Hoy les contaré cómo logramos resolver el problema de portar
aplicaciones de transmisión estructuradas de Spark a
Kubernetes (K8) e implementar la transmisión de CI.
¿Cómo empezó todo?
La transmisión es un componente clave de la plataforma FASTEN RUS BI. El equipo de análisis de fechas utiliza los datos en tiempo real para crear informes operativos.
Las aplicaciones de transmisión se implementan usando
Spark Structured Streaming . Este marco proporciona una API de transformación de datos conveniente que satisface nuestras necesidades en términos de la velocidad de las mejoras.
Las transmisiones mismas aumentaron en el clúster de
AWS EMR . Por lo tanto, al subir una nueva secuencia al clúster, se diseñó un script ssh para enviar trabajos de Spark, después de lo cual se lanzó la aplicación. Y al principio todo parecía adaptarse a nosotros. Pero con el creciente número de transmisiones, la necesidad de transmisión de CI se hizo cada vez más obvia, lo que aumentaría la autonomía del comando de fecha de análisis al iniciar aplicaciones para entregar datos en nuevas entidades.
Y ahora veremos cómo logramos resolver este problema transfiriendo la transmisión a Kubernetes.
¿Por qué kubernetes?
Kubernetes, como gerente de recursos, se adapta mejor a nuestras necesidades. Esta es una implementación sin tiempo de inactividad y una amplia gama de herramientas de implementación de CI en Kubernetes, incluido Helm. Además, nuestro equipo tenía suficiente experiencia en la implementación de tuberías de CI en K8. Por lo tanto, la elección fue obvia.
¿Cómo se organiza el modelo de gestión de aplicaciones Spark basado en Kubernetes?

El cliente ejecuta spark-submit en K8. Se crea un pod controlador de aplicaciones. El programador de Kubernetes vincula un pod a un nodo del clúster. Luego, el controlador envía una solicitud para crear pods para ejecutar ejecutivos, los pods se crean y se conectan a los nodos del clúster. Después de eso, se realiza un conjunto estándar de operaciones con la posterior conversión del código de la aplicación en DAG, descomposición en etapas, descomposición en tareas y su ejecución en ejecutables.
Este modelo funciona con bastante éxito al iniciar manualmente las aplicaciones de Spark. Sin embargo, el enfoque de lanzar el envío de chispas fuera del clúster no nos convenía en términos de implementación de CI. Era necesario encontrar una solución que permitiera a Spark ejecutarse (realizar envío de chispa) directamente en los nodos del clúster. Y aquí el modelo de operador de Kubernetes cumplió plenamente con nuestros requisitos.
Operador de Kubernetes como modelo de gestión del ciclo de vida de la aplicación Spark
Kubernetes Operator es un concepto de gestión de aplicaciones con estado en Kubernetes, propuesto por
CoreOS , que implica la automatización de tareas operativas, como implementar aplicaciones, reiniciar aplicaciones en caso de archivos, actualizar la configuración de las aplicaciones. Uno de los patrones clave del operador de Kubernetes es CRD (
CustomResourceDefinitions ), que implica agregar recursos personalizados al clúster K8s, que, a su vez, le permite trabajar con estos recursos como con los objetos nativos de Kubernetes.
Operator es un demonio que vive en el pod del clúster y responde a la creación / cambio del estado de un recurso personalizado.
Considere este concepto para la gestión del ciclo de vida de la aplicación Spark.
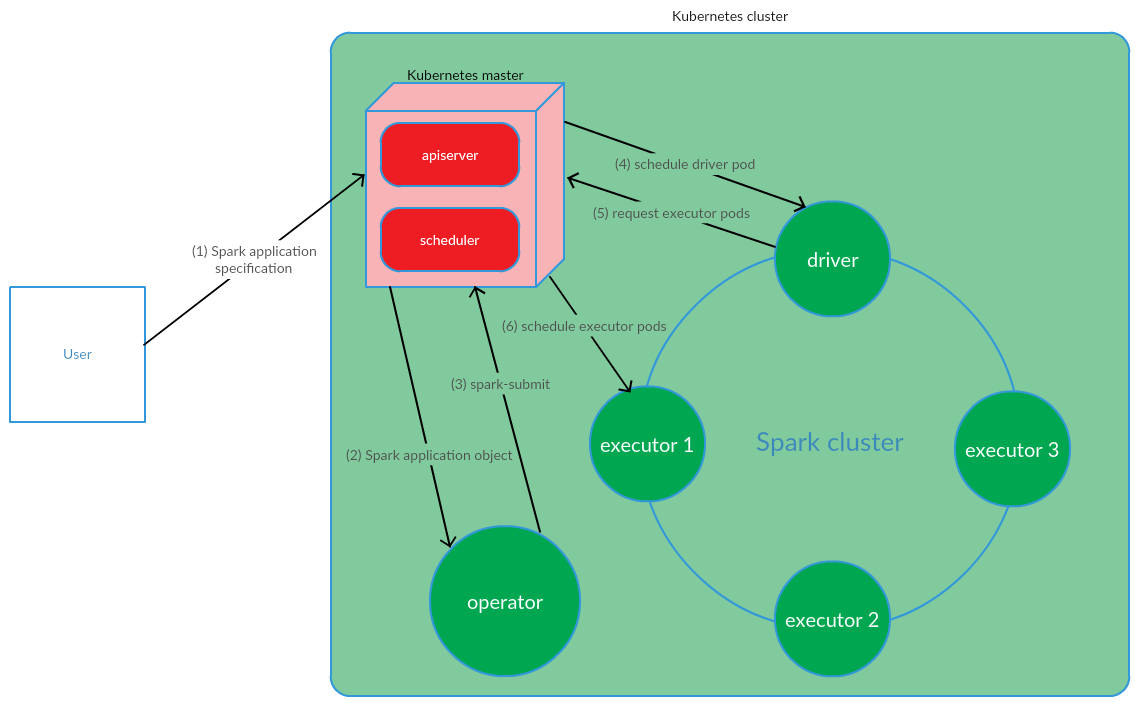
El usuario ejecuta el comando kubectl apply -f spark-application.yaml, donde spark-application.yaml es la especificación de la aplicación Spark. El operador recibe el objeto de aplicación Spark y ejecuta el envío de chispa.
