
El mundo moderno es simplemente inconcebible sin el uso de sistemas distribuidos. Incluso la aplicación móvil más simple tiene una API a través de la cual se conecta al almacenamiento en la nube. Sin embargo, el diseño de sistemas distribuidos sigue siendo un arte, no una ciencia exacta. La necesidad de poner una base seria debajo de ella está muy atrasada, y si desea ganar confianza en la creación, soporte y operación de sistemas distribuidos, ¡comience con este libro!
Brendan Burns, un reputado especialista en tecnologías de nube y Kubernetes, establece en este pequeño trabajo el mínimo absoluto necesario para el diseño adecuado de los sistemas distribuidos. Este libro describe los patrones eternos del diseño de sistemas distribuidos. Le ayudará no solo a crear tales sistemas desde cero, sino también a convertir efectivamente los existentes.
Extracto Patrón Decorador Convertir una solicitud o respuesta
FaaS es ideal cuando necesita funciones simples que procesan datos de entrada y luego los transfieren a otros servicios. Este tipo de patrón puede usarse para extender o decorar solicitudes HTTP enviadas o recibidas por otro servicio. Este patrón se muestra esquemáticamente en la Fig. 8.1.
Por cierto, en los lenguajes de programación hay varias analogías con este patrón. En particular, Python tiene decoradores de funciones que son funcionalmente similares a los decoradores de solicitud o respuesta. Dado que las transformaciones de decoración no almacenan estado y, a menudo, se agregan ex facto a medida que se desarrolla el servicio, son ideales para la implementación como FaaS. Además, la ligereza FaaS significa que puede experimentar con diferentes decoradores hasta que encuentre uno que se integre más estrechamente con el servicio.
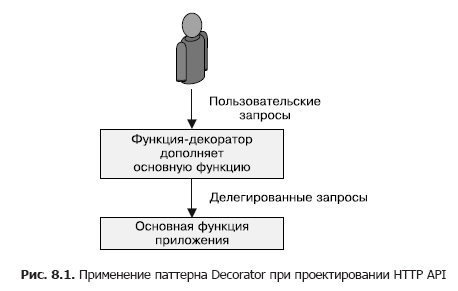
Agregar valores predeterminados a los parámetros de entrada de las solicitudes HTTP RESTful API demuestra los beneficios del patrón Decorator. Muchas solicitudes de API tienen campos que deben completarse con valores razonables si el llamador no los especificó. Por ejemplo, desea que el campo tenga el valor predeterminado verdadero. Esto es difícil de lograr con el JSON clásico, porque el campo vacío predeterminado es nulo, lo que generalmente se interpreta como falso. Para resolver este problema, puede agregar la lógica de sustituir los valores predeterminados delante del servidor API o en el código de la aplicación (por ejemplo, si (campo == nulo) campo = verdadero). Sin embargo, ambos enfoques no son óptimos, ya que el mecanismo de sustitución predeterminado es conceptualmente independiente del procesamiento de solicitudes. En cambio, podemos usar el patrón FaaS Decorator, que transforma la solicitud en el camino entre el usuario y la implementación del servicio.
Teniendo en cuenta lo que se dijo anteriormente en la sección sobre patrones de nodo único, es posible que se pregunte por qué no diseñamos el servicio de sustitución predeterminado en forma de un contenedor adaptador. Este enfoque tiene sentido, pero también significa que la escala del servicio de búsqueda predeterminado y la escala del servicio API se vuelven dependientes entre sí. La sustitución de valores predeterminados es una operación computacionalmente fácil y, para ello, lo más probable es que no necesite muchas instancias del servicio.
En los ejemplos de este capítulo, usaremos el marco FaaS sin kube (https://github.com/kubeless/kubeless). Kubeless se implementa sobre el servicio de orquestador de contenedores de Kubernetes. Si ya ha preparado el clúster de Kubernetes, continúe con la instalación de Kubeless, que se puede descargar desde el sitio correspondiente (https://github.com/kubeless/kubeless/releases). Una vez que tenga el ejecutable kubeless, puede instalarlo en el clúster con el comando de instalación kubeless.
Kubeless se instala como un complemento de API de Kubernetes de terceros. Esto significa que después de la instalación se puede usar como parte de la herramienta de línea de comandos kubectl. Por ejemplo, las funciones implementadas en el clúster se pueden ver ejecutando el comando kubectl get functions. Actualmente no hay funciones implementadas en su clúster.
Taller Sustitución de valores predeterminados antes de procesar la solicitud
Puede demostrar la utilidad del patrón Decorator en FaaS utilizando el ejemplo de sustitución de valores predeterminados en una llamada RESTful para parámetros cuyos valores no fueron establecidos por el usuario. Con FaaS, esto es bastante simple. La función de búsqueda predeterminada está escrita en Python:
# -, # def handler(context): # obj = context.json # "name" , # if obj.get("name", None) is None: obj["name"] = random_name() # 'color', # 'blue' if obj.get("color", None) is None: obj["color"] = "blue" # API- # # return call_my_api(obj)
Guarde esta función en un archivo llamado defaults.py. Recuerde reemplazar la llamada call_my_api con la API que desee. Esta función de sustitución predeterminada se puede registrar como una función sin cubo con el siguiente comando:
kubeless function deploy add-defaults \ --runtime python27 \ --handler defaults.handler \ --from-file defaults.py \ --trigger-http
Para probarlo, puede usar la herramienta sin cubo:
kubeless function call add-defaults --data '{"name": "foo"}'
El patrón Decorator muestra lo fácil que es adaptar y ampliar las API existentes con características adicionales como validar o sustituir valores predeterminados.
