces menor que el indicador real (y esta desviación de ~ 100% durante la semana de Pascua hace que la desviación promedio de seis meses sea increíblemente grande). Por qué Después de todo, la semana de Pascua ocurre anualmente: ¡debe haber un patrón en los datos de los 2 años anteriores!
El análisis de la investigación ha demostrado que no hay patrón. En 2018 (estos son nuestros datos de prueba), el pico de compras cae toda la semana antes de Pascua hasta el 7 de abril. En la Pascua misma (8 de abril de 2018), las compras de huevos siempre caen, lo que el modelo ve correctamente. Pero en 2017, la Pascua cae el 16 de abril, y el pico de compras en datos históricos es el 8 de abril, y este año el pico es un día. En 2016, la Pascua cae el 1 de mayo. El pico de compras es el 29 de abril, con aumentos un día antes y un día después. En 2015, Pascua cae el 12 de abril, el pico de compras es nuevamente un día, 9 de abril.

Nuestra primera versión fue la influencia de los días de la semana (y la imaginación pintó a los padres que, para mañana, necesitan pintar una docena de huevos, porque la lección temática, y el niño dijo esto hoy). Por desgracia, esto no es así. Probablemente, durante la Pascua hay algunos factores que aún no hemos encontrado (y no hemos tenido en cuenta), tanto externos como relacionados con el marketing de la propia empresa.
¡Podemos hacerlo mejor!
Esta historia trata sobre trabajar con datos de minoristas durante un tiempo limitado y no sobre técnicas de aprendizaje automático encubiertas. Pero al trabajar con datos existe la oportunidad de mejorar el resultado.
Después de trabajar con productos de la categoría "Huevo de gallina", quedó claro que el modelo puede mejorarse agregando factores que no utilizamos en el proyecto piloto. Por lo tanto, se decidió realizar un pequeño experimento con un bosque aleatorio y datos que podemos recopilar de fuentes abiertas. Además, podremos ver cómo se comporta el modelo, dónde los días de venta tendrán un conjunto diverso de signos, y no solo un conjunto de "días especiales" asignados de una forma u otra.
La siguiente información se recopiló en el conjunto de datos sobre el "mundo exterior":
- un calendario completo de producción para cada año;
- puestos religiosos y feriados, feriados seculares;
- condiciones climáticas y sus desviaciones de los valores promedio durante un mes en la región, así como las fluctuaciones durante el último mes, día y semana;
- los tipos de cambio del dólar y el euro para el Banco Central y sus fluctuaciones como indicadores de la situación económica general.
Por separado, se agregaron letreros para realizar campañas de marketing separadas y el precio por unidad de bienes.
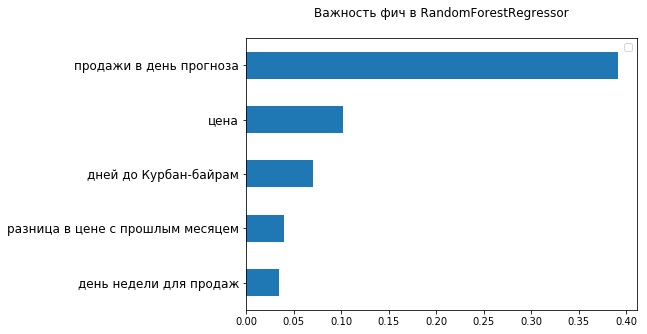
En el conjunto de datos extendido, nuevamente construimos un modelo que diariamente se entrenaba en nuevos datos, ahora usando RandomForestRegressor. La desviación relativa mejoró levemente: a 27.29%. El gráfico muestra que el nuevo modelo predice mejor el impacto de las campañas de marketing, pero peor: la estacionalidad semanal.

Mirando los 5 signos más importantes desde el punto de vista del RandomForestRegressor usado, puede asegurarse de que ya hay dos signos relacionados con el valor de los bienes: el precio actual y sus cambios en comparación con el mes pasado. Obviamente, el hecho de que el rango de precios no pudiera establecerse bien en el FB Prophet afectó su precisión.
Al verificar si podemos pensar un poco más y mejorar el resultado, se completó el estudio piloto. Los objetivos principales se lograron: demostramos que el aprendizaje automático es, en principio, aplicable a los datos del minorista y muestra buenos resultados incluso en el modo de "inicio rápido".
Alexandra Tsareva, Especialista, Análisis Inteligente, Jet Infosystems