Cualquier operación con big data requiere mucha potencia informática. Un movimiento típico de datos de una base de datos a Hadoop puede llevar semanas o costar tanto como un ala de avión. ¿No quieres esperar y derrochar? Equilibre la carga en diferentes plataformas. Una forma es la optimización pushdown.
Le pedí a Alexei Ananyev, un entrenador ruso líder para el desarrollo y administración de productos de Informatica, que hablara sobre la función de optimización de pushdown en Informatica Big Data Management (BDM). ¿Alguna vez aprendió a trabajar con productos de Informatica? Lo más probable es que fue Alex quien le contó los conceptos básicos de PowerCenter y le explicó cómo crear asignaciones.
Alexey Ananiev, jefe de formación en DIS Group
¿Qué es el pushdown?
Muchos de ustedes ya están familiarizados con Informatica Big Data Management (BDM). El producto puede integrar big data de diferentes fuentes, moverlo entre diferentes sistemas, proporciona un acceso fácil a ellos, le permite perfilarlos y mucho más.
En manos hábiles, BDM puede hacer maravillas: las tareas se completarán rápidamente y con recursos informáticos mínimos.
¿Tú también lo quieres? Aprenda a usar la función pushdown en BDM para distribuir la carga informática en las plataformas. La tecnología Pushdown le permite convertir la asignación en un script y elegir el entorno en el que se ejecutará este script. La posibilidad de tal elección le permite combinar las fortalezas de diferentes plataformas y lograr su máximo rendimiento.
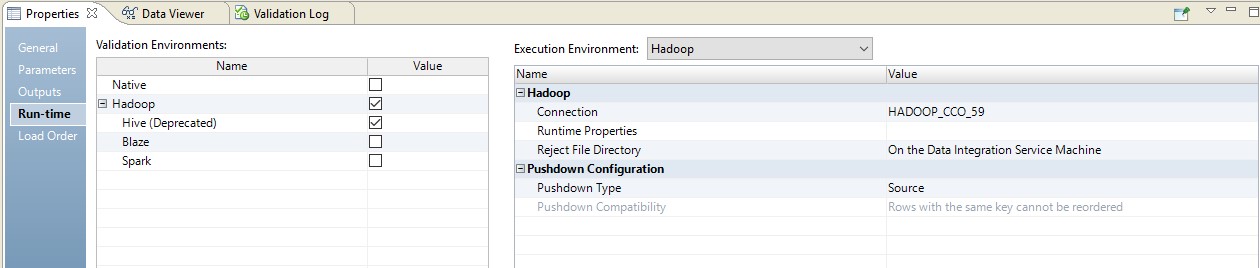
Para configurar el tiempo de ejecución del script, seleccione el tipo pushdown. El script puede ejecutarse completamente en Hadoop o distribuirse parcialmente entre la fuente y el receptor. Hay 4 tipos posibles de pushdown. La asignación no se puede convertir en un script (nativo). La asignación se puede realizar tanto como sea posible en la fuente (fuente) o completamente en la fuente (completa). La asignación también se puede convertir en un script Hadoop (ninguno).
Optimización de pushdown
Los 4 tipos enumerados se pueden combinar de diferentes maneras: optimice el pushdown para las necesidades específicas del sistema. Por ejemplo, a menudo es más recomendable extraer datos de una base de datos utilizando sus propias capacidades. Y para transformar los datos, por Hadoop, para que la base de datos en sí no se sobrecargue.
Veamos el caso cuando tanto el origen como el receptor están en la base de datos, y se puede seleccionar la plataforma de ejecución de transformación: dependiendo de la configuración, será Informatica, un servidor de base de datos o Hadoop. Tal ejemplo permitirá comprender con mayor precisión el lado técnico de este mecanismo. Naturalmente, en la vida real, esta situación no surge, pero es más adecuada para demostrar la funcionalidad.