Manejo de eventos
La mayoría de los sistemas están orientados a consultas: procesan flujos continuos de solicitudes de usuario y API. A pesar de esto, hay bastantes sistemas orientados a eventos. La diferencia entre la solicitud y el evento, me parece, radica en el concepto de la sesión. Las solicitudes son parte de un proceso de interacción más grande (sesión). En el caso general, cada solicitud de usuario es parte del proceso de interacción con una aplicación web o la API en su conjunto. Veo los eventos como más "únicos", de naturaleza asincrónica. Los eventos son importantes y deben manejarse en consecuencia, pero se sacan del contexto principal de interacción y la respuesta a ellos llega solo después de un tiempo. Un ejemplo de un evento es la suscripción de un usuario a un determinado servicio, lo que provocará el envío de una carta de saludo; cargar un archivo en una carpeta compartida, lo que llevará a enviar notificaciones a todos los usuarios de esta carpeta; o incluso preparar la computadora para reiniciar, lo que notificará al operador o al sistema automatizado que se requiere la acción adecuada.
Dado que estos eventos son en gran medida independientes y no tienen un estado interno, y su frecuencia es muy variable, son ideales para trabajar en arquitecturas FaaS orientadas a eventos. A menudo se implementan junto al servidor de aplicaciones de "batalla" para proporcionar capacidades adicionales o para el procesamiento en segundo plano de los datos en respuesta a eventos emergentes. Además, dado que constantemente se agregan nuevos tipos de eventos procesados al servicio, la simplicidad de la implementación de funciones los hace adecuados para implementar controladores de eventos. Y dado que cada evento es conceptualmente independiente de los demás, el debilitamiento forzado de las relaciones dentro de un sistema construido sobre la base de funciones nos permite reducir su complejidad conceptual, lo que permite al desarrollador centrarse en los pasos necesarios para procesar solo un tipo específico de evento.
Un ejemplo específico de integración de un componente orientado a eventos en un servicio existente es la implementación de la autenticación de dos factores. En este caso, el evento será el inicio de sesión del usuario en el sistema. Un servicio puede generar un evento para esta acción y pasarlo a una función de controlador. El controlador enviará un código de autenticación en forma de mensaje de texto basado en el código transmitido y la información de contacto del usuario.
Taller Implementación de autenticación de dos factores
La autenticación de dos factores indica que para que el usuario ingrese al sistema, necesita algo que sabe (por ejemplo, una contraseña) y algo que tiene (por ejemplo, un número de teléfono). La autenticación de dos factores es mucho mejor que solo una contraseña, porque un atacante tendrá que robar tanto su contraseña como su número de teléfono para obtener acceso.
Al planificar la implementación de la autenticación de dos factores, debe procesar una solicitud para generar un código aleatorio, registrarlo con el servicio de inicio de sesión y enviar un mensaje al usuario. Puede agregar código que implemente esta funcionalidad directamente en el servicio de inicio de sesión. Esto complica el sistema, lo hace más monolítico. El envío de un mensaje debe realizarse simultáneamente con el código que genera la página web de inicio de sesión, lo que puede generar un cierto retraso. Este retraso degrada la calidad de la interacción del usuario con el sistema.
Sería mejor crear un servicio FaaS que generaría un número aleatorio de forma asincrónica, registrarlo con el servicio de inicio de sesión y enviarlo al teléfono del usuario. Por lo tanto, el servidor de inicio de sesión puede simplemente ejecutar una solicitud asincrónica al servicio FaaS, que en paralelo realizará la tarea relativamente lenta de registrar y enviar el código.
Para ver cómo funciona esto, considere el siguiente código:
def two_factor(context): # code = random.randint(1 00000, 9 99999) # user = context.json["user"] register_code_with_login_service(user, code) # Twillio account = "my-account-sid" token = "my-token" client = twilio.rest.Client(account, token) user_number = context.json["phoneNumber"] msg = ", {}, : {}.".format(user, code) message = client.api.account.messages.create(to=user_number, from_="+1 20652 51212", body=msg) return {"status": "ok"}
Luego registre FaaS en Kubeless:
kubeless function deploy add-two-factor \ --runtime python27 \ --handler two_factor.two_factor \ --from-file two_factor.py \ --trigger-http
Una instancia de esta función puede generarse asíncronamente a partir del código JavaScript del lado del cliente después de que el usuario ingrese la contraseña correcta. La interfaz web puede mostrar inmediatamente la página para ingresar el código, y el usuario, tan pronto como reciba el código, puede informarle sobre el servicio de inicio de sesión en el que este código ya está registrado.
