
En este artículo, hablaré sobre mi solución a la parte de texto de la tarea
SNA Hackathon 2019 . Algunas de las ideas propuestas serán útiles para los participantes de la parte de tiempo completo del hackathon, que se llevará a cabo en la oficina de Moscú del Grupo Mail.ru del 30 de marzo al 1 de abril. Además, esta historia puede ser de interés para los lectores que resuelven los problemas prácticos del aprendizaje automático. Como no puedo reclamar premios (trabajo en Odnoklassniki), traté de ofrecer la solución más simple, pero al mismo tiempo efectiva e interesante.
Al leer sobre nuevos modelos de aprendizaje automático, quiero entender cómo razonó el autor mientras trabajaba en una tarea. Por lo tanto, en este artículo intentaré sustanciar en detalle todos los componentes de mi solución. En la primera parte hablaré sobre el planteamiento del problema y las limitaciones. En el segundo, sobre la evolución del modelo. La tercera parte está dedicada a los resultados y al análisis del modelo. Finalmente, en los comentarios intentaré responder cualquier pregunta que haya surgido. Los lectores impacientes pueden mirar de inmediato la
arquitectura final .
Desafío
Los organizadores de Hackathon sugirieron que resolvamos el problema de formar una cinta inteligente. Para cada usuario, es necesario ordenar el conjunto de publicaciones para que el número máximo de publicaciones en el que el usuario establezca la "clase" esté en la parte superior de la lista. Para configurar el algoritmo de clasificación, se suponía que debía usar datos históricos del formulario (usuario, publicación, comentarios). La tabla proporciona una breve descripción de los datos de la parte del texto y la notación que usaré en este artículo.
Fuente
| Designación
| Tipo
| Descripción
|
|---|
el usuario
| ID_usuario
| categórico
| ID de usuario
|
publicar
| post_id
| categórico
| ID de publicación
|
publicar
| texto
| lista categórica
| lista de palabras normalizadas
|
publicar
| características
| categórico
| grupo de características de la publicación (autor, idioma, etc.)
|
retroalimentación
| retroalimentación
| lista binaria
| Diversas acciones que el usuario podría realizar con la publicación (vista, clase, comentario, etc.)
|
Antes de comenzar a construir el modelo, introduje varias restricciones en la solución futura. Esto era necesario para satisfacer los requisitos de simplicidad y practicidad, mis intereses y para reducir el número de opciones posibles. Aquí están las más importantes de estas limitaciones.
Predicción de la probabilidad de "clase" . Inmediatamente decidí que resolvería este problema como un problema de clasificación. Se podrían aplicar los métodos utilizados en la clasificación, por ejemplo, para predecir el orden en pares de publicaciones. Pero me decidí por una formulación más simple, en la que las publicaciones se ordenan según la probabilidad pronosticada de obtener una "clase". Vale la pena señalar que el enfoque que se describe a continuación se puede ampliar para formular la clasificación.
Modelo monolítico . A pesar del hecho de que los conjuntos de modelos tienden a ganar competencias, mantener un conjunto en un sistema de combate es más difícil que un solo modelo. Además, quería tener al menos algunas capacidades de interpretación de caja no negra.
Gráfico computacional diferenciable . En primer lugar, los modelos de esta clase (redes neuronales) determinan el estado del arte en muchas tareas, incluidas las relacionadas con el
análisis de datos de texto . En segundo lugar, los marcos modernos, en mi caso
Apache MXNet , le permiten implementar arquitecturas muy diversas. Por lo tanto, puede experimentar con diferentes modelos cambiando solo unas pocas líneas de código.
Trabajo mínimo con letreros . Quería que el modelo se expandiera fácilmente con nuevos datos. Esto puede ser necesario en la parte de tiempo completo, donde habrá poco tiempo para preparar las señales. Por lo tanto, me decidí por el enfoque más simple para identificar atributos:
- Los datos binarios están representados por una etiqueta con un valor de 1 o 0;
- los datos numéricos permanecen tal cual o se discretizan en categorías;
- Los datos categóricos se presentan mediante incrustaciones.
Habiendo decidido la estrategia general, comencé a probar diferentes modelos.