Tome la asignación para leer dos tablas en una sola base de datos Oracle. Y deje que los resultados de lectura se escriban en una tabla en la misma base de datos. El esquema de mapeo será el siguiente:

En forma de mapeo en Informatica BDM 10.2.1, se ve así:
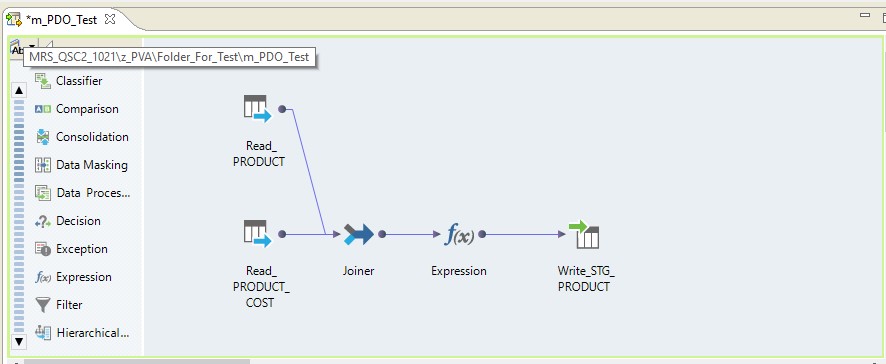
Tipo pushdown - nativo
Si seleccionamos el tipo nativo pushdown, la asignación se realizará en el servidor de Informatica. Los datos se leerán desde el servidor Oracle, se transferirán al servidor de Informatica, se transformarán allí y se transferirán a Hadoop. En otras palabras, obtenemos un proceso regular de ETL.
Tipo pushdown - fuente
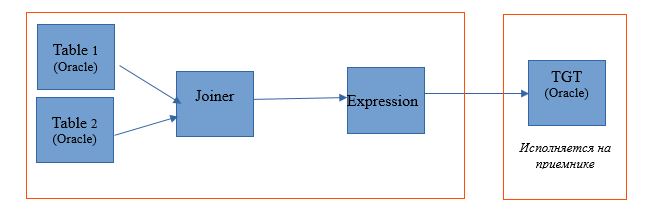
Al elegir el tipo de fuente, tenemos la oportunidad de distribuir nuestro proceso entre el servidor de base de datos (DB) y Hadoop. Al ejecutar un proceso con esta configuración, las solicitudes para seleccionar datos de las tablas volarán a la base de datos. Y el resto se hará en forma de pasos en Hadoop.
El esquema de ejecución se verá así:
A continuación se muestra un ejemplo de configuración del tiempo de ejecución.
En este caso, el mapeo se realizará en dos pasos. En su configuración, veremos que se convirtió en un script que se enviará a la fuente. Además, la combinación de tablas y conversión de datos se realizará en forma de una consulta anulada en la fuente.
En la imagen a continuación, vemos un mapeo optimizado en BDM y en la fuente, una solicitud anulada.
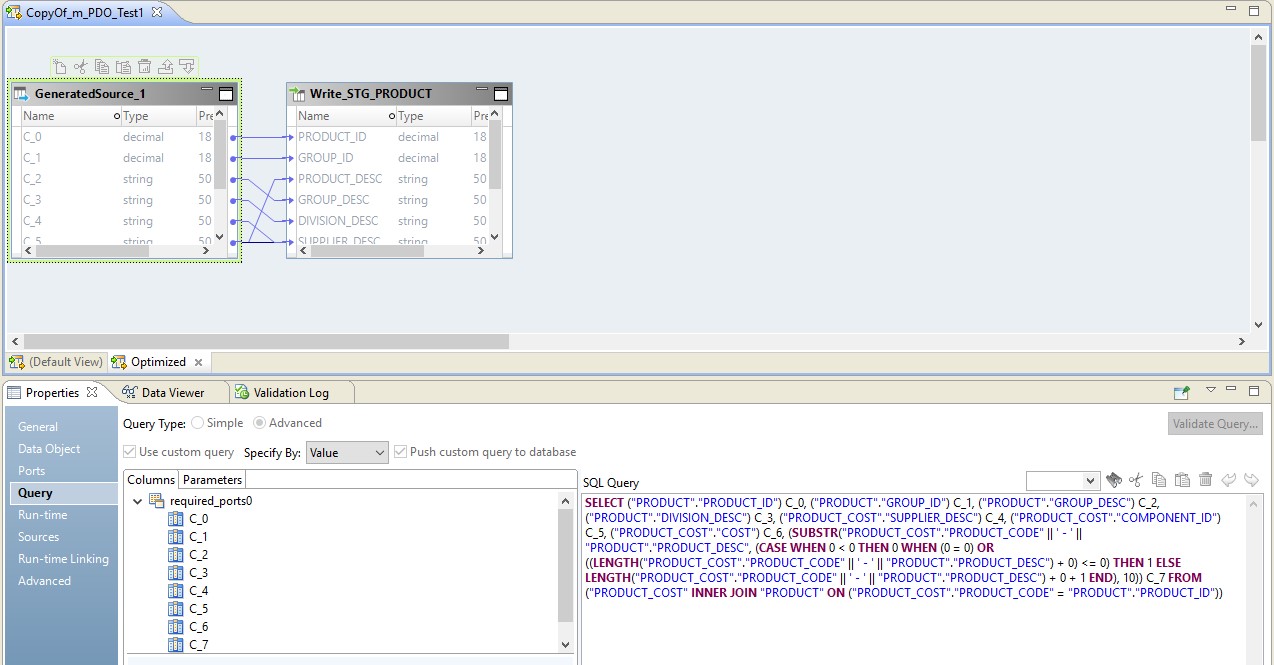
El papel de Hadoop en esta configuración se reduce a administrar el flujo de datos, llevarlo a cabo. El resultado de la solicitud se enviará a Hadoop. Después de leer, el archivo de Hadoop se escribirá en el receptor.