Por lo tanto, el enfoque FaaS ha facilitado enormemente el desarrollo de un servicio simple, asíncrono y orientado a eventos que se inicia cuando un usuario inicia sesión en el sistema.
Transportadores de eventos
Hay una serie de aplicaciones que, de hecho, son más fáciles de considerar como una tubería de eventos poco acoplados. Las canalizaciones de eventos a menudo se parecen a los buenos diagramas de flujo antiguos. Se pueden representar como un gráfico dirigido de sincronización de eventos relacionados. Dentro del marco del patrón Event Pipeline, los nodos corresponden a funciones, y los arcos que los conectan corresponden a solicitudes HTTP u otro tipo de llamadas de red.
Entre los elementos del contenedor, por regla general, no hay un estado común, pero puede haber un contexto común u otro punto de referencia, en función del cual se realizará la búsqueda en el almacenamiento.
¿Cuál es la diferencia entre una arquitectura de canalización y microservicio? Hay dos diferencias importantes. La primera y más importante diferencia entre las funciones de servicio y los servicios que se ejecutan constantemente es que las canalizaciones de eventos se basan esencialmente en eventos. La arquitectura de microservicios, por el contrario, implica un conjunto de servicios que funcionan constantemente. Además, las canalizaciones de eventos pueden ser asíncronas y enlazar una variedad de eventos. Es difícil imaginar cómo se puede integrar la aprobación de la aplicación de Jira en una aplicación de microservicio. Al mismo tiempo, es fácil imaginar cómo se integra en la canalización de eventos.
Como ejemplo, considere una tubería en la que el evento de origen es la carga de código en un sistema de control de versiones. Este evento provoca una reconstrucción del código. El ensamblaje puede demorar varios minutos, luego de lo cual se genera un evento que activa la función de prueba de la aplicación ensamblada. Dependiendo del éxito del ensamblaje, la función de prueba toma diferentes acciones. Si el ensamblaje fue exitoso, se crea una aplicación, que debe ser aprobada por la persona para que la nueva versión de la aplicación entre en funcionamiento. Cerrar la aplicación sirve como señal para poner en funcionamiento la nueva versión. Si el ensamblaje falla, Jira solicita el error detectado y la tubería se cierra.
Taller Implementar una canalización para registrar un nuevo usuario
Considere la tarea de implementar una secuencia de acciones para registrar un nuevo usuario. Al crear una nueva cuenta, siempre se realiza una serie completa de acciones, por ejemplo, enviar un correo electrónico de bienvenida. También hay una serie de acciones que pueden no realizarse cada vez, por ejemplo, suscribirse a un boletín de correo electrónico sobre nuevas versiones de un producto (también conocido como spam).
Un enfoque implica crear un servicio monolítico para crear nuevas cuentas. Con este enfoque, un equipo de desarrollo es responsable de todo el servicio, que también se implementa como un todo. Esto hace que sea difícil realizar experimentos y realizar cambios en el proceso de interacción del usuario con la aplicación.
Considere la implementación del inicio de sesión del usuario como una canalización de eventos de varios servicios de FaaS. Con esta separación, la función de creación de usuarios no tiene idea de lo que sucede durante el inicio de sesión del usuario. Ella tiene dos listas:
- una lista de acciones necesarias (por ejemplo, enviar un correo electrónico de bienvenida);
- una lista de acciones opcionales (por ejemplo, suscribirse a un boletín informativo).
Cada una de estas acciones también se implementa como FaaS, y la lista de acciones no es más que una lista de funciones de devolución de llamada HTTP. Por lo tanto, la función de creación de usuarios tiene la siguiente forma:
def create_user(context): # for key, value in required.items(): call_function(value.webhook, context.json) # # for key, value in optional.items(): if context.json.get(key, None) is not None: call_function(value.webhook, context.json)
Cada uno de los controladores ahora también se puede implementar de acuerdo con el principio FaaS:
def email_user(context): # user = context.json['username'] msg = ', {}, , !".format(user) send_email(msg, contex.json['email]) def subscribe_user(context): # email = context.json['email'] subscribe_user(email)
Descompuesto de esta manera, el servicio FaaS se vuelve mucho más simple, contiene menos líneas de código y se enfoca en la implementación de una función específica. El enfoque de microservicio simplifica la escritura de código, pero puede generar dificultades para implementar y administrar tres microservicios diferentes. Aquí, el enfoque FaaS se demuestra en todo su esplendor, porque como resultado de su uso se vuelve muy simple administrar pequeños fragmentos de código. La visualización del proceso de creación de un usuario en forma de canalización de eventos también nos permite comprender en términos generales qué sucede exactamente cuando un usuario inicia sesión, simplemente siguiendo el cambio de contexto de función a función dentro de la canalización.
»Se puede encontrar más información sobre el libro en
el sitio web del editor»
Contenidos»
Extracto20% de descuento en cupones para diseñadores -
Patrones de diseñoTras el pago de la versión en papel del libro, se envía una versión electrónica del libro por correo electrónico.