Modelo de evolución
El punto de partida fue el enfoque de factorización matricial, a menudo utilizado en tareas de recomendación:
pi,j= sigma(ui cdotvj)
Pérdida(yi,j,pi,j) rightarrowminu,v
En el lenguaje de los gráficos computacionales, esto significa que la estimación de la probabilidad de que el usuario
i ponga una "clase" en la publicación
j es el sigmoide del producto escalar de incrustar el identificador de usuario y el identificador de publicación. Lo mismo se puede expresar mediante un diagrama:

Tal modelo no es muy interesante: no utiliza todas las características, no es demasiado útil para identificadores de baja frecuencia y sufre el problema de un arranque en frío. Pero, habiendo formulado la tarea en forma de un gráfico computacional, "desatamos nuestras manos" y ahora podemos resolver problemas por etapas. En primer lugar, para valores de baja frecuencia, crearemos la única incrustación fuera del
vocabulario . A continuación, elimine la necesidad de tener incrustaciones de la misma dimensión. Para hacer esto, reemplazamos el producto escalar con un perceptrón poco profundo, que recibe características concatenadas como entrada. El resultado se presenta en el diagrama:

Una vez que nos deshacemos de una dimensión fija, nada nos impide comenzar a agregar nuevos atributos. Representando la publicación con todo tipo de características (idioma, autor, texto, ...), resolveremos el problema del inicio en frío de las publicaciones. El modelo aprenderá, por ejemplo, que un usuario con
user_id = 42 coloca "clases" en publicaciones en ruso que contienen la palabra "alfombra". En el futuro, podremos recomendar a este usuario todas las publicaciones en ruso sobre alfombras, incluso si no aparecen en los datos de capacitación. Para la incrustación de texto, por ahora, simplemente promediaremos las incrustaciones de las palabras incluidas en él. Como resultado, el modelo se ve así:
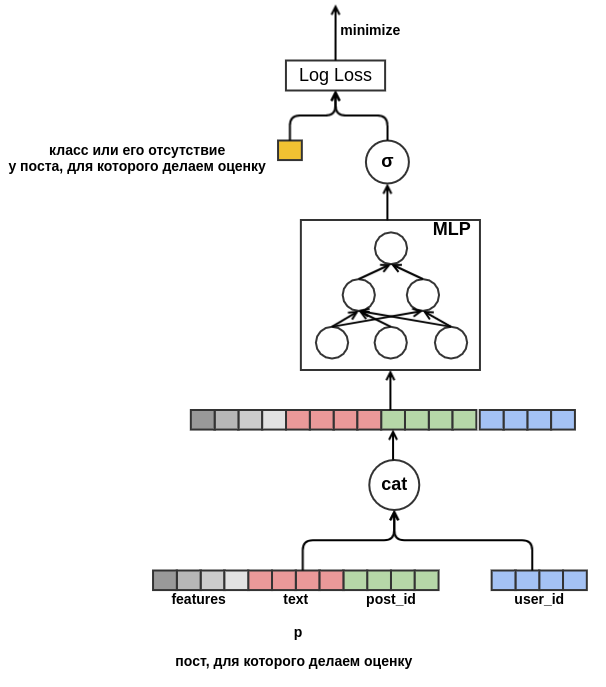
Finalmente, me gustaría lidiar con el arranque en frío de los usuarios. Sería posible construir características a partir de datos históricos sobre las vistas de publicaciones de los usuarios. Este enfoque no satisface la estrategia elegida: decidimos minimizar la creación manual de atributos. Por lo tanto, proporcioné al modelo la oportunidad de aprender de forma independiente la presentación del usuario a partir de la secuencia de publicaciones vistas antes de esa publicación para la que se evalúa la probabilidad de la "clase". A diferencia de la publicación que se está evaluando, todos los comentarios se conocen para cada publicación de la secuencia. Esto significa que el modelo tendrá acceso a información sobre si el usuario ha establecido las "publicaciones" en publicaciones anteriores o, por el contrario, las ha eliminado del feed.