Tipo pushdown - completo
Al elegir el tipo completo, la asignación se convertirá completamente en una solicitud de base de datos. Y el resultado de la consulta se dirigirá a Hadoop. A continuación se presenta un diagrama de dicho proceso.
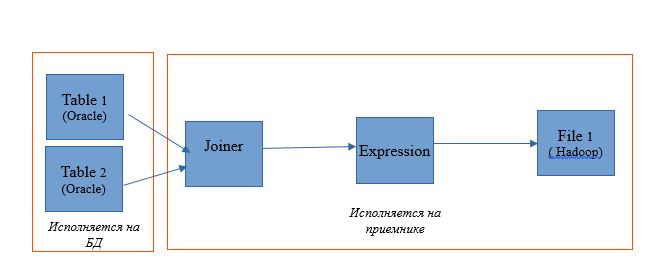
Un ejemplo de configuración se muestra a continuación.
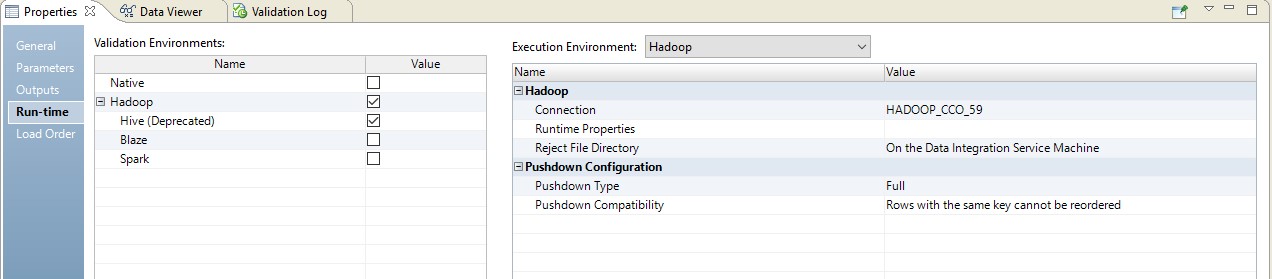
Como resultado, obtenemos un mapeo optimizado similar al anterior. La única diferencia es que toda la lógica se transfiere al receptor en forma de anulación de su inserción. A continuación se presenta un ejemplo de mapeo optimizado.
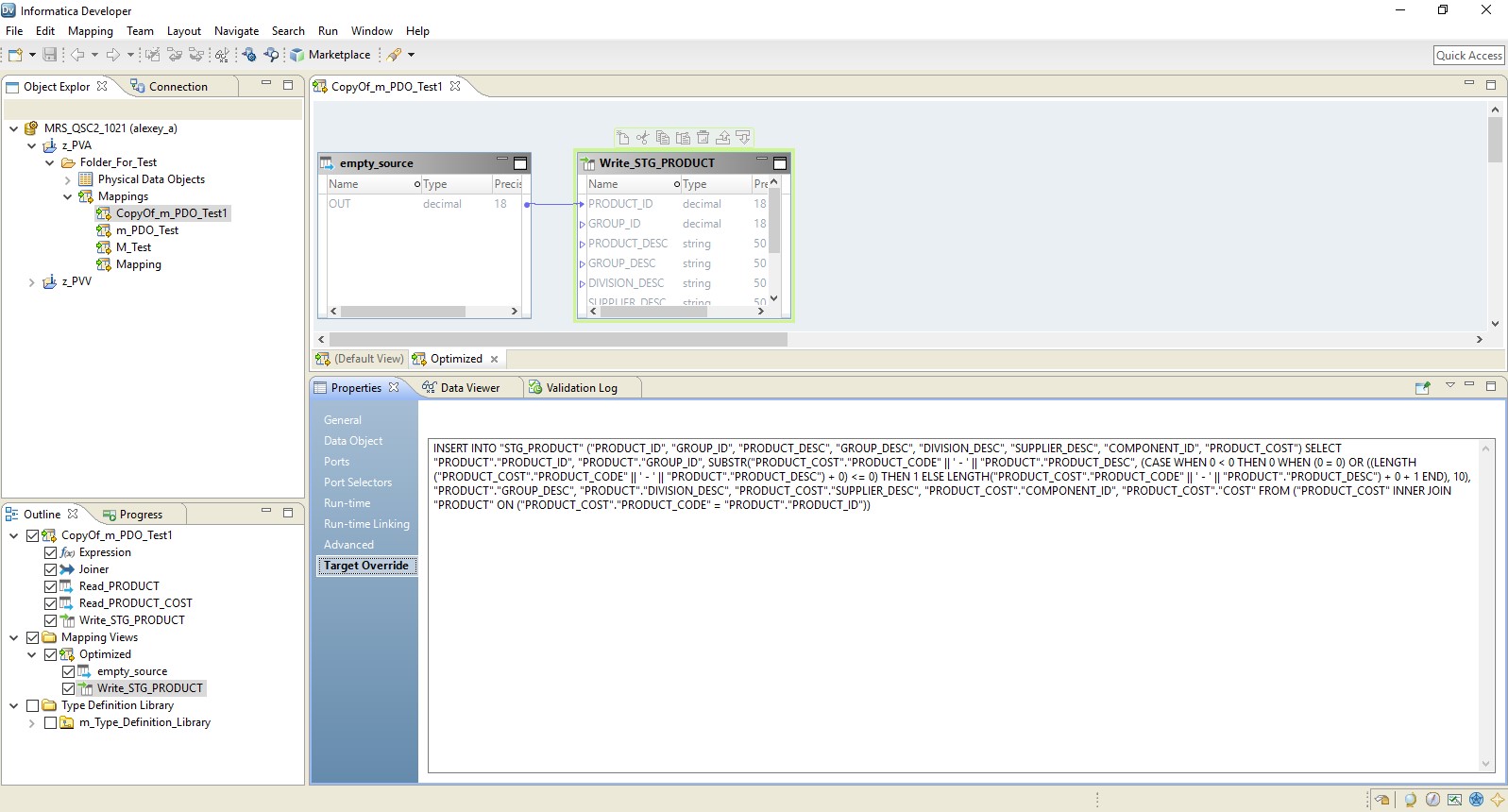
Aquí, como en el caso anterior, Hadoop actúa como conductor. Pero aquí la fuente se lee en su totalidad, y luego, a nivel del receptor, se ejecuta la lógica de procesamiento de datos.