Como podemos ver, el modelo de operador de Kubernetes implica administrar el ciclo de vida de una aplicación Spark directamente en el clúster de Kubernetes, lo cual fue un argumento serio a favor de este modelo en el contexto de la resolución de nuestros problemas.
Como operador de Kubernetes para gestionar aplicaciones de transmisión, se decidió utilizar
el operador spark-on-k8s . Este operador ofrece una API bastante conveniente, así como flexibilidad en la configuración de la política de reinicio para las aplicaciones de Spark (que es bastante importante en el contexto del soporte de aplicaciones de transmisión).
Implementación de CI
Para implementar la transmisión de CI,
se utilizó GitLab CI / CD . El despliegue de aplicaciones Spark en K8 se realizó utilizando herramientas
Helm .
La tubería en sí implica 2 etapas:
- prueba: se realiza la comprobación de sintaxis, así como la representación de plantillas de Helm;
- deploy: despliegue de aplicaciones de transmisión en los entornos de prueba (dev) y producto (prod).
Consideremos estas etapas con más detalle.
En la etapa de prueba, la plantilla Helm de la aplicación Spark (CRD -
SparkApplication ) se
representa con valores específicos del entorno.
Las secciones clave de la plantilla Helm son:
- chispa:
- versión - versión Apache Spark
- imagen: imagen de Docker utilizada
- nodeSelector: contiene una lista (clave → valor) correspondiente a las etiquetas de los hogares.
- tolerancias: indica la lista de tolerancias de la aplicación Spark.
- mainClass - Clase de aplicación Spark
- applicationFile: ruta local donde se encuentra el jar de la aplicación Spark
- restartPolicy - Política de reinicio de la aplicación Spark
- Nunca: la aplicación Spark completada no se reinicia
- Siempre: la aplicación Spark completada se reinicia independientemente del motivo de la detención.
- OnFailure: la aplicación Spark se reinicia solo en caso de archivo
- maxSubmissionRetries: número máximo de envíos de una aplicación Spark
- conductor / ejecutor:
- núcleos: el número de núcleos asignados al controlador / ejecutor
- instancias (utilizadas solo para la configuración de ejecutivos): el número de ejecutivos
- memoria: la cantidad de memoria asignada al proceso del controlador / ejecutor
- memoryOverhead: la cantidad de memoria fuera del montón asignada al controlador / ejecutor
- corrientes:
- nombre: nombre de la aplicación de transmisión
- argumentos - argumentos a la aplicación de transmisión
- sumidero: la ruta a los conjuntos de datos de Data Lake en S3
Después de representar la plantilla, las aplicaciones se implementan en el entorno de prueba de desarrollo mediante Helm.
Resolvió la tubería de CI.
Luego lanzamos el trabajo deploy-prod, lanzando aplicaciones en producción.
Estamos convencidos del desempeño exitoso del trabajo.
Como podemos ver a continuación, las aplicaciones se están ejecutando, los pods están en estado EN EJECUCIÓN.

Conclusión
La transferencia de aplicaciones de transmisión estructuradas de Spark a K8 y la posterior implementación de CI nos permitieron automatizar el lanzamiento de transmisiones para entregar datos a nuevas entidades. Para generar la siguiente secuencia, es suficiente preparar una Solicitud de fusión con una descripción de la configuración de la aplicación Spark en el archivo de valores yaml y cuando se inicia el trabajo de implementación-producción, se iniciará la entrega de datos a Data Lake (S3). Esta solución garantizó la autonomía del comando de fecha de análisis al realizar tareas relacionadas con la adición de nuevas entidades al repositorio. Además, la transmisión de transmisiones a K8 y, en particular, la administración de aplicaciones de Spark con el operador Kubernetes Operador spark-on-k8 aumentaron significativamente la resistencia de la transmisión. Pero más sobre eso en el próximo artículo.