Queda por decidir cómo combinar secuencias de publicaciones de diferentes longitudes en una representación de un ancho fijo. Como tal combinación, utilicé la suma ponderada de las representaciones de cada una de las publicaciones. En el gráfico, el peso posterior
j se denota por
α_j . Los pesos se calcularon utilizando el mecanismo de atención de valor clave-consulta, similar al utilizado en el
transformador o
NMT . Por lo tanto, la presentación aprendida del usuario también se configura para la publicación para la que se realiza la evaluación. Aquí hay una parte del gráfico responsable de calcular
α_j :
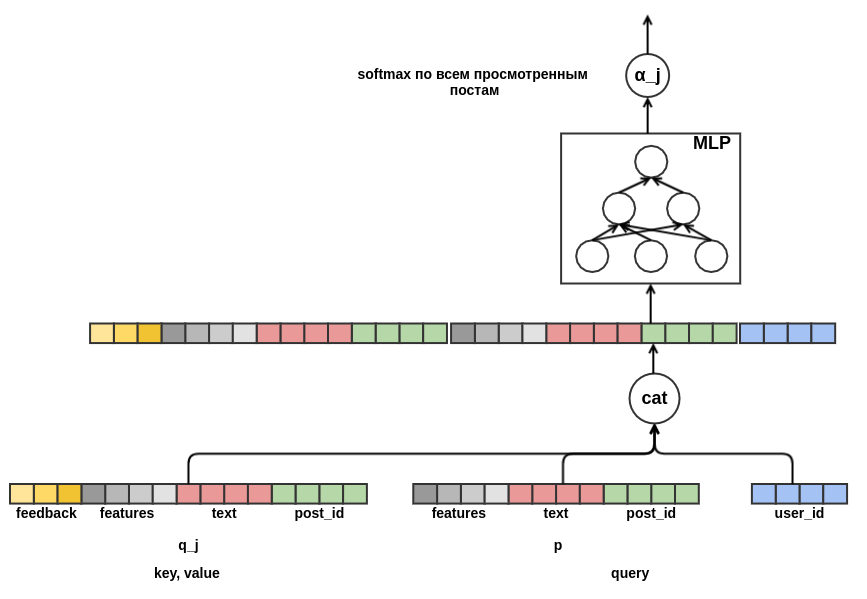
Después de
sentir un canto de juerga, me convencí de la efectividad del enfoque de atención, se decidió utilizar la atención en la presentación de textos. En aras de ahorrar tiempo y hierro, decidí no usar la auto-atención como en el mismo transformador, sino entrenar directamente los pesos de las palabras en el texto, así:
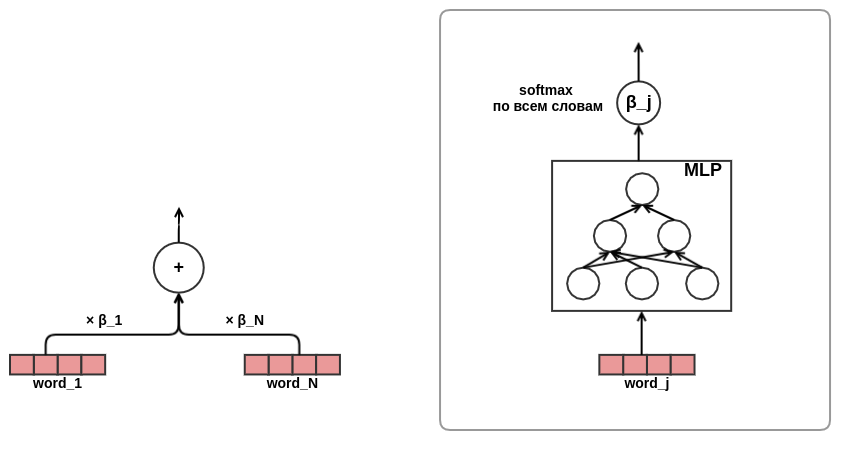
Sobre esto, se completó el desarrollo de la arquitectura del modelo. Como resultado, pasé de la factorización clásica de matrices a un modelo de secuencia bastante complejo.