Tipo pushdown - nulo
Bueno, la última opción es el tipo pushdown, dentro del cual nuestra asignación se convertirá en un script de Hadoop.
El mapeo optimizado ahora se verá así:
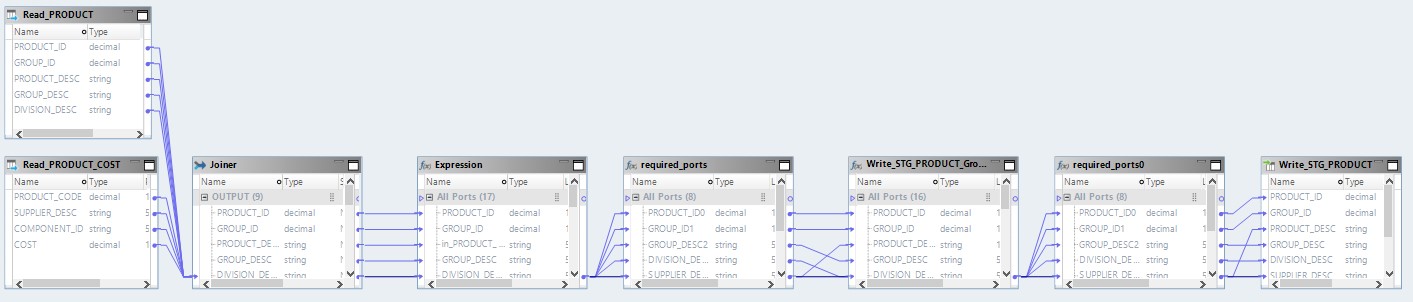
Aquí, los datos de los archivos de origen se leerán primero en Hadoop. Luego, por sus propios medios, estos dos archivos se combinarán. Después de eso, los datos se convertirán y cargarán en la base de datos.
Al comprender los principios de la optimización pushdown, puede organizar de manera muy efectiva muchos procesos para trabajar con big data. Entonces, recientemente, una gran empresa en solo unas pocas semanas cargó grandes datos desde el almacenamiento a Hadoop, que había estado recopilando durante varios años antes.