Resultados y análisis
Desarrollé y depuré mi solución en un séptimo de los datos en una computadora portátil con 16 GB de memoria y una tarjeta gráfica GeForce 930MX. Se realizaron experimentos de datos completos en un servidor dedicado con 256 GB de memoria y una tarjeta Tesla T4. Para la optimización, se utilizó el algoritmo Adam con los parámetros predeterminados de MXNet. La tabla muestra los resultados para un modelo simplificado: la longitud de la secuencia de publicaciones se limitó a diez. En el concurso presentado, utilicé secuencias de longitud cincuenta.
Modelo
| Pérdida de registro
| Mejora de la línea anterior.
| Tiempo de entrenamiento
|
|---|
Al azar
| 0.4374 ± 0.0009
| | |
Perceptrón
| 0.4330 ± 0.0010
| 0.0043 ± 0.0002
| 7 min
|
Perceptrón con signos
| 0.4119 ± 0.0008
| 0.0212 ± 0.0003
| 44 min
|
Perceptrón con una secuencia de publicaciones
| 0.3873 ± 0.0008
| 0.0247 ± 0.0003
| 4 horas 16 minutos
|
Perceptrón con una secuencia de publicaciones y atención en los textos.
| 0.3874 ± 0.0008
| 0.0001 ± 0.0001
| 4 horas 43 minutos
|
La última línea resultó ser la más inesperada para mí: usar la atención en la presentación de textos no proporciona una mejora visible en el resultado. Esperaba que la red de atención aprendiera el peso de las palabras en los textos, algo así como
idf . Quizás esto no sucedió, porque los organizadores eliminaron las palabras de detención por adelantado y las palabras de la misma importancia permanecieron en las listas preparadas. Por lo tanto, el pesaje "inteligente" no dio una ventaja tangible en comparación con el promedio simple. Otra posible razón es que la red de atención para las palabras era bastante pequeña: contenía solo una capa oculta estrecha. Quizás carecía de capacidad de representación para aprender algo útil.
El mecanismo de atención de consulta-valor-clave le permite mirar dentro del modelo y descubrir a qué "presta atención" al tomar una decisión. Para ilustrar esto,
seleccioné algunos ejemplos:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
La primera línea muestra el texto de la publicación que debe evaluarse, luego las publicaciones vistas anteriormente y el puntaje de atención correspondiente. Con alivio, notamos que el modelo ha aprendido a ignorar el relleno. El modelo consideraba las publicaciones como las más importantes sobre los tipos de almas y sobre Windows. Debe tenerse en cuenta que la atención puede ser positiva (el usuario responderá a una publicación sobre un aura de la misma manera que una publicación sobre tipos de almas) o negativa (evaluamos una publicación sobre un aura; por lo tanto, la reacción no será la misma que la reacción a la publicación sobre tecnología). El siguiente ejemplo es la atención "en todo su esplendor":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
Aquí, la modelo vio claramente el tema de las vacaciones de verano. Incluso los niños y los gatitos fueron por el camino. El siguiente ejemplo muestra que interpretar la atención no siempre es posible. A veces, incluso nada está claro:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
Después de mirar varias de esas listas, llegué a la conclusión de que el modelo pudo aprender lo que esperaba. Lo siguiente que hice fue mirar la incrustación de palabras. En nuestro problema, no podemos esperar que las incrustaciones resulten tan hermosas como cuando se aprende un
modelo de lenguaje : estamos tratando de predecir una variable bastante ruidosa, además, no tenemos una pequeña ventana de contexto: las incrustaciones de todas las palabras simplemente se promedian sin tener en cuenta su orden en el texto. Ejemplos de tokens y sus vecinos más cercanos en el espacio de incrustación:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
Parte de esta lista es fácil de explicar (programa - bl), algo es desconcertante (iPhone - youki), pero en general, el resultado volvió a cumplir mis expectativas.
Conclusión
Me gusta el enfoque para construir modelos basados en gráficos diferenciables (
muchos están de acuerdo ). Le permite alejarse de la tediosa selección manual de características y centrarse en la formulación correcta del problema y diseñar arquitecturas interesantes. Y aunque mi modelo ocupó solo el segundo lugar en la tarea de texto SNA Hackathon 2019, estoy bastante satisfecho con este resultado, dada su simplicidad y sus opciones de expansión casi ilimitadas. Estoy seguro de que en el futuro habrá modelos cada vez más interesantes y aplicables en los sistemas de combate basados en ideas